







前言
-
本文参考众多技术文章,选取个人认为比较易于理解的例子以及数学公式原理来解读集成学习相关的一些算法原理,作为学习笔记。
-
集成学习文章将会根据算法提出时间的顺序进行依次总结,最主要的是算法原理会越来越复杂,所以个人能力有限可能有些地方考虑不全面或者理解错了,所以总结文章仅供参考。
-
每篇文章单独介绍时候会尽可能提出更多围绕本篇算法相关的问题,但是实际需要用到才会理解更深,所以不全面的地方还望提出问题,共同进步。
-
GBDT原理与Adaboost算法都属于boosting家族所以有些类似,但是并不一样的思路,相对来说GBDT原理还是比较容易理解的
-
本文只能理解GBDT是怎么一个流程,是如何实现的,知道是怎么一回事的程度,具体如何实现可以看参考资料有的带实现代码,等GBDT代码篇会更深入的解释该算法(应该是很久以后了)。
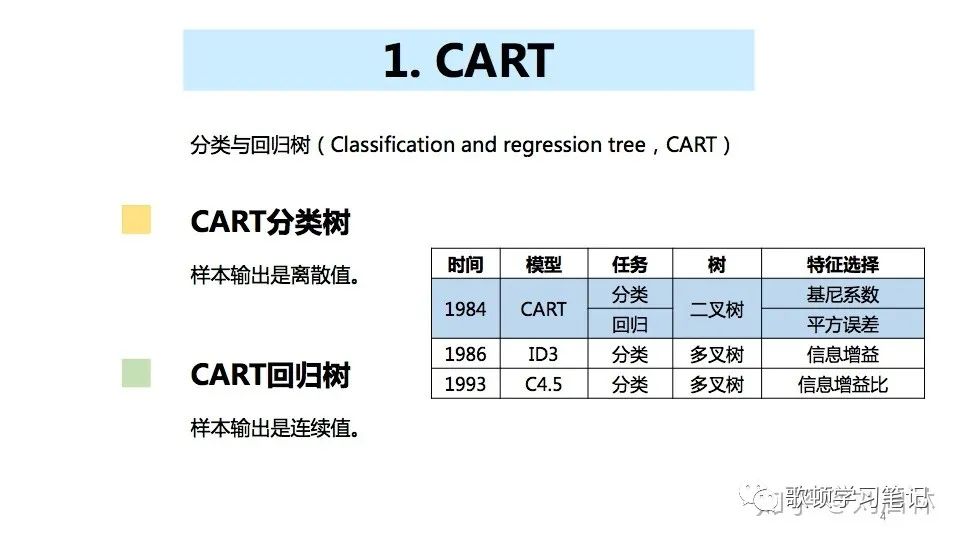
GBDT简介
-
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于boosting集成学习思想的加法模型,训练时采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。
-
GBDT涉及的知识点有:cart树(后续补充),集成学习(后续补充:),梯度下降(个人整理:https://zhuanlan.zhihu.com/p/473605654)

