






Geometric Deep Learning on Molecular Representations![]() https://arxiv.org/pdf/2107.12375.pdf
https://arxiv.org/pdf/2107.12375.pdf
一、Background

随着网络时代的发展,生活中产生的数据量越来越多,但数据大体分为两类:欧氏数据、非欧氏数据。如图为两类常见的数据,而绝大多数深度学习都是在欧氏数据(Euclidean Data)上进行的,包括一维和二维域中的数据类型。但在现实世界中我们并不存在于一维或二维世界。所有我们能观察到的都存在于3D中,其使用的数据集中的数据基本都反映出这一点。

欧氏数据是一类具有很好的平移不变性(图像中的平移不变性:即不管图像中的目标被移动到图片的哪个位置,得到的结果(标签)应该相同的)的数据。对于这类数据以其中一个像素为节点,其邻居节点的数量相同。所以可以很好的定义一个全局共享的卷积核来提取图像中相同的结构,卷积被定义为不同位置的特征检测器。对于常见的欧氏数据,如图像是一种2D的网格类型数据,通常用矩阵进行存储。文本是一种1D的网格类型数据,通常可以用向量进行存储。对于文本,我们通常做法是去停用词、以及高频词(DIFT),最后嵌入到一个一维的向量空间。
而且,因为这类型的数据排列整齐,不同样本之间可以容易的定义出 “距离” 这个概念出来。我们假设现在有两个图片样本,尽管其图片大小可能不一致,但是总是可以通过空间下采样的方式将其统一到同一个尺寸的,然后直接逐个像素点进行相减后取得平方和,求得两个样本之间的欧氏距离是完全可以进行的。如公式所示。因此把图片样本的不同像素点看成是高维欧几里德空间中的某个维度,因此一张m×n的图片可以看成是m×n维的欧几里德样本空间中的一个点,而不同样本之间的距离就体现在了样本点之间的距离了。

非欧氏数据是一类不具有平移不变性的数据。这类数据以其中的一个为节点,其邻居节点的数量可能不同。样本总得来说有两大类型,分别是图(Graph)数据和流形数据(manifolds),这两类数据有个特点就是,排列不整齐,比较的随意。具体体现在:对于数据中的某个点,难以定义出其邻居节点出来,或者是不同节点的邻居节点的数量是不同的。
这个其实是一个特别麻烦的问题,因为这样就意味着难以在这类型的数据上定义出和图像等数据上相同的卷积操作出来,而且因为每个样本的节点排列可能都不同,比如在生物医学中的分子筛选中,显然这个是一个Graph数据的应用,但是我们都明白,不同的分子结构的原子连接数量,方式可能都是不同的,因此难以定义出其欧几里德距离出来,这个是和我们的欧几里德结构数据明显不同的。因此这类型的数据不能看成是在欧几里德样本空间中的一个样本点了,而是要想办法将其嵌入(embed)到合适的欧几里德空间后再进行度量。而现在流行的GNN便可以进行这类型的操作。
当用非欧氏的方式来表示事物时,我们给了它一种归纳偏置(inductive bias,指在学习算法中,当学习器去预测其未遇到过的输入结果时,所做的一些假设的集合)。这是基于一种直觉:给定任意类型、格式和大小的数据,可以通过更改数据的结构来确定模型的优先级,以了解特定的模式。机器学习试图去建造一个可以学习的算法,用来预测某个目标的结果。要达到此目的,要给于学习算法一些训练样本,样本说明输入与输出之间的预期关系。然后假设学习器在预测中逼近正确的结果,其中包括在训练中未出现的样本。既然未知状况可以是任意的结果,若没有其它额外的假设,这任务就无法解决。这种关于目标函数的必要假设就称为归纳偏置。
基于这种直觉,几何深度学习(GDL) 是深度学习中的小众领域,旨在建立可以从非欧氏数据中学习的神经网络。
二、Motivation
深度学习是基于神经网络的人工智能的一个实例,近年来的进展已经在分子科学中产生了许多应用,如药物发现、量子化学和结构生物学。
深度学习的两个特点使它在应用于分子时特别有前途。首先,深度学习方法可以处理“非结构化”的数据表示,如文本序列、语音信号、图像和图表。这种能力对分子系统尤其有用,化学家已经为分子系统开发了许多模型(即“分子表示”),这些模型在不同的抽象级别上捕捉分子的特性。以青霉素亚结构penam(青霉烷)为例:

