







一.概念
CAP理论

CAP理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- 一致性(C ) :保证所有节点上的数据始终同步。
- 可用性(A ):无论响应成功还是失败,每个请求都是有效的,并不会发生网络超时等情况。
- 分区容错性(P ) :系统内部(某个节点的分区)中丢失消息,系统也应该可以继续提供服务。一致性和可用性是分布式系统的固有属性。
总结:在互联网分布式环境中,P是不可能缺失,C和A只能出现一个。
BASE理论
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(StrongConsistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是指基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency)。
做不到100%可用,那么就做到基本可用。做不到强一致性,那么就做到最终一致性。
想要做到BASE,那么主要就是用这几个手段:中间状态(软状态)+重试(最终一致性+降级(基本可用)。
总结:BASE理论是对CAP的补充,是对AP模式下对数据一致性的阐述。
XA协议规范
X/Open 组织(即现在的 Open Group )定义了分布式事务处理模型。 模型中主要包括应用程序 ( AP )、事务管理器 (TM )、资源管理器(RM )、通信资源管理器(CRM )等四个角色。
一般,常见的事务管理器 ( TM )是交易中间件,常见的资源管理器(RM )是数据库,常见的通信资源管理器(CRM )是消息中间件。
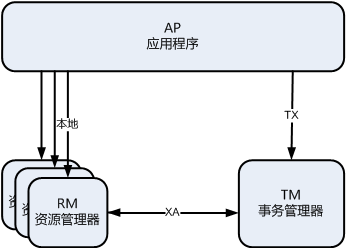
通常把一个数据库内部的事务处理,如对多个表的操作,作为本地事务看待。数据库的事务处理对象是本地事务,而分布式事务处理的对象是全局事务。
所谓全局事务,是指分布式事务处理环境中,多个数据库可能需要共同完成一个工作,这个工作即是一个全局事务,例如,一个事务中可能更新几个不同的数据库。对数据库的操作发生在系统的各处但必须全部被提交或回滚。此时一个数据库对自己内部所做操作的提交不仅依赖本身操作是否成功,还要依赖与全局事务相关的其它数据库的操作是否成功,如果任一数据库的任一操作失败,则参与此事务的所有数据库所做的所有操作都必须回滚。
总结:XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。
XA 接口函数由数据库厂商提供。二阶提交协议和三阶提交协议就是根据这一思想衍生出来的。可以说二阶段提交其实就是实现XA分布式事务的关键。
二.常见的分布式事务
CP(强一致性):
如果想要实现强一致性,那么就一定要引入一个协调者,通过协调者来协调所有参与者来进行提交或者回滚。所以,这类方案包含基于XA规范的二阶段及三阶段提交、以及支持2阶段提交。
2pc:
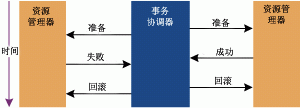
二阶段提交流程为,第一阶段(准备阶段),准备阶段不仅要通讯TM,还有执行本地事务机制。 第二阶段(执行阶段),执行阶段要进行commit和rollback操作。但是在第二阶段执行完毕前第一阶段的资源数据是阻塞锁定的,故会出现同步阻塞问题与单点故障问题。
问题?
1、同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
作为一个分布式的一致性协议,我们主要关注他可能带来的一致性问题的。2PC在执行过程中可能发生协调者或者参与者突然宕机的情况,在不同时期宕机可能有不同的现象。
解决方案及演进3PC。
3pc:

三阶段提交分为 CanCommit(可提交),PreCommit(预提交),DoCommit(执行提交)

CanCommit(可提交)阶段可能出现两种情况,一:参与者都ok,二:参与者不ok。
全都OK

不OK

PreCommit(预提交阶段)具体动作取决于CanCommit阶段的结果,因此可以分为两种情况 ,一:CanCommit 阶段成功,二:CanCommit阶段出现问题。
CanCommit成功,PreCommit也成功。

CanCommit成功,PreCommit进行本地事务出现失败。

DoCommit(执行阶段)具体动作取决于第二阶段 PreCommit 的结果,因此仍然分为两种情况,一: PreCommit成功,二:PreCommit失败
一: PreCommit成功

二:PreCommit失败

问题?
AP (最终一致性):
如果想要实现最终一致性,那么方案上就比较简单,常见的基于可靠消息的最终一致性(本地消息表、事务消息)、最大努力通知。
本地消息表:

主要思想是将分布式事务拆成两部分,参与者的本地事务及消息事务。本地事务在本地数据操作,消息事务依靠MQ中间件进行投递和消费。
大体过程如下:在发送消息之前,将写消息记录和本地写数据库操作放到同一个事务操作中,这样只要本地业务操作成功,消息记录也就记录到数据库中了。然后依靠本地消息记录,发送远程MQ消息调用。等待消费发进行消息处理,处理完成后更改本地消息记录状态。
问题?
1、2如果失败,因为在同一个事务中,所以事务会回滚,3及以后的步骤都不会执行。数据是一致的。
3如果失败,那么就需要有一个定时任务,不断的扫描本地消息数据,对于未成功的消息进行重新投递。
日
4、5如果失败,则依靠消息的重投机制,不断地重试。
6、7如果失败,那么就相当于两个分布式系统中的业务数据已经一致了,但是本地消息表的状态还是错的。这种情况也可以借助定时任务继续重投消息,让下游幂等消费再重新更改消息状态,或者本系统也可以通过定时任务去查询下游系统的状态,如果已经成功了,则直接推进消息状态即可。
事务消息MQ:

事务消息需要消息队列提供相应的功能才能实现,Kafka 和 RocketMQ 都提供了事务相关功能。
1.发送半消息:应用程序向RocketMQ Broker发送一条半消息,该消息在Broker端的事务消息日志中被标记为“prepared”状态。
2.执行本地事务:RocketMQ会通知应用程序执行本地事务。如果本地事务执行成功,应用程序通知RocketMQ Broker提交该事务消息。
3.提交事务消息:RocketMQ收到提交消息以后,会将该消息的状态从“prepared”改为'committed”,并使该消息可以被消费者消费。
4.回滚事务消息:如果本地事务执行失败,应用程序通知RocketMQ Broker回滚该事务消息,RocketMQ将该消息的状态从“prepared”改为“rollback”,并将该消息从事务消息日志中删除,从而保证该消息不会被消费者消费。
代码实现
// 生产者:发送半消息
Message message = new Message("transaction_topic", "transaction_tag", "Transaction Message".getBytes());
TransactionSendResult sendResult = producer.sendMessageInTransaction(message, null);
//生产者监听:
public class TransactionListenerImpl implements TransactionListener {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
// 执行本地事务逻辑
// 在这里编写执行本地事务的代码,包括数据库操作、服务调用等。
// 本地事务成功,返回 COMMIT_MESSAGE
return LocalTransactionState.COMMIT_MESSAGE;
} catch (Exception e) {
// 本地事务失败,返回 ROLLBACK_MESSAGE
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 消息回查逻辑
// 在这里编写消息回查的代码,根据本地事务的状态返回 COMMIT_MESSAGE、ROLLBACK_MESSAGE 或 UNKNOW。
}
}
//消费者:
public class MessageListenerImpl implements MessageListenerConcurrently {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
// 处理消息
// 在这里编写处理消息的代码,包括业务逻辑的执行等。
// 根据本地事务状态确认消息
if (transactionState == LocalTransactionState.COMMIT_MESSAGE) {
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} else if (transactionState == LocalTransactionState.ROLLBACK_MESSAGE) {
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}
问题?
--------未完继续----















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









