






文章目录
- 文章来源
- 论文的背景
- 论文的目的
- 研究的内容
- 贡献与创新
- 相关工作:
- 研究方法:
- 实验以及结果
- 全新的专业名称
- 高维与低维数据:
- Embeddings:嵌入:
- embeddings from ImageNet models
- ImageNet:
- deep representations from ImageNet classification without adaptation to the target distribution.:
- Memory bank:
- GANs:对抗生成网络
- autoencoding models:自动编码模型
- 自适应,无自适应:
- the multiscale nature of deep feature representations:
- paths:补丁,图像的局部区域
- 补丁级特征(Patch-Level features)
- greedy coreset subsampling:贪婪 核心集二次抽样
- 鲁棒性:
- 高斯分布:正态分布
- 特征工程与预训练
- 特征(Feature):
- 隐藏特征(Hidden Feature):
- 特征表示(Feature Representation):
- 特征向量
- 特征图 feature map
- 特征切片(feature slice)
- 接受野(receptive field)
- 自适应平均池化(Adaptive Average Pooling)
- MVTec AD
- 图片级异常检查与分割异常检测的区别
- F1-optimal threshold(f1最优阈值)
- approximate nearest neighbour search(近似最近邻搜索,ANN)
- learning of a set of basis proxies
- subsampling target percentage ptarget(子采样目标百分比)
- 分割性能
文章来源
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 14318-14328
来自2022年的IEEE/CVF计算机视觉与模式识别会议。
论文的背景
- 工业异常检查中普遍存在的冷启动问题。在训练集中都是正常的图片,模型很容易捕获到正常图像的特征,但是很难捕获到异常缺陷的样本。
- 当前对缺陷进行分类是十分困难的,因为缺陷有大有小,不易察觉
- 目前,有人利用ImageNet分类的深度表征而且无需自适应,它正常样本与测试样本进行特征匹配。但这种来自ImageNet训练的高层次抽象特征与工业的抽象特征不太匹配
- 表现最好的方法是将ImageNet模型的嵌入与异常模型结合起来。
论文的目的
- 解决冷启动问题。
- 构建能够自动适用于多个任务的系统
研究的内容
提出了PatchCore。
通过:
1.在测试时,最大化提取正常数据的信息
2.减少ImageNet上的类别偏差
3.保持高的推理速度
来解决问题。
- PatchCore使用了中层网络区块特征(mid-level network patch
features),这使得它可以在高分辨率下工作,并且对ImageNet类的偏向最小。 - 同时利用了局部邻域的特征聚合,保证了有足够的空间保留上下文。在测试时,PathCore就可以最高效地利用可用的正常上下文。
- 而且PatchCore还引入了greedy coreset subsampling来减少区块级记忆库的冗余,减低存储空间与推理时间。
贡献与创新
贡献
- 提出了PatchCore模型,在只使用正常样本训练的情况下就可以达到一个十分优秀的性能。为解决工业异常检测中的冷启动问题提供了一个优秀的方案。
- 提出了 Locally aware patch features(邻域感知的补丁级特征),保留了更多的补丁局部上下文信息,能够更好地捕捉图像中的局部异常区域。
创新点
- 提出了 Locally aware patch features(邻域感知的补丁级特征),能够在检测过程中更好地利用图像的局部信息
- 使用了贪心核心集选择技术与随机线性投影来缩小记忆库的大小,同时保留了主要的特征信息。
相关工作:
文章在这部分总结了当时工业异常检测的一些先进方法,研究方向以及该领域的总体情况。
正常(名义)数据的特征学习
目前多数模型通过对正常数据进行训练,提取和学习到正常数据的特征模式,然后在实际应用中识别出偏离这些模式的数据作为异常。这可以通过自动编码模型实现。
而且为了更好地估计正常特征分布,领域内也提出了不少方法:
- 基于高斯混合模型的扩展: 高斯混合模型 GMM是一种概率模型,假设数据是由多个高斯分布混合而成的。通过使用GMM,可以更好地捕捉正常数据的复杂特征分布。
- 生成对抗训练目标:生成对抗网络(GAN)
- 对预定义物理增强的不变性:Invariance towards predefined physical augmentations
在训练过程中对数据进行各种物理增强(如旋转、缩放等),并要求模型对这些增强不敏感,从而提高模型对正常数据特征的鲁棒性。 - 隐藏特征对重构再引入的鲁棒性:Robustness of hidden features to reintroduction of reconstructions
将重构后的数据再次输入模型,并确保隐藏特征保持一致,以增强模型对正常数据特征的鲁棒性。 - 原型记忆库: Prototypical memory banks
使用记忆库存储正常数据的原型特征,模型在检测新数据时可以参考这些原型,从而更准确地判断数据是否异常。 - 注意力引导: Attention-guidance
