









一、RAG技术架构设计哲学
1.1 范式演进:从静态模型到动态知识系统
graph LR
A[传统LLM架构] -->|问题| B[依赖预训练参数]
B --> C[知识固化风险]
C --> D[领域适配困难]
A -->|解决方案| E[RAG增强架构]
E --> F[实时知识检索]
F --> G[动态上下文融合]
G --> H[可验证知识溯源]
1.2 核心组件技术选型矩阵
| 组件层级 | 开源方案 | 商业方案 | 选型建议 |
|---|---|---|---|
| 向量数据库 | Milvus, FAISS, ChromaDB | Pinecone, Weaviate | 中小规模选ChromaDB |
| 检索引擎 | Elasticsearch, Vespa | AWS Kendra | 需混合检索时选Elastic |
| 处理框架 | LangChain, Haystack | LlamaIndex | 快速开发选LangChain |
| 部署平台 | Docker+K8s | AWS SageMaker | 企业级选K8s集群 |
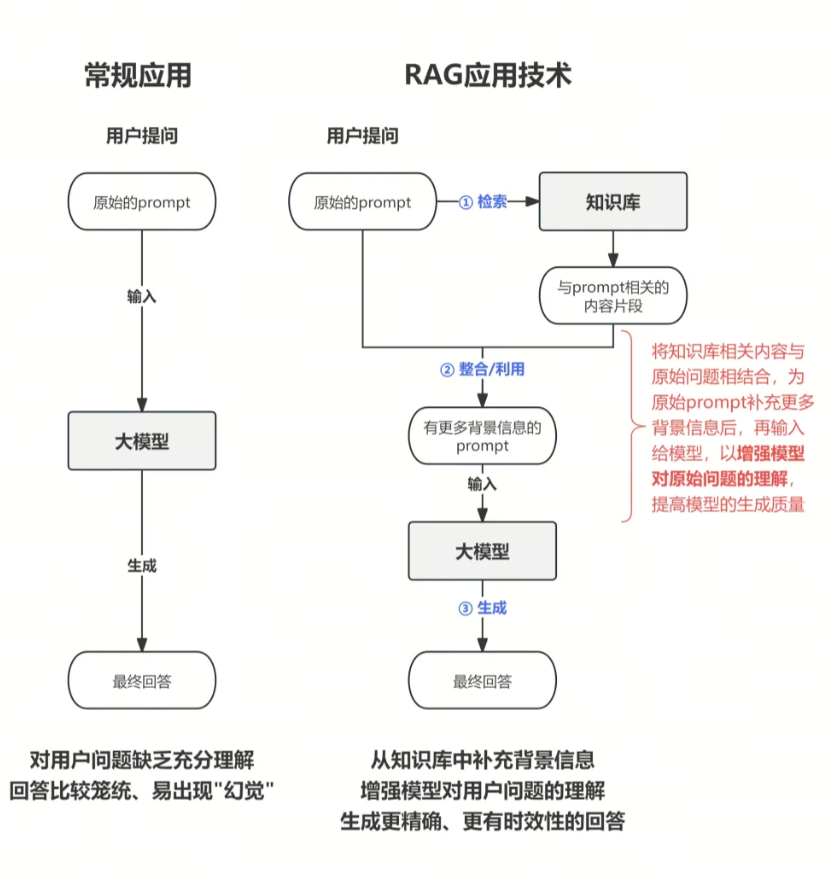
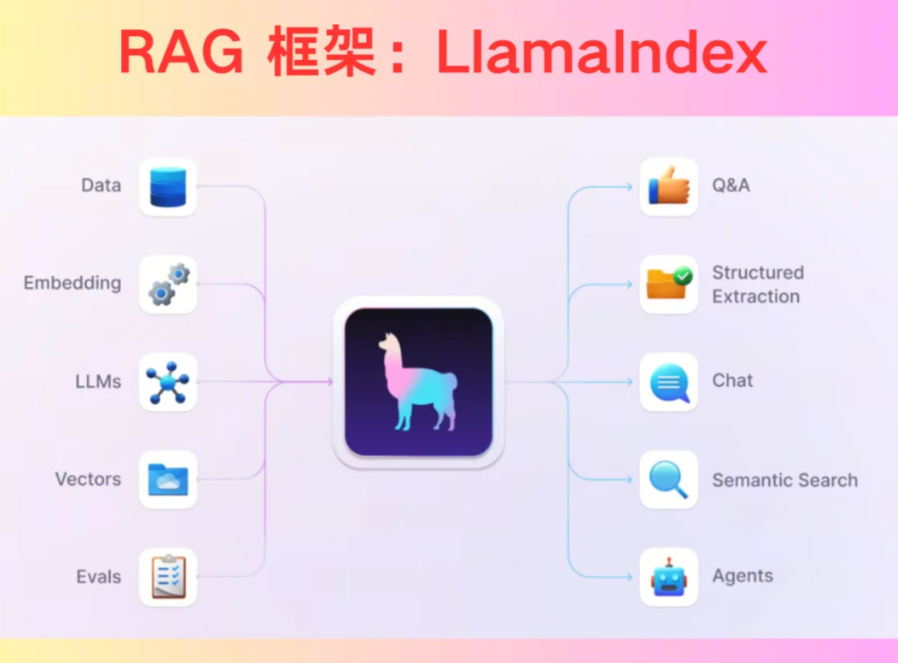
1.3 混合检索策略实现
# 混合检索代码示例(BM25 + 向量检索)
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
class HybridRetriever:
def __init__(self, corpus):
self.tokenized_corpus = [doc.split() for doc in corpus]
self.bm25 = BM25Okapi(self.tokenized_corpus)
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
def search(self, query, top_k=5):
# 文本检索
bm25_scores = self.bm25.get_scores(query.split())
bm25_topk = np.argsort(bm25_scores)[-top_k:][::-1]
# 向量检索
query_embedding = self.encoder.encode(query)
corpus_embeddings = self.encoder.encode(self.corpus)
