






目录
3,设置kibana-7.13.4-linux-x86_64目录的所属用户和所属组为es。
一、全文搜索
1,数据分类
结构化数据:固定格式,有限长度,比如数据库(MySQL,PostgreSQL)存的数据
非结构化数据:不定长,无固定格式 比如邮件,word文档,日志
半结构化数据:前两者结合。比如xml,html网页
2,搜索分类:
结构化数据搜索:使用关系型数据库
非结构化数据搜索:
- 顺序扫描
- 全文检索
设想一个关于搜索的场景,假设要搜索一首诗句内容中带有“前”字的古诗
| name | content | author |
| 静夜思 | 床前明月光,疑是地上霜,举头望明月,低头思故乡 | 李白 |
| 望庐山瀑布 | 日照香炉生紫烟,遥看瀑布挂前川。飞流直下三千尺,疑是银河落九天 | 李白 |
| ... | ... | ... |
如果使用数据库的SQL来存储古诗的话,应使用这样的SQL查询
select name from poems where content like "%前%";这种使用SQL查询的方式称为顺序扫描法,需要遍历所有的记录进行匹配,不但效率低,而且不符合我们搜索时的期望数据~
所以,采用es的全文检索的方式,可以大幅提升我们搜索数据的效率~
3,什么是全文搜索
全文检索是指:
-
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置,以及出现的次数
-
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置,出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
示例:csdn搜索关键词查找对应信息
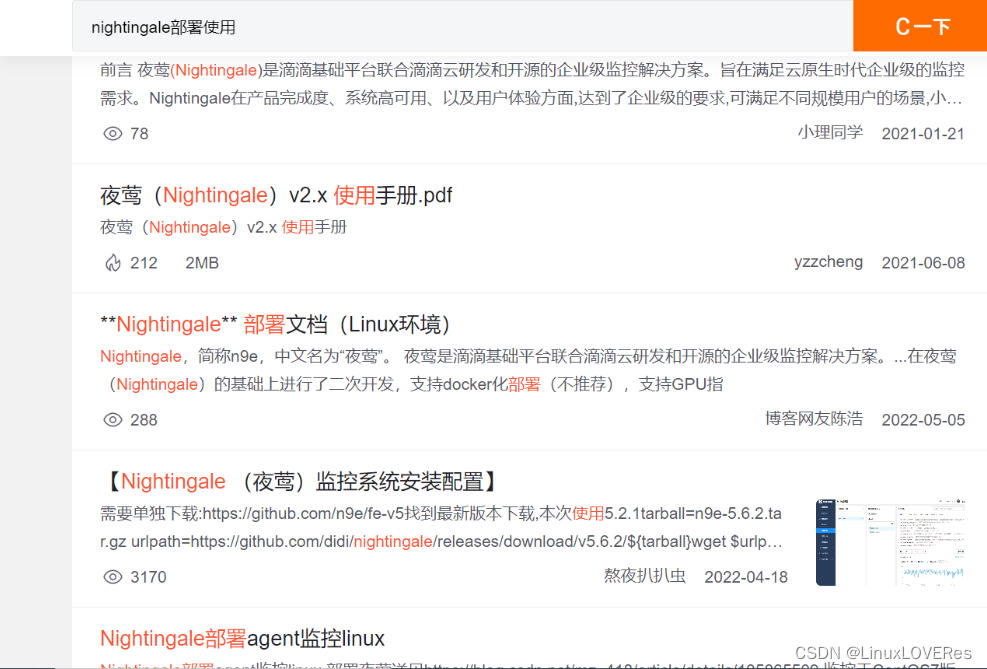
如上图,如果使用SQL的模糊匹配,则搜索结果对应应该是包含“nightingale部署使用”这个关键字的信息才会被匹配出来。
而根据上图搜索匹配出来的结果看,显然不是通过模糊匹配来搜索的。首先根据搜索出来的结果看,此搜索操作是被分词后的了,所以无论是匹配到nightingale部署,还是匹配到nightingale使用等其他一些关键词,都会匹配搜索出结果来。包括文章中出现对应分词的信息,也会被高亮显示出来~
简单理解搜索步骤原理主要概况为以下几个步骤:
-
内容爬取,停顿词过滤比如一些无用的像“的”,“了” 之类的语气词/连接词
-
内容分词,提取关键词
-
根据关键词建立倒排索引
-
用户输入关键词进行搜索
倒排索引
索引就类似于目录,平时我们使用的索引,都是通过主键定位到某条数据,那么倒排索引,刚好相反,数据对应到主键
示例图:
 这里以一个博客文章的内容举例,来查看正排索引和倒排索引的区别~
这里以一个博客文章的内容举例,来查看正排索引和倒排索引的区别~
正排索引(正向索引)
| 文章ID | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 浅析JAVA设计模式 | JAVA设计模式是每一个JAVA程序员都应该掌握的进阶知识 |
| 2 | JAVA多线程设计模式 | JAVA多线程与设计模式结合 |
如上表格,正排索引可以根据主键id对应查询文章标题和文章内容
倒排索引(反向索引)
| 关键词 | 文章ID |
|---|---|
| JAVA | 1,2 |
| 设计模式 | 1,2 |
| 多线程 | 2 |
假如,我们有一个站内搜索的功能,通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种,我们可以称之为倒排索引。
总结:
-
倒排索引:是数据关键词对应主键
-
正排索引:主键对应具体数据
二、ElasticSearch简介
1,ElasticSearch是什么
ElasticSearch(简称ES)是一个分布式、RESTful风格的搜索和数据分析引擎,是用Java开发并开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
客户端Java、.NET(c#)、PHP、Python、Ruby等多种语言。
官方网站:Elasticsearch Platform — Find real-time answers at scale | Elastic
下载地址:Download Elasticsearch | Elastic
2,ElasticSearch特点:
-
支持分布式,可水平扩展
-
降低全文检索的学习曲线,可以被任何编程语言调用
-
分片与副本机制,直接解决了集群下性能与高可用问题。
3,ElasticSearch版本特性:
5.x新特性:
-
默认打分机制从TF-IDF改为BM25
-
内部引擎移除了避免同一文档并发更新的竞争锁,带来15%~20%的性能提升
-
Instant aggregation支持分片,上聚合的缓存
-
新增了Profile API
6.x新特性:
-
跨集群复制(CCR)
-
索引生命周期管理
-
SQL的支持
-
更友好的升级和数据迁移
-
在主要版本之间的迁移更为简化;
-
全新的基于操作的数据复制框架,可加快恢复数据;
-
-
性能优化
-
有效存储稀疏字段的新方法,降低了存储成本
-
在索引时进行排序,可加快排序的查询性能
-
7.x新特性:
重大改进:正式废除单个索引下多Type的支持
7.1开始,Security功能免费使用
ECK-Elasticsearch Operator on kubernetes
新功能
-
New Cluster coordination
-
Feature--Complete High Level REST Client
-
Script Score Query
性能优化
-
默认的Primary Shard数从5改为1,避免Over Sharding
-
性能优化,更快的Top K
8.x新特性:
-
Rest API相比较7.x而言做了比较大的改动(比如彻底删除type)
-
默认开启安全配置
-
存储空间优化:对倒排文件使用新的编码集,对于keyword、match_only_text类型字段有效,有3.5%的空间优化提升,对于新建索引和segment自动生效
-
优化geo_point,geo_shape类型的索引(写入)效率:15%的提升
-
技术预览版KNN API发布,(K邻近算法),跟推荐系统、自然语言排名相关。
4,Elastic生态圈--Elastic Stack介绍
首先,我们经常说的日志搜集分析系统ELK系统分别是Elasticsearch,Logstash,Kibana三款软件的简称,在发展的过程中又有新的成员Beats的加入,就形成了Elastic Stack。

