






hello,我是Lilith,今天要带大家解锁LangChain中一个既强大又傲娇的技能点——实体记忆组件!

一、实体记忆:对话系统的"最强大脑"
想象一下,你的AI助手能记住你住在广州、最喜欢的编程语言是Python,甚至还能把你和"LangChain学习进度"关联起来!这就是实体记忆的魔法:
1️⃣ 实体雷达:精准捕捉对话中的关键信息(人物/地点/事件)
2️⃣ 属性记事本:自动记录每个实体的特征标签
3️⃣ 关系图谱:构建实体间的隐秘联系
二、避雷预警:官方组件的三大天坑
虽然LangChain自带的ConversationEntityMemory很香,但实测发现这些致命伤:
# 坑点可视化(官方示例代码)
chain = ConversationChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE, # 复杂到怀疑人生的Prompt模板
memory=ConversationEntityMemory(llm=llm), # Token吞噬兽本体
)1️⃣ Prompt模板臃肿:预设模板堪比老太太的裹脚布——又长又臭
2️⃣ Token黑洞:生成实体描述时疯狂吞噬计算资源
3️⃣ LLM依赖症:没有GPT-4级别的模型根本带不动
三、实战:手把手教你调教实体记忆
让我们用三段真实对话,揭开实体记忆的神秘面纱!
1.对话场景
# 第一回合:新手村打招呼
response1 = chain.invoke("你好,我是csdn。我最近正在学习LangChain。")
# 第二回合:暴露编程偏好
response2 = chain.invoke("我最喜欢的编程语言是 Python。")
# 第三回合:地理信息解锁
response3 = chain.invoke("我住在广州")2.实体捕获结果
{
"csdn": "最近正在学习LangChain的萌新",
"LangChain": "LLM应用开发的神兵利器",
"Python": "AI领域的万金油语言",
"广州": "早茶与科技并存的超级都市"
}四、高阶技巧:让实体记忆不再"金鱼脑"
想要突破官方限制?这三个锦囊请收好:
1️⃣ Prompt瘦身计划:把官方模板从500+token精简到150token以内
2️⃣ 实体缓存策略:用Redis/MongoDB实现长期记忆
3️⃣ 关联推理引擎:基于知识图谱实现跨对话推理
🎁 实体记忆的N种场景
-
电商场景:记住用户的尺码偏好+购物历史
-
教育领域:追踪学习进度+知识点关联
-
医疗助手:记录患者病史+药物过敏源
五、干货来咯
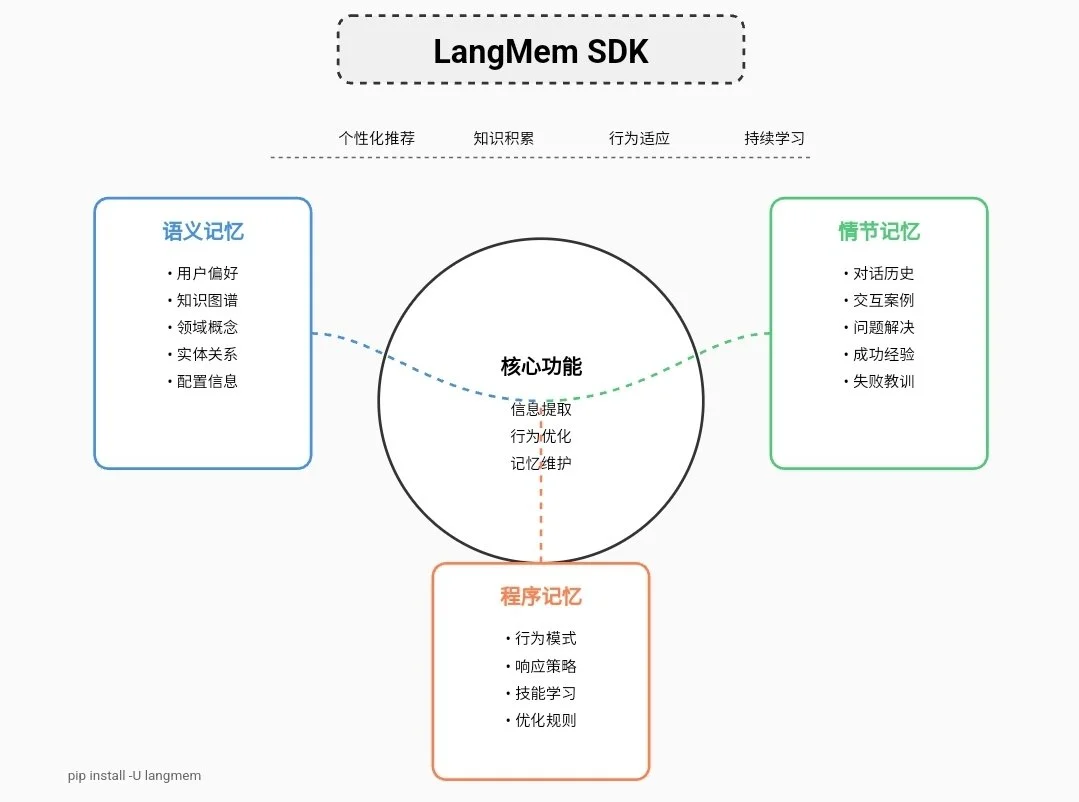
核心功能:
- 从对话中提取信息
- 通过提示词更新来优化 Agent 行为
- 维护关于行为、事实和事件的长期记忆
记忆类型分为三种:
- 语义记忆(Semantic Memory):存储事实和知识,如用户偏好
- 情节记忆(Episodic Memory):存储过去的经验,如对话历史
- 程序记忆(Procedural Memory):存储系统行为,如核心个性和响应模式
实用特点:
- 可与任何存储系统和 Agent 框架集成
- 原生支持 LangGraph 的长期记忆层
- 提供免费的托管服务
使用建议:
- 在实施记忆系统前,建议考虑:
- 哪些行为应该是可学习的,哪些应该是预定义的
- 需要追踪什么类型的知识或事实
- 什么条件应该触发记忆的召回
互动时间!大家在用LangChain时还遇到过哪些"坑爹"组件?欢迎分享交流~ 有用的话记得点赞收藏噜!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









