







kafka是分布式发布-订阅消息系统,它是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
1.kafka的特点:
(1)它被设计为一个分布式系统,易于向外扩展;
(2)它同时为发布和订阅提供高吞吐量;
(3)它支持多订阅者,当失败时能自动平衡消费者;
(4)它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
2.kafka包括以下组件:
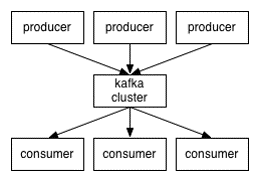
(1)话题(Topic),是特定类型的消息流,话题是消息的分类名;
(2)生产者(Producer),是能够发布消息到话题的任何对象;
(3)消费者(Consumer),是消息的接收者,消费者可以订阅一个或多个话题。
3.要点:
具体可以参考这篇博客:kafka入门
(1)一个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。一个topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replications),每个partition将会被备份到多台机器上,以提高可用性。 partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
(2)kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存。
(3) Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于”round-robin”方式或者通过其他的一些算法等。
(4) 本质上kafka只支持Topic。每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer。发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费。
4.操作:
(1)启动:sbin/start-kafka.sh
(2)创建topic:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic topic-name
(3)启动producer:bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
(4)启动consumer:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic topic-name















07-18
 337
337
337
07-19
502
502
10-08
238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