指标分析/日志分析
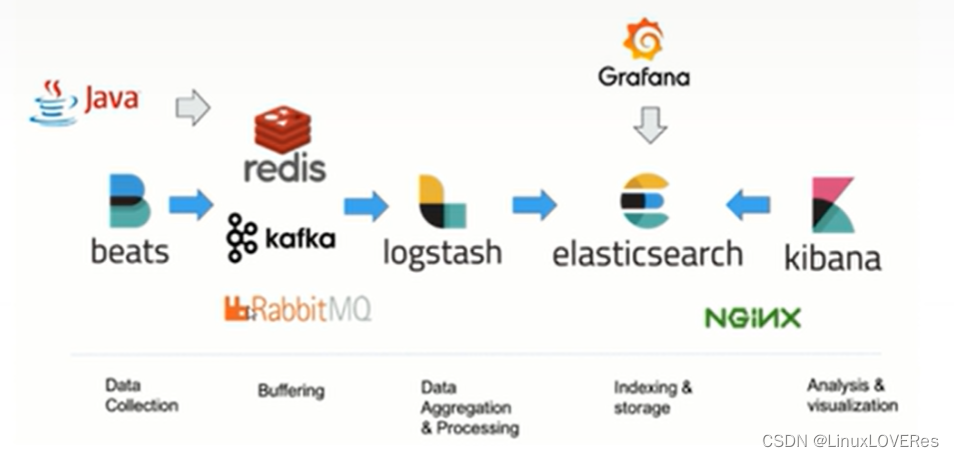
-
利用Java程序或beats搜集各种中间件、或Java程序的日志;
-
将搜集到的日志数据写入到redis、或kafka、rabbitmq等各种mq消息队列中;
-
利用logstash对收集到的日志做过滤(数据分析,将主要报错或一些重要字段数据取出),并将数据转为json格式;
-
logstash将数据处理完成后,将数据持久化存储到elasticsearch中;
-
最后,使用可视化工具kibana或Grafana将数据可视化展示;
-
另外,可以配置使用nginx做一些安全策略(如限制ip访问等~)
5,ElasticSearch应用场景
-
站内搜索
-
日志管理和分析
-
大数据分析
-
应用性能监控
-
机器学习
6,ElasticSearch单机版部署安装
1,环境准备
-
操作系统:CentOS7.6
-
CPU:1核1G
-
内存:4G
-
软件版本:elasticsearch-7.13.4
注意:不同版本的es所需环境不同,es5需要安装java环境,需要jdk8以上的版本;
es从6.5开始支持java11,es从7.0开始,内置了java环境 ~~~
2,下载elasticsearch压缩包(Linux版本)
[root@ecs-69416390 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.4-linux-x86_64.tar.gz3,创建es用户
在Linux中添加一个普通用户:es 【目前ES不支持root用户启动】
[root@ecs-69416390 ~]# useradd -d /es -m es #创建es用户并生成es用户的家目录
[root@ecs-69416390 ~]# passwd es #设置es用户的登录密码4,修改参数
修改Linux中最大文件描述符以及最大虚拟内存的参数。
因为ES对Linux的最大文件描述符以及最大虚拟内存有一定要求,所以需要修改。否则ES无法正常启动。
[root@localhost ~]# vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096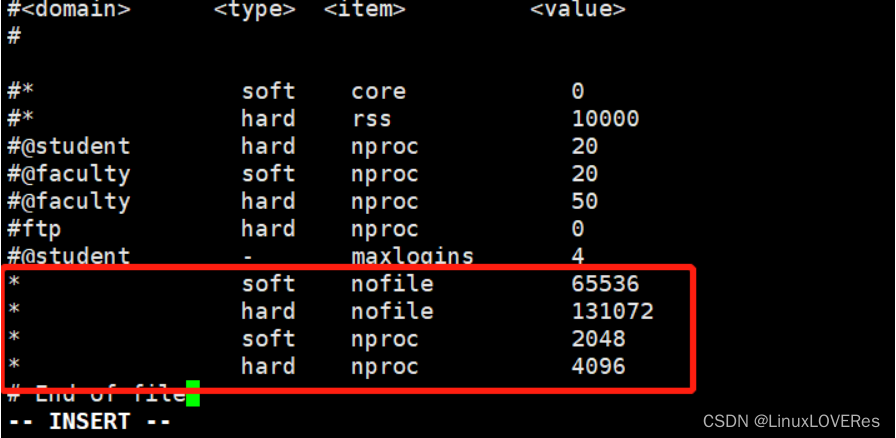
修改最大虚拟内存
[root@localhost ~]# vi /etc/sysctl.conf
vm.max_map_count=262144
5,配置主机名,重启系统
配置主机名,重启Linux系统。
前面修改的Linux的一些系统参数需要重启系统后才会生效。
[root@localhost ~]# hostnamectl set-hostname elasticsearch01
[root@elasticsearch01 ~]# vi /etc/hosts
...
...
192.168.48.201 elasticsearch01
[root@localhost ~]# reboot -h now6,解压ES安装包
解压ES安装包到es用户的家目录下面。
[root@localhost ~]# tar -zxvf elasticsearch-7.13.4-linux-x86_64.tar.gz
[root@localhost ~]# mv elasticsearch-7.13.4/ /es/7,配置Java环境变量
在profile文件中配置ES_JAVA_HOME环境变量,指向ES中内置的JDK。
[root@localhost ~]# vi /etc/profile
...
export ES_JAVA_HOME=/es/elasticsearch-7.13.4/jdk/
export PATH=$PATH:$ES_JAVA_HOME/bin
...
[root@localhost ~]# source /etc/profile
8,修改目录所属属组
修改elasticsearch-7.13.4目录所属的属组。
因为前面是使用root用户解压的,elasticsearch-7.13.4目录下的文件es用户是没有权限的。
[root@localhost ~]# chown -R es:es /es/elasticsearch-7.13.4/9,修改ElasticSearch的配置文件。
[root@localhost ~]# vi /es/elasticsearch-7.13.4/config/elasticsearch.yml
...
# ---------------------------------- Cluster -----------------------------------
...
cluster.name: comment-es
# 集群名称
...
# ------------------------------------ Node ------------------------------------
...
node.name: node-1
# 节点名称
...
# ---------------------------------- Network -----------------------------------
network.host: 192.168.26.10
# 为ES设置绑定的IP
http.port: 9200
# 为ES服务设置监听的端口
...
# --------------------------------- Discovery ----------------------------------
cluster.initial_master_nodes: ["node-1"]
# 初始化具备主节点资格的节点,在选择主节点时,会优先在这一批列表中进行选择
...
# ---------------------------------- Various -----------------------------------
...
xpack.security.enabled: true #开启安全策略
xpack.security.transport.ssl.enabled: true #开启安全策略10,切换用户
切换到es用户
[root@localhost ~]# su es11,启动elasticsearch服务
(1.)前台启动ES服务
[es@elasticsearch01 elasticsearch-7.13.4]$ bin/elasticsearch(2.)后台启动ES服务
在实际生产环境中,需要将ES放到后台运行。
[es@elasticsearch01 elasticsearch-7.13.4]$ bin/elasticsearch -d12,设置es安全访问的密码
此处密码设置均自定义设置,即执行命令后根据提示输入密码即可。
[es@elasticsearch01 elasticsearch-7.13.4]$ ./bin/elasticsearch-setup-passwords interactive
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana_system]:
Reenter password for [kibana_system]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]13,验证
验证ES服务。
通过jps命令或者jcmd命令验证进程是否存在。
[es@elasticsearch01 elasticsearch-7.13.4]$ jps
1314 Elasticsearch
8786 Jps
[es@elasticsearch01 elasticsearch-7.13.4]$ jcmd
8800 jdk.jcmd/sun.tools.jcmd.JCmd
1314 org.elasticsearch.bootstrap.Elasticsearch通过web界面访问验证是否可以正常访问。

