






目录
1,请求模块urllib
(介绍:urllib模块为python自带的网络请求模块,无需导入)
1.1,urllib模块包含的多个子模块
✅urllib.request:用于实现基本HTTP请求的模块。
✅urllib.error:异常处理模块,如果在发送网络请求时出现了错误,可以捕获异常进行异常的有效处理。
✅urllib.parse:用于解析URL的模块。
✅urllib.robotparser:用于解析robots.txt文件,判断网站是否可以爬取信息。
1.2,使用urlopen()方法发送请求
1.2.1,简介
urllib.request模块提供了urlopen()方法,用于实现最基本的HTTP请求,然后接收服务端所返回的响应数据。
urlopen()方法的语法格式:
urllib.request.urlopen(url,date=None[timeout,]*,cafile=None,capth=None,cadefault=False,context=None)
urllib.request.urlopen(url,date=None[timeout,]*,cafile=None,capth=None,cadefault=False,context=None)✅url:需要访问网址的URL完整地址
✅date:该参数默认为None,通过该参数确定请求方式,如果是None请求方式为GET,否则请求方式为POST。
✅timeout:以秒为单位,设置超时。
✅cafile、capath:指定一组HTTPS请求受信任的CA证书,cafile指定包含CA证书的单个文件,capth指定证书文件目录。
✅cadefault:CA证书默认值。
✅context:描述SSL选项的实例。
1.2.2,发送Get请求
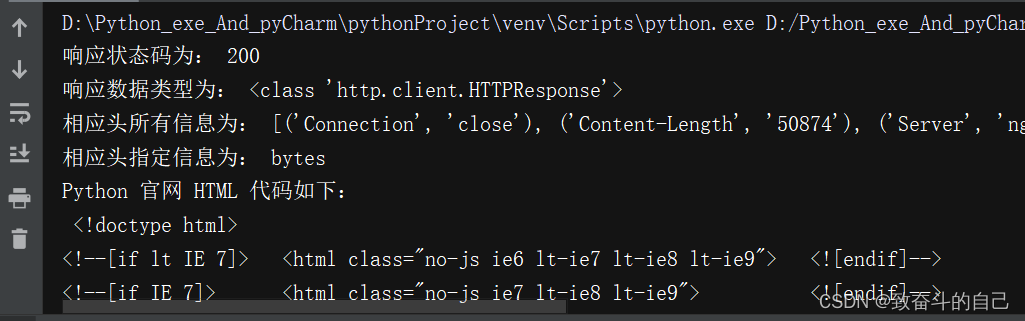
在使用urlopen()方法实现一个网络请求时,所返回的是一个http.client.HTTPResponse对象,在HTTPResponse对象中包含着需要获取信息的方法以及属性,式例如下
import urllib.request #导入request子模块
url="https://www.python.org/"
response=urllib.request.urlopen(url=url) #发送网络请求
print('响应状态码为:',response.status)
print('响应数据类型为:',type(response))
print('相应头所有信息为:',response.getheaders())
print('相应头指定信息为:',response.getheader('Accept-Ranges'))
#读取HTML代码并进行utf-8解码
print('Python 官网 HTML 代码如下:\n',response.read().decode('utf-8'))代码结果!
