







更简洁的代码
if else
# Q: 从服务器返回的响应可能是文本, 也可能是 None, 请判断当为 None 时, 转换为 ''.
# == Good ==
if response is None:
data = ''
else:
data = response
# == Better ==
data = '' if response is None else response
# == Best ==
data = response or ''
海象运算符 (Python 3.8)
# Q: 书架上有 a 本书, 用户借了 b 本, 请分别打印 a, b 和 b / a 的百分比值
# == Bad ==
print('书架上有 {} 本书, 用户借阅 {} 本, 占比 {}%'.format(
len(total_books),
len(rent_books),
round(len(rent_books) / len(total_books) * 100, 2)
))
# == Good ==
a = len(total_books)
b = len(rent_books)
print('书架上有 {} 本书, 用户借阅 {} 本, 占比 {}%'.format(
a, b, round(b / a * 100, 2)
))
# == Better (Python 3.8) ==
print('书架上有 {} 本书, 用户借阅 {} 本, 占比 {}%'.format(
a := len(total_books),
b := len(rent_books),
round(b / a * 100, 2)
))
List Comprehension vs Filter
# Q: 已知一个数字组成的列表, 获取里面大于 0 的数字
num_list = [1, 0, -1, 2]
# == Good ==
positive_num = (x for x in num_list if x > 0)
# == Tricky ==
positive_num = filter(lambda x: x > 0, num_list)
列表展平 (List Flattening)
# Q: 请将 [(1, 2), (3, 4)] 展平为 [1, 2, 3, 4]
a = [(1, 2), (3, 4)]
# == Good ==
b = []
for i in a:
for j in i:
b.append(j)
# == Better ==
b = []
for i in a:
b.extend(i)
# == Best ==
b = [y for x in a for y in x]
集合更新
a = [(1, 2), (3, 4)]
b = set()
# == Good ==
for i in a:
for j in i:
b.add(j)
# == Better ==
for i in a:
b.update(i)
# -> {1, 2, 3, 4}
# == Best ==
b.update(y for x in a for y in x)
# == Tricky 1 ==
_ = [b.update(x) for x in a]
# == Tricky 2 ==
[b.update(x) for x in a]
字典合并 (Python 3.9)
a = {'A': 'Apple', 'B': 'Banana'}
b = {'A': 'Almond', 'C': 'Cherry'}
# == Good ==
merged = {**a, **b}
# -> {'A': 'Almond', 'B': 'Banana', 'C': 'Cherry'}
# == Better (Python 3.9) ==
merged = a | b
更合理的做法
类属性 (class attributes)
# == Bad ==
class AAA:
# 会产生单例对象 (如果这不是你想要的话)
keywords = ['first', 'second', 'third']
def __init__(self, *keywords):
self.keywords.extend(keywords)
# == Good ==
class BBB:
def __init__(self, *keywords):
self.keywords = ['first', 'second', 'third']
self.keywords.extend(keywords)
# == Better ==
class CCC:
keywords: list # 这样做有利于子类继承时, 更安全地覆写
def __init__(self, *keywords):
self.keywords = ['first', 'second', 'third']
self.keywords.extend(keywords)
深入理解为什么这样做? 推荐阅读: Python 类属性, 实例属性, 类的单例化行为解惑.
前向类型标注 (Forward Declaration)
Google Python Style Guide - Forward Declaration
If you need to use a class name from the same module that is not yet defined – for example, if you need the class inside the class declaration, or if you use a class that is defined below – use a string for the class name.
class AAA:
def __init__(self, b: 'BBB'):
print(b.beep) # ^^^^^ 这里使用引号包裹, 可以向下引用之后定义的类
# ^^^^ Pycharm 的智慧感知和代码补全功能是可以识别它的!
class BBB:
beep = 'bee~~bee~~'
使用全局变量的情况
当全局变量更方便时 – 比如非常用的配置参数的多级交递 – 就使用全局变量.
# Bad
def main(a1, a2, b1, b2, b3):
aaa(a1, a2)
bbb(b1, b2, b3)
def aaa(c1, d1):
ccc(c1)
ddd(d1)
def bbb(e1, f1, f2):
eee(e1)
fff(f1, f2) # -> def fff(g1, h1): ...
...
# Good
class Config:
c1 = ...
d1 = ...
e1 = ...
g1 = ...
h1 = ...
def main():
aaa()
bbb()
def aaa():
ccc(Config.c1)
# def ccc(val=None):
# print(val)
ddd(Confi.d1)
...
...
减少嵌套, 尽快返回
注: 仅在单个函数内涉及的条件判断过多时使用.