到此,ElasticSearch部署完成 ~~~
7,客户端Kibana部署安装
Kibana是一个开源分析和可视化平台,旨在与ElasticSearch协同工作。
1,下载kibana安装包。
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.4-linux-x86_64.tar.gz
# 注意:安装的kibana客户端的版本必须和elasticsearch的版本完全一致~
# 官网下载慢可以使用华为云镜像下载:https://mirrors.huaweicloud.com/home2,解压kibana tar包至es目录下
[root@elasticsearch01 ~]# tar -zxvf kibana-7.13.4-linux-x86_64.tar.gz -C /es/3,设置kibana-7.13.4-linux-x86_64目录的所属用户和所属组为es。
[root@elasticsearch01 es]# chown -R es:es kibana-7.13.4-linux-x86_64/4,修改kibana配置文件~
[root@elasticsearch01 kibana-7.13.4-linux-x86_64]# vi config/kibana.yml
...
server.port: 5601
# kibana服务端口
...
server.host: "192.168.26.10"
...
elasticsearch.hosts: ["http://192.168.26.10:9200"]
...
elasticsearch.username: "elastic" #此处为明文配置的es密码
elasticsearch.password: "自定义的elastic密码"
...
xpack.reporting.encryptionKey: "a_random_string"
xpack.security.encryptionKey: "something_at_least_32_characters"
...
i18n.locale: "zh-CN"5,启动kibana服务并验证是否启动成功
[es@elasticsearch01 kibana-7.13.4-linux-x86_64]$ nohup ./bin/kibana &
[root@elasticsearch01 kibana-7.13.4-linux-x86_64]# netstat -uptln |grep 5601
tcp 0 0 192.168.26.10:5601 0.0.0.0:* LISTEN 18982/node通过浏览器访问 http://192.168.26.10:5601/login?next=%2F 验证kibana服务

