







本文基于Mac系统测试,Windows系统请参考其GitHub网站上的编译说明进行使用。
在GitHub上下载最新版本的Tesseract,目前最新是3.05.01,注意,对中文识别的支持需要版本3.0以上:
下载好tesseract解压后,目录结构如下:

可以看到,功能可以移植到android平台上,使用的是jni的方式,这里后面再尝试了。
安装依赖库,这里使用的是homebrew安装的方式:brew install automake autoconf autoconf-archive libtool pkgconfig icu4c leptonica gcc

安装好依赖库后,进入tesseract根目录:
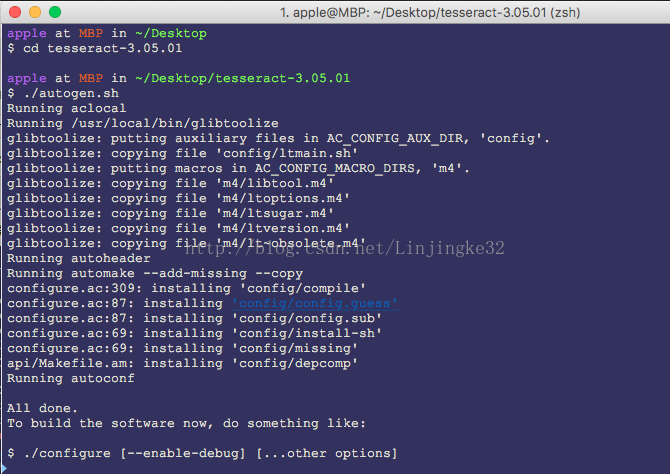
按照提示,继续下一步:
./configure CC=gcc CXX=g++ CPPFLAGS=-I/usr/local/opt/icu4c/include LDFLAGS=-L/usr/local/opt/icu4c/lib
报如下错误:
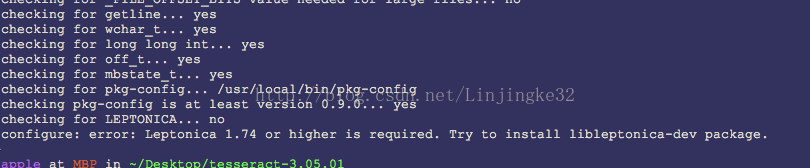
囧~居然还不支持当前系统版本,目前brew下载的最高是1.72版本,但是要求1.74版本,因此,brew remove liptonica,采用手动下载源码的方式来安装这个依赖,现在去下载1.74.2版本的,下载解压后目录结构如下:
为了生成configure文件,这里先执行"./autobuild"脚本:
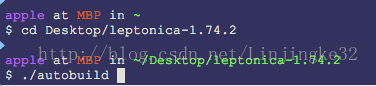
完成后,执行"./configure",从而生成makefile文件:

然后执行"make && make install"即可,接着,导出环境变量,也可以通过修改"~/.bash_profile"永久修改:

安装完成Leptonica1.74版本后,进入tesseract根目录:
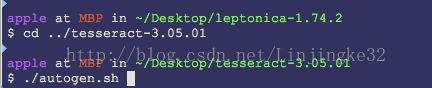
执行完,执行configure生成makefile文件:

然后执行"make && make install"即可。
如果要生成训练工具,用于对文字识别进行训练,还可继续执行:"make training && make training-install"即可。
重启命令行终端,如下输出即安装成功tesseract:
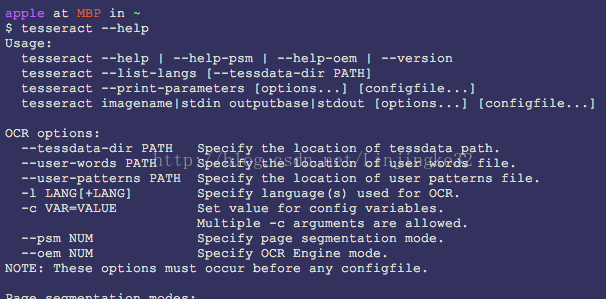
下面使用一张图片来试下识别效果怎样,为了识别中文,还需要中文字库,去百度找到下载即可:

解压后把字库拉到一个文件夹先,先测试功能行不行,按照命令行提示操作,包如下错误:
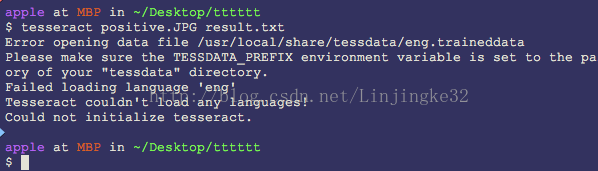
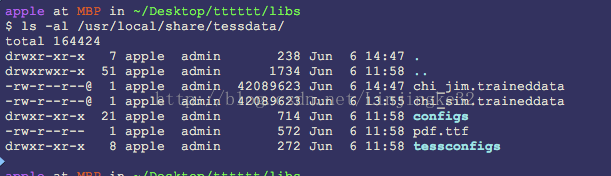
原来字库是要放到/usr/local/share/tessdate下,看看那里现在有什么:
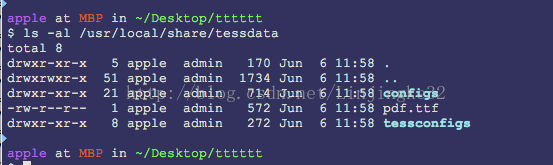
现在把下载的中文字库放到这个目录下:
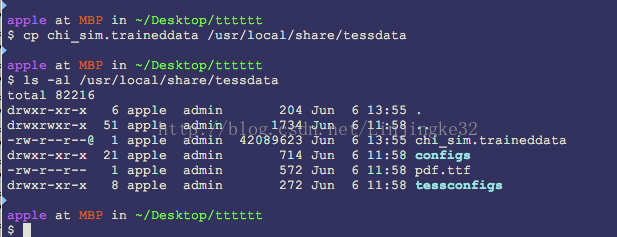
现在来试试识别这张图片:
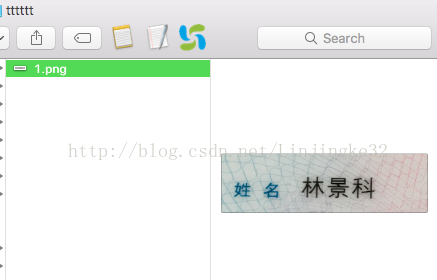
命令如下:(也可通过java代码方式调用,有库tess4j可以使用,具体可以了解下,其源码地址:http://sourceforge.jp/projects/sfnet_tess4j/)

识别结果如下:

"名'"这个字识别不了。
---------------------------------------------------
下面来训练一下,下载jTessBoxEditor,它需要Java环境的支持,这里我下载1.7.3版本的:

下载完成解压后目录如下:
准备几张图片来进行识别的图片库,如下:
这里的三张图片其实是一样的,复制而已,偷下懒,其实可以自己从不同角度拍照获取作为识别,这样后期的识别精度更高。
运行jTessBoxEditor:
注意,图片需要是tiff格式,用于后面生成box文件,还有一点,图片的命名有要求:[lang].[fontname].exp[num].tiff,lang是语言,fontname是字体,num是编号,现在需要训练自定义字库name字体名为jim,则命名为: name.jim.exp0.tiff,最后修改为如下:
进入jTessBoxEdtior,选择菜单栏如下:
弹出如下窗口,选择我们的三张图片,然后输入名称,点击"Save":
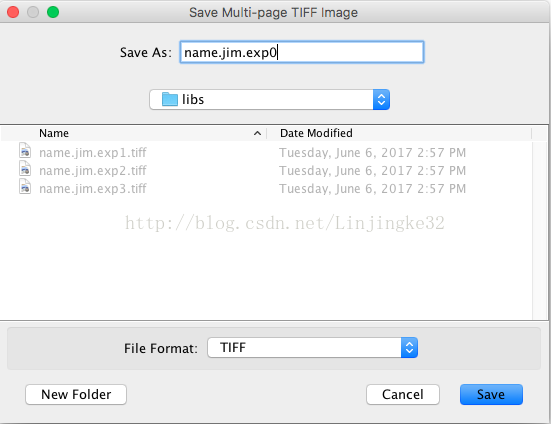
合并后的图片如下:

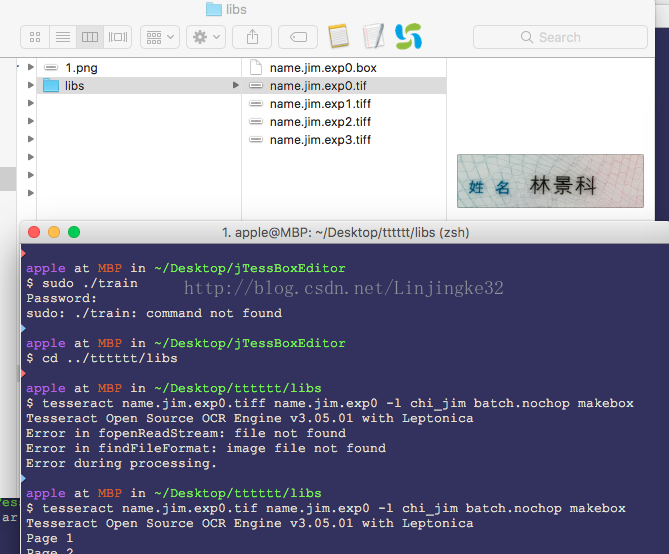
接下来,生成BoxFile文件:(为了便于测试,我们复制刚刚的一份字库,命名为chi_jim),如下:
生成:
现在软件切换到BoxEditor界面:
然后打开刚刚合并的tif图片文件:
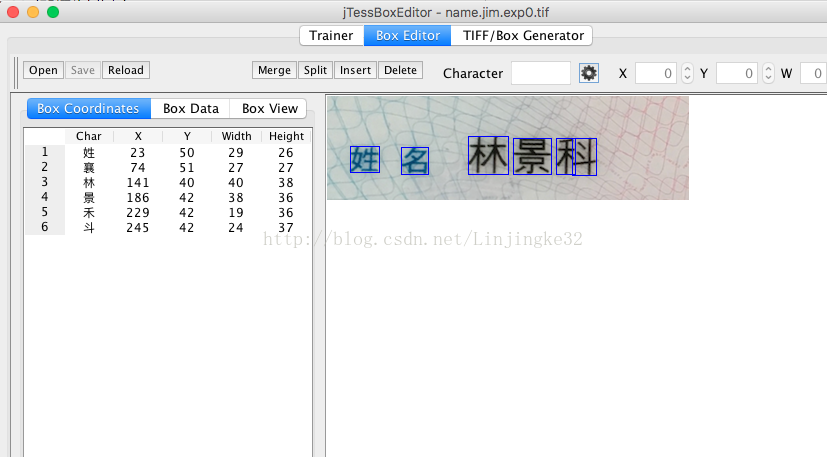
我们手动修改错误的地方,合并“禾”与“斗”,结果如下,然后点击"Save"保存矫正后的数据:
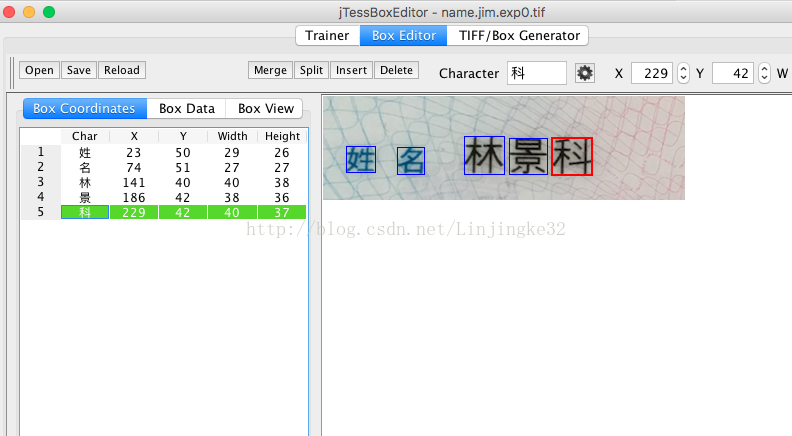
现在就进行训练,生成了tr后缀的文件:
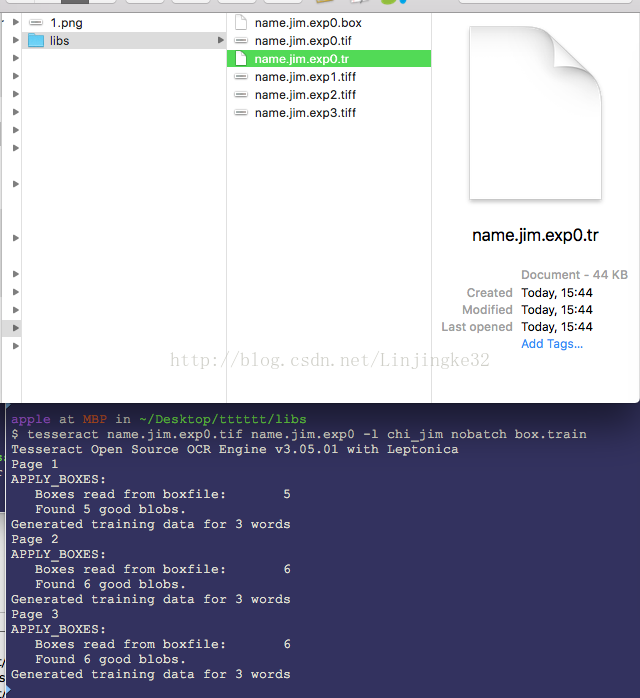
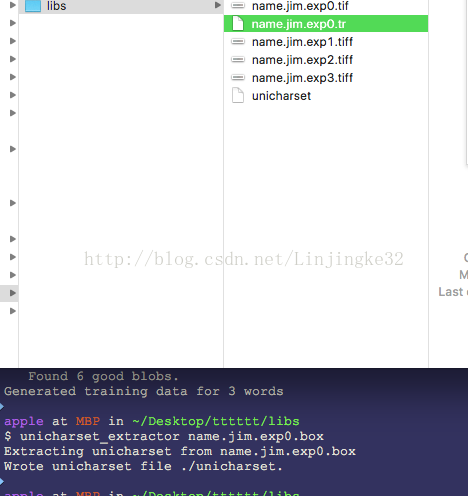
生成unicharset文件:
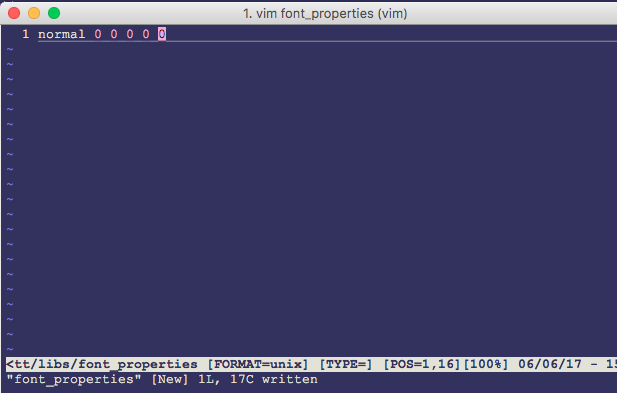
新建文件:

文件内容为:
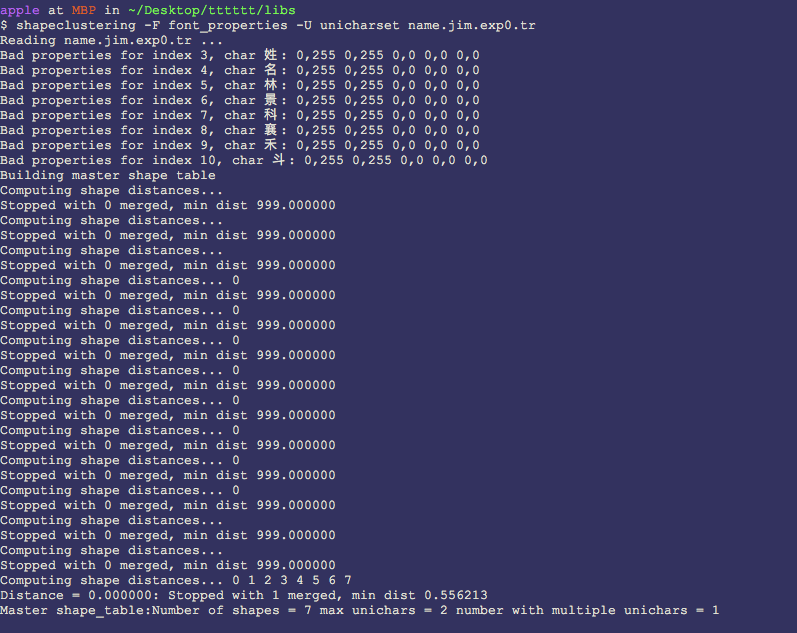
继续执行如下命令:
1.
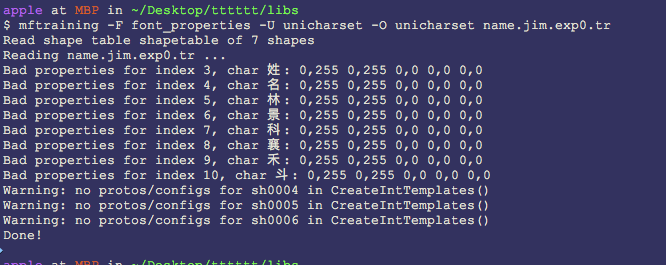
2.
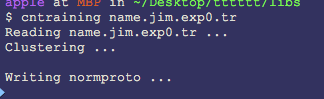
3.
最后目录如下:
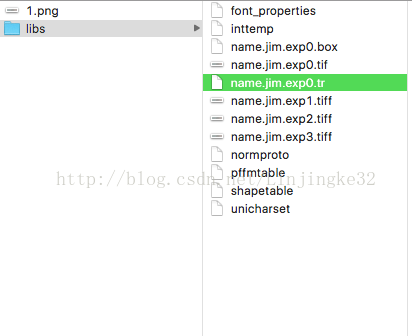
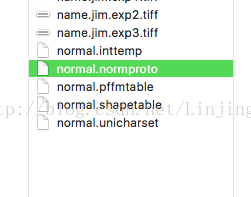
现在将unicharset、inttemp、pffmtable、shapetable、normproto这5个文件前面都加上"normal.":如下:
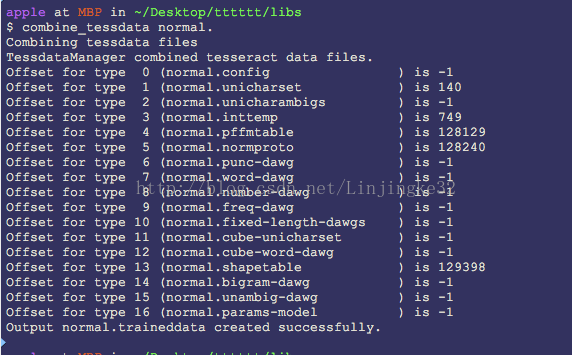
最后,生成训练结果文件:
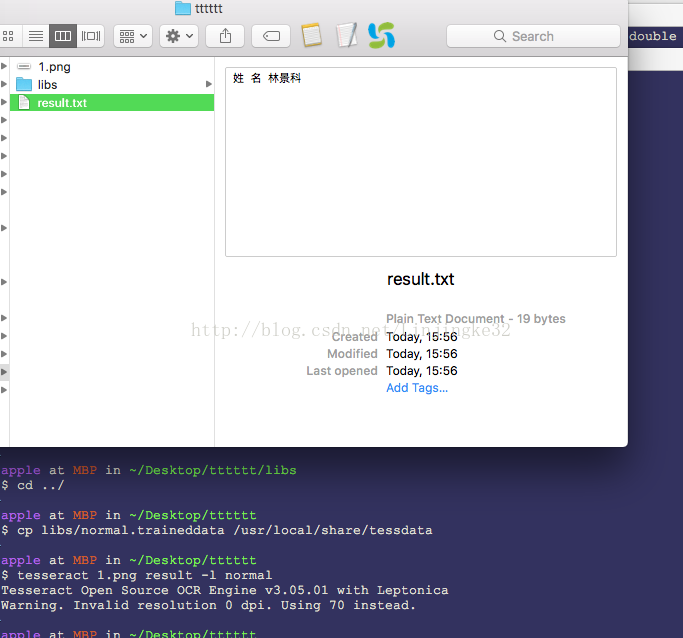
把这个文件拷贝到字库路径下,并重新识别一次看看效果怎样,可以看到,训练后识别都正确了:
后面就是根据需要,不断完善自己的语言识别库了,步骤也类似这样去进行处理。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









