







引言
-
本文是使用pytorch对循环神经网络RNN(Recurrent Neural Network)的代码实现,作为之前介绍RNN原理的一个代码补充。
-
本文代码相关介绍相对较为详细,也为自己的一个学习过程,对RNN的理解还是比较浅显,有错误的地方欢迎指正。
简述RNN结构
- 详细原理介绍可以参考上述链接,此处简述RNN结构实为方便理解后面代码分析部分。
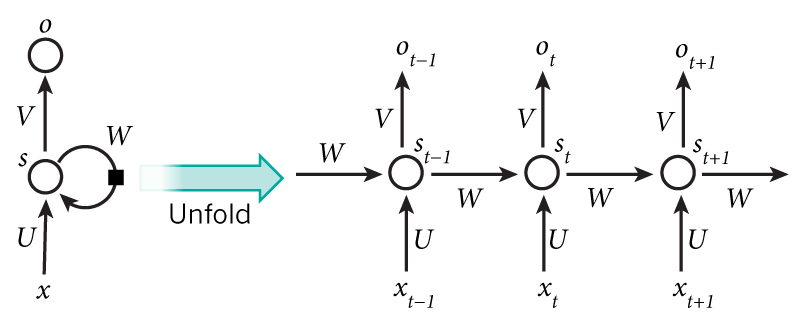
- 单向循环神经网络
- RNN的应用场景一般是当前输入与前一个输入是有联系的,所以下图x部分的参数会与
X_t-1有关- x:数据输入
- u:输入层到隐藏层的权重
- s:隐藏层的输出结果
- v:隐藏层到输出层的权重
- w:上一次的值
S_t-1作为这一次输入的权重矩阵
- 关于数学计算公式

- RNN的应用场景一般是当前输入与前一个输入是有联系的,所以下图x部分的参数会与
- 双向循环神经网络
- 单项循环神经网络只能作为与前一个数据建立连接,双向循环神经网络则可以同后一个数据建立连接
- 当然这个隐藏层只有一层,也可以多加几层构成深度循环神经网络


RNN实例
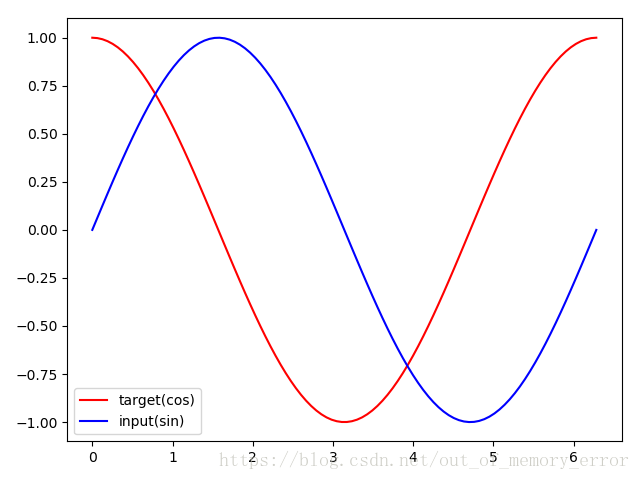
- 关于实现RNN的实例,我觉得有一个比较简单但是又比较符合RNN使用场景的序列数据例子,那就是正弦和余弦函数。
- 该例子来自参考资料1
- 以sin函数值作为输入,其对应的cos函数值作为输出,在相同sin值的情况下会对应不同的cos值的情况,这就是因为输出结果不仅要看输入数据,还要依赖前后值的信息,且FC,CNN就不适合该例子了。
Pytorch中RNN函数torch.nn.RNN()参数介绍
-
参数其实主要写input_size和hidden_size,其他的参数使用默认的即可,当然有特殊需要再设置