输入用户名密码:elastic,elastic
三、ElasticSearch使用操作
1,ElasticSearch常用cat API
/_cat/allocation # 查看单节点的$hard分配整体情况
/_cat/shards # 查看各shard的详细情况
/_cat/shards/{index} # 查看指定分片的详细情况
# 示例:GET /_cat/shards/.kibana-event-log-7.13.4-000001
/_cat/master # 查看master节点信息
/_cat/nodes # 查看所有节点信息
/_cat/indices # 查看集群中所有index的详细信息
/_cat/indices/{index} # 查看集群中指定index的详细信息
# 示例:GET /_cat/indices/.tasks
/_cat/segments # 查看各index的segment详细信息,包括segment名,所属shard,内存(磁盘)占用大小等
/_cat/segments/{index} # 查看指定index的segment详细信息
/_cat/count # 查看当前集群的doc数量
/_cat/count/{index} # 查看指定索引的doc数量
/_cat/recovery # 查看集群内每个shard的recovery过程,调整replica。
/_cat/recovery/{index} # 查看指定索引$hard的recovery过程
/_cat/health # 查看集群当前状态:红、黄、绿
/_cat/pending_tasks # 查看当前集群的pending task
/_cat/aliases # 查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} # 查看指定索引的alias信息
/_cat/thread_pool # 查看集群各节点内部不同类型的threadpool的统计信息
/_cat/plugins # 查看集群各个节点上的plugin信息
/_cat/fielddata # 查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} # 查看指定field的内存使用情况
/_cat/nodeattrs # 查看单节点的自定义属性
/_cat/repositories # 输出集群中组测快照存储库
/_cat/templates # 输出当前正在存在的模板信息2,Elasticsearch安装插件
安装分词器插件,这里安装ik分词器插件和icu分词器插件。
1,)离线安装ik分词器。
本地下载相应的插件,解压。然后手动上传到elasticsearch的plugins目录,然后重启ES示例就可以了
[root@elasticsearch01 ~]# cd /es/elasticsearch-7.13.4/plugins/
[root@elasticsearch01 plugins]# mkdir ik && cd ik
[root@elasticsearch01 plugins]# unzip elasticsearch-analysis-ik-7.13.4.zip
[root@elasticsearch01 plugins]# rm -rf elasticsearch-analysis-ik-7.13.4.zip2,)在线安装icu分词器。
# 查看已安装插件
[es@elasticsearch01 elasticsearch-7.13.4]$ bin/elasticsearch-plugin list
# 安装插件
[es@elasticsearch01 elasticsearch-7.13.4]$ bin/elasticsearch-plugin install analysis-icu
# 删除插件
[es@elasticsearch01 elasticsearch-7.13.4]$ bin/elasticsearch-plugin remove analysis-icu注意:安装和删除完插件后,需要重启ES服务才能生效。
# 杀掉es进程
[es@elasticsearch01 elasticsearch-7.13.4]$ kill 9387
# 重启es服务
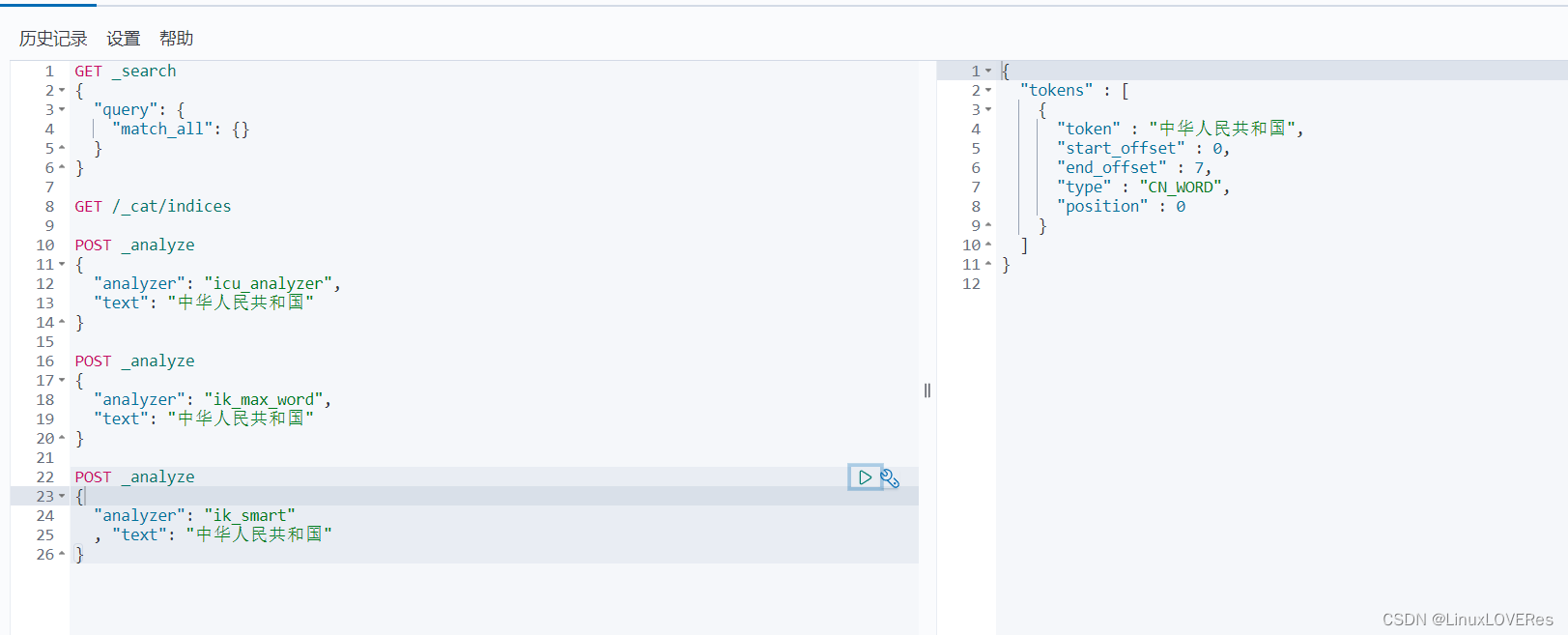
[es@elasticsearch01 elasticsearch-7.13.4]$ ./bin/elasticsearch -d3,)使用分词器测试分词效果
icu分词效果
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "中华人民共和国"
}
ik分词效果
# 按最大词组分词
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
# 按最少词组分词
POST _analyze
{
"analyzer": "ik_smart"
, "text": "中华人民共和国"
}最大分词:

最少分词
3,Elasticsearch索引操作
官网文档地址:[Elasticsearch Guide 7.13] | Elastic
创建索引
索引命名必须小写,不能以下划线开头
格式:PUT /索引名称
# 创建索引
PUT /es_db
# 创建成功后返回:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "es_db"
}
# 创建索引时可以设置分片数和副本数
# 如果有多个elasticsearch节点,可以设置多个分片,比如如果有3个节点,可以指定设置3个分片,将索引数据分成3分放到3个节点上。
PUT /es_db
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
# 修改索引配置
PUT /es_db/_settings
{
"index" : {
"number_of_replicas" : 1
}
}查询索引
格式:GET /索引名称
# 查询索引
GET /es_db
# 查询后输出一些信息:
{
"es_db" : {
"aliases" : { }, # 索引别名
"mappings" : { }, # 映射,索引有数据之后 会存放数据类型~
"settings" : { # 设置
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1", # 索引分片
"provided_name" : "es_db", # 索引名称
"creation_date" : "1680163838332", # 创建时间
"number_of_replicas" : "1", # 副本
"uuid" : "tfWi352WT9WvvhriwslZqA",
"version" : {
"created" : "7130499"
}
}
}
}
}
# es_db索引是否存在
HEAD /es_db删除索引
格式:DELETE /索引名称
DELETE /es_db4,ElasticSearch基本概念
ElasticSearch与传统关系型数据库的区别:
-
Elasticsearch Schemaless /相关性/高性能全文检索
-
RDMS 事务性 / join