通过注意力机制,引导模型关注数据中的重要部分,从而提高对正常数据特征的学习效果。 - 结构化目标: Structural objectives
通过设计特定的结构化目标函数(例如考虑数据的空间结构或时间序列结构),来增强模型对正常数据特征的捕捉能力。 - 受限表示空间: Constrained representation spaces
通过对特征表示空间进行约束,使得正常数据的表示更加紧凑,从而提高模型对正常数据分布的估计能力。
几种无监督特征学习的方法
- 生成对抗网络:
- 预测预定义的几何变换: Learning to predict predefined geometric transformations
通过让模型预测应用于数据的几何变换(如旋转、平移、缩放等),可以促使模型学习数据的结构和特征。在训练过程中,首先对输入数据应用预定义的几何变换,然后让模型预测这些变换。模型在学习如何识别变换的过程中,也学会了捕捉数据的关键特征。 - 规范化流: 规范化流是一类概率模型,通过一系列可逆变换将简单的分布(如高斯分布)映射到复杂的数据分布。这些变换的可逆性保证了模型可以在数据空间和潜在空间之间相互转换。
异常检测的方法:
在拥有正常特征表示与新的特征表示时,需要判断新的特征表示是否为异常,以下为常用方法:
-
重构误差:通过自编码器或其他重构模型对测试数据进行重构,然后计算原始数据与重构数据之间的误差。自编码器训练阶段仅使用正常数据,模型学会如何重构正常数据。检测阶段,输入新数据并计算重构误差,异常数据的重构误差通常较大。
-
与最近邻的距离(Distances to k Nearest Neighbours):文章使用了这个方法
计算新测试数据与正常数据中k个最近邻样本之间的距离。如果距离较大,表示新数据与正常数据有显著差异,可能是异常数据。首先计算所有正常数据样本的特征表示,然后对于每个新的测试样本,找到其在特征空间中k个最近的正常样本,计算距离并进行判断。 -
单类分类模型的微调(Finetuning of One-Class Classification Models)
工业异常检测
在工业异常检测中,最近的研究表明使用大型外部图像数据集(如ImageNet)进行预训练的模型拥有最先进的性能,即使不对数据进行任何适应。
据此,出现了一些可以更好地重复使用预训练特征的方式,例如SPADE与PaDiM,PatchCore是对这两种方法的改进。它们都是无监督的学习方法
SPADE
SPADE依赖于使用在大型自然图像数据集(如ImageNet)上预训练的特征,并通过记忆库和k最近邻(kNN)方法进行细粒度的异常检测。
下面将对所使用的技术进行介绍:
- 预训练特征提取:
SPADE使用一个在大型数据集上预训练的深度学习模型(如ResNet、VGG等)来提取图像的特征。这些特征捕捉了图像中的高级模式和结构。
预训练模型的中间层输出的特征被用作名义(正常)数据的特征表示 - 记忆库 :
记忆库是一个存储从正常图像中提取的各种特征层次的存储空间。每个正常图像的特征向量都被存储在记忆库中。
记忆库的目的是保留和管理大量的正常特征,以便在检测新图像时可以进行快速匹配和比较。 - k最近邻(kNN):
k最近邻算法需要计算新图像特征向量与记忆库中特征向量之间的距离。常用的距离度量方法包括欧几里得距离和余弦相似度。
对于每个新的特征向量,找到距离最近的k个特征向量。这些最近邻特征向量代表了数据的局部特征分布。
通过分析新图像特征向量与其k最近邻特征向量的距离分布,可以判断新图像是否包含异常。 - 细粒度检测:
SPADE不仅能检测整个图像是否异常,还能定位异常在图像中的具体位置。
具体步骤如下:- 先将输入图像划分为多个小块(patches),每个小块代表图像的一个局部区域。对每个小块进行特征提取,得到每个小块的特征向量。
- 对每个小块的特征向量,使用k最近邻算法在记忆库中找到最相似的k个特征向量。计算每个小块特征向量与其k最近邻特征向量的距离。
- 对每个小块,根据其与k最近邻特征向量的距离计算异常评分。如果距离较大,则该小块可能包含异常。
PatchCore借鉴了SPADE,利用了SPADE的kNN来进行异常检测,但与SPADE又有所不同。
记忆库:
- 在SPADE中,记忆库存储的是整个图片的全局特征向量。
- 在PatchCore种,记忆库在构建时就将图像划分为多个补丁,每个补丁都单独提取特征向量,存储在记忆库中。这种方法通过邻域感知的补丁级特征捕捉更多的名义上下文信息
- 而且PatchCore为了减少储存,还利用了核心集(coreset)采样方法,对记忆库中的补丁级特征进行采样,也就是之后的greedy coreset subsampling。
检测阶段:
- SPADE会将输入的图像划分为多个patches,对每个补丁单独提取特征,并与记忆库中的全局特征向量进行比较。
- PatchCore也会将图像划分为多个patches,然后直接与记忆库中的补丁级特征进行比较,也是使用kNN
PaDim
PatchCore中,补丁级的异常检测与异常分割与PaDim有关,目的是提高异常检测的灵敏度。下面介绍所使用的技术:
-
局部约束的特征袋方法(Locally Constrained Bag-of-Features, LCBF):一种用于图像和补丁级特征表示的方法。该方法通过提取图像的局部特征,并将这些特征表示为特征袋,从而捕捉图像的细粒度信息。用来估计补丁级别特征分布的均值和协方差矩阵。其中:
- 特征袋 :从图像中提取多个局部特征,并将这些特征表示为一个集合(袋)。不考虑特征的空间位置,将所有提取的特征看作一个无序的集合。
