






基本原理
Transformer是一种深度学习模型,它通过自注意力机制和位置编码,实现了对序列数据的处理。在机器翻译任务中,Transformer模型将输入的源语言文本序列作为输入,通过编码器和解码器两个阶段,生成目标语言的文本序列。
在编码阶段,Transformer模型将源语言文本序列中的每个单词都映射到一个向量表示,并通过自注意力机制计算出每个单词的权重。然后,通过位置编码将单词的位置信息编码为向量,与单词向量相加得到最终的表示。在解码阶段,模型将编码器输出的向量作为输入,通过解码器生成目标语言的文本序列。
这个系统可以分为以下几个关键部分:
1.词汇表(Vocab):
Vocab类用于创建词汇表,包含每个单词或子词的频率信息,并添加特殊标记,如(未知单词)、(填充标记)、(句子开始标记)和(句子结束标记)。
2.分词器(Tokenizer):
Tokenizer类用于将句子转换为单词或子词的标识符序列。
3.模型(Seq2SeqTransformer):
- Seq2SeqTransformer类继承自nn.Module,它定义了一个序列到序列的Transformer模型,包括编码器和解码器。
- 模型包含词嵌入层、位置编码、Transformer编码器层、Transformer解码器层和输出线性层。
- forward方法实现了模型的前向传播,包括编码器和解码器的处理。
- encode和decode方法分别实现了编码器和解码器的前向传播。
4.损失函数(Loss Function):
loss_fn函数用于计算模型的损失。
5.数据处理(Data Processing):
- data_process函数将文本数据转换为张量形式。
- generate_batch函数将一批数据转换为批次形式,并添加开始和结束标记。
- create_mask函数创建源语言和目标语言的掩码,包括注意力掩码和填充掩码。
6.训练和评估(Training and Evaluation):
- train_epoch函数用于在一个epoch内训练模型。
- evaluate函数用于评估模型性能。
7.翻译(Translation):
- greedy_decode函数使用贪婪解码策略生成翻译结果。
- translate函数将源语言句子翻译成目标语言。
做完前期了解工作 我们开始编码吧!
数据准备
JParaCrawl![]() http://www.kecl.ntt.co.jp/icl/lirg/jparacrawl在这个链接中下载汉-日对照数据集
http://www.kecl.ntt.co.jp/icl/lirg/jparacrawl在这个链接中下载汉-日对照数据集
然后把下载下来的数据转换为pandas的数据结果Dataframe便于处理
df = pd.read_csv('./zh-ja/zh-ja.bicleaner05.txt', sep='\\t', engine='python', header=None)
trainen = df[2].values.tolist()#[:10000]
trainja = df[3].values.tolist()#[:10000]我们可以通过下面的抽样检查 判断Dataframe中是否有误
print(trainen[500])
print(trainja[500]) 输出显示是无误的
输出显示是无误的
因为日语不存在空格提供天然的分词,所以我们需要对日语句子进行分词操作
ja_tokenizer = spm.SentencePieceProcessor(model_file='enja_spm_models/spm.ja.nopretok.model')
ja_tokenizer.encode("年金 日本に住んでいる20歳~60歳の全ての人は、公的年金制度に加入しなければなりません。", out_type='str')
接下来我们需要构建词汇表
并且把句子转换为张量
- 使用分词器编码句子: 使用之前加载的 SentencePiece 分词器将日语句子转换为子词的标识符序列。
- 统计词频: 使用 Counter 对象统计每个子词的出现次数,这有助于构建词汇表。
- 构建词汇表: 使用 TorchText 的 Vocab 类,根据子词的频率信息创建词汇表对象。
- 特殊标记: 词汇表会自动添加一些特殊标记,例如:
<unk>:表示未知单词<pad>:用于填充序列到相同长度<bos>:表示句子的开始<eos>:表示句子的结束
- 转换句子为张量: 使用词汇表将子词的标识符转换为整数索引,并将索引转换为 PyTorch 张量。 这样,模型就可以处理这些张量数据了。
# 定义一个构建词汇表的函数
def build_vocab(sentences, tokenizer):
"""
根据给定的句子列表和分词器构建词汇表。
参数:
sentences -- 列表,包含多个句子字符串。
tokenizer -- 一个分词器,能够将句子编码为单词或子词的标识符。
返回:
Vocab -- 一个词汇表对象,它包含句子中所有单词的频率信息,以及特殊标记。
这个函数首先创建一个Counter对象来计算每个单词或子词的出现次数。
然后,它遍历提供的句子列表,使用分词器对每个句子进行编码,并更新Counter。
最后,它使用Counter创建一个Vocab对象,这个对象还会添加几个特殊标记,