索引(Index)
一个索引就是一个拥有相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对对应这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
{
"es_db" : {
"aliases" : { }, # 索引别名
"mappings" : { }, # 映射,索引有数据之后 会存放数据类型~
"settings" : { # 设置
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1", # 索引分片
"provided_name" : "es_db", # 索引名称
"creation_date" : "1680163838332", # 创建时间
"number_of_replicas" : "1", # 副本
"uuid" : "tfWi352WT9WvvhriwslZqA",
"version" : {
"created" : "7130499"
}
}
}
}
}文档(Document)
-
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位。
-
日志文件中的日志项
-
一部电影的具体信息/一张唱片的详细信息
-
MP3播放器里的一首歌/一篇PDF文档中的具体内容
-
-
文档会被序列化成JSON格式,保存在Elasticsearch中
-
JSON对象由字段组成
-
每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
-
-
每个文档都有一个Unique ID
-
可以自己指定ID或者通过Elasticsearch自动生成
-
-
一篇文档包含了一系列字段,类似数据库表中的一条记录
-
JSON文档,格式灵活,不需要预先定义格式
-
字段的类型可以指定或者通过Elasticsearch自动推算
-
支持数组/支持嵌套
-
文档元数据

元数据,用于标注文档的相关信息:
_index:文档所属的索引名
_type:文档所属的类型名
_id:文档唯一id
_source:文档的原始json数据
version:文档的版本号,修改删除操作version都会自增
seq_no:和version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的seq_no大于先写入的Doc的seq_no。
primory_term:primory_term主要是用来恢复数据时处理当多个文档的seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primory_term会递增1。
5,ElasticSearch文档操作
1,添加文档
- 格式:[PUT | POST /索引名称/[_doc | _create ]/id
# 创建文档,指定id
# 如果id不存在,创建新的文档,否则先删除现有文档,再创建新的文档,版本会增加
PUT /es_db/_doc/1
{
"name":"张三",
"sex":1,
"age":25,
"address":"广州天河公园",
"remark":"java developer"
}
# 输出:
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
# PUT方式创建文档,它底层会根据id查看这条数据是否存在,如果存在则会删除这条文档,再新增(类似于全量更新操作),比如下面示例,将id为1的文档修改。
PUT /es_db/_doc/1
{
"name":"张三xxx",
"address":"广州天河公园",
"remark":"java developer"
}
# 输出:可以看出此时version版本为2,result为update
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
# 查看新增的这条文档数据:
GET /es_db/_doc/1
# 输出:
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三xxx",
"address" : "广州天河公园",
"remark" : "java developer"
}
}
# 使用POST创建文档,ES自动生成id
POST /es_db/_doc
{
"name":"张三",
"sex":1,
"age":25,
"address":"广州天河公园",
"remark":"java developer"
}
# 使用POST修改文档
POST /es_db/_doc/FuGtNYgBnLz27AmKfPQf
{
"name":"李四xxx",
"sex":1,
"age":26,
"address":"深圳金沙湾公园",
"remark":"java developer"
}
# 输出:
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "FuGtNYgBnLz27AmKfPQf",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
总结:POST和PUT都能起到创建/更新的作用,PUT需要对一个具体的资源进行操作也就是要确定id才能进行更新/创建;而POST是可以针对整个资源集合进行操作的,如果不写id就有ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新注意:语法中的_create语法,如果ID已经存在,再使用create创建就会失败。
一般_create语法用于多线程并发场景。
# 例如:针对es_db索引中id为1的文档做新增操作。
POST /es_db/_create/1
{
"name":"李四xxx",
"address":"广州天河公园",
"remark":"java developer"
}接口报错:提示该文档已存在

2,修改文档
-
全量更新,整个json都会替换,格式:[PUT | POST]/索引名称/_doc/id
如果文档存在,现有文档会被删除,新的文档会被索引
# 全量更新,替换整个json
PUT /es_db/_doc/1/
{
"name":"张三",
"sex":1,
"age":25
}
-
使用update部分更新,格式:POST /索引名称/update/id
update不会删除原来的文档,而是实现真正的数据更新
# 部分更新:在原有文档上更新
# Update - 文档必须已经存在,更新只会对相应字段做增量修改
POST /es_db/_update/1
{"doc": {
"age":26,
"address":"北京工人体育广场"
}
}
# 查看索引文档
GET /es_db/_doc/1
# 输出:
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "1",
"_version" : 5,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三",
"sex" : 1,
"age" : 26,
"address" : "北京工人体育广场"
}
}- 使用_update_by_query更新文档
POST /es_db/_update_by_query
{
"query": {
"match": {
"_id": "FuGtNYgBnLz27AmKfPQf"
}
},
"script": {
"source": "ctx._source.age = 30",
"lang": "painless"
}
}根据id查看对应文档,age字段已更改

