







MapReduce 里的键值对必须实现可序列化,以支持在网络中传输。
值必须实现 Writable接口,而键因为在Reduce阶段有排序任务,所以必须实现WritableComparable<T> 接口。

现在想自定义数据类型,则自己写类来实现WC<T>接口即可。
Writable接口有两个函数

write是序列化函数,即向其他人传送类时使用,readFields则在接受此类时调用来反序列化。
参数DataInput和DataOutput是Java中的接口。
DataOutput 接口用于将任意 Java 基本类型转换为一系列字节,并将这些字节写入二进制流。
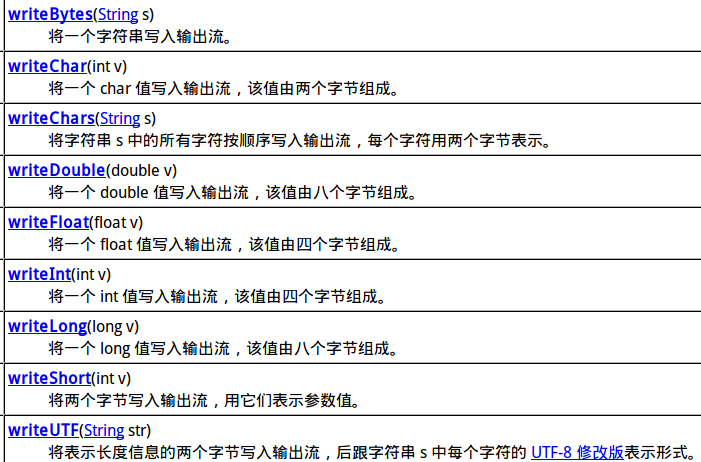
下图为DataOutput的方法。这里已经定义了基本类型的序列化,而我们要做的是把类做序列化。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class Edge implements WritableComparable<Edge>{
private String FromNode; // 出发地
private String ToNode; // 目的地
@Override
public void readFields(DataInput in) throws IOException {
FromNode = in.readUTF();
ToNode = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(FromNode);
out.writeUTF(ToNode);
// out 可直接写入二进制流
}
@Override
public int compareTo(Edge i) {
return (FromNode.compareTo(i.FromNode)!=0)
?FromNode.compareTo(i.FromNode)
:ToNode.compareTo(i.ToNode);
//按出发地的字典序排列,如果相同则按照目的地的字典序排列。
}
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