1.2.3,发送POST请求
urlopen方法在默认情况下发送的是Get请求,在发送POST请求时,需要为其设置data参数,该参数是bytes类型,所以需要使用bytes()方法将参数进行数据转化。
import urllib.request #导入request子模块
url="https://www.python.org/"
response=urllib.request.urlopen(url=url) #发送网络请求
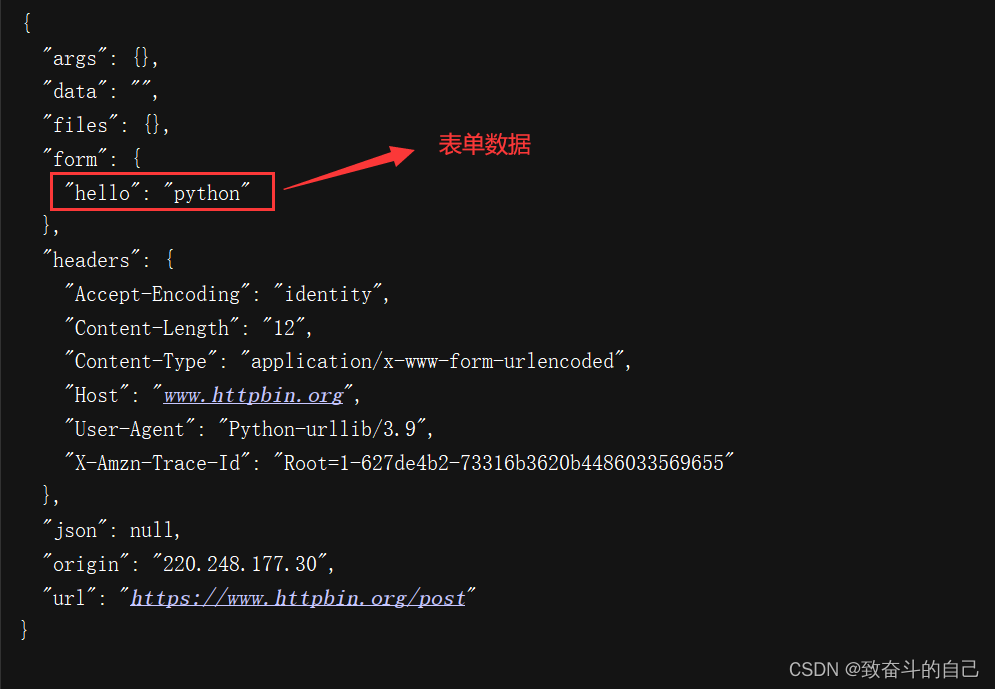
print('响应状态码为:',response.status)
print('响应数据类型为:',type(response))
print('相应头所有信息为:',response.getheaders())
print('相应头指定信息为:',response.getheader('Accept-Ranges'))
#读取HTML代码并进行utf-8解码
print('Python 官网 HTML 代码如下:\n',response.read().decode('utf-8'))
运行结果如下:
1.2.4,设置网络超时
1.3,复杂的网络请求
(介绍:前面的urlopen只能实现最基本的网络请求,所以......看后续)
1.3.1,Request()的语法格式:
urllib.request.Request(url,data=None,haeders{},origin_req_host=None,unverifiable=False,method=None)
urllib.request.Request(url,data=None,haeders{},origin_req_host=None,unverifiable=False,method=None)✅headers:设置请求头信息,该参数类型为字典类型。添加请求头信息最常见的用法就是修改User-Agent来伪装成浏览器,例如,headers={'User-Agent':'Mozilla/5.0(Windows NT 10.0;WOW64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/83.0.4103.61 Safari/537.36'},表示伪装谷歌浏览器进行网络请求
✅origin_req_host:用于设置请求方的host名称或IP
✅unverfiable:用于设置网页是否需要验证,默认值为False
✅method:用于设置请求方式,如GET,POST等,默认为GET请求
1.3.2, 设置请求头
设置请求头参数是为了模拟浏览器向网页后台发送网络请求,这样可以避免服务器的反爬措施。
设置请求头实例:
如果需要设置请求头信息,那么首先要通过Request类构造一个带有headers请求头信息的Request对象,然后为urlopen()方法传入Request对象,再进行网络请求发送。