修改指定索引的name字段
 3,查询文档
3,查询文档
- 根据id查询文档,格式:GET /索引名称/_doc/id
GET /es_db/_doc/1 # 查询索引为1的文档数据- 条件查询search,格式:GET /索引名称/doc/_search,默认查询前10条文档
# 查询前10条文档
GET /es_db/_doc/_searchES Search API 提供了两种条件查询搜索方式:
-
REST风格的请求URI,直接将参数带过去
-
封装到request body中,这种方式可以定义更加易读的JSON格式
# search条件查询
1,)term精确查找文档数据
GET /es_db/_search
{
"query": {
"term": {
"name": {
"value": "张三" # 查询name字段是张三的索引文档
}
}
}
}
# 使用match查询address中有工人体育的索引文档
GET /es_db/_search
{
"query": {
"match": {
"address": "工人体育"
}
}
}
常用search条件查询
# 通过URI搜索,使用"q"指定查询字符串,"query string syntax" KV键值对
# 条件查询,如果查询age等于25岁的 _search?q=*:***
GET /es_db/_search?q=age:25
# 范围查询,如果查询的age在25岁至27岁之间的,_search?q=***[** TO **] 注意:TO 必须为大写
GET /es_db/_search?q=age[25 TO 27]
# 查询年龄小于等于27岁的 :<=
GET /es_db/_search?q=age:<=27
# 查询年龄大于27岁的 :>
GET /es_db/_search?q=age:>27
# 分页查询 from=*&size=*
GET /es_db/_search?q=age[25 TO 28]&from=0&size=1 # 从第一页(索引0)开始,每页展示1条数据
# 对查询结果只输出某些字段 _source=字段,字段
GET /es_db/_search?_source=name,age,remark # 只查询名称,年龄,职业
# 对查询结果排序 sort=字段:desc/asc
GET /es_db/_doc/_search?sort=age:desc- ES Search API 提供了SQL查询方式,可以使用SQL条件匹配查询数据。
# SQL 方式查询文档,注意后面不能带;
POST _sql?format=json
{
"query": """
SELECT * FROM "es_db" where name = '王五'
"""
}输出结果:

4,删除文档操作
格式:DELETE /索引名称/_doc/id
DELETE /es_db/_doc/F-G4NYgBnLz27AmKVPS45,ElasticSearch文档批量写入操作
批量对文档进行写操作是通过_bulk的API来实现的
-
请求方式:POST
-
请求地址:_bulk
-
请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
-
第一行参数为指定操作的类型及操作的对象(index,type和id)
-
第二行参数才是操作的数据
-
参数格式类似于:
{"actionName":{"_index":"indexName","_type":"typeName","_id":"id"}}
{"field1":"value1","field2":"value2"}- actionName:表示操作类型,主要有create,index,delete和update
批量创建文档create
POST _bulk
{"create":{"_index":"user_db","_type":"_doc","_id":1}}
{"id":1,"city":"哈尔滨","temperture":"25摄氏度"}
{"create":{"_index":"user_db","_type":"_doc","_id":2}}
{"id":2,"city":"长春","temperture":"26摄氏度"}
{"create":{"_index":"user_db","_type":"_doc","_id":3}}
{"id":3,"city":"沈阳","temperture":"27摄氏度"}
{"create":{"_index":"user_db","_type":"_doc","_id":5}}
{"id":5,"city":"大连","temperture":"27摄氏度"}普通创建或全量替换index
POST _bulk
{"index":{"_index":"user_db","_type":"_doc","_id":1}}
{"id":1,"city":"哈尔滨","temperture":"25摄氏度"}
{"index":{"_index":"user_db","_type":"_doc","_id":2}}
{"id":2,"city":"长春","temperture":"26摄氏度"}
{"index":{"_index":"user_db","_type":"_doc","_id":3}}
{"id":3,"city":"沈阳","temperture":"27摄氏度"}
{"index":{"_index":"user_db","_type":"_doc","_id":5}}
{"id":5,"city":"大连","temperture":"27摄氏度"}-
如果原文档不存在,则是创建
-
如果原文的存在,则是替换(全量修改原文档)
批量删除delete
POST _bulk
{"delete":{"_index":"user_db","_type":"_doc","_id":3}}
{"delete":{"_index":"user_db","_type":"_doc","_id":4}}
# 将索引为3和索引为4的文档数据删除批量修改update
POST _bulk
{"update":{"_index":"user_db","_type":"_doc","_id":1}}
{"doc":{"temperture":"30摄氏度"}}
{"update":{"_index":"user_db","_type":"_doc","_id":2}}
{"doc":{"temperture":"31摄氏度"}}
{"update":{"_index":"user_db","_type":"_doc","_id":3}}
{"doc":{"temperture":"32摄氏度"}}
{"update":{"_index":"user_db","_type":"_doc","_id":5}}
{"doc":{"temperture":"33摄氏度"}}组合应用
POST _bulk
{"delete":{"_index":"user_db","_type":"_doc","_id":"EuGSNYgBnLz27AmKKPT_"}}
{"index":{"_index":"user_db","_type":"_doc","_id":4}}
{"id":6,"city":"昆明","temperture":"34摄氏度"}
{"update":{"_index":"user_db","_type":"_doc","_id":5}}
{"doc":{"temperture":"33摄氏度"}}
# 先删除索引为EuGSNYgBnLz27AmKKPT_的文档数据,然后创建索引为4的文档数据,然后更新索引为5的文档中的temperture字段批量读取
GET _mget
{"docs":[{"_index":"es_db","_id":1},{"_index":"user_db","_id":1}]}
# 可以通过id批量获取es_db的数据
GET /es_db/_mget
{
"ids":["1","2","3","4"]
}6,ES检索原理分析
索引的原理
索引是加速数据查询的重要手段,其核心原理是通过不断的缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件。
磁盘IO与预读
磁盘IO是程序设计中非常高昂的操作,也是影响程序性能的重要因素,因此应当尽量避免过多的磁盘IO,有效的利用内存可以大大的提升程序的性能。在操作系统层面,发生一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,局部预读性原理告诉我们,当计算机访问一个地址的数据时,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
倒排索引
当数据写入ES时,数据将会通过 分词 被切分为不同的term,ES将term与其对应的文档列表建立一种映射关系,这种结构就是 倒排索引。如下图所示:

为了进一步提升索引的效率,ES在term的基础上利用term的前缀或者后缀构建了term index,用于对term本身进行索引,ES实际的索引结构如下图所示:

这样当我们去搜索某个关键词时,ES首先根据它的前缀或者后缀迅速缩小关键词在term dictionary 中的范围,大大减少了磁盘IO的次数。
-
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系
-
倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成
-
倒排索引项(Posting):
-
文档ID
-
词频TF:该单词在文档中出现的次数,用于相关性评分
-
位置(Position):单词在文档中分词的位置,用于短语搜索(match phrase query)
-
偏移(Offset):记录单词的开始结束位置,实现高亮显示
-

四,Python读取excel数据批量写入ES文档数据
excel数据展示:
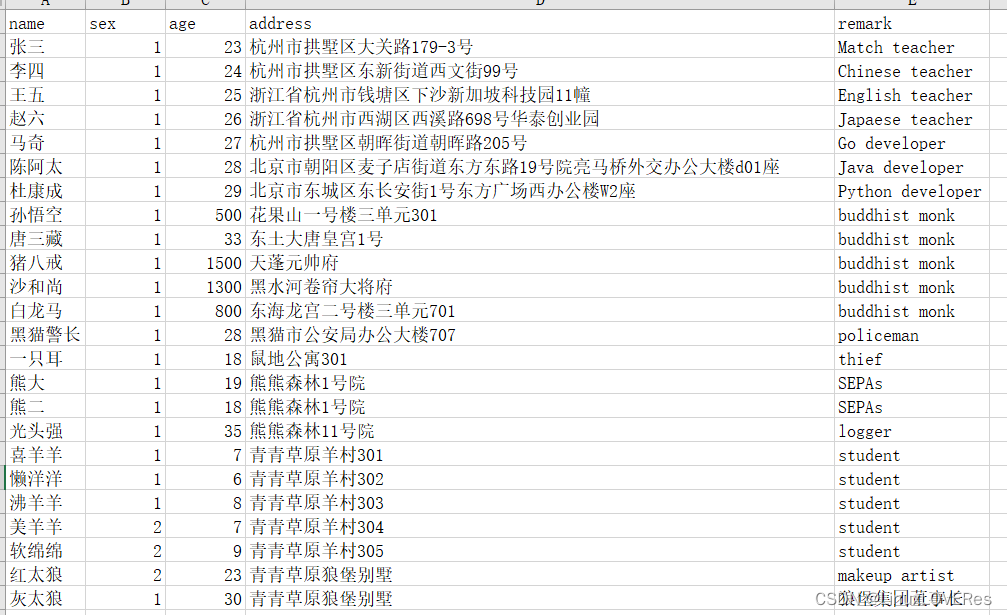
python中提供了elasticsearch包用于操作ES。需要注意的是elasticsearch包的版本,不同版本的es使用不同版本的elasticsearch包。由于此处安装es是安装的elastsearch7版本,所以python安装elastsearch7包。
pip install elasticsearch7from elasticsearch7 import Elasticsearch
# 导入elasticsearch7包
import openpyxl
# 导入openpyxl包用于读取excel文档中的数据
client = Elasticsearch(hosts="http://192.168.26.10:9200", http_auth=("elastic", "elastic"))
# 配置es的连接方式,http_auth 是设置es的用户名和密码
wb = openpyxl.load_workbook(r'test.xlsx')
sheet = wb['Sheet1']
# 读取test.xlsx文件中的Sheet1表
res = list(sheet.rows)
# 使用列表封装行的生成器
title = [i.value for i in res[0]]
# 将表格中行的value值放到列表中,即拿取表格的表头数据
for item in res[1:]: # 从第二行开始遍历
data = [i.value for i in item]
dic = dict(zip(title,data))
# 将每一行的value值和表头封装到字典中
client.index(index='test_user_db',doc_type='_doc',document=dic)
# 将拿取到的字典数据写入到es的test_user_db索引中
在kibana界面中查询test_user_db索引中的文档数据,检查写入是否成功。

可以看到文档写入已成功。
也可以在python中利用Elasticsearch模块查询
query = {'match_all': {}}
# 查询所有文档数据
allDoc = client.search(index='test_user_db', query=query,size=30)
# 查询test_user_db索引,指定显示最大条数30条
for item in allDoc['hits']['hits']:
print(item['_source'])结果输出:
















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









