






目录
目录
前面2讲,我们探讨了爬虫的基础知识和请求等概念,从第3讲开始,正式进入实操,我们一起学习如何用python编写代码,实现向服务器进行爬虫的操作。同样,我的理念是用长期主义+循序渐进的方式学习,把每个重要的基础概念吃透理解,写代码是最后水到渠成的步骤而已。
库-模块-函数的概念辨析
python的初学者,通常会对标题中的3个概念有些疑惑,我认为还是英文直译成中文造成的,这3个单词确实不太好理解,我试图用比喻的技巧去理解它们:
1、库。我们可以把库想象成一个非常庞大的工具箱,类似于装修工人或者维修工人手里会提的那种大箱子,里面有螺丝刀、扳手、电钻等工具品类,且每个品类有好多型号,会根据具体维修的场景挑选趁手的工具。不同的工人会有不同的工具箱,每种工具箱可以实现工人特定的需求和用途。此处,urllib库就是一个大的工具箱,主要实现爬虫的用途。
2、模块。我们可以进一步想象,工人从库(工具箱)中取出螺丝刀,这个螺丝刀就是一个模块,所以说,模块是属于库,每个库中有N多个模块。每个模块是实现细分功能的工具,例如,urllib库中的request模块,就是爬虫大用途下实现请求细分功能的工具。
3、函数。函数就是我们例子中的具体工具的某个用途了,例如,电动螺丝刀包含很多用途,钉入螺丝、取出螺丝等,urllib库中request模块中的urlopen函数,就是实现打开url并获取网页信息的用途。
当然,我这个比喻是比较粗浅的,完全是让大家对库-模块-函数有个直观的感受。
urllib库
urllib库是python自带的库,因此不需要安装,直接使用即可。
urllib库是一个最基本的网络请求库,可以模拟浏览器的行为,向指定的服务器发送请求(request),并保存服务器返回的数据。
1、urlopen函数
urllib库中所有关于网络请求相关的方法,全部集成到urllib.request模块中,urlopen就是request模块中的一个函数,主要用来打开指定的url,并获取服务器返回的数据。示例代码如下:
# 从urllib库中导入request模块,如果是下面这种写法,就只引入request模块,而非整个urllib库:
from urllib import request
# 使用urlopen函数,打开百度官网并获取整个页面信息,将信息赋值给变量resp:
resp = request.urlopen('http://www.baidu.com')
# 打印变量resp的html信息:
print(resp.read())
执行上面的代码,输入结果如下:
 结果把整个百度官网的html信息全部返回到python终端的输出窗口了,我画红圈的地方是b',这代表bytes字节型,简言之,这种类型的数据会把中文进行编码,因此输出的这一大坨中我们不会看到任何一个中文汉字。为了比较urlopen函数获取的数据是否和百度官网的html完全一致,我们可以在浏览器端-右键-查看源代码,此时浏览器窗口会弹出百度官网首页的完整html代码,我们可以在python输出窗口随意复制一段代码,然后去浏览器窗口ctrl+F搜索,看看是否能找到对应的代码,我尝试了下,是完全能对应上的。
结果把整个百度官网的html信息全部返回到python终端的输出窗口了,我画红圈的地方是b',这代表bytes字节型,简言之,这种类型的数据会把中文进行编码,因此输出的这一大坨中我们不会看到任何一个中文汉字。为了比较urlopen函数获取的数据是否和百度官网的html完全一致,我们可以在浏览器端-右键-查看源代码,此时浏览器窗口会弹出百度官网首页的完整html代码,我们可以在python输出窗口随意复制一段代码,然后去浏览器窗口ctrl+F搜索,看看是否能找到对应的代码,我尝试了下,是完全能对应上的。
这里需要注意下,我们上面的代码是一个最简单的request请求,很多时候服务器会设置反爬,因此抓取到的数据会与网页源代码有所出入!
有朋友会问,若resp后面不加read方法,输出会怎么样呢?