import urllib.request
import urllib.parse
url='https://www.httpbin.org/post'
#定义请求头信息,这里是模拟谷歌浏览器
headers={'User-Agent':'Mozilla/5.0(Windows NT 10.0;WOW64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/83.0.4103.61 Safari/537.36'}
#将表单数据转化为bytes类型,并设置编码方式为:utf-8
data=bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8')
#创建Resquest对象
r=urllib.request.Request(url=url,data=data,headers=headers,method='POST')
#发送网络请求
response=urllib.request.urlopen(r)
#读取并解码
print(response.read().decode('utf-8'))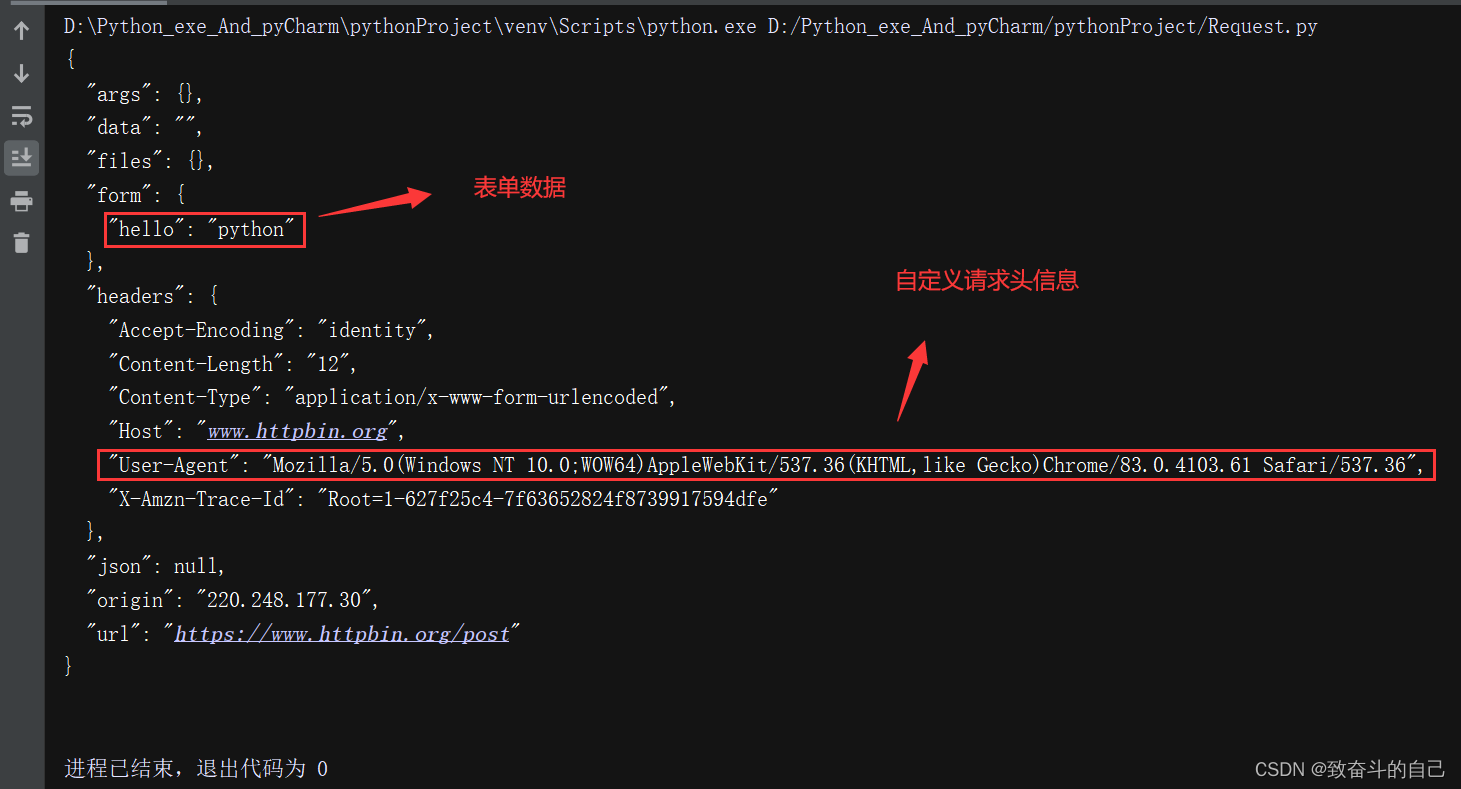
1.3.3,异常处理
urllib模块中urllib.error子模块包含了URLError和HTTPError俩个比较重要的异常类。
URLError类中提供了一个reason属性,可以调用该属性查看错误。
HTTPError类有三个属性,
(1)code:返回HTTP的状态码。
(2)reason:返回错误原因。
(3)headers:返回请求头。
由于HTTPError是URLError的子类,有时候HTTPError类会有捕捉不到的异常,所以可以先捕捉HTTPError类,然后再捕捉URLError类,这样可以起双重保险,例如:
#双重异常捕捉
import urllib.request
import urllib.error
try:
url=urllib.request.urlopen('https://www.httpbin.org/post/iii',timeout=0.1)
print('没有异常')
except urllib.error .HTTPError as error2:
print('状态码:',error2.code)
print('HTTPError异常信息为:',error2.reason)
print('请求头信息如下:',error2.headers)
except urllib.error.URLError as error1:
print('URLError异常信息为:',error1.reason)
由此可知HTTPError没有捕捉到 time out超时,再然后就被URLError捕捉到了。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











