







内容简介
这次文章的内容是pandas的连接操作
这是参加datawhale的学习打卡活动的学习笔记
学习链接: http://joyfulpandas.datawhale.club/Content/%E5%8F%82%E8%80%83%E7%AD%94%E6%A1%88.html
关系型连接
把两张相关的表按照某一个或某一组键连接起来是一种常见操作,例如学生期末考试各个科目的成绩表按照 姓名 和 班级 连接成总的成绩表,又例如对企业员工的各类信息表按照 员工ID号 进行连接汇总。由此可以看出,在关系型连接中, 键 是十分重要的,往往用 on 参数表示。
另一个重要的要素是连接的形式。在 pandas 中的关系型连接函数 merge 和 join 中提供了 how 参数来代表连接形式,分为左连接 left 、右连接 right 、内连接 inner 、外连接 outer ,它们的区别可以用如下示意图表示:
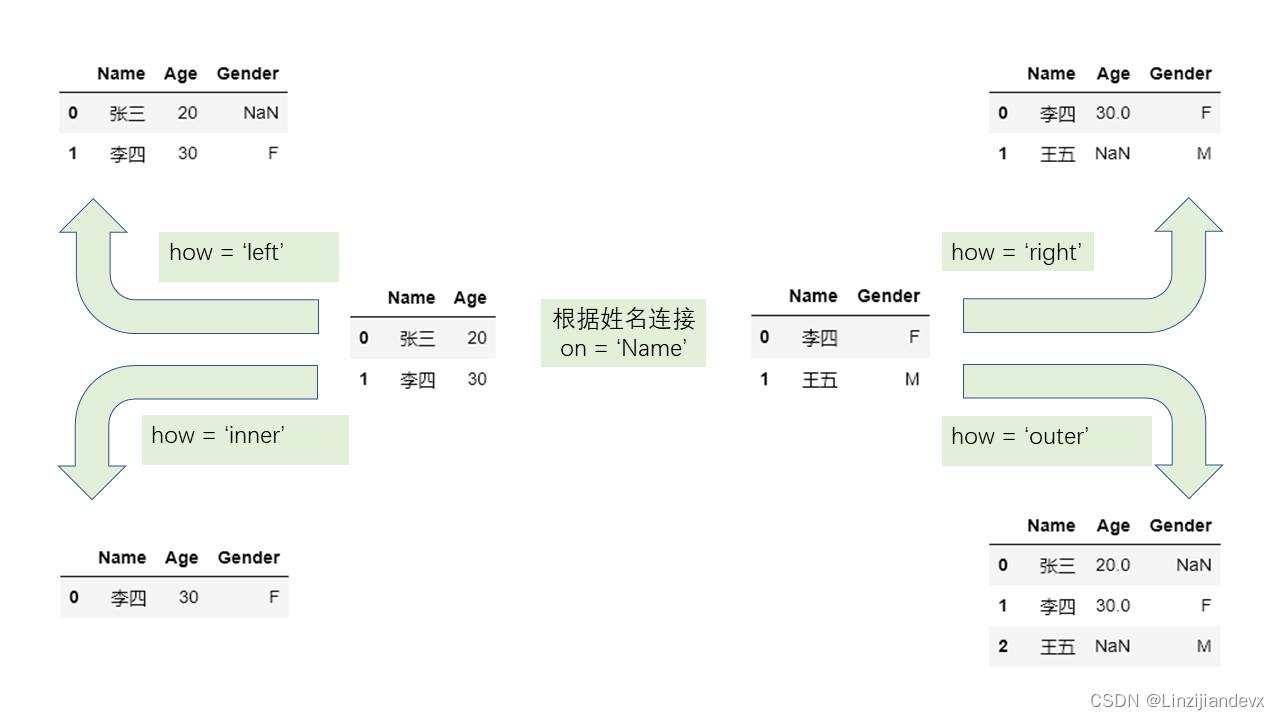
值连接
值连接使用merge方法。
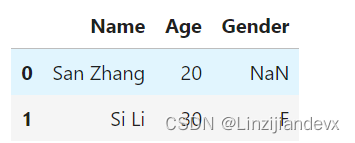
现有两个表,对其做值连接。
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({'Name':['Si Li','Wu Wang'], 'Gender':['F','M']})
df1.merge(df2, on='Name', how='left')
out
- 当值连接的列的列名不相同时,使用
left_on和right_on参数 - 当值连接对应的列有多列时,传入列名列表
- 当表中有相同的列名时,可以选用
suffixes指定列名的后缀,以便区分
索引连接
所谓索引连接,就是把索引当作键,因此这和值连接本质上没有区别,pandas中利用join函数来处理索引连接,它的参数选择要少于merge,除了必须的on和how之外,可以对重复的列指定左右后缀lsuffix和rsuffix。其中,on参数指索引名,单层索引时省略参数表示按照当前索引连接。
- 注意,在merge中传入suffixes的是列表,而join中是需要分别使用lsuffix和rsuffix
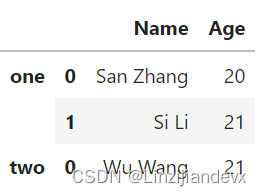
df1 = pd.DataFrame({'Age':[20,30]}, index=pd.Series(['San Zhang','Si Li'],name='Name'))
df2 = pd.DataFrame({'Gender':['F','M']}, index=pd.Series(['Si Li','Wu Wang'],name='Name'))
df1.join(df2, how='left')
out

