








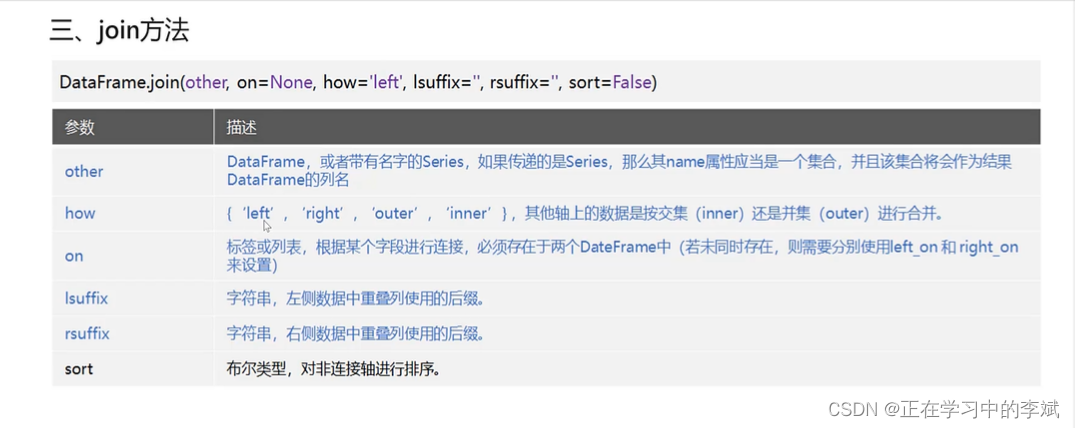
pandas 的 join 是基于 index 连接dataframe,主要用于基于行索引上的合并。
只要两个表列名不同,不加任何参数就可以直接用。如果两个表有重复的列名,需指定 lsuffix(左侧数据重列列使用的列名后缀), rsuffix 参数。其中参数的意义与 merge 方法基本相同。
https://blog.csdn.net/qq_35240689/article/details/125680279?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22125680279%22%2C%22source%22%3A%22qq_35240689%22%7D
df.join(other)
取交集
df.join(other, how='inner')
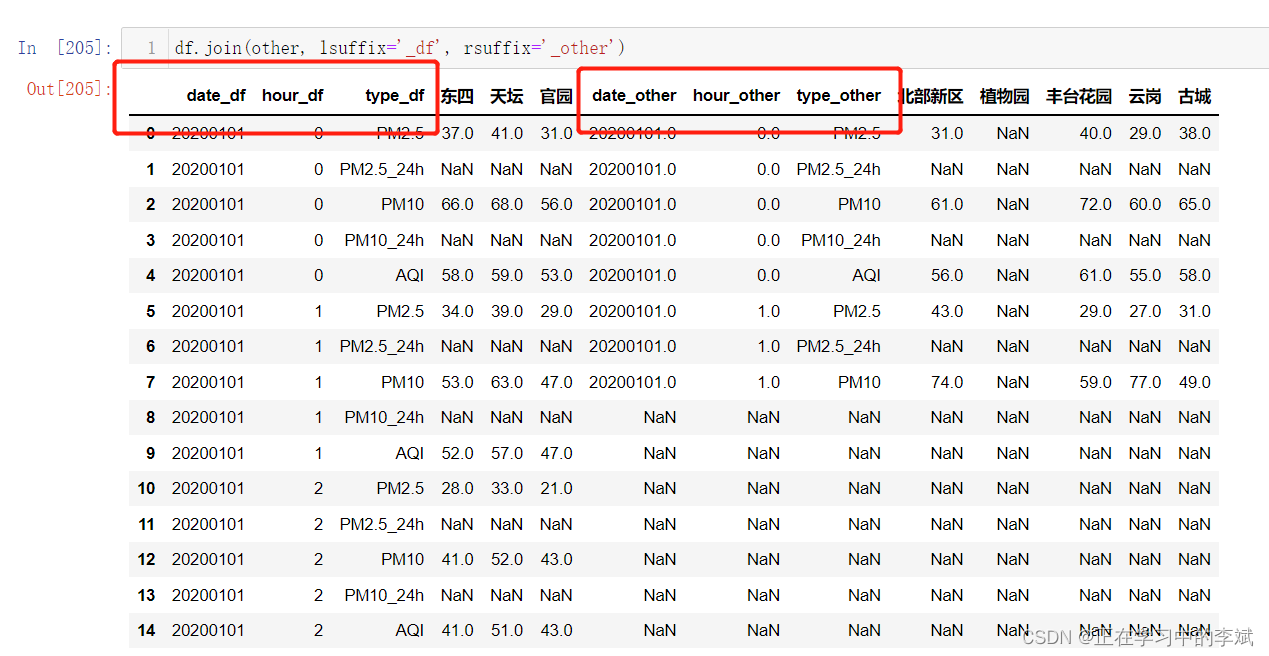
根据重叠的列[‘hour’, ‘date’, ‘type’]。此时需要设置重叠列合并后的后缀名
df.join(other, on=['hour', 'date', 'type'], how='inner',lsuffix='_df', rsuffix='_other')

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