- 局部约束:考虑了特征的局部空间信息。即,特征不仅仅作为一个无序的集合存在,还保留了它们在图像中的相对位置或局部上下文信息。
在运行中,先会将图片切分为补丁并使用预训练模型提取出各自的特征向量。然后对每个补丁进行建模,通常包括计算均值和协方差矩阵,以表示特征的分布。最后将所有补丁的特征表示为一个特征袋,这个特征袋包含了整个图像的局部特征信息。
-
马氏距离度量:它是一种度量方法,用于计算数据点与分布之间的距离。它考虑了数据的协方差结构,使得在有相关性的高维数据中,能够更准确地度量点与分布的差异。
PaDim在构建记忆库时,会使用局部约束的特征袋方法来估计每个补丁特征的分布(均值和协方差矩阵),并存储这些分布参数。
而在检测阶段,会先提取待输入图像的补丁级特征,计算每个补丁特征与记忆库中特征分布的马氏距离,进行异常检测。
PatchCore借鉴了PaDim的思想,也使用预训练模型从图像中提取补丁级特征,而且保留了补丁的局部上下文信息。
但也对PaDim进行了改进:
- 在构建记忆库时,存储的是经过核心集采样的补丁级特征。可以减低储存
- 在异常检测时,使用了kNN方法,更加高效。
研究方法:
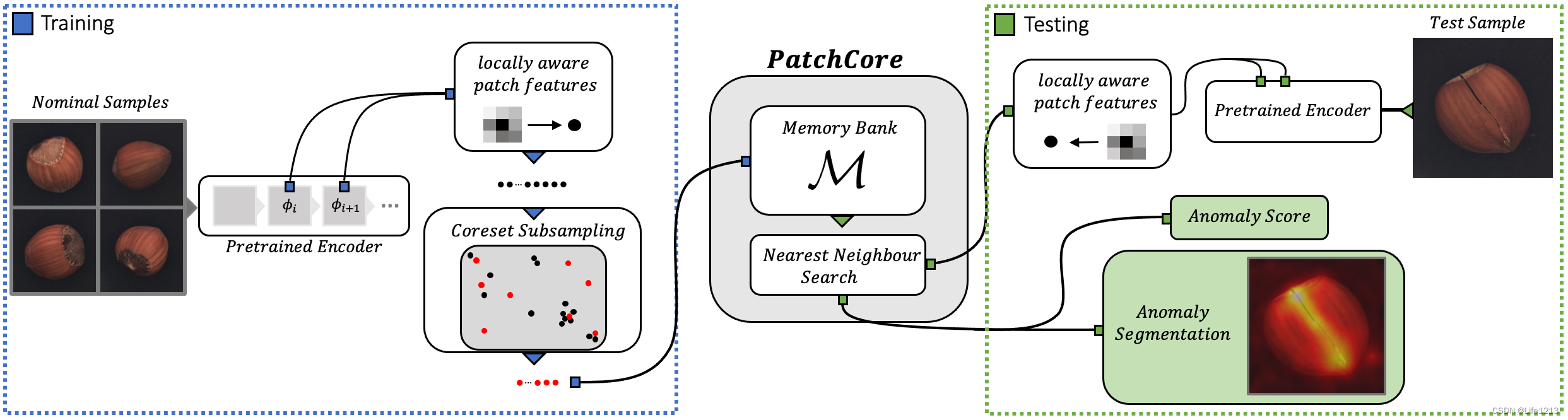
整体分为两个部分,一个是训练部分,一个是测试部分。
训练部分
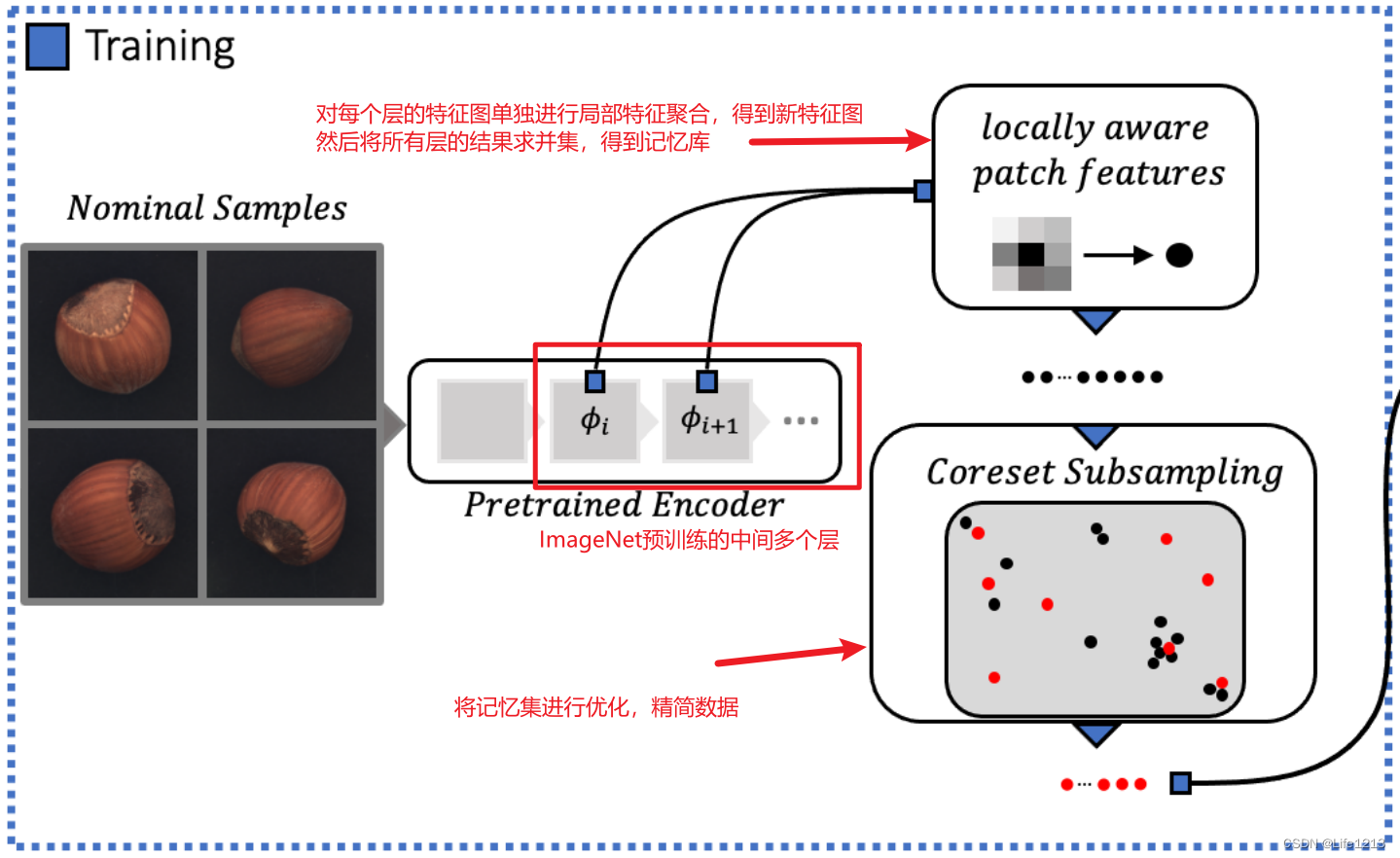
关键是通过正常样本得到PathCore记忆库。
Locally aware patch features 局部特征提取
patchcore从ImageNet的预训练模型中选取哪些特征层构建记忆库 𝑀,同时为了增强patchcore对小空间差异的鲁棒性以及增大其感受野而对patchcore进行特征局部邻域聚合。
先介绍各个参数:
- x:当前样本
- X N X_N XN:正常样本的集合
- X T X_T XT:测试样本的集合
- ϕ i , j = ϕ j ( x i ) \phi_{i,j}=\phi_j(x_i) ϕi,j=ϕj(xi):样本Xi在预训练模型 ϕ \phi ϕ的第 j 层的feature map 特征图
- ϕ i , j ∈ R c ∗ × h ∗ × w ∗ \phi_{i,j} \in \mathbb{R}^{c^* \times h^* \times w^*} ϕi,j∈Rc∗×h∗×w∗:该特征图是属于深度(通道数)为c的,高度为h的且宽度为w*的特征图集合。
- ϕ i , j ( h , w ) = ϕ j ( x i , h , w ) ∈ R c ∗ \phi_{i,j}(h, w) = \phi_{j}(x_i, h, w) \in \mathbb{R}^{c^*} ϕi,j(h,w)=ϕj(xi,h,w)∈Rc∗:该特征图中位于(h,w)的切片,并且这切片提取于深度c*。R代表深度为c*的切片的集合。
PatchCore使用了中间层的特征代表,而没有使用更深层次的。有两个原因:
- 会丢失过多的局部正常学习。
- 预训练网络中的深层和抽象特征倾向于自然图像分类任务,这与工业异常检测任务不匹配
- 因为冷启动带来的问题,缺陷特征很少,很难推测出来。
接下来介绍patchcore如何实现局部特征聚合,这部分包含了很多公式,下面为这些公式与其对应的解释:
当补丁特征的接受野足够大时,效果会更加好。虽然可以通过加深层数来获得更大的接受野,但会导致补丁特征变得更加特定于imagenet,因此与手头的异常检测任务不太相关,同时训练成本增加,有效的特征映射分辨率下降。
为了解决这个,要将周围的补丁特征聚合起来,生产局部感知特征(locally aware features),首先要定义领域。
定义领域:
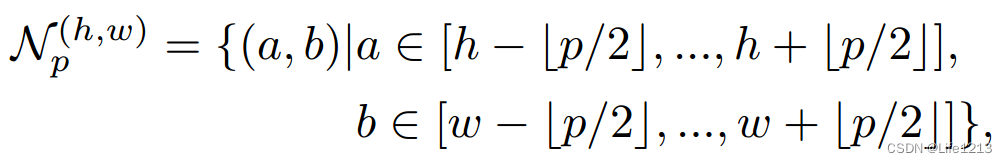
其中
N
p
(
h
,
w
)
N^{(h,w)}_p
Np(h,w)代表着位置 (ℎ,𝑤)附近大小为 𝑝×𝑝 的邻域。
聚合领域内的补丁特征,生成locally aware features:
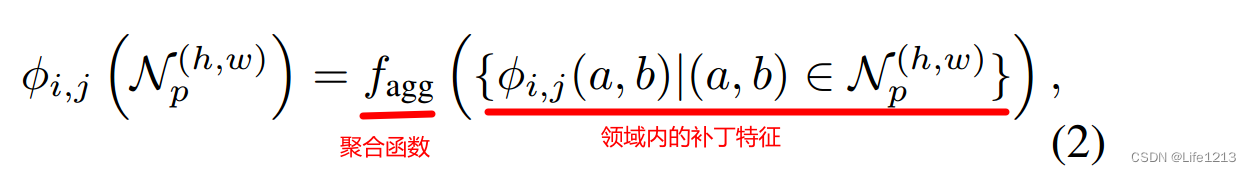
其中
f
a
g
g
f_{agg}
fagg是聚合邻居的函数,在PatchCore中使用自适应平均池化(adaptive average pooling)作为聚合函数。
自适应平均池化类似于对每个特征图进行局部平滑,结果是在位置 (h,w) 处生成一个具有预定义维度d的特征表示(这是由自适应平均池化生成的)。
这个聚合过程对特征图的所有位置 (h,w) 都进行,这样可以保留特征图的分辨率。
局部感知特征集合
在一个特征图中,所有局部感知特征集合表示为:
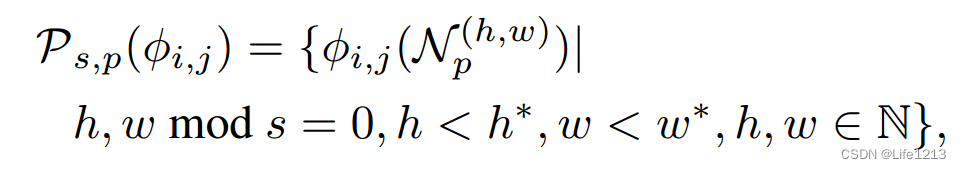
其中S为步幅,每次补丁移动多少。
为了保留特征的通用性和空间分辨率,PatchCore只使用中间层 j 与 j+1来实现。
首先要计算出
P
s
,
p
(
ϕ
i
,
j
+
1
)
\mathcal {P_{s,p}}(\phi_{i,j+1})
Ps,p(ϕi,j+1)。然后通过线性重采样
P
s
,
p
(
ϕ
i
,
j
+
1
)
\mathcal {P_{s,p}}(\phi_{i,j+1})
Ps,p(ϕi,j+1),使得
∣
P
s
,
p
(
ϕ
i
,
j
)
∣
|\mathcal {P_{s,p}}(\phi_{i,j})|
∣Ps,p(ϕi,j)∣与
∣
P
s
,
p
(
ϕ
i
,
j
+
1
)
∣
|\mathcal {P_{s,p}}(\phi_{i,j+1})|
∣Ps,p(ϕi,j+1)∣的大小相同,方便聚合。