TODO
对单条语句换行书写时, 使用括号包住, 而不是反斜杠
# Bad
text = 'Tailwind is a utility-first CSS framework for rapidly building ' + \
'custom user interfaces.'
# Good
text = 'Tailwind is a utility-first CSS framework for rapidly building ' \
'custom user interfaces.'
# Better
text = ('Tailwind is a utility-first CSS framework for rapidly building '
'custom user interfaces.')
# Not Good
if case_a and \
case_b and \
case_c:
...
# Good
if (case_a and
case_b and
case_c):
...
使用 textwrap.dedent 改善长字符串的缩进形式
# Bad
def f1(**kwargs):
template = '''
for i in range(0, {COUNT}, {OFFSET}):
print('{PREFIX}', i)
'''
return template.format(**kwargs)
# Good
def f2():
from textwrap import dedent
template = dedent('''
for i in range(0, {COUNT}, {OFFSET}):
print('{PREFIX}', i)
''')
return template.format(**kwargs)
更友好的命名
注: 以下内容仅供参考!
对称好于不对称
注: 仅建议在局部范围尝试.
# == Good ==
move_up = 1
move_down = 2
# == Better ==
move_up = 1
move_dn = 2
# == Good ==
benchmark = Benchmark()
select = Selector()
provider = Provider()
# == Tricky ==
bcmk = Benchmark()
slct = Selector()
prvd = Provider()
# == Good ==
class Foo:
def fast_calc(self): # fast calculate
pass
def std_calc(self): # standard calculate
pass
# == Better 1 ==
class Foo:
def fst_calc(self):
^^^
pass
def std_calc(self):
pass
# == Better 2 ==
class Foo:
def fast_calc(self):
pass
def stnd_calc(self):
^^^^
pass
# == Good ==
a = ['sunny',
'rainy',
'foggy']
b = {
'red': '#FF0000',
'green': '#00FF00',
'blue': '#0000FF'
}
# == Better ==
a = ['sunny',
'rainy',
'foggy',]
b = { ^
'red' : '#FF0000',
^^
'green': '#00FF00',
'blue' : '#0000FF',
} ^ ^
语义明确好于语义简洁
# == Bad ==
er = ExcelReader()
ew = ExcelWriter()
fr = FileReader()
fw = FileWriter()
# == Good ==
reader1 = ExcelReader()
writer1 = ExcelWriter()
reader2 = FileReader()
writer2 = FileWriter()
# == Better ==
exl_reader = ExcelReader()
exl_writer = ExcelWriter()
file_reader = FileReader()
file_writer = FileWriter()
格式一致好于格式不一致
class MyFinder:
def find_one(self, x):
pass^
def find_last(self, x):
pass^
# == Not Good ==
def findall(self, x):
pass
# == Good ==
def find_all(self, x):
pass^
使用 i/o, r/w 作为前缀 (或者作为后缀) 表示 “输入”, “输出”
for file_i, file_o in file_io.items():
data_r = read_file(file_i)
data_w = process_data(data_r)
write_file(data_w, file_o)
为什么?
Pycharm 自 2019 版本开始支持路径提示功能, 该功能是基于关键词来激活的.
例如: def read_file(file, i_file, file_i, file_1), 这几种格式都可以激活路径提示功能, 效果如下图所示:
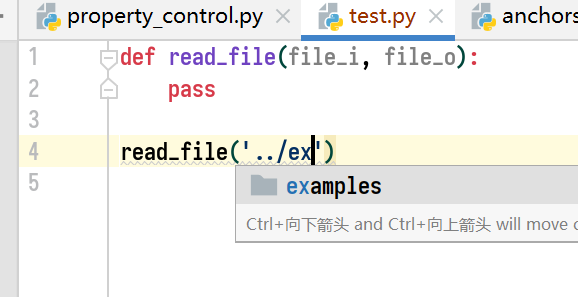
而使用: def read_file(ifile, filei, file1) 则不会提示 (也就是说 ‘file’ 这个关键词必须明显).
备注:
- 目前支持路径提示功能的关键词有:
file,dir和path - 如果您觉得
file_o会和for的短打冲突 (也就是说按下 ‘f’ 和 ‘o’ 每次都会优先提示for, 造成了不便), 有两个解决方法:- 使用
o_file替代file_o(这样按下 ‘o’ 和 ‘f’ 就能提示了, 重码率低) (缺点是i_file和if的短打会重复) - 使用 AHK 令 “单击右Shift” 打出下划线, 这样按下 ‘f’ - ‘rshift’ - ‘o’ 就能提示了 (适用场景更广泛, 这是我在用的方法)
- AHK 代码如下:

- AHK 代码如下:
- 使用
目录路径末尾不要加斜杠
dir_i = '../input' # 不要写成 '../input/'
dir_o = '../output' # 不要写成 '../output/'
for name in name_list:
file_i = f'{dir_i}/{name}.html'
file_o = f'{dir_o}/{name}.json'
# ^ 在这里使用显式的斜杠
...