cosine_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
vector_topk = torch.topk(cosine_scores, top_k).indices.tolist()
# 结果融合
combined = list(set(bm25_topk + vector_topk))
return sorted(combined, key=lambda x: bm25_scores[x]+cosine_scores[x], reverse=True)[:top_k]二、生产环境性能优化策略
2.1 分层缓存机制设计
graph TB
A[用户请求] --> B{缓存检查}
B -->|命中| C[返回缓存结果]
B -->|未命中| D[语义解析]
D --> E[向量检索]
E --> F[LLM生成]
F --> G[结果缓存]
G --> H[TTL管理]
subgraph 缓存层级
C -->|L1| I[内存缓存:Redis]<-->|LRU策略|J[缓存淘汰]
C -->|L2| K[磁盘缓存:SSD]
end2.2 精度-时延平衡公式
优化目标=α⋅Recall@k+β⋅1Latency+γ⋅Precision优化目标=α⋅Recall@k+β⋅Latency1+γ⋅Precision
参数建议值:α=0.6, β=0.3, γ=0.1
2.3 典型性能指标
| 场景 | 召回率 | 响应延迟 | 吞吐量 | 硬件配置 |
|---|---|---|---|---|
| 金融知识问答 | 92% | 650ms | 120 QPS | 4xV100+128GB内存 |
| 医疗诊断辅助 | 88% | 1.2s | 80 QPS | 2xA100+256GB内存 |
| 法律条款检索 | 95% | 850ms | 200 QPS | 8xT4+64GB内存 |
三、行业落地最佳实践
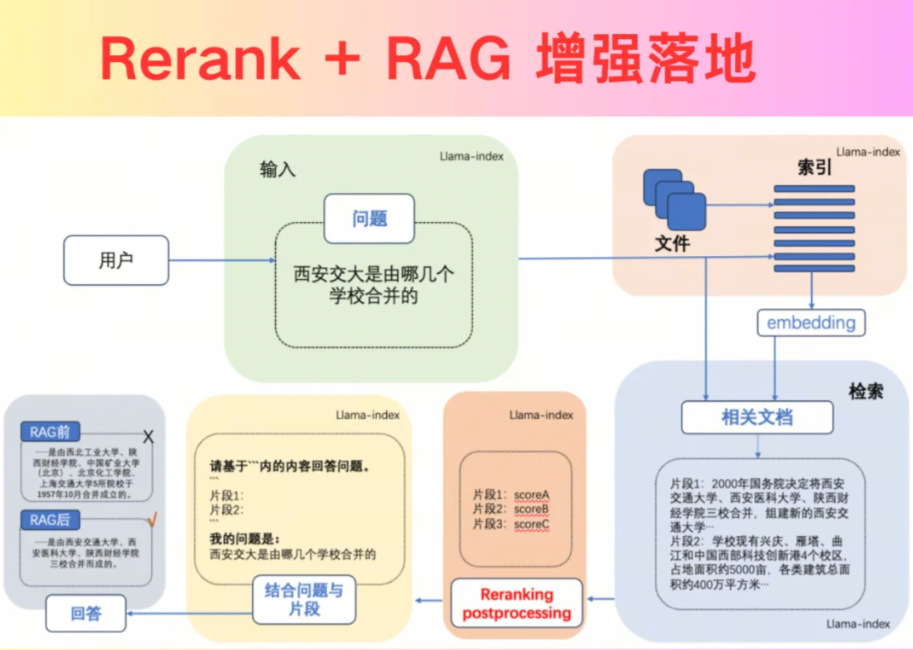
3.1 金融领域:实时财报分析系统
架构拓扑:
SEC EDGAR API → Kafka → Spark Streaming → Milvus → GPT-4 → 结果校验关键指标:
-
数据新鲜度:<3分钟
-
报表解析准确率:91.2%
-
日均处理量:15万份文档
3.2 医疗领域:循证医学辅助平台
**数据治理流程:
-
多源采集:PubMed + 临床指南 + 电子病历
-
术语标准化:SNOMED CT → UMLS映射
-
证据分级:Oxford CEBM标准
-
版本控制:Git式知识库管理