最后将
P
s
,
p
(
ϕ
i
,
j
+
1
)
\mathcal {P_{s,p}}(\phi_{i,j+1})
Ps,p(ϕi,j+1)中的特征与第 j 层所对应的补丁级特征进行聚合。
聚合后的特征保留了第 j 层的高分辨率信息,同时增强了第 j 层特征的表达能力。
记忆库生成
由每个正常样本生成的
P
s
,
p
(
ϕ
i
,
j
)
\mathcal {P_{s,p}}(\phi_{i,j})
Ps,p(ϕi,j)来构成记忆库。
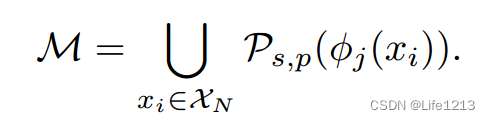
Coreset-reduced patch-feature memory bank(生成核心集)
通过局部感知特征构成了记忆库,但这样生成的记忆库会耗费大量的存储,因此需要进行精简。在尽量保持性能的同时大幅减少其存储需求并提高性能。
随着
X
N
X_{N}
XN 的不断增大,记忆库𝑀也在不断增大,从而导致评估新测试数据的推理时间和所需存储空间都显著增加。
所以通过找到一个𝑀的子集𝑀c,使𝑀c能够保持对原始记忆库的良好表示,同时极大缩小其对存储的需求以及推理时间。
但是随机采样会丢失M中正常特征的重要信息。因此使用了 coreset subsampling mechanism。
下面是提取Mc的公式,将进行介绍:
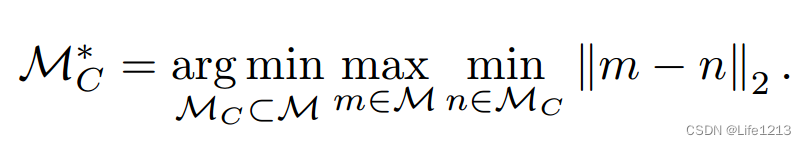
- min n ∈ M C ∥ m − n ∥ 2 \min_{n \in \mathcal{M}_C} \| m - n \|_2 minn∈MC∥m−n∥2:得到M中每一个点m到Mc的距离,也就是M中每个点到Mc中最近的点n的距离。一般点与集合的距离用点与集合中与它最近的点的距离来代表。
- max m ∈ M min n ∈ M C ∥ m − n ∥ 2 \max_{m \in \mathcal{M}} \min_{n \in \mathcal{M}_C} \| m - n \|_2 maxm∈Mminn∈MC∥m−n∥2:M中的点m 到Mc的距离集合中的最大值,也就是M中离Mc最远的点到Mc的距离。
- M C ∗ = arg min M C ⊂ M \mathcal{M}_C^* = \arg \min_{\mathcal{M}_C \subset \mathcal{M}} MC∗=argminMC⊂M:调整Mc,使得M中点到Mc的距离集合中最大值最小化的Mc集合。
这个公式让M中的点到Mc的距离中的最大值尽可能小。
M中的点到Mc的距离中的最大值决定了M中任一点到Mc的距离不会大于这个值,只要将这个值缩小了,就能让Mc中的点与M的点更加靠近,更能代表M。
而使用 PatchCore-n% 代表从M中抽取了 n%的数据作为核心集。
但直接使用这个公式求解 M c ∗ M_c^* Mc∗是一个NP难问题,因此贪心方法。并且为了进一步减低 M c M_c Mc的选择时间,使用了random linear projections(随机线性投影) ψ \psi ψ,将元素的维度从d降到d*。
算法代码如图所示:

l
l
l:核心集大小
ψ
\psi
ψ:随机线性投影
其中 arg max m ∈ M − M C min n ∈ M C ∥ ψ ( m ) − ψ ( n ) ∥ 2 \arg \max_{m \in \mathcal{M} - \mathcal{M}_C} \min_{n \in \mathcal{M}_C} \|\psi(m) - \psi(n)\|_2 argmaxm∈M−MCminn∈MC∥ψ(m)−ψ(n)∥2用于寻找核心集,其中:
- min n ∈ M C ∥ ψ ( m ) − ψ ( n ) ∥ 2 \min_{n \in \mathcal{M}_C} \|\psi(m) - \psi(n)\|_2 minn∈MC∥ψ(m)−ψ(n)∥2:全部不属于Mc的点m计算自己与Mc中的最近的点n之间的距离,也就是全部不属于 M c M_c Mc的点与 M c M_c Mc的距离。
- a r g max m ∈ M − M C arg \max_{m \in \mathcal{M} - \mathcal{M}_C} argmaxm∈M−MC:在不属于 M c M_c Mc的点中,与 M c M_c Mc距离最远的点加入 M c M_c Mc。
经过 l l l次,会生成一个大小为 l l l的核心集代替原始记忆库,生成新的记忆库 M M M。
检测阶段
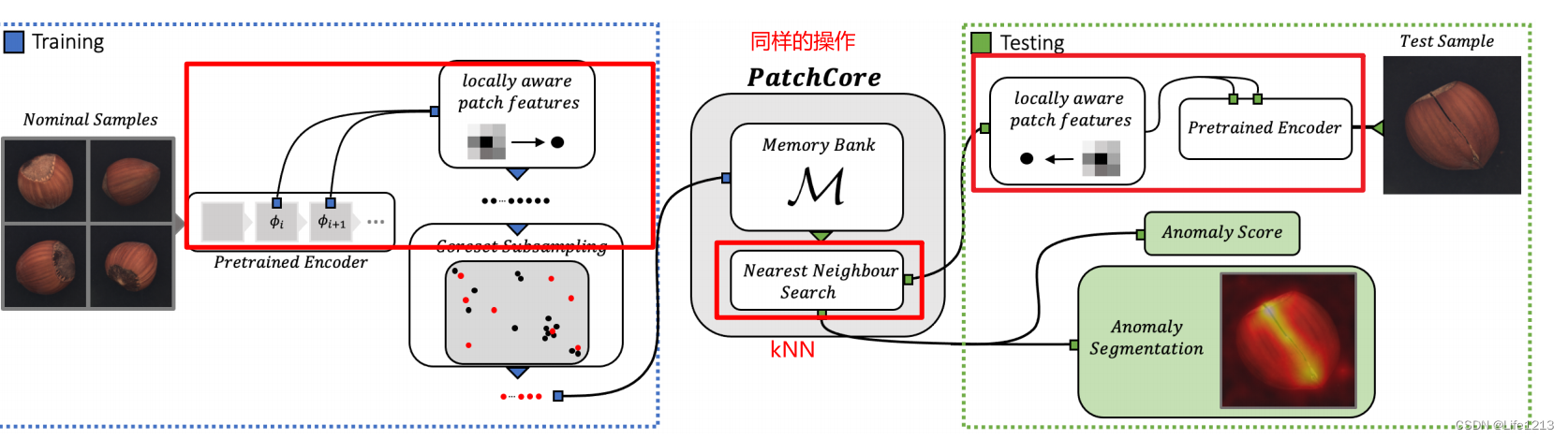
输入要检测的图片后,首先要做的就是提取特征,生成测试图像的局部感知特征集合:
P
(
x
t
e
s
t
)
=
P
s
,
p
(
ϕ
j
(
x
t
e
s
t
)
)
\mathcal {P}(x^{test}) = \mathcal {P_{s,p}}(\phi_{j}(x^{test}))
P(xtest)=Ps,p(ϕj(xtest))
使用名义补丁特征记忆库 𝑀 来估计测试图像
x
t
e
s
t
x^{test}
xtest的图像级异常得分 s。
计算
P
(
x
t
e
s
t
)
\mathcal {P}(x^{test})
P(xtest)中每个补丁级特征(pathes features)
m
t
e
s
t
m^{test}
mtest 与记忆库M中最近的特征
m
m
m之间的距离,并且取出其中的最大值,作为最大距离得分
s
∗
s^*
s∗。
首先要得到所需的
m
t
e
s
t
,
∗
m^{test,*}
mtest,∗ 与
m
∗
m^*
m∗,来计算
