








 超级会员免费看
超级会员免费看

 本文详细介绍了如何使用pandas DataFrame的append方法添加数据,包括添加字典、Series和列表。讨论了ignore_index、verify_integrity和sort参数的作用,并给出了处理不同数据结构时的注意事项和示例。
本文详细介绍了如何使用pandas DataFrame的append方法添加数据,包括添加字典、Series和列表。讨论了ignore_index、verify_integrity和sort参数的作用,并给出了处理不同数据结构时的注意事项和示例。
官方文档介绍链接:append方法介绍
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
功能说明:向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加
- other:DataFrame、series、dict、list这样的数据结构
- ignore_index:默认值为False,如果为True则不使用index标签
- verify_integrity :默认值为False,如果为True当创建相同的index时会抛出ValueError的异常
- sort:boolean,默认是None,该属性在pandas的0.23.0的版本才存在。
append添加字典
import pandas as pd
data = pd.DataFrame()
a = {"x":1,"y":2}
data = data.append(a,ignore_index=True)
print(data)
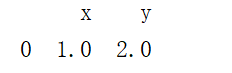
append添加series
如果不添加ignore_index=True,会报错提示TypeError: Can only append a Series if ignore_index=True or if the Series has a name,如果不添加ignore_index=True,也可以改成以下代码
import pandas as pd
data = pd.DataFrame()
series = pd.Series({"x":1,"y":2},name="a")
data = data.append(series)
print(data)
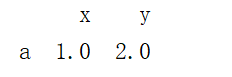
注意:当dataframe使用append方法添加series的时候,必须要设置name,设置name名称将会作为index的name。
append添加list
data = pd.DataFrame()
a = [1,2,3]
data = data.append(a)
print(data)

如果list是一维的,则是以列的形式来进行添加,如果list是二维的则是以行的形式进行添加的,如果是三维的则只添加一个值
data = pd.DataFrame()
a = [[[1,2,3]]]
data = data.append(a)
print(data)
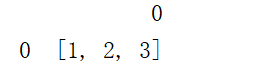
注意:在多次使用append方法追加数据的时候,可能会出现相同的index
data = pd.DataFrame()
a = [[1,2,3],[4,5,6]]
data = data.append(a)
a = [[7,8,9],[10,11,12]]
data = data.append(a)
print(data)

如果想要添加的index不出现重复的情况,可以通过设置ignore_index=True来避免
data = pd.DataFrame()
a = [[1,2,3],[4,5,6]]
data = data.append(a,ignore_index=True)
a = [[7,8,9],[10,11,12]]
data = data.append(a,ignore_index=True)
print(data)



















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











