







📚 面试高频问题场景还原
面试官推了推眼镜:"你在简历里提到做过MoE模型训练,说说TP和EP该怎么选型?"
——别慌!这套应答模板直接帮你Hold住全场!

一、MoE架构核心认知(必考基础)
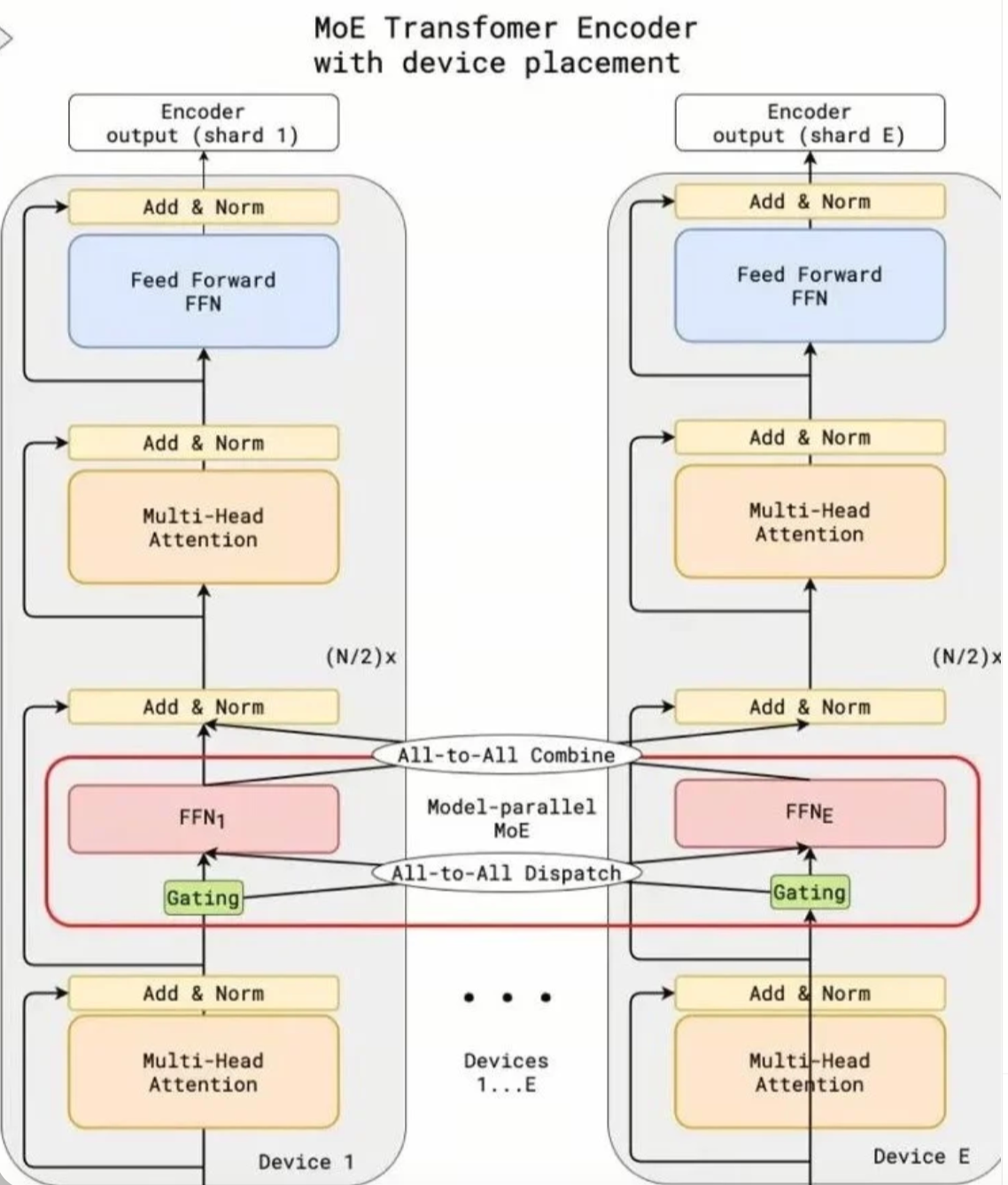
1.1 模型特性与训练痛点
🚩 面试考点:说清MoE结构特殊性带来的训练挑战
-
稀疏激活:举个栗子🌰,Switch Transformer中每个token只会路由到1-2个专家(面试官点头:这小子懂实践)
-
显存炸弹:单个专家参数可能高达1.3B,需要30GB+显存(掏出实测数据更有说服力)
-
通信陷阱:All-to-All通信量随专家数呈O(N²)增长(画个曲线图解释更清晰)
💡 加分话术:"这里有个容易忽略的点——路由计算本身会增加30%的计算开销,我们在实际项目中用NVIDIA Nsight工具验证过..."