s
∗
s^*
s∗。
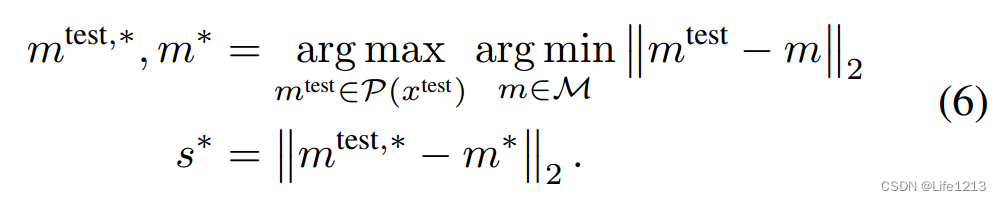
- arg min m ∈ M \arg \min_{\mathcal{m} \in \mathcal{M}} argminm∈M:在记忆库中找到与 m t e s t m^{test} mtest距离最小的补丁特征 m*。
- arg max m t e s t ∈ P ( x t e s t ) \arg \max_{\mathcal{m^{test}} \in \mathcal {P}(x^{test})} argmaxmtest∈P(xtest):在所有测试补丁中找到与M距离最大的补丁特征 m t e s t , ∗ m^{test,*} mtest,∗。
其实可以将公式6进行分解。
- m ∗ = arg min m ∈ M ∣ ∣ m t e s t − m ∣ ∣ 2 m^*=\arg \min_{\mathcal{m} \in \mathcal{M}}||m^{test}-m||_2 m∗=argminm∈M∣∣mtest−m∣∣2
- m t e s t , ∗ = arg max m t e s t ∈ P ( x t e s t ) ∣ ∣ m t e s t − m ∗ ∣ ∣ 2 m^{test,*}=\arg \max_{\mathcal{m^{test}} \in \mathcal {P}(x^{test})}||m^{test}-m^*||_2 mtest,∗=argmaxmtest∈P(xtest)∣∣mtest−m∗∣∣2
也就是找到在测试补丁特征集中,与记忆库最远的补丁级特征
m
t
e
s
t
,
∗
m^{test,*}
mtest,∗以及其在M中最近的特征
m
∗
m^*
m∗。
并通过
m
t
e
s
t
,
∗
m^{test,*}
mtest,∗与m*计算欧几里得距离得到 最大距离分数
s
∗
s^*
s∗。
最后要计算图像级异常得分
s
s
s:
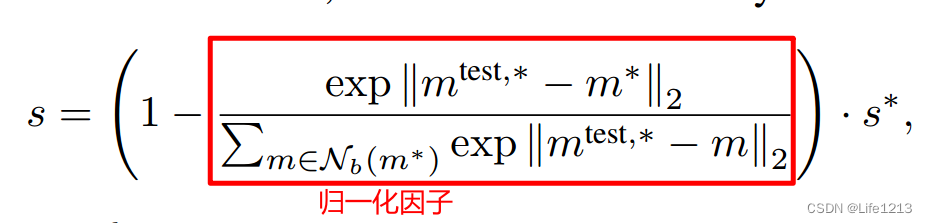
- exp(x): e x e^x ex。
- N b ( m ∗ ) N_b(m^*) Nb(m∗):在记忆库M中,与m*最近的b个补丁级特征。
归一化因子:对最大距离得分s*进行缩放,从而使得异常得分 𝑠 更加鲁棒。
- 归一化因子将 m t e s t , ∗ m^{test,*} mtest,∗分别与m*的距离和与m*的邻域补丁的距离进行比较。如果m*本身为一个异常点(即它与其邻域中的补丁特征的距离也较大),则归一化因子会减小,进而增加最终的异常得分。
- 而且通过这种归一化,可以更好地考虑局部上下文的信息,使得异常得分不仅仅依赖于一个单一的距离值,而是综合考虑了邻域特征的行为。这种方式提高了异常检测的鲁棒性。
其中在计算图像级异常得分
s
s
s的过程中,就已经计算了每个补丁的异常得分
s
(
m
t
e
s
t
)
s(m^{test})
s(mtest)。
s
(
m
t
e
s
t
)
=
∣
∣
m
t
e
s
t
−
m
∗
∣
∣
2
s(m^{test})=||m^{test}-m^*||_2
s(mtest)=∣∣mtest−m∗∣∣2:在得到
m
t
e
s
t
,
∗
m^{test,*}
mtest,∗的过程中,每个
m
t
e
s
t
m^{test}
mtest都计算了自己的异常得分,而
m
t
e
s
t
,
∗
m^{test,*}
mtest,∗就是异常得分最高的补丁特征。
因此可以写为
m
t
e
s
t
,
∗
=
arg
max
m
t
e
s
t
∈
P
(
x
t
e
s
t
)
(
s
(
m
t
e
s
t
)
)
m^{test,*}=\arg \max_{\mathcal{m^{test}} \in \mathcal {P}(x^{test})}(s(m^{test}))
mtest,∗=argmaxmtest∈P(xtest)(s(mtest))。
计算完图像级异常得分 s 后,就可以根据过程中所得到的补丁级异常得分来生成分割图。
- 将每个补丁级异常得分映射到图像中对应的位置,由于补丁可能存在重叠区域,需要累计这些得分。
- 同时为了使得分割图的分辨率与原始图像匹配,还使用了**双线性插值(Bi-linear Interpolation)**来进行采样,将分割图从较低分辨率上采样到与原始图像相同的分辨率。
- 最后使用高斯核对分割图进行平滑处理。高斯平滑处理有助于减少噪声,使得结果更加平滑和连贯。而且通过高斯平滑处理,结果图像中的异常区域更加清晰,便于人眼观察和解释。
实验以及结果
为了研究工业异常检测的性能,大部分实验MVTec异常检测上进行的。使用了MVTec AD数据集。
同时为了研究更加专业的工业异常检测,还使用了MTD数据集。
而且要强调了PatchCore对非工业图像的潜在实用性,使用了mSTC。
评价指标
图像级异常检测性能是通过area under the receiveroperator curve(AUROC)来评价。而在MVTec上计算class-average AUROC 。
而分割性能则是通过 像素级 AUROC 与 PRO指标来评价。PRO指标考虑了connected anomaly components(连通异常组件)的重叠和恢复程度。
- 连通异常组件:表示那些在空间上相互连接的异常像素组成的区域。
- 重叠:检测出的异常区域与真实异常区域的重叠程度。
- 恢复:检测结果对真实异常区域的覆盖程度。好的恢复度表示大部分真实异常区域被正确检测出来。
MVTec AD的异常检测
图像级异常检测
Table 1.