例如 '<unk>' 表示未知单词,'<pad>' 表示填充,'<bos>' 表示句子的开始,'<eos>' 表示句子的结束。
"""
counter = Counter()
for sentence in sentences:
# 使用分词器编码句子,并更新计数器
counter.update(tokenizer.encode(sentence, out_type=str))
# 创建词汇表对象,并添加特殊标记
return Vocab(counter, specials=['<unk>', '<pad>', '<bos>', '<eos>'])
# 使用日语训练数据和分词器构建日语词汇表
ja_vocab = build_vocab(trainja, ja_tokenizer)
# 使用英语训练数据和分词器构建英语词汇表
en_vocab = build_vocab(trainen, en_tokenizer)# 定义一个数据处理函数,将文本数据转换为张量形式
def data_process(ja, en):
"""
将给定的日语和英语句子对转换为张量形式的数据。
参数:
ja -- 列表,包含多个日语句子字符串。
en -- 列表,包含多个英语句子字符串。
返回:
data -- 列表,包含多个日语和英语句子对的张量表示。
这个函数首先创建一个空列表data来存储处理后的数据。
然后,它遍历输入的日语和英语句子对,使用对应的词汇表和分词器将每个句子转换为张量。
具体来说,它使用分词器对每个句子进行编码,然后使用词汇表将编码后的单词或子词转换为整数索引。
最后,它将这些索引转换为PyTorch张量,并将每个语言对的张量元组添加到data列表中。
"""
data = []
for (raw_ja, raw_en) in zip(ja, en):
# 使用日语分词器对日语句子进行编码,并使用日语词汇表将编码转换为张量
ja_tensor_ = torch.tensor([ja_vocab[token] for token in ja_tokenizer.encode(raw_ja.rstrip("\n"), out_type=str)],
dtype=torch.long)
# 使用英语分词器对英语句子进行编码,并使用英语词汇表将编码转换为张量
en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer.encode(raw_en.rstrip("\n"), out_type=str)],
dtype=torch.long)
# 将日语和英语张量元组添加到数据列表中
data.append((ja_tensor_, en_tensor_))
return data
# 使用日语和英语训练数据调用数据处理函数,获取训练数据
train_data = data_process(trainja, trainen)接下来创建了一个 DataLoader 对象,用于在训练过程中迭代地加载数据批次
BATCH_SIZE = 16 #设置为16
PAD_IDX = ja_vocab['<pad>']
BOS_IDX = ja_vocab['<bos>']
EOS_IDX = ja_vocab['<eos>']
# 定义一个生成批处理数据的函数
def generate_batch(data_batch):
"""
将一批数据转换为批次形式,并添加开始和结束标记。
参数:
data_batch -- 列表,包含多个日语和英语句子对的张量表示。
返回:
ja_batch -- PyTorch张量,形状为(max_len, batch_size),包含一批日语句子。
en_batch -- PyTorch张量,形状为(max_len, batch_size),包含一批英语句子。
这个函数首先初始化两个空列表ja_batch和en_batch来存储处理后的句子。
然后,它遍历输入的数据批次中的每个句子对,将开始标记(BOS_IDX)和结束标记(EOS_IDX)添加到每个句子的开头和结尾。
接着,它使用PyTorch的pad_sequence函数来将批次中的句子填充到相同长度,使用填充标记(PAD_IDX)作为填充值。
最后,它返回两个张量ja_batch和en_batch,它们分别包含一批处理后的日语和英语句子。
"""
ja_batch, en_batch = [], []
for (ja_item, en_item) in data_batch:
# 将开始和结束标记添加到日语句子
ja_batch.append(torch.cat([torch.tensor([BOS_IDX]), ja_item, torch.tensor([EOS_IDX])], dim=0))
# 将开始和结束标记添加到英语句子
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
# 使用填充函数将批次中的句子填充到相同长度
ja_batch = pad_sequence(ja_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
return ja_batch, en_batch
# 使用DataLoader创建一个训练迭代器,它会在每个批次中生成处理后的数据
train_iter = DataLoader(train_data, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=generate_batch)模型构建
