






C语言源程序在进行编译、链接之前会进行检测是否有一些特殊的预处理指令,若检测一些特殊的预处理指令则会进行相应的处理。C语言中多有的预处理指令都以符号“#”开头,并且结尾不使用分号。预处理指令在程序中出现的位置没有限定,即可以出现在任何地方,它的作用范围是从它出现的位置到文件尾。但一般我们把预处理指令写在文件的开头,这种情况下,他的作用范围会是整个源程序文件。C语言主要提供了三大类预处理指令:宏定义、文件包含、条件编译
一、宏定义
1、不带参数的宏定义
有时我们会在程序中使用一些常量,比如使用圆周率PI,这时为了避免重复书写复杂数据和为了以后修改方便,我们会使用宏定义来定义这些常量。不带参数的宏定义的语法为:#define 宏名 字符串,比如: #define PI 3.1415926。或许有人会疑惑为什么使用宏定义而不使用全局常量,这是因为宏定义会在程序编译之前进行处理,而且宏定义只是单纯的字符串替换,即在后续所有使用PI的地方都会用3.1415926进行替换掉,并不涉及数据类型、内存分配等处理。因此宏定义更加高效、安全。在使用宏时,我们习惯将宏名大写,并且末尾不加空格。当我们希望在代码的某处之后都不再使用之前的某个宏定义时我们可以使用#undef命令结束一个宏,例如结束PI宏的定义,#undef PI。当然在定义一个宏时我们可以引用已经定义的宏名,例如: #define CIRCLE 2*PI*3.0
2、 带参数的宏定义
当我们在定义一个宏时,我们希望不仅进行我们所希望的字符串的替换,我们也希望可以自己指定参数进行替换时我们就可以使用带参数的宏定义。其语法为:#define 宏名(参数列表) 字符串。例如:
#include <stdio.h>
#include <stdlib.h>
#define DOUBLE(a) 2*(a)
int main()
{
printf("%d\n", DOUBLE(2));
system("pause");
return 0;
}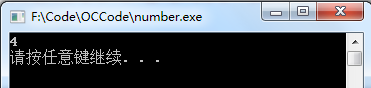
当调用DOUBLE(2)时,编译器会直接使用2*2进行文本替换,所以得到的结果为4。但我们使用带参数的宏定义时需要注意以下几点:
(1)宏名与参数列表之间不能有空格,否则编译器会以为空格之后的字符串都是进行字符串替换的字符串。例如:如果我们书写#define DOUBLE (a) 2*a时,当进行替换时会替换成:(a) 2*a(2),此时编译器不能正确编译。
(2)在定义宏时应用小括号将字符串的参数括起来,否则会出现意想不到的错误。例如:执行DOUBLE(3+4),本来我们期望的结果为14,但如果我们采用这样的宏定义:#define DOUBLE(a) 2*a,我们会得到这样的替换:2*3+4 = 10。
(3)我们最好将计算结果也用括号括起来,比如我们定义一个宏Pow(a),其功能是返回a的平方,若不使用小括号括住结果则:#define Pow(a) (a)*(a),我们调用Pow(10)/Pow(2),会得到替换结果为:(10 )*( 10) / (2) * (2) = 100,并不是我们所期望的:100/4 = 25。但如果我们将宏改为:#define Pow(a) ((a) * (a)),则结果会变为:
((10)* (10))/ ((2)* (2)) = 25。
二、文件包含
在C语言的代码文件开头,我们通常都会看到这样一句#include <stdio.h>,这就是C语言中文件包含的预处理指令。这句话的作用就是在预处理文件时将stdio.h文件的内容全部拷贝到当前文件的当前位置。文件包含的预处理命令有两种形式,第一种:#include <>,第二种:#include " "
#include<文件名>的形式与#include " 文件名"的形式在本质上没有不同,都是找到文件内容然后拷贝到当前文件。但是这两种方式的区别在于对于指定的文件的路径搜索顺序不同,#include<>形式将直接到C语言库函数头文件所在的目录寻找头文件,如果没有查找到目标文件则会直接报错;而 #include " "形式将先会去源程序所在的当前目录下寻找头文件,如果没找到再到操作系统的path路径中寻找,如果仍就未找到则会去C语言库函数头文件所在目录中查找,如果依旧未找到则会报错。因此,我们使用文件包含指令时一般按如下的规则使用:当我们确定使用库函数头文件时我们使用#include<>形式,如果我们使用自己自定义的头文件时我们一般使用#include" " 形式。
使用C语言的#include指令有一点需要注意,那就是#include指令有可能造成头文件的重复包含使得编译效率降低。什么是头文件的重复包含?比如我们定义了一个头文件test1.h,而且我们在test1.h中包含了我们自己定义的另一个头文件#include"test.h",紧接着我又定义了一个test2.h,并且我在test2.h中包含了test1.h,但是当我在main函数中包含时我使用了#include"test1.h" 和#include "test2.h",那么我们将会拷贝两次test.h到当前的文件。那么为了解决重复包含的问题我们一般会引入条件编译指令,使用条件编译指令来防止头文件的重复包含。
三、条件编译
在C语言中如果我们希望程序中的一部分代码只有在满足特定的条件时才进行编译,否则不进行编译时,我们会采用条件编译的策略。条件编译的基本用法为:
#if 条件1
...Code1...
#elif 条件2
...Code2...
#else
...Code3...
#endif
上述指令并不等同于C语言中的if else指令,if与elif后的判定条件一般是宏定义,如果条件1成立则会将Code1表示的代码编译进源文件,如果条件2成立则只有Code2代表的代码段会被编译进源程序。如果条件2也不成立则只有Code3会被编译进源文件,末尾的#endif一定要有,否则#else以下的所有内容都将会被看成Code3的内容,这是不符合实际情况的。例如:
#include <stdio.h>
#define NUMBER 2
int main()
{
#if NUMBER == 1
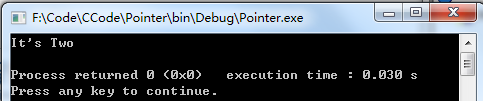
printf ("It's One\n");
#elif NUMBER == 2
printf ("It's Two\n");
#else
printf ("It's Nothing\n");
#endif // NUMBER
return 0;
}
另一组指令#ifdef和#ifndef如此类似,但这组指令一般用在防止头文件重复包含时,其使用的一般语法为:
#ifdef 宏名
...Code...
#endif
或:#ifndef 宏名
...Code...
#endif
第一条命令会判断指定的宏是否已经定义,如果定义过则将Code编译进去,后一条命令则与此相反。例如我们在编译一个test.h的自定义头文件时我们一般会在头文件开头这样写:
#ifndef _TEST_H_
#define _TEST_H_...
#endif // _TEST_H_















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