测试不同模型在MVTec AD下的AUROC得分、错误数以及分类错误数。
其中分类错误的总数是在 a F1-optimal threshold(f1最优阈值) 下假阳性和假阴性预测的总和。
从图中可知,在各个指标中PatchCore-25%都达到了最优。
而且值得注意的是,错误从PaDim的2.1%降到了0.9%,这代表着相对于PaDim,误差率减少了57%=(2.1-0.9)/2.1。
分割性能


测试不同模型下分割性能,用像素级AUROC与PRO指标来衡量。
有表中数据可知,PatchCore的分割性能是最优的。
推理时间
MVTec AD上每幅图像的平均推理时间和(图像级AUROC,像素级AUROC、PRO)
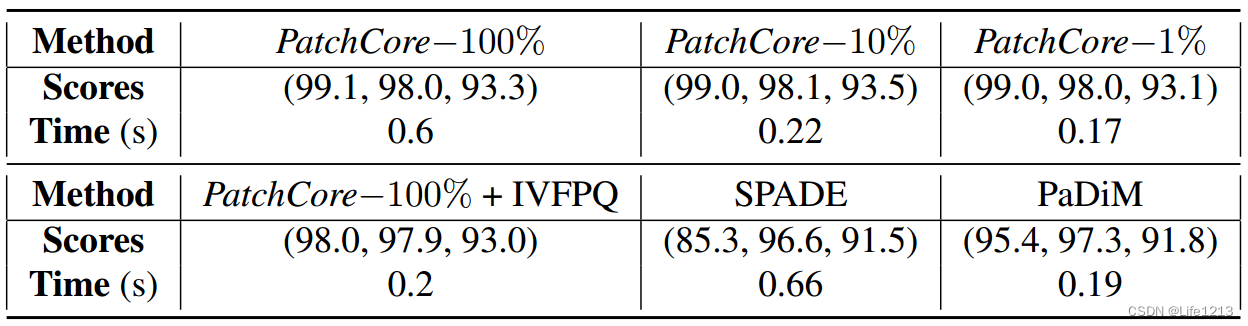
比较了不同PatchCore-n%以及SPADE、PADiM的推理时间与得分。
其中PatchCore-100%(未对M进行采样)的推理时间已经少于SPADE。而且通过采样可以比PaDim更快,同时拥有优秀的异常检测性能。
最后,使用了approximate nearest neighbour search(近似最近邻搜索,ANN)来减少推理时间,但虽然异常检测性能减低了,但推理时间依然不如PatchCore-1%。
消融实验(Ablation Study)
评估PatchCore中各项技术与组件的重要性与影响,主要是靠逐步移除或替换系统中的某些部分并观察性能变化。
局部感知补丁特征
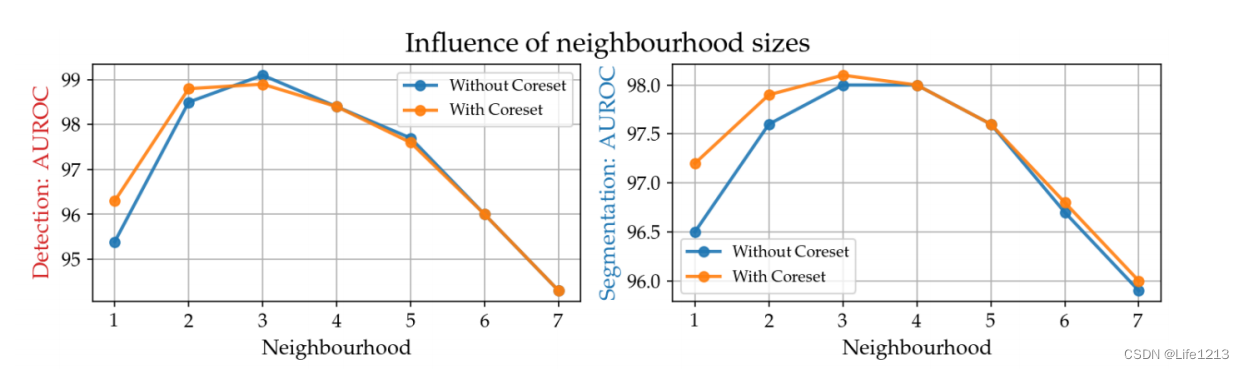
研究邻域的大小
p
p
p 对异常检测性能的影响,包含使用了核心集与无核心集。
由图可以看出,当
p
=
3
p=3
p=3时性能达到最优
PatchCore所使用的特征层次
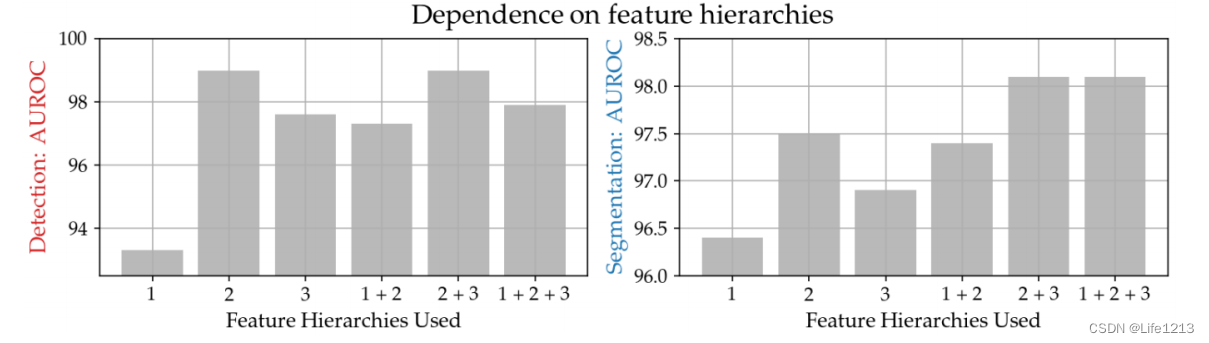
研究来自不同层级的特征对异常检测性能的影响。
由图可以看出,使用了第2/3层的特征的性能最好。
核心集采样的重要性
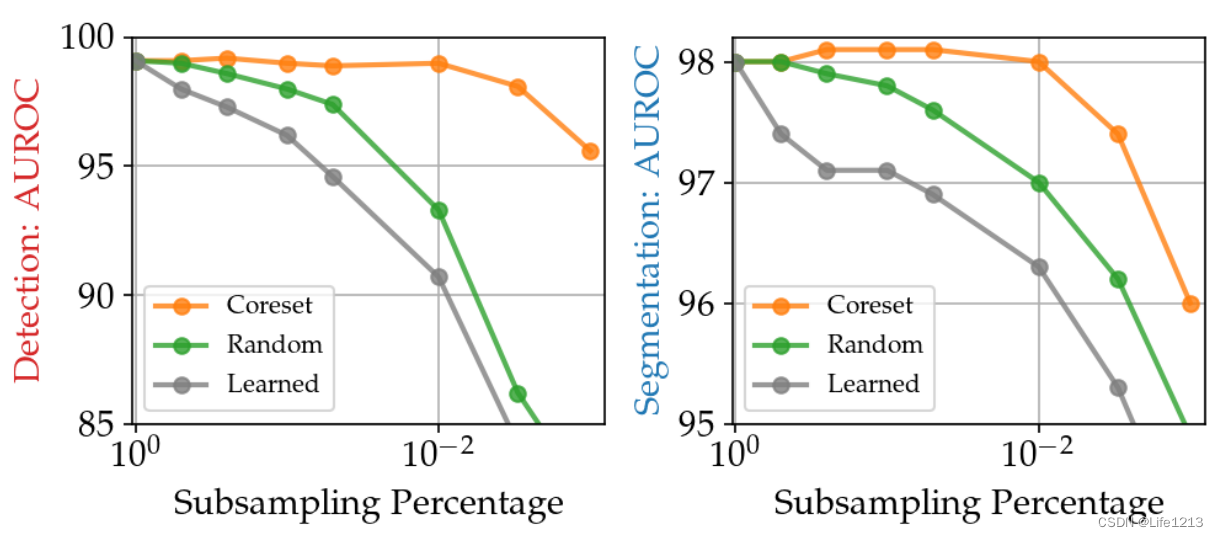
研究贪心核心集采样、随机采样以及学习一组基础代理(basis proxies)这三种方法的性能。
由图可知,使用了核心集采样的性能明显优于其他。
在无核心集采样下,其性能与使用了核心集的媲美,后者的M大小要小两个数量级。
而且使用了核心集可以减少记忆库的冗余。并且使用不同的步幅s,对性能也有影响。
少量数据的异常检测
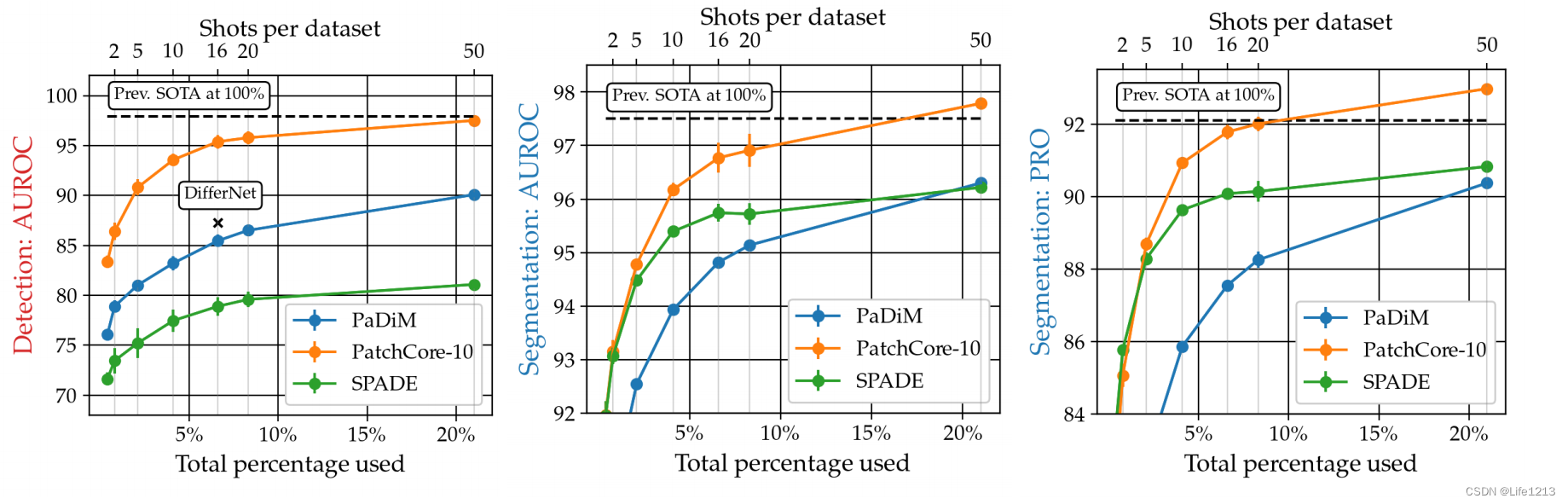
这幅图片是SPADE、PaDim与PaChore-10之间在MVTec AD的数据量增加时的性能对比,可以发现PaChore在少量数据的情况下也可以有优秀的性能,明显优于其他两种。
其他测试

使用了mSTC与MTD这两个数据集来测试性能。
由图可知,PatchCore在这两个数据集的性能都是最优的。
全新的专业名称
高维与低维数据:
数据中所有值的所有可能性的个数之和是数据的维度,如一张图片由10个像素,每个像素有256种颜色,因此维度为10*256。
对于高维数据,可以通过降维来降低维度,将高维数据映射到低维数据上。映射到二维或三维后,可以利用图像来表示数据的分布来分析数据。
Embeddings:嵌入:
嵌入是指将高维数据转换为低维的特征向量的方法。这些向量表示能够捕捉数据中的重要特征和模式
而在图像中要获得嵌入,首先要训练深度学习模型,逐渐提取出高层特征。然后预训练模型的中间层输出的特征向量就是嵌入。
嵌入的基本思想是通过一种方式将复杂的数据映射到一个可以被模型理解和处理的空间中。
embeddings from ImageNet models
在ImageNet数据集上预训练的模型中提取的嵌入
ImageNet:
ImageNet是一种数据集,而不是神经网络模型。