Sequence-to-sequence Transformer 模型是一种基于 Transformer 架构的序列到序列模型,用于解决机器翻译等自然语言处理任务。它由编码器和解码器两部分组成,每个部分都包含多层 TransformerEncoderLayer 和 TransformerDecoderLayer。
编码器:
- 输入序列: 编码器接收源语言序列作为输入。
- 多头注意力机制: 编码器使用多头注意力机制,将输入序列中每个位置的单词与其他位置进行关联,捕捉单词之间的依赖关系。
- 前馈网络: 编码器使用前馈网络对每个位置的单词进行非线性变换,学习更复杂的特征表示。
- 输出序列: 编码器的输出序列称为“内存”,它包含了源语言序列的语义信息,并作为解码器的输入。
解码器:
- 目标序列: 解码器接收目标语言序列作为输入,并逐步生成翻译文本。
- 自注意力机制: 解码器使用自注意力机制,将目标序列中每个位置的单词与之前生成的单词进行关联,捕捉单词之间的依赖关系。
- 编码器-解码器注意力机制: 解码器使用编码器-解码器注意力机制,将目标序列中每个位置的单词与源语言序列进行关联,获取源语言序列的语义信息。
- 前馈网络: 解码器使用前馈网络对每个位置的单词进行非线性变换,学习更复杂的特征表示。
- 输出序列: 解码器的输出序列包含了目标语言序列的概率分布,可以根据概率分布选择最可能的单词作为翻译结果。
训练过程:
- 教师强迫: 在训练过程中,解码器使用教师强迫技术,即使用目标序列的真实值作为输入,而不是使用模型预测的值。这有助于模型更快地学习翻译规则。
- 端到端训练: 编码器和解码器共同训练,通过最小化翻译误差来更新模型参数。
Transformer 的优势:
- 并行计算: Transformer 模型可以并行计算注意力机制和前馈网络,从而加速训练过程。
- 长距离依赖: Transformer 模型可以有效地处理长距离依赖关系,从而提高翻译质量。
- 可扩展性: Transformer 模型可以轻松扩展到更大的模型和更多的数据,从而进一步提升翻译质量。
from torch.nn import (TransformerEncoder, TransformerDecoder,
TransformerEncoderLayer, TransformerDecoderLayer)
# 定义一个序列到序列的Transformer模型
class Seq2SeqTransformer(nn.Module):
def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward:int = 512, dropout:float = 0.1):
"""
初始化Seq2SeqTransformer模型。
参数:
num_encoder_layers -- int, 编码器层的数量。
num_decoder_layers -- int, 解码器层的数量。
emb_size -- int, 词嵌入的维度。
src_vocab_size -- int, 源语言的词汇表大小。
tgt_vocab_size -- int, 目标语言的词汇表大小。
dim_feedforward -- int, feedforward层的维度,默认为512。
dropout -- float, dropout概率,默认为0.1。
这个构造函数创建了一个序列到序列的Transformer模型。
它包括一个编码器和一个解码器,每个都由指定数量的层组成。
模型还包含词嵌入层、位置编码和输出线性层。
"""
super(Seq2SeqTransformer, self).__init__()
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
tgt_mask: Tensor, src_padding_mask: Tensor,
tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
"""
实现前向传播。
参数:
src -- Tensor, 源语言输入序列。
trg -- Tensor, 目标语言输入序列。
src_mask -- Tensor, 源语言注意力掩码。
tgt_mask -- Tensor, 目标语言注意力掩码。
src_padding_mask -- Tensor, 源语言填充掩码。
tgt_padding_mask -- Tensor, 目标语言填充掩码。
memory_key_padding_mask -- Tensor, 编码器输出填充掩码。
返回:
generator(outs) -- Tensor, 模型的输出序列。
这个函数首先对源语言和目标语言序列进行词嵌入和位置编码。
然后,它使用编码器处理源语言序列,并使用解码器处理目标语言序列。
最后,它通过线性层生成输出序列。
"""
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
"""
实现编码器的前向传播。
参数:
src -- Tensor, 源语言输入序列。
src_mask -- Tensor, 源语言注意力掩码。
返回:
transformer_encoder -- Tensor, 编码器的输出序列。
这个函数对源语言序列进行词嵌入和位置编码,然后使用编码器处理。
"""