方向连接
前面介绍了关系型连接,其中最重要的参数是on和how,但有时候用户并不关心以哪一列为键来合并,只是希望把两个表或者多个表按照纵向或者横向拼接,为这种需求,pandas中提供了concat函数来实现。
在concat中,最常用的有三个参数,它们是axis, join, keys,分别表示拼接方向,连接形式,以及在新表中指示来自于哪一张旧表的名字。这里需要特别注意,join和keys与之前提到的join函数和键的概念没有任何关系。
在默认状态下的axis=0,表示纵向拼接多个表,常常用于多个样本的拼接;而axis=1表示横向拼接多个表,常用于多个字段或特征的拼接。
concat
虽然说concat是处理关系型合并的函数,但是它仍然是关于索引进行连接的。纵向拼接会根据列索引对其,默认状态下join=outer,表示保留所有的列,并将不存在的值设为缺失;join=inner,表示保留两个表都出现过的列。横向拼接则根据行索引对齐,join参数可以类似设置。
序列和表的合并
利用 concat 可以实现多个表之间的方向拼接,如果想要把一个序列追加到表的行末或者列末,则可以分别使用 append 和 assign 方法。
在 append 中,如果原表是默认整数序列的索引,那么可以使用 ignore_index=True 对新序列对应的索引自动标号,否则必须对 Series 指定 name 属性。
原表:
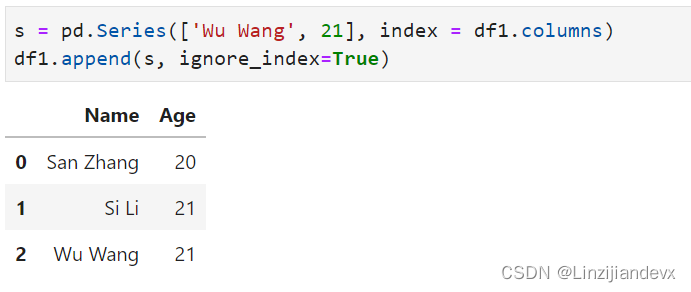
添加一行使用append
s = pd.Series(['Wu Wang', 21], index = df1.columns)
df1.append(s, ignore_index=True)
out
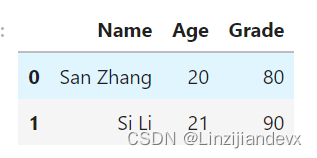
添加列使用assign
s = pd.Series([80, 90])
df1.assign(Grade=s)
out
习题
Ex1:美国疫情数据集
现有美国4月12日至11月16日的疫情报表(在 /data/us_report 文件夹下),请将 New York 的 Confirmed, Deaths, Recovered, Active 合并为一张表,索引为按如下方法生成的日期字符串序列:
date = pd.date_range('20200412', '20201116').to_series()
date = date.dt.month.astype('string').str.zfill(2
) +'-'+ date.dt.day.astype('string'
).str.zfill(2) +'-'+ '2020'
date = date.tolist()
out
['04-12-2020', '04-13-2020', '04-14-2020', '04-15-2020', '04-16-2020']
解答:
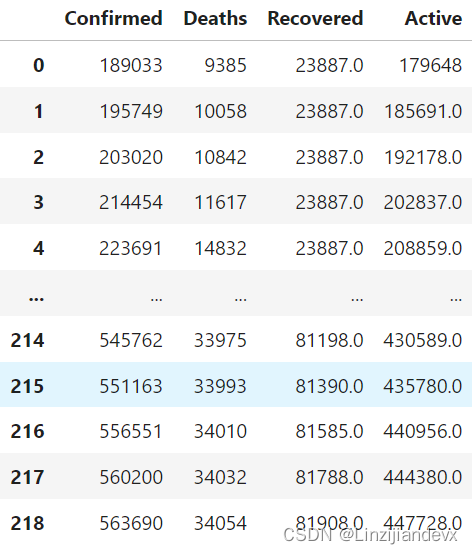
res=[]
col=['Confirmed', 'Deaths', 'Recovered', 'Active']
for i in range(len(date)):
data=pd.read_csv(path+date[i]+'.csv')
res.append((data.loc[data['Province_State']=='New York'][col]))
L=pd.concat(res)
L.reset_index(drop=True)
out:















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