是一个图片分类数据集,分成1000类,每类大约1000多张图片。
deep representations from ImageNet classification without adaptation to the target distribution.:
从ImageNet分类任务中获得的深度表示(或特征),而且直接应用于目标任务,而不对这些特征进行任何针对目标任务的数据分布调整或适应
这些深度表示是通过在大型数据集ImageNet上预训练的深度神经网络(如卷积神经网络CNN)所学习到的特征。
Memory bank:
就是记忆提取到的特征的集合;
冷启动:
out-of-distribution:
GANs:对抗生成网络
两个网络相互竞争。一个生成,一个判断
一个叫做生成器网络( Generator Network),它不断捕捉训练库中的数据,从而产生新的样本。
另一个叫做判别器网络(Discriminator Network),它也根据相关数据,去判别生成器提供的数据到底是不是足够真实。
autoencoding models:自动编码模型
是一类无监督学习模型,主要用于学习数据的低维特征表示和重构原始输入数据。
包含编码器与解码器:
- 编码器:对原始数据进行编码会得到特征向量(嵌入),将高维输入数据映射到低维的隐含空间。通常由一系列神经网络构成
- 解码器:将低维的隐含表示重新映射回高维的输入数据,对嵌入进行解码会到重构输出。
训练过程:
- 对正常数据进行编码,得到嵌入;Z=f(X),并且使其能够学习到正常图像的特征。
- 对嵌入进行解码,得到重构输出;X’=F(Z)
- 得到X与X’之间的误差。
- 利用误差来训练模型
检查过程:
- 对新数据进行编码与解码,得到新数据的重构输出X’
- 计算原图像与重构后的图像之间的误差
- 若误差小则为正常,反之为异常
自适应,无自适应:
the multiscale nature of deep feature representations:
paths:补丁,图像的局部区域
补丁级特征(Patch-Level features)
从图像的局部区域(补丁)提取的特征。通常使用卷积神经网络(CNN)的卷积层来提取这些补丁的特征。
补丁级特征能够保留更多的名义上下文信息,通过邻域感知的方式捕捉补丁之间的关系,提高检测性能。
greedy coreset subsampling:贪婪 核心集二次抽样
coreset subsampling原理是从原始数据中提取一小部分的样品,来代表整个数据集的特征。该样本称为coreset。

通过本算法,可以用较小的数据集来代替原始数据集,从而在不明显降低数据集质量的情况下减少计算量。
鲁棒性:
系统或模型在面对不确定性、干扰或变化时,仍能保持其性能和功能的能力。
高斯分布:正态分布
GMM在异常检测中的使用:通过GMM得到正常数据的分布。对于新数据,若数据在正常数据的分布中属于低概率的部分,则可能是异常。
特征工程与预训练
特征工程:对数据进行预处理与特征提取的过程,为了生成更好的特征表示。
涉及从原始数据中提取、选择、转换和创建特征。
预训练: 在大规模数据集上预先训练一个模型,然后将该模型应用到特定任务中。
特征工程与预训练之间的联系与区别
- 联系:两者都涉及特征提取。
- 区别:
- 特征工程是手工设计或通过简单算法从原始数据中提取和转换特征。
- 预训练是在大规模数据集上预先训练深度学习模型,利用预训练模型的高级特征。
特征(Feature):
从数据中提取的属性或变量,用于描述数据的某些方面,并作为机器学习模型的输入。可以是直接从数据中提取的原始属性(原始特征),也可以是通过特征工程从原始数据中提取的高级特征(工程特征)。
隐藏特征(Hidden Feature):
由深度学习模型的隐藏层生成的特征表示,是对输入数据的高层次抽象。通过模型的学习过程自动生成的。
特征表示(Feature Representation):