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
"""
实现解码器的前向传播。
参数:
tgt -- Tensor, 目标语言输入序列。
memory -- Tensor, 编码器的输出序列。
tgt_mask -- Tensor, 目标语言注意力掩码。
返回:
transformer_decoder -- Tensor, 解码器的输出序列。
这个函数对目标语言序列进行词嵌入和位置编码,然后使用解码器处理。
"""
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)接下来我们进行位置编码
就是将文本数据转换为包含单词语义信息和位置信息的特征向量
为 Transformer 模型的训练和翻译提供了基础
# 定义位置编码模块
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
"""
初始化位置编码模块。
参数:
emb_size -- int, 词嵌入的维度。
dropout -- float, dropout概率。
maxlen -- int, 句子的最大长度,默认为5000。
这个模块用于为词嵌入添加位置信息,使模型能够学习单词在句子中的位置关系。
"""
super(PositionalEncoding, self).__init__()
# 计算位置编码的缩放因子
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
# 创建位置索引
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
# 初始化位置编码
pos_embedding = torch.zeros((maxlen, emb_size))
# 填充位置编码
pos_embedding[:, 0::2] = torch.sin(pos * den) # 奇数维度使用正弦函数
pos_embedding[:, 1::2] = torch.cos(pos * den) # 偶数维度使用余弦函数
# 增加维度,使其可以与词嵌入相加
pos_embedding = pos_embedding.unsqueeze(-2)
# 创建dropout层
self.dropout = nn.Dropout(dropout)
# 将位置编码注册为模型的缓冲区
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
"""
实现前向传播。
参数:
token_embedding -- Tensor, 词嵌入向量。
返回:
Tensor, 包含位置信息的词嵌入向量。
这个函数将词嵌入和位置编码相加,并应用dropout层,得到最终的输入特征。
"""
return self.dropout(token_embedding +
self.pos_embedding[:token_embedding.size(0),:])
# 定义词嵌入模块
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
"""
初始化词嵌入模块。
参数:
vocab_size -- int, 词汇表的大小。
emb_size -- int, 词嵌入的维度。
这个模块用于将单词转换为词嵌入向量,即将单词转换为向量表示,方便模型进行计算。
"""
super(TokenEmbedding, self).__init__()
# 创建词嵌入层
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
"""
实现前向传播。
参数:
tokens -- Tensor, 单词的索引。
返回:
Tensor, 词嵌入向量。
这个函数将单词的索引转换为词嵌入向量,并进行缩放。
"""
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
现在生成一个方形后续掩码矩阵,用于Transformer模型中的自注意力机制
后续单词掩码 (Subsequent Word Mask):
- 作用: 防止目标语言序列中一个位置的单词关注到它后面的单词。
- 原理:
- 创建一个上三角矩阵,其中对角线以上的元素为 1,表示可以相互关注,对角线以下的元素为 0,表示不能相互关注。
- 将上三角矩阵转置,得到下三角矩阵,即后续单词掩码。
- 在解码器中,使用后续单词掩码来屏蔽自注意力机制中的未来信息,确保模型在生成每个单词时只能依赖于它之前的单词。
# 生成一个方形后续掩码矩阵
def generate_square_subsequent_mask(sz):
"""
生成一个方形后续掩码矩阵,用于Transformer模型中的自注意力机制。
参数:
sz -- int, 掩码矩阵的大小。
返回:
mask -- Tensor, 大小为(sz, sz)的方形后续掩码矩阵。
这个函数首先创建一个上三角矩阵,所有的元素都是1。
然后,它将上三角矩阵转置,并将上三角部分的元素设置为0,其余部分设置为-无穷大。
这样,掩码矩阵确保了在自注意力机制中,一个位置的输出只依赖于该位置之前的输入。
"""
mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