-
其重要参数解析如下
参数 含义 input_size 输入RNN的维度/输入x的特征数量 hidden_size 隐藏层节点数量/隐藏层的特征数量 num_layers RNN的层数 nonlinearity 指定激活函数使用tanh还是relu。默认是tanh bias 如果是 False , 那么 RNN 层就不会使用偏置权重 b_ih 和 b_hh, 默认: True batch_first 如果 True, 那么输入 Tensor 的 shape 应该是 (batch, seq, feature),并且输出也是一样(详见参3) dropout 如果值非零, 那么除了最后一层外, 其它层的输出都会套上一个 dropout 层 bidirectional 如果 True , 将会变成一个双向 RNN, 默认为 False -
主要是介绍了节点数的一些细节 参考资料2
-
主要介绍了数据维度的一些细节,介绍的挺详细的,可惜我还是没看懂,以后看懂了补上参考资料3
-
贴两个询问ChatGPT的截图,作为比对
RNN代码分析
- 具体print输出结果以及打印出来的结果见文章末尾的测试文件资源)
- 测试文件中还包含几个函数测试的结果,用来辅助分析代码
- 注:个人分析的注释可能也有错误,仅供参考,且数据维度的变换那里目前理解能力有限,思考了很久还是一知半解,待后续有能力完全解析再做补充。
- 该代码是他人写好的代码,并不是本人的实现代码,主要是确实个人能力不足目前难以自己写出来…
# encoding:utf-8
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
# 定义RNN模型(可以类别下方RNN简单测试代码理解)
class Rnn(nn.Module):
def __init__(self, input_size):
super(Rnn, self).__init__()
# 定义RNN网络
## hidden_size是自己设置的,貌似取值都是32,64,128这样来取值
## num_layers是隐藏层数量,超过2层那就是深度循环神经网络了
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=32,
num_layers=1,
batch_first=True # 输入形状为[批量大小, 数据序列长度, 特征维度]
)
# 定义全连接层
self.out = nn.Linear(32, 1)
# 定义前向传播函数
def forward(self, x, h_0):
r_out, h_n = self.rnn(x, h_0)
# print("数据输出结果;隐藏层数据结果", r_out, h_n)
# print("r_out.size(), h_n.size()", r_out.size(), h_n.size())
outs = []
# r_out.size=[1,10,32]即将一个长度为10的序列的每个元素都映射到隐藏层上
for time in range(r_out.size(1)):
# print("映射", r_out[:, time, :])
# 依次抽取序列中每个单词,将之通过全连接层并输出.r_out[:, 0, :].size()=[1,32] -> [1,1]
outs.append(self.out(r_out[:, time, :]))
# print("outs", outs)
# stack函数在dim=1上叠加:10*[1,1] -> [1,10,1] 同时h_n已经被更新
return torch.stack(outs, dim=1), h_n
TIME_STEP = 10
INPUT_SIZE = 1
LR = 0.02
model = Rnn(INPUT_SIZE)
print(model)
# 此处使用的是均方误差损失
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
h_state = None # 初始化h_state为None
for step in range(300):
# 人工生成输入和输出,输入x.size=[1,10,1],输出y.size=[1,10,1]
start, end = step * np.pi, (step + 1)*np.pi
# np.linspace生成一个指定大小,指定数据区间的均匀分布序列,TIME_STEP是生成数量
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32)
# print("steps", steps)
x_np = np.sin(steps)
y_np = np.cos(steps)
# print("x_np,y_np", x_np, y_np)
# 从numpy.ndarray创建一个张量 np.newaxis增加新的维度
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
# print("x,y", x,y)
# 将x通过网络,长度为10的序列通过网络得到最终隐藏层状态h_state和长度为10的输出prediction:[1,10,1]
prediction, h_state = model(x, h_state)
h_state = h_state.data
# 这一步只取了h_state.data.因为h_state包含.data和.grad 舍弃了梯度
# print("precision, h_state.data", prediction, h_state)
# print("prediction.size(), h_state.size()", prediction.size(), h_state.size())
# 反向传播
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
# 更新优化器参数
optimizer.step()
# 对最后一次的结果作图查看网络的预测效果
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.show()
另外一种构建RNN的方法
- 除了上面介绍的torch.nn.RNN()外,还有RNNCell方法,使用方法如下:
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)hidden = cell(input, hidden)- input_size与hidden_size与上面的参数介绍的含义是一致的,但是输入类型不一样。
- 和RNN不同的是RNN cell要自己写处理序列的循环,个人通俗理解就是,比如要处理3个句子,每个句子10个单词,每个单词用20长度的向量表示,如果使用
nn.RNN(),那输出的tensor的shape应该是[10,3,20],而使用nn.RNNCell()需要将序列上的每个时刻分开处理,即送入的tensor的shape是[3,100],然后将该单元运行10次,灵活的代价当然就是比较麻烦。 - 关于
hidden_size输入shape与input_size同样有变化,概括来说就是(可以看上面代码的具体解析那有关于维度的详细分析) - input:batch_size*input_size
- 输入的hidden: batch_size*hidden_size
- 输出的hidden: batch_size*hidden_size
其他参考资料
- 数据集为MNIST使用RNN实现(未测试,找资料时候看到了仅供参考)
- RNN两种实现方式的区别以及代码实现比较
- 本文代码详细测试过程文件(待上传)
- Github代码文件资源
















 1583
1583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