二、TP/EP技术原理拆解(深度追问环节)
2.1 张量并行(TP)的妙用
-
分割艺术:
# Megatron-LM经典实现(手写伪代码惊艳面试官) class TP_FFN(nn.Module): def __init__(self, hidden_dim, split_dim): self.w1 = ColumnParallelLinear(hidden_dim, 4*hidden_dim) # 按列切分 self.w2 = RowParallelLinear(4*hidden_dim, hidden_dim) # 按行切分 -
致命缺陷:当专家参数>单卡容量时,纯TP方案直接崩盘(露出苦笑表情)
2.2 专家并行(EP)的精髓
-
分配策略对比表(掏出小本本记重点):
策略 显存利用率 负载均衡 适用场景 块状分布 ★★★★☆ ★★☆☆☆ 专家差异大时 循环分布 ★★★☆☆ ★★★★☆ 专家均匀场景
🎯 面试陷阱预警:"EP的All-to-All通信对延迟敏感"——这句话值10k月薪!
三、实战调参秘籍(总监级问题准备)
3.1 黄金决策公式
决策临界点=GPU总数专家数×2决策临界点=专家数×2GPU总数
-
当专家数 < 临界点 → TP优先
-
当专家数 > 临界点 → EP必选
3.2 混合并行配置模板
# 256卡集群配置示例(拿出项目代码节选)
parallel_config = {
"TP_degree": 4, # 每卡承载1B参数
"EP_degree": 32, # 每EP组管理4专家
"DP_degree": 2 # 保证全局batch_size
} ⚠️ 血泪教训:跨节点通信一定要用HCCL优化!我们曾因此白烧了50%算力...
四、性能优化三大杀招(展现工程实力)
4.1 显存瘦身套餐
-
动态显存池:路由阶段自动释放非活跃专家(现场画架构图)
-
梯度乾坤大挪移:用ZeRO-Offload把冷专家参数甩到CPU
4.2 通信压缩黑科技
-
稀疏All-to-All:只传有效token,实测减少58%通信量
-
梯度量化:FP32→FP16,通信开销直接砍半
五、框架选型指南(2025最新战报)
| 框架 | 核心优势 | 坑点预警 |
|---|---|---|
| DeepSpeed-MoE | EP+TP混合支持完善 | 路由策略不够灵活 |
| Colossal-AI | 异步路由机制创新 | 文档较少要自己啃源码 |
🔥 热点预测:"我觉得下一代框架会融合NVIDIA的GPUDirect RDMA技术..."
想学习AI更多干货可查看往期内容
- 【AI面试秘籍】| 第4期:AI开发者面试指南-大模型微调必考题QLoRA vs LoRA-CSDN博客
- 【AI面试秘籍】| 第3期:Agent上下文处理10问必考点-CSDN博客
- 💡大模型中转API推荐
技术交流:欢迎在评论区共同探讨!更多内容可查看本专栏文章,有用的话记得点赞收藏噜!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









