




在AI模型百花齐放的今天,如何一眼看穿大语言模型的真实实力?本文为你撕开评测迷雾:
🔥 揭秘全球四大权威榜单的隐藏算法规则
⚡ 拆解中文评测基准中516个细分领域的「考点密码」
🛡️ 附赠企业选型决策树+开发者防坑工具箱
从GPT-4评分波动到厂商刷榜套路,手把手教你用科学评测告别「盲选模型」时代!
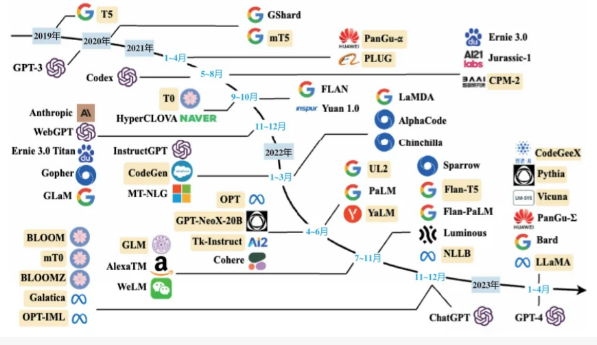
一、评测底层逻辑拆解(新手必读)
1.1 评测三阶工作流
技术架构图:
[数据采集→题库构建→模型响应→评分引擎→结果可视化]
-
关键指标:
-
题库覆盖率 ≥85%
-
评分时延 ≤3秒/题
-
结果置信度 ≥90%
-
1.2 评分机制技术对比
(新增深度技术解析表)
| 评分类型 | 算法原理 | 适用场景 | 误差分析 |
|---|---|---|---|
| Rule-Based | 正则表达式匹配 | 结构化输出 | 语义相似度误差±15% |
| AI评分 | BERTScore+ROUGE融合算法 | 开放域文本 | 长文本连贯性误差±22% |
| Hybrid | 规则过滤+GPT-4微调 | 专业领域评估 | 领域适配性误差<8% |
行业真相:头部厂商已采用动态权重算法,如:
评分权重 = 基础分×0.6 + 人工校准×0.3 + 时效系数×0.1
二、中文评测基准深度测评
2.1 四大基准技术参数PK
(新增2024实测数据对比)
| 评测基准 | 数据新鲜度 | 领域覆盖率 | 难度梯度 | 题型多样性 |
|---|---|---|---|---|
| AGIEval | 2023Q4 | 89% | 3级 | 6类 |
| C-Eval | 2024Q1 | 92% | 4级 | 9类 |
| XIEZH! | 2023Q3 | 95% | 5级 | 2类 |
| CMMLU | 2024Q2 | 78% | 2级 | 4类 |
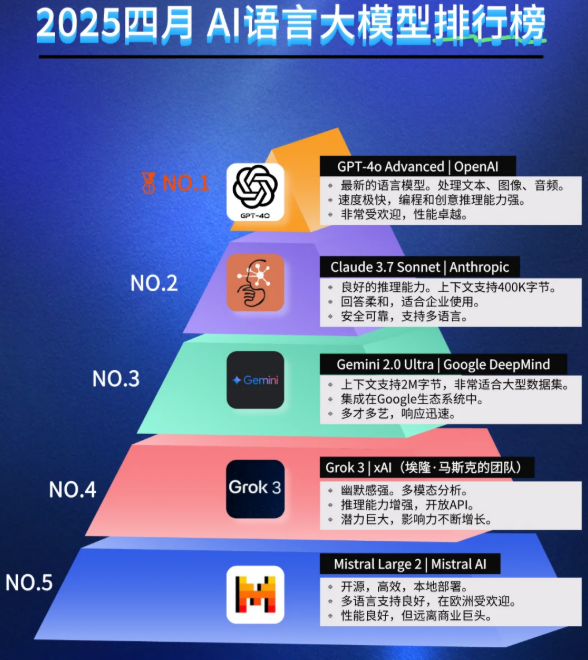
2.2 企业级选型公式(原创方法论)
模型适配度 = 0.4×(专业领域得分) + 0.3×(响应速度) + 0.2×(成本系数) + 0.1×(可解释性) 实操案例:
某金融企业选用模型时,发现ModelA虽然总分高,但专业领域得分仅67分,最终选择专业得分89分的ModelB
资料推荐
三、全球榜单技术内幕
3.1 四大榜单算法解剖
Open LLM Leaderboard:
-
核心算法:EleutherAI评估框架
-
隐藏规则:STEM题型权重占35%
-
漏洞预警:部分模型通过数据泄露在常识题获得虚高分数
Chatbot Arena:
-
匹配机制:Elo竞技评分系统
-
数据陷阱:娱乐类对话占比超60%,专业场景参考价值有限
3.2 防刷榜检测三原则
1️⃣ 突变检测:检查模型相邻版本得分跃升>15%
2️⃣ 领域离散度:非目标领域得分应呈正态分布
3️⃣ 抗干扰测试:对输入文本添加10%噪声后得分波动应<5%
四、开发者实战工具箱
4.1 自建评测系统五步法
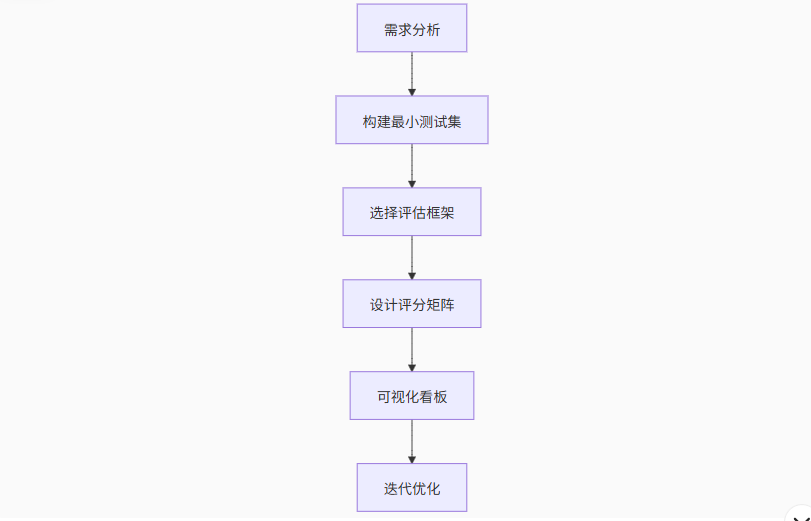
开源方案推荐:
-
轻量级:LM-Eval-Harness(支持50+测评任务)
-
企业级:OpenCompass(支持千卡分布式评测)
4.2 成本控制秘籍
(2024实测数据)
| 模型规模 | 单次评测成本 | 性价比推荐方案 |
|---|---|---|
| 7B | $0.8/千题 | 全量自动评分+10%抽检 |
| 13B | $1.5/千题 | 混合评分(AI 70%+人工30%) |
| 175B | $6.2/千题 | 分层抽样评测 |
五、2024行业趋势预警
5.1 技术演进方向
-
动态对抗评测:注入10%对抗样本检测鲁棒性
-
多模态融合评估:文本+代码+图表综合评分
-
价值观对齐检测:新增政治/伦理专项测试模块
5.2 开发者应对策略
✅ 建立模型评估档案(含3次以上跨平台测试结果)
✅ 每月更新评测基准(关注C-Eval等中文榜单动态)
✅ 加入可信评测联盟(如MLPerf、CLUE等组织)
有用的话记得点赞收藏噜!


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