-
GBDT中得树用的是cart回归树,而非是cart分类树
-
什么是提升树?(理解GBDT的基础)
-
以决策树(回归树或者分类树)为基函数的提升方法称为提升决策树,简称提升树
-
提升树模型:可以表示决策树的加法模型
f M ( x ) = ∑ m = 1 M T m ( x ) (1.0) f_{M}(x) = \sum^M_{m=1}T_{m}(x)\tag{1.0} fM(x)=m=1∑MTm(x)(1.0) -
回归问题的提升树算法如下:
-
输入:训练数据集T={(x1, y1), (x2, y2), 。。。,(xn, yn)}
-
输出:提升树fm(x)
-
初始化f0(x) = 0
-
对m=1,2,。。。,M
-
计算残差(i即为数据集标号,m为决策树编号)
e m i = y i − f m − 1 ( x i ) (残差用e表示) e_{mi} = y_{i} - f_{m-1}(x_{i})\tag{残差用e表示} emi=yi−fm−1(xi)(残差用e表示) -
拟合残差e学习一个回归树,得到Tm(x),更新fm(x)
f m ( x ) = f m − 1 ( x ) + T m ( x ) (加法模型与前向分步算法实现训练) f_{m}(x) = f_{m-1}(x) + T_{m}(x)\tag{加法模型与前向分步算法实现训练} fm(x)=fm−1(x)+Tm(x)(加法模型与前向分步算法实现训练) -
然后得到公式(1.0)
-
提升树的训练优化目标
m i n s [ m i n c 1 ∑ x j ∈ R 1 ( y j − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( y i − c 2 ) 2 ] (2.0) min_{s} [min_{c1}\sum_{x_{j}\in{R_{1}}}(y_{j}- c_{1})^2 + min_{c2}\sum_{x_{i}\in{R_{2}}}(y_{i}- c_{2})^2]\tag{2.0} mins[minc1xj∈R1∑(yj−c1)2+minc2xi∈R2∑(yi−c2)2](2.0) -
其中:s是数据分切分点,那么(特征选择依据,平方误差最小)
R 1 = x ∣ x < = s , R 2 = x ∣ x > s (2.1) R1 = {x|x<=s},R2 = {x|x>s}\tag{2.1} R1=x∣x<=s,R2=x∣x>s(2.1) -
c1是R1内部使平方损失误差达到最小值(c2同理)
c 1 = 1 N ∑ x i ∈ R i y i (2.2) c1 = \frac{1}{N}\sum_{x_{i}\in{R_{i}}}y_{i}\tag{2.2} c1=N1xi∈Ri∑yi(2.2) -
N为Ri内的样本数
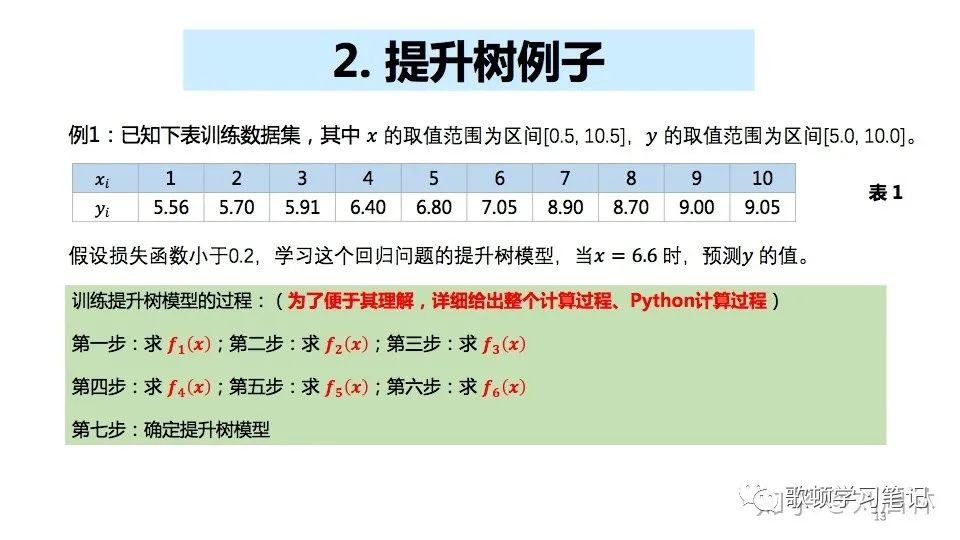
提升树的分割实例
-
提升树求训练数据的切分点:根据公式(2.2)算出c1与c2,继而根据公式(2.0)最小平方误差找到第一棵树的切分点

-
注:图中计算结果并非全都正确,为参考文章中例子的结果,本人只是求解参数c1与c2手动计算了结果作为验证
-
第一步:求解f1(x)
-
当s=6.5的时候,m(s)最小,那么我们就根据6.5这一切割点分隔数据集R1={1,2,3,4,5,6},R2={7,8,9,10},同上面求分割点一样,求得参数c1与c2(c1=6.24,c2=8.91),得到回归树T1(x)的表达式
T 1 ( x ) = { 1 , X 1 < 6.24 − 1 , X 1 > = 8.91 (3.0) T_{1}(x)=\begin{cases} 1,X_{1} < 6.24 \\ -1, X_{1} >= 8.91\end{cases}\tag{3.0} T1(x)={1,X1<6.24−1,X1>=8.91(3.0)
f 1 ( x ) = T 1 ( x ) (3.1) f_{1}(x) = T_{1}(x)\tag{3.1} f1(x)=T1(x)(3.1) -
用求得的f1(x)拟合训练数据,得到平方损失误差:

