







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、问题阐述
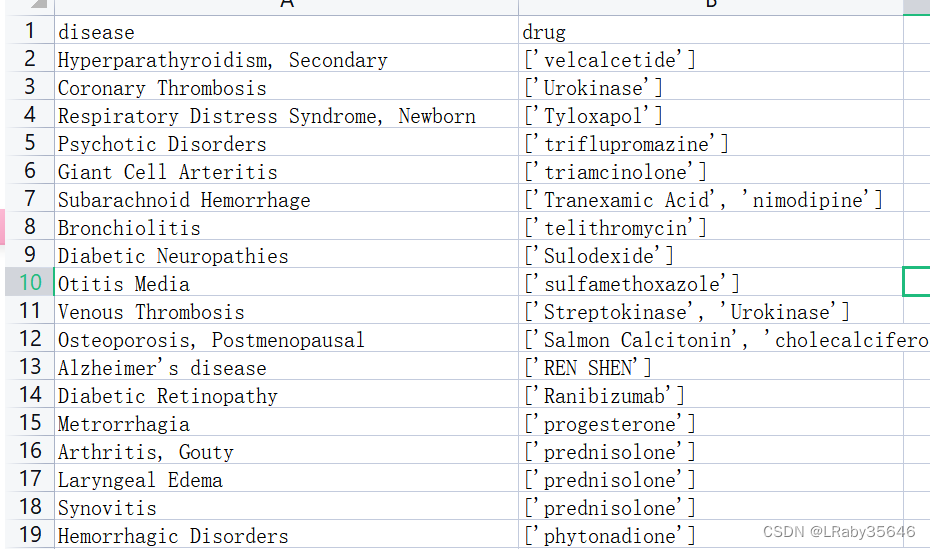
想对drug这一列进行判断,如果哪一行drug的数量是1,则将此行删除
二、解决方法
1.将字符串转成列表,进行计数
代码如下(示例):
import pandas as pd
# 读取CSV文件到DataFrame
df = pd.read_csv('your_file.csv')
# 定义一个函数,用于处理 drug 列中的字符串,strip()是将字符串两端的空格去除
def process_drug_column(drug_str):
# 去除多余的字符并将字符串转换为列表
drugs = drug_str.strip('[]').replace("'", "").split(',')
return [drug.strip() for drug in drugs]
# 应用处理函数到 drug 列
df['drug'] = df['drug'].apply(process_drug_column)
# 过滤出 drug 列中包含多个药物的行
df_filtered = df[df['drug'].apply(len) > 1]
# 保存过滤后的DataFrame到新的CSV文件
df_filtered.to_csv('filtered_file.csv', index=False)
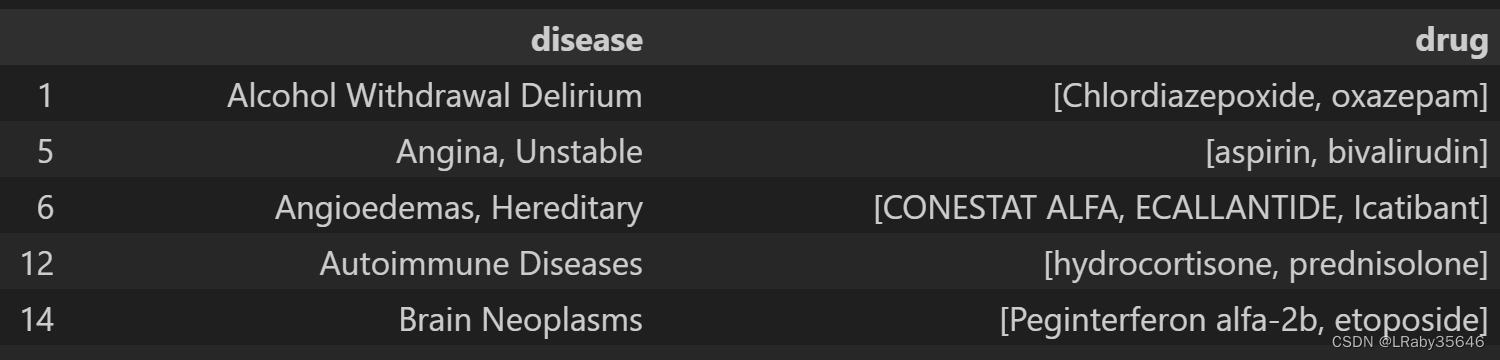
2.针对字符串,直接计数逗号来计算药物数量
代码如下(示例):
import pandas as pd
# 读取CSV文件到DataFrame
df = pd.read_csv('/home/yin/DREAMwalk-main/DREAMwalk-main/demo/LiuRui/recall_result/true_disease.csv')
# 过滤出 drug 列中包含多个药物的行(逗号数量大于等于1的行)
df_filtered = df[df['drug'].str.count(',') >= 1]
# 保存过滤后的DataFrame到新的CSV文件
df_filtered
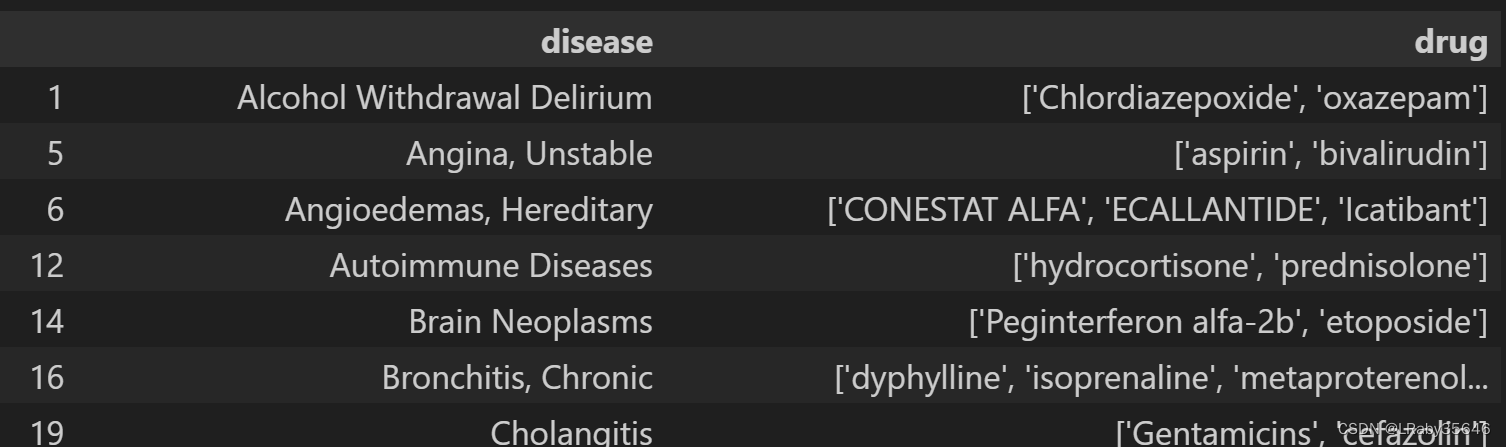
总结
针对上面两种方法,第二种要求数据格式是规范的且没有额外的复杂情况,所以第一种较为灵活,且生成的数据格式规范。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