3.3 法律领域:智能合同审查
特征工程:
-
条款向量化:Law-BERT预训练模型
-
相似判例检索:Jaccard+BM25混合算法
-
风险预测:XGBoost分类器(AUC=0.93)
四、前沿技术演进方向
4.1 自适应检索框架
# 检索策略动态路由示例
class SmartRouter:
def __init__(self):
self.llm = GPT4()
self.retrievers = {
'vector': VectorRetriever(),
'keyword': BM25Retriever(),
'hybrid': HybridRetriever()
}
def route(self, query):
analysis = self.llm.generate(f"分析该问题的类型:{query}")
if "专业术语" in analysis:
return self.retrievers['vector']
elif "时效性" in analysis:
return self.retrievers['hybrid']
else:
return self.retrievers['keyword']4.2 多模态RAG架构
用户输入 → 多模态编码器 → 联合索引 → 跨模态检索
↳ 文本 → CLIP文本编码 ↳ 图像 → CLIP视觉编码
↳ 语音 → Whisper转录 ↳ 视频 → 关键帧提取五、实施路线图建议
gantt
title RAG系统实施里程碑
dateFormat YYYY-MM-DD
section 基础建设
知识库构建 :done, des1, 2023-01-01, 30d
检索系统部署 :active, des2, 2023-02-01, 20d
section 优化阶段
混合检索调优 : des3, 2023-03-01, 25d
缓存机制实施 : des4, 2023-04-01, 15d
section 高级功能
智能路由开发 : des5, 2023-05-01, 30d
多模态支持 : des6, 2023-06-01, 45d推荐工具链:
-
开发框架:LangChain + LlamaIndex
-
监控系统:Prometheus + Grafana(监控P90延迟、召回率等核心指标)
-
测试工具:Postman + Locust(压力测试场景模拟)
如果觉得有帮助,欢迎点赞⭐收藏!


















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