-
第二步:求解f2(x)
-
求解方法同第一步一样,但是训练数据变成了上述表中得到的残差作为拟合数据

-
同理进行第三步第四步第五步等直到(m表示第几步) L(y,fm(x))损失函数的值小于例题中设定的0.2停止训练,然后确认提升树模型

GBDT原理以及实例
-
与提升树不同的是,GBDT使用负梯度来模拟提升树每次迭代求解的残差,这也是GBDT的核心思想

-
那么如何得到GBDT的初始化弱学习器呢?
-
在上面提升树的回归问题中我们初始化f0(x) = 0,那么GBDT的f0(x)为(c同样为使得切分后区域内样本点的平方损失误差的最小值,对比提升树例子中的c,此时c就是自变量)
f 0 ( x ) = arg m i n c ∑ i = 1 N L ( y i , c ) (4.0) f_{0}(x) = \arg min_{c}\sum_{i=1}^NL(y_{i}, c)\tag{4.0} f0(x)=argminci=1∑NL(yi,c)(4.0) -
我们假设损失函数为平方损失。因为平方损失函数是一个凸函数,那么直接对c求导
- 注:也可以用其他损失函数,不同场景应用不同的损失函数,例题为了易懂选用了平方损失
∑ i = 1 N ∂ L ( y i , c ) ∂ c = ∑ i = 1 N ∂ ( 1 2 ( y i − c ) 2 ) ∂ c = ∑ i = 1 N ( c − y i ) (4.1) \sum_{i=1}^N\frac{\partial{L(y_{i}, c)}}{\partial{c}} = \sum_{i=1}^N\frac{\partial({\frac{1}{2}(y_{i}- c)}^2)}{\partial{c}} = \sum_{i=1}^N(c-y_{i})\tag{4.1} i=1∑N∂c∂L(yi,c)=i=1∑N∂c∂(21(yi−c)2)=i=1∑N(c−yi)(4.1)
- 注:也可以用其他损失函数,不同场景应用不同的损失函数,例题为了易懂选用了平方损失
-
令导数为0,即可得到
c = 1 N ∑ i = 1 N y i (4.2) c = \frac{1}{N}\sum_{i=1}^Ny_{i}\tag{4.2} c=N1i=1∑Nyi(4.2) -
所以初始化时,c取值就是所有训练样本值得均值,此时得到的初始学习器为:
f 0 ( x ) = c (4.3) f_{0}(x) = c\tag{4.3} f0(x)=c(4.3)
-
GBDT的训练
- 对比提升树例子就是将计算残差替换成了计算负梯度作为残差,初始化弱学习器的值就是训练集的均值,那么f1(x)求解时如下所示:
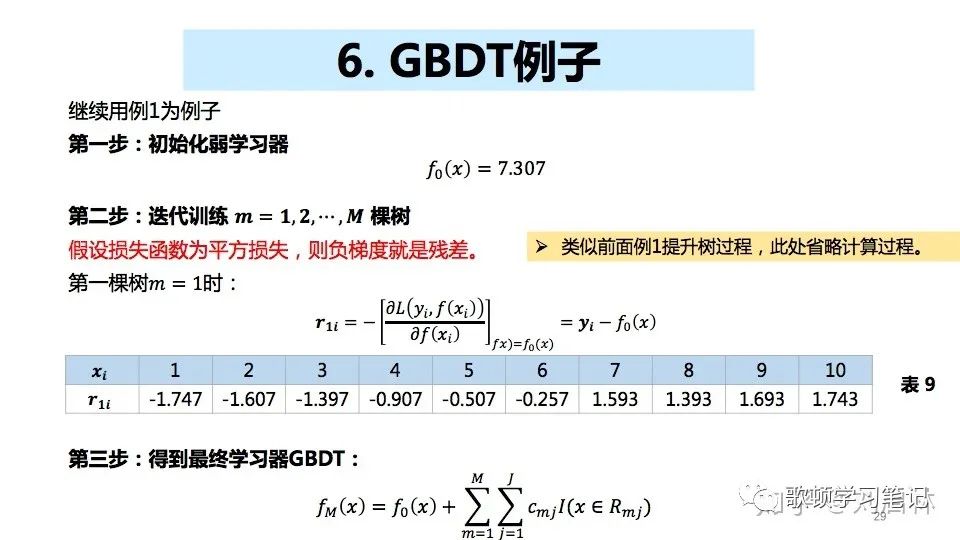
关于GBDT做回归任务
- 关于GBDT做回归,多分类任务暂不做详述,先理解GBDT回归算法作为基础了解GBDT的思想,实现原理,以后再补充
GBDT参考资料
文本叙述主要参考:
https://zhuanlan.zhihu.com/p/280222403
另一个例子很不错的blog(个人觉得例子没有文中例子易懂)
https://zhuanlan.zhihu.com/p/81016622
其他参考资料:
https://blog.csdn.net/joy_91/article/details/31346753
https://www.zhihu.com/question/332121327
https://blog.csdn.net/qfikh/article/details/102884930?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2aggregatepagefirst_rank_ecpm_v1~rank_v31_ecpm-1-102884930.pc_agg_new_rank&utm_term=GBDT平方损失的损失函数&spm=1000.2123.3001.4430















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