可以看到,输出结果是一段简单的英文字符串,表示resp是一个HTTP协议下的响应对象,而我们为了获取resp对象下的内容,所以必须写成resp.read( )。
上面我是直接用了一个直观的示例,向大家展示了urlopen函数的使用方法,相信大家跟着我把代码敲进去,并结合讲解之后,会对爬虫、请求、响应有比较具体的理解。现在,回过头来,我们讲下urlopen函数的细节知识点。
urlopen函数的作用
学术概念:创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
通俗理解:把urlopen参数中的url的全部信息抓取过来。
urlopen函数的参数
共有2个参数,第1个就是url,示例中我们用的是www.baidu.com。这个参数是必填项,没有url参数,函数就没法去爬取数据,很好理解。
第2个参数是data,非必填项,若在urlopen函数中填写data参数,就表示我们的请求变成post请求,例如:data我们放入某些网站的用户名字符串、密码字符串。
urlopen函数的返回值
示例中,我们已经用print(resp)向大家展示了,返回值是一个http.client.HTTPResponse对象,这个对象是一个类文件句柄对象【我也没搞懂】。
我们可以使用许多方法去操作这个对象,示例中的read是其中一种,还有readline(读取一行)、readlines(读取多行)、getcode(获取响应状态码)。大家注意哈,read( )中是可以填写数字的,如read(10)就代表我们只读取html代码中前10个字符串,read(100)代表我们读取html代码中前100个字符串。


状态码返回200,表示我们请求获得了正常的响应,未出现bug。
2、request模块的request类
初学的朋友可能会迷惑,怎么标题出现两个request?第1个request代表的是模块,上面的比喻我们提到过把模块想象成螺丝刀或者一类工具,用来实现特定功能,这里的request模块隶属于urllib库,此模块用来实现向服务器发送请求。第2个request是类,如何理解类会有些困难,我们就简单把它理解为相同类型的一批请求吧,例如,我们向百度服务器发送的请求、我们向虎扑服务器发送的请求、我们向新浪新闻服务器发送的请求...这些请求都是request类。
那可能又会有朋友问了:刚才使用urlopen函数不是已经可以实现请求并获取数据了,为什么现在又要介绍request类这个知识点?其实,urlopen函数是最基础的请求方法,一旦遇到服务器反爬设置就会失效,而request类是比urlopen函数更加高级的请求方法。
(1)在request类中添加UA
User-Agent,就是我们使用的浏览器,这个知识点之前已经有过介绍,示例如下:
from urllib import request
# 设置我们发送请求的url地址
url = 'https://www.zhibo8.com/'
# 设置请求头
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 设置Request类对象
resp = request.Request(url,headers=header)3、urlretrieve函数
urlretrieve函数属于urllib库中的request模块,retrieve的英文含义是“检索、取回、找回”。
该函数的作用是将网页上的一个文件保存到本地文件夹,示例如下:
# 导入urllib库的request模块
from urllib import request
# 下载百度官网的整个网页代码
request.urlretrieve('http://www.baidu.com','baidu.html')上面的代码中,urlretrieve函数有2个参数,第1个参数是我们想要获取的文件地址,示例中输入的是整个百度官网的url,第2个参数是我们保存的文件名称,示例中的文件名称为baidu.html。运行代码后,我们可以在这个python代码文件的同个文件夹中,发现一个新的html文件,名称为baidu,用浏览器打开这个文件,就是体现百度的官网。
urltrieve函数获取网页图片
接下来这个示例更加有趣一些,我们利用urlretrieve函数获取并保存我们喜欢的名人图片。
第1步:我们打开百度官网,直接搜索我们喜欢的名人名字,我是一个足球迷,搜索梅西吧。

第2步:找到心仪的照片,右键-检查-element-图片代码。
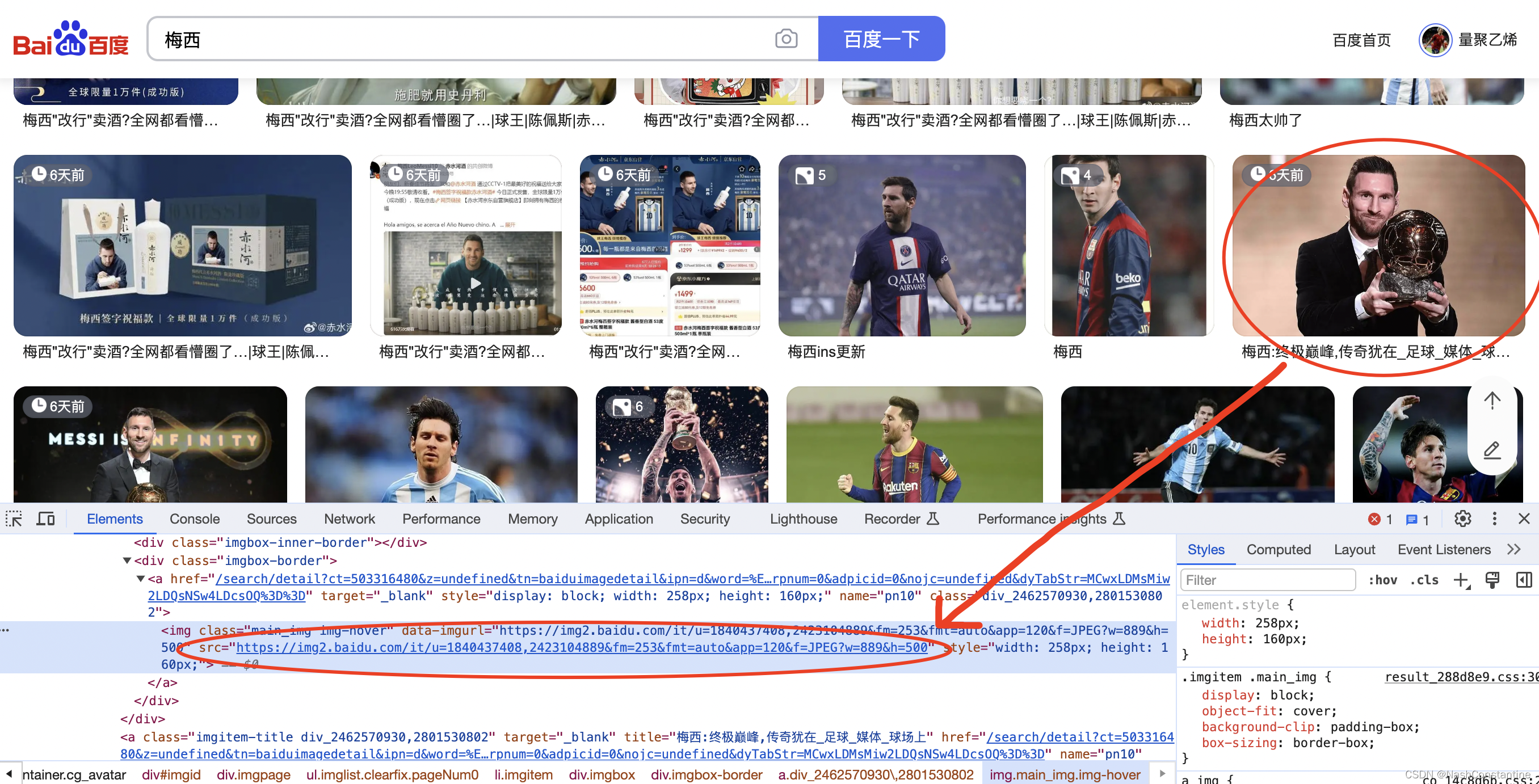 第3步:复制图片的代码,放入urlretrieve函数的第1个参数当中:
第3步:复制图片的代码,放入urlretrieve函数的第1个参数当中:
# 导入urllib库的request模块
from urllib import request
# 下载百度官网的整个网页代码
request.urlretrieve('http://k.sinaimg.cn/n/sports/transform/20160929/KhtD-fxwkzym7365354.jpg/w5707dd.jpg','messi.jpg')第4步:运行代码,发现本地文件夹出现图片文件。
 以上就是使用urlretrieve函数获取网页图片的整个流程,大家可以自行尝试下。
以上就是使用urlretrieve函数获取网页图片的整个流程,大家可以自行尝试下。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









