







python爬虫入门练习,爬豆瓣网(感谢豆瓣网--双手合十
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import os
def padouban():
path='D:\\picture_files'
if os.path.exists(path):
print("路径已存在,无需创建")
else:
print("路径不存在,需创建路径,正在创建")
os.mkdir(path)
movieurl=['https://movie.douban.com/top250/?start={}&filter='.format(i) for i in range(0,250,25)] #一共250页,最好别写这么多
count = 0
for url_bianliang in movieurl:
#Xpath='//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[3]'
headers={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-coding":"gzip, deflate, br",
"Accept-language":"zh-CN,zh;q=0.9,en-GB;q=0.8,en-US;q=0.7,en;q=0.6",
"Cache-Control":"max-age=0",
"Connection":"keepalive",
"Refer":"https://www.baidu.com/link?url=CZenQ6ne8mqB7tawlE1eqM9hqcQ9LTyU_XzndOrk3GwSPiBcNnUpJ4x0egm5AkiR&wd=&eqid=f22a72d70003713a000000036256b4a3",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
time.sleep(10)
requests.packages.urllib3.disable_warnings()
r=requests.get(url_bianliang,headers=headers,verify=False)
soup=BeautifulSoup(r.content,'html.parser')
li=soup.find('ol',class_='grid_view').find_all('img')#找的图片,也可以换成名字或者其他的
for i in li:
src_rs=i.get('src')#获取图像标签 总
finalsrc=requests.get(src_rs) #获取每个的图像标签
print(finalsrc)
if src_rs.split(".")[-1] == 'webp':
src_name=src_rs.split('/')[-1].split('.')[0]+'.jpg' #图片改个格式
print(src_name+'正在下载...') #写入文件 即是 下载
with open(path+'/'+src_name,'wb') as f:
f.write(finalsrc.content)
f.close()
count = count + 1
if count < 250:
print('第 ' + str(count) + ' 页,下载完成')
else:
print('250页,全部下载完成啦!')
if __name__ == '__main__':
padouban()
#------
#print(soup.prettify()) 分行
#翻页抓取入门想看看的,可以直接复制运行。
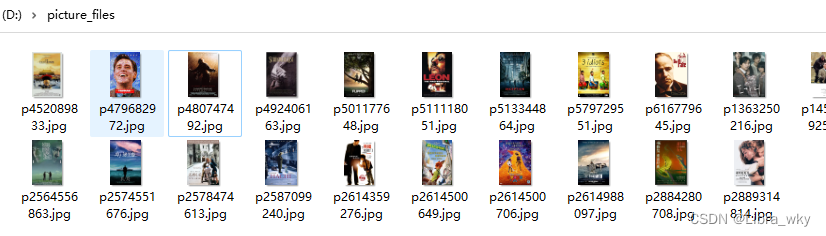
效果大概就这这样子
---------------------------------------------------------------------------------------------















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