为什么?
显式的斜杠更易于阅读. 这点类似于百分号, 查看下面的例子:
# == Bad ==
def calc_percent_a(m, n):
return str(round(m / n * 100, 2)) + '%'
# == Good ==
def calc_percent_b(m, n):
return round(m / n * 100, 2)
print('当前的工作进度是 {}'.format(calc_percent_a(1, 3)))
print('当前的工作进度是 {}%'.format(calc_percent_b(1, 3)))
前者在易读性上更差一些. 特别是当计算百分比的函数和 print 在不同的 py 文件时, 前者更容易让人忽略掉它是百分数的事实. (而且 calc_percent_a 在函数 “单一职能” 的表达上也不如 calc_percent_b)
路径的斜杠的使用原则和这个百分号示例有着相同之处. 这是为什么不推荐在目录路径末尾加斜杠的原因.
项目目录结构
注: 以下内容仅供参考!
小型项目或者单脚本文件
如果只是写一个简单的脚本, 一个 py 文件搞定, 不考虑什么依赖丢失, 后期重构的事情. 那么:
myproj
|- main.py
|- README.md
或者:
myproj
|- myscript.py
就已足够.
大中型项目 (个人建议)
myproj
|- bin # 二进制文件, 例如 .exe 程序
|- build # 打包工具
|- conf # 配置文件
|- data
|- dist # 发布版本
|- docs # 文档
|- assets # 存放文章关联的图片或附件
|- examples # 情景示例, 一般准备的这些用例都是可运行和展示的
|- gallery # 运行截图 (GUI 程序较常见)
|- history # 历史版本, 待销毁的文件
|- lib # 库文件
|- log # 日志文件
|- myproj # 与父目录同名, 或者稍有变化
| # (比如 myproj_desktop, myproj_web, myproj_mobile)
|- main.py # 主业务的入口
|- ...
|- sidework # 与主业务分开的边缘工作, 一般不会随主业务打包发布. 名字可以改成具
| # 体的名称 (比如 stat_code_count, callgraph_viewer, check_my_venv)
|- test # 测试模块, 有些人也喜欢用复数 'tests'
|- venv # 虚拟环境
|- CHANGELOG.md # 更新日志
|- README.md # 项目自述文档
以上目录按需取用, 也可以根据个人喜好改名 (比如有人不喜欢 {myproj}/{myproj} 这种同名的写法, 就用 {myproj}/src), 也可以改位置 (比如把 conf 放到 data 目录下, 或者删除 conf 目录, 把 conf.json 文件放到 data 目录下) 等等.
例如, 这是我的 lk-utils 项目的目录结构:
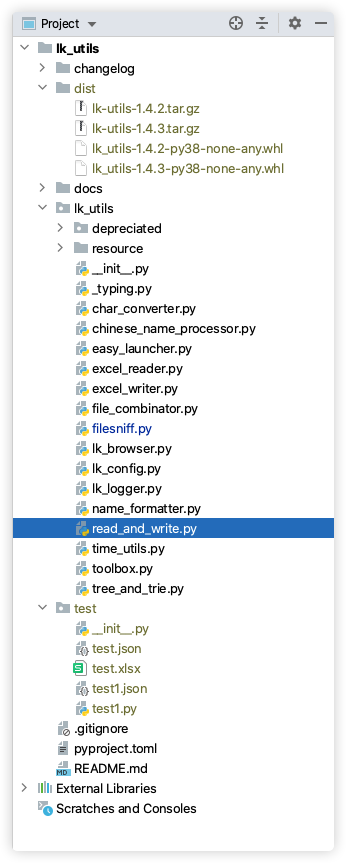
参考
- Google Python Style Guide
- Python 代码怎么写, 听听顶尖 Python 大神 kennethreitz 的建议 - 云+社区 - 腾讯云
- chiphuyen/python-is-cool
- Python 有哪些让你相见恨晚的技巧? - 量子位的回答 - 知乎
- 改善 Python 程序的 91 个建议
- 如何合理的规划一个 Python 的项目目录? - V2EX
- What is the best project structure for a Python application? - Stack Overflow
- Python 基础 6 - 目录结构 - Bigberg - 博客园















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