# 创建源语言和目标语言的掩码
def create_mask(src, tgt):
"""
创建源语言和目标语言的掩码,包括注意力掩码和填充掩码。
参数:
src -- Tensor, 源语言序列,形状为(src_seq_len, batch_size)。
tgt -- Tensor, 目标语言序列,形状为(tgt_seq_len, batch_size)。
返回:
src_mask -- Tensor, 源语言注意力掩码,形状为(src_seq_len, src_seq_len)。
tgt_mask -- Tensor, 目标语言注意力掩码,形状为(tgt_seq_len, tgt_seq_len)。
src_padding_mask -- Tensor, 源语言填充掩码,形状为(batch_size, src_seq_len)。
tgt_padding_mask -- Tensor, 目标语言填充掩码,形状为(batch_size, tgt_seq_len)。
这个函数首先获取源语言和目标语言的序列长度。
然后,它使用generate_square_subsequent_mask函数为目标语言生成方形后续掩码矩阵。
对于源语言,由于Transformer编码器的自注意力机制允许位置之间的相互关注,因此创建一个全为False的掩码矩阵。
最后,它还创建了源语言和目标语言的填充掩码,用于在注意力机制中忽略填充标记。
"""
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torch.zeros((src_seq_len, src_seq_len), device=device).type(torch.bool)
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask模型训练
SRC_VOCAB_SIZE = len(ja_vocab)
TGT_VOCAB_SIZE = len(en_vocab)
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
BATCH_SIZE = 16
# 加深网络层数
NUM_ENCODER_LAYERS = 4
NUM_DECODER_LAYERS = 4
# 增加迭代轮数
NUM_EPOCHS = 20
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
transformer = transformer.to(device)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(
transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9
)
# 定义一个训练函数,用于训练模型一个epoch
def train_epoch(model, train_iter, optimizer):
"""
在一个epoch内训练模型。
参数:
model -- Seq2SeqTransformer, 要训练的模型。
train_iter -- DataLoader, 训练数据迭代器。
optimizer -- Optimizer, 用于优化模型参数的优化器。
返回:
losses / len(train_iter) -- float, 平均损失。
这个函数首先将模型设置为训练模式。
然后,它初始化损失累加器,并遍历训练数据迭代器中的每个批次。
在每个批次中,它将数据移动到指定设备,创建注意力掩码和填充掩码,然后通过模型前向传播。
接着,它计算损失,执行反向传播,并更新模型参数。
最后,它返回整个epoch的平均损失。
"""
model.train()
losses = 0
for idx, (src, tgt) in enumerate(train_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
optimizer.zero_grad()
tgt_out = tgt[1:,:]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
loss.backward()
optimizer.step()
losses += loss.item()
return losses / len(train_iter)
# 定义一个评估函数,用于评估模型性能
def evaluate(model, val_iter):
"""
评估模型性能。
参数:
model -- Seq2SeqTransformer, 要评估的模型。
val_iter -- DataLoader, 验证数据迭代器。
返回:
losses / len(val_iter) -- float, 平均损失。
这个函数首先将模型设置为评估模式。
然后,它初始化损失累加器,并遍历验证数据迭代器中的每个批次。
在每个批次中,它将数据移动到指定设备,创建注意力掩码和填充掩码,然后通过模型前向传播。
接着,它计算损失。
最后,它返回整个验证集的平均损失。
"""
model.eval()
losses = 0
for idx, (src, tgt) in enumerate(val_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:,:]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
