







今天讲一下起点中文网的列表页爬取,准备爬取的是小说书名、图片url、详情页url、作者、字数、分类及状态。
爬取网址:https://www.qidian.com/all
分析url

翻页至第二页、第三页,发现url上只有page=x这一个在改变,所以url的循环就很容易写出
def main():
"""
起点中文网列表页只能爬5页
:return:
"""
for i in range(1, 6):
q = QiDianZhongWenWang()
url = f"https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page={i}"
q.get_page(url)
分析源码
- 通过F12查看渲染后的代码和Ctrl+U查看源码发现两处代码是一致的,可以判断起点中文网没有使用js渲染。(我用的是Chrome浏览器,各个浏览器查看源码的方式可能不同)
- 可以看到起点中文网的列表页每一页有20个item,分别放在每一个
<li>标签里面
- 我们可以看到网页正常显示小说字数,但是渲染后的代码在应该显示数字的地方却是一个个方框。
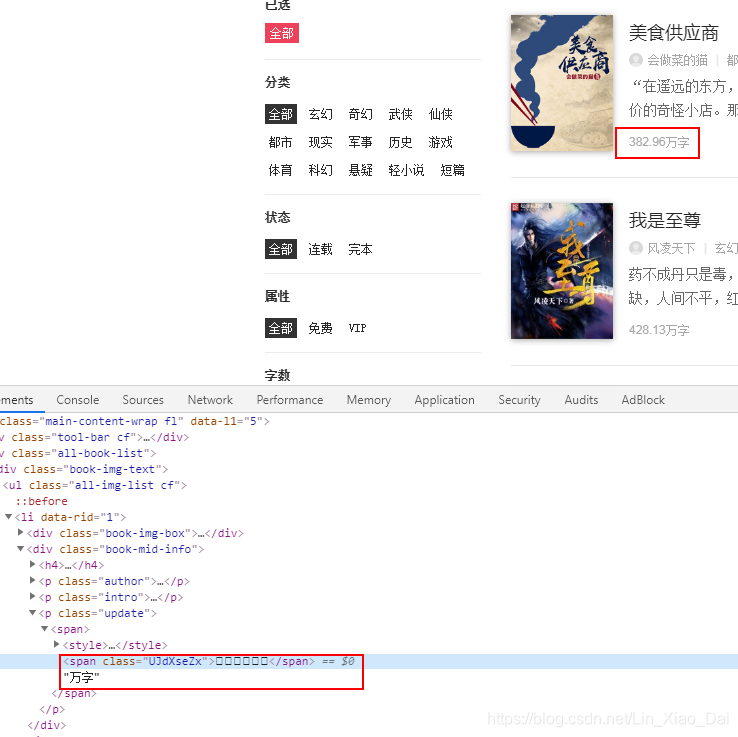
- 我们Ctrl+U查看一下源代码发现对应位置的方框变成了unicode,我们可以看到这里有一个
<span>标签,其中的class属性是一个很奇怪的字符串,在<span>前面有一个<style>我们看一下里面的内容。
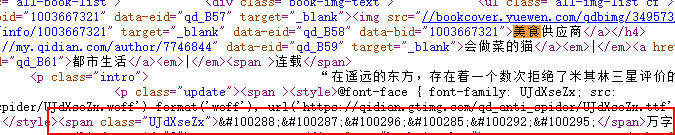
- 可以看到这个
<style>里面显示出了一个font文件的下载路径,而且仔细看一下代码可以发现之前<span>里的奇怪的字符串也出现在了这个<style>里面。

解密
- 我们直接访问上图红框划出的url,下载font文件,然后打开百度字体编辑器(http://fontstore.baidu.com/static/editor/index.html)查看一下字体的对应关系。

- 可以看数字和英文单词相对应,所以我们先写一个字典出来表示它们的对应关系。
woff_map = {
"one": "1",
"two": "2",
"three": "3",
"four": "4",
"five": "5",
"six": "6",
"seven": "7",
"eight": "8",
"nine": "9",
"zero": "10",
"period": ".",
}
- 然后我们用fonttools来看一下font文件里面的映射关系。
font = TTFont("./UJdXseZx.woff")
print(font.getBestCmap())
{
100285: 'period', 100287:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









