







 本文介绍了基于Python的PLA(Perceptron Learning Algorithm)线性分类器的实现。PLA作为简单的单层前馈神经网络,旨在将二维数据集上的点进行分类。文章详细阐述了数据集的构建、误差函数的定义,并提供了完整的实现代码。
本文介绍了基于Python的PLA(Perceptron Learning Algorithm)线性分类器的实现。PLA作为简单的单层前馈神经网络,旨在将二维数据集上的点进行分类。文章详细阐述了数据集的构建、误差函数的定义,并提供了完整的实现代码。
线型分类器(PLA),可以看做是一个最简单的单层前馈神经网络。PLA的目的可以简要概括为:通过训练,将一系列二维平面上的点分开。
1、数据集
这里采用带标签【0,1】的二维数据集:
dataset = np.array([ # 此处用x,y形式的array来存储数据
((- 0.4, 0.3), 0),
((- 0.3, - 0.1), 0),
((- 0.2, 0.4), 0),
((- 0.1, 0.1), 0),
((0.6, - 0.5), 0), # 非线性分割点,后面可根据情况删掉
((0.8, 0.7), 1),
((0.9, - 0.5), 1),
((0.7, - 0.9), 1),
((0.8, 0.2), 1),
((0.4, - 0.6), 1)])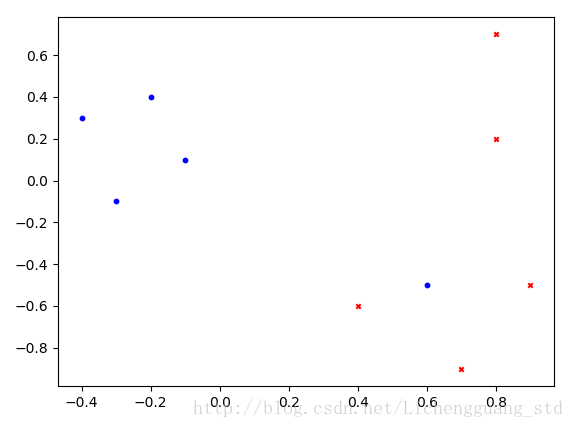
2、误差函数
定义误差函数的目的在于确定当前的权重向量是否需要修正。这里,本算法的误差确定较为粗略,仅根据权重向量与数据集向量的点积值正负来确定。
3、完整代码
import numpy as np
import matplotlib.pyplot as plt
from matp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2114
2114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