losses += loss.item()
return losses / len(val_iter)在完成必要的类和函数准备之后,就可以开始训练模型
这个训练需要很大的计算资源 需要借助gpu
for epoch in tqdm.tqdm(range(1, NUM_EPOCHS+1)):
start_time = time.time()
train_loss = train_epoch(transformer, train_iter, optimizer)
end_time = time.time()
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "
f"Epoch time = {(end_time - start_time):.3f}s"))训练过程如下
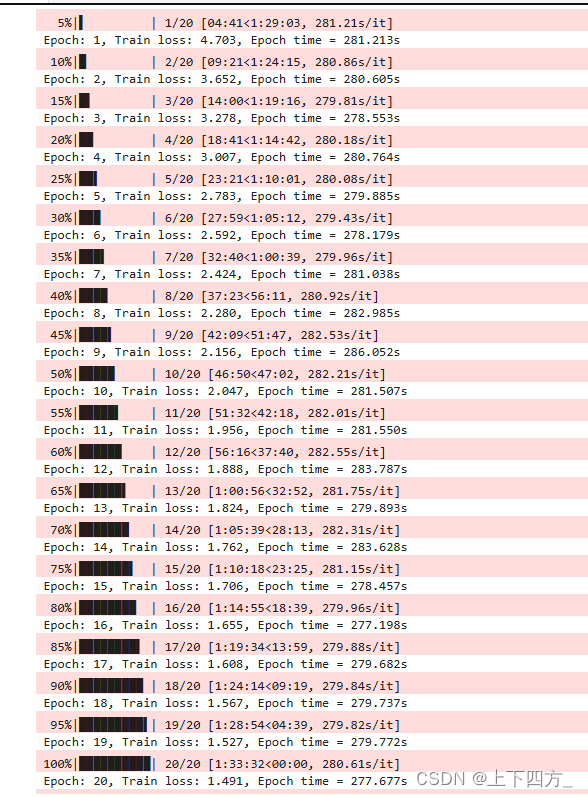
在我的实践中发现 将NUM_ENCODER_LAYERS,NUM_DECODER_LAYERS提的太高并不有利于模型的loss降低和持续收敛,并且就我的经验来说,将batch_size提升对模型的训练速度的提升几乎没有帮助(这点是有违常规的,通常在gpu上训练的时候增加batch_size是可以显著提升训练速度的),并且带来模型精度的下降
模型使用
# 定义一个贪婪解码函数,用于生成翻译结果
def greedy_decode(model, src, src_mask, max_len, start_symbol):
"""
使用贪婪解码策略生成翻译结果。
参数:
model -- Seq2SeqTransformer, 训练好的模型。
src -- Tensor, 源语言序列。
src_mask -- Tensor, 源语言注意力掩码。
max_len -- int, 生成序列的最大长度。
start_symbol -- int, 开始标记的索引。
返回:
ys -- Tensor, 生成的目标语言序列。
这个函数首先将源语言序列和注意力掩码移动到指定设备。
然后,它使用模型编码源语言序列,并初始化一个包含开始标记的输出序列。
接着,它迭代地解码序列,每次选择概率最高的词作为下一个词,直到达到最大长度或生成结束标记。
最后,它返回生成的目标语言序列。
"""
src = src.to(device)
src_mask = src_mask.to(device)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
for i in range(max_len-1):
memory = memory.to(device)
memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool)
tgt_mask = (generate_square_subsequent_mask(ys.size(0))
.type(torch.bool)).to(device)
out = model.decode(ys, memory, tgt_mask)
out = out.transpose(0, 1)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.item()
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX:
break
return ys
# 定义一个翻译函数,用于将源语言句子翻译成目标语言
def translate(model, src, src_vocab, tgt_vocab, src_tokenizer):
"""
将源语言句子翻译成目标语言。
参数:
model -- Seq2SeqTransformer, 训练好的模型。
src -- str, 源语言句子。
src_vocab -- Vocab, 源语言词汇表。
tgt_vocab -- Vocab, 目标语言词汇表。
src_tokenizer -- Tokenizer, 源语言分词器。
返回:
str, 翻译后的目标语言句子。
这个函数首先将模型设置为评估模式。
然后,它将源语言句子转换为词汇表索引,并添加开始和结束标记。
接着,它使用贪婪解码函数生成翻译结果。
最后,它将生成的目标语言序列的索引转换回文本,并返回翻译后的句子。
"""
model.eval()
tokens = [BOS_IDX] + [src_vocab.stoi[tok] for tok in src_tokenizer.encode(src, out_type=str)] + [EOS_IDX]
num_tokens = len(tokens)
src = (torch.LongTensor(tokens).reshape(num_tokens, 1))
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")
Then, we can just call the translate function and pass the required parameters.看看效果

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