特征在特定表示空间中的编码方式或表达形式,也就是决定如何表示该特征。特征表示决定了特征如何在模型中被使用和处理。
特征可以有不同的表示方式,例如向量、矩阵、张量等。可以表示不同种类的特征,可以是原始特征、工程特征,也可以是隐藏特征。
注意,特征表示不一定是从模型中得到的:
可以直接从数据中提取特征,并将其转换为特征向量或其他特征表示。这些特征可以是原始特征或通过特征工程生成的特征。
也可以通过预训练的模型,提取高层次的特征表示和特征向量。
特征向量
特征向量是特征表示的一种具体形式,特别适合机器学习模型的输入。
分为全局特征向量与局部特征向量。
全局特征向量:每张图像通常被表示为一个全局特征向量。这是通过对整个图像进行处理,从中提取出一个高层次的表示。这个全局特征向量能够捕捉图像的整体信息。
局部特征向量(补丁级特征): 对于一些更细粒度的任务,每张图像通常会被划分为多个小块 (patches),每个小块提取一个特征向量。这些局部特征向量能够捕捉图像的局部信息。
特征图 feature map
指卷积神经网络(CNN)各层输出的特征表示。
通道数(深度、维度):在卷积神经网络中,每个卷积层会生成多个特征图,这些特征图的数量就是通道数。每个通道对应一个卷积核的输出,捕捉图像的不同特征。
高度:特征图的高度,表示特征图的垂直尺寸。
宽度:特征图的宽度,表示特征图的水平尺寸。
特征切片(feature slice)
指的是从特征图中提取的一部分,具体来说就是在特定维度上的一个或多个切片。
接受野(receptive field)
感受野指的是网络某一层的一个神经元在输入图像上的感知范围,即这个神经元所“看到”的图像区域。
分为 局部接受野 和 全局接受野。
- 局部接受野:每个卷积核只与输入的一小部分区域进行卷积操作,这个小区域称为局部感受野。
- 全局接受野:网络越深,越靠后的层感受野越大,因为它们的神经元通过前面多层卷积逐步整合了更大区域的信息。因此,最后一层的神经元感受野可以覆盖整个输入图像,称为全局感受野。
自适应平均池化(Adaptive Average Pooling)
它能够将输入特征图的大小调整为指定的输出大小。自适应池化可以根据需要灵活地调整输出特征图的大小,而不受输入特征图大小的限制。
MVTec AD
用于进行工业异常检测模型的训练与测试,包含15个子数据集。每个子数据集被分为仅正常的训练数据和包含正常和异常样本的测试集
图片级异常检查与分割异常检测的区别
图片级异常检测是判断整个图像中是否包含异常,而不关心异常的位置与大小等具体信息,颗粒度大。适用于快速筛查。
分割异常检测是精确检测与定位图像中的异常区域,颗粒度小,关注每个像素的异常检测精度。
F1-optimal threshold(f1最优阈值)
approximate nearest neighbour search(近似最近邻搜索,ANN)
是一种在高维空间中寻找近邻点的技术,旨在快速找到与查询点最接近的数据点。在高维数据空间中进行精确的最近邻搜索非常耗时和计算资源。
learning of a set of basis proxies
学习一组基础代理(basis proxies):
- 基础代理:代表原始数据集或特征空间的一小部分数据点或特征。通过学习这些代理,模型能够在减少计算和存储资源的同时,仍然捕捉到数据的主要特征和结构。
subsampling target percentage ptarget(子采样目标百分比)
指的是要从原始数据集中选择的样本比例
分割性能
评估图像分割算法在特定任务中表现好坏的一种度量。分割性能通常用于评估算法在将图像划分为不同区域或对象时的准确性和精确度。
在异常检测中,评价标识的异常区域是否准确。















 6389
6389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