a图为2维的Kekulé式描写;
b图为2维的分子图,由顶点(原子)和边(键)组成;
c图为简化分子线性输入规范字符串(SMILES串),其中原子类型、键类型和连通性由字母和数字字符指定;
d图为三维图,由顶点(原子)、它们在3D空间中的位置(x, y, z坐标)和边(键)组成;
e图则是根据分子内各自的原子类型,以网状的形式表示的分子表面。
第二个关键特征是,深度学习可以从输入数据中执行特征提取(或特征学习),即从输入数据中生成数据驱动的特征,而不需要人工干预。
这两个特征对于深度学习来说很有前景,可以作为“经典”机器学习应用(例如,定量构效关系[QSAR],一种借助分子的理化性质参数或结构参数,以数学和统计学手段定量研究有机小分子与生物大分子相互作用、有机小分子在生物体内吸收、分布、代谢、排泄等生理相关性质的方法)的补充,在这种应用中,分子特征(例如,“分子描述符”)通过基于规则的算法进行先验编码。从非结构化数据中学习并获得数据驱动的分子特征的能力导致了AI在分子科学中前所未有的应用。
几何深度学习(GDL)是一种基于融合和处理对称信息的神经网络架构的方法,是人工智能领域最近出现的一种范式,也是深度学习中最有前途的进展之一。它将神经网络推广到欧几里德和非欧几里德领域,如图、流形、网格或字符串表示。
一般来说,GDL包含了包含几何先验的方法,即关于输入变量的结构空间和对称属性的信息。利用这种几何先验来提高模型捕获的信息的质量,因此GDL在具有不同对称性和抽象级别的各种分子表示的分子建模应用中具有特殊的前景。

值得引起注意的是,对称在GDL中是一个至关重要的概念,因为它包含了与操作(转换)相关的系统属性,如平移、反射、旋转、缩放或排列。分子系统(及其三维表示)可以被认为是欧氏空间中的对象。在这样的空间中,人们可以应用几种对称操作(转换),它们(i)针对三个对称元素(即线、面、点)执行,(ii)是刚性的,也就是说,它们保持所有原子对之间的欧氏距离(即等距)。
欧几里得变换如下:
1、旋转:物体相对于某一给定点的径向方向的运动;
2、平移:物体的每一点在给定方向上移动相同距离的运动;
3、反射:通过点(反转)、直线或平面(镜像)将对象映射到自身。
① 旋转;② 平移;③ 反转反射;④ 镜像反射
这三种变换及其任意有限组合都包含在欧氏群中[E(3)]。特殊的欧氏群[SE(3)]只包括平移和旋转。而一般情况下分子在SE(3)基团中总是对称的,也就是说,它们的固有性质(如生物和物理化学性质,以及平衡能)对坐标旋转和平动及其组合是不变的。但有些分子是手性的,也就是说,它们的一些(手性)性质取决于它们的立体中心的绝对构型,因此对分子反射不恒定。手性在化学生物学中起着关键作用,如一些药物的对映体表现出明显不同的药理和毒理学性质。
对称性经常以等变性与不变性来表达任何数学函数相对于变换T(例如旋转、平移、反射或排列)的行为。这里的函数F(X)是一个给定分子的神经网络F,输入X后,F(X)可以对T进行等变变换、不变变换或不变换:
1、等变性:通俗来说,对于一个函数,如果对其输入施加的变换也会同样反应在输出上,那么这个函数就对该变换具有等变性;
e.g.: 假设变换是将图像向右平移一段距离,函数是检测一个人脸的位置(比如输出坐标),那么先将图片像右移,接着我们在原图偏右的位置检测到人脸;或是我们先检测到人脸, 然后再将人脸往右移一点。这二者的输出是一样的,与我们施加变换的顺序无关。
2、不变性:通俗来说,对于一个函数,如果对其输入施加的某种操作丝毫不会影响到输出,那么这个函数就对该变换具有不变性;
e.g.: 假设函数是检测图像中是否有红色, 此时如果我们的变换是旋转/平移, 那么这些变换都不会对函数结果有任何影响。
3、通俗来说,对于一个函数,如果对其输入施加的变换与其输出上的变换不一致时,那么这个函数就对该变换既不具有等变性,又不具有不变性;
等变性与不变性的概念也可用于从给定的分子表示中获得的分子特征,这取决于它们在对分子表示进行转换时的行为。例如,许多分子描述子通过设计后对分子表示的旋转和平移是不变的,例如Moriguchi辛醇-水分配系数,它只依赖于特定分子亚结构的出现进行计算。神经网络提取的分子特征的对称性既取决于输入分子表示的对称性,也取决于利用的神经网络的对称性。许多相关的分子性质(如平衡能、原子电荷或物理化学性质如渗透性、亲脂性或溶解度)对某些对称操作也是不变的。因此,在许多化学任务中,设计在预先定义的对称组作用下等价变换的神经网络是很有必要的。如果目标性质在分子的对称变换过程中发生改变(例如,在手性分子的反转过程中手性性质发生改变,或在分子的旋转过程中矢量性质发生改变),则会出现例外。在这种情况下,等变神经网络的归纳偏置将不允许对称转换分子的分化。
虽然神经网络可以被认为是单变量函数近似器[28],但融合合理的几何信息(几何先验)等先验知识已经发展成为神经网络建模的核心设计原则。通过整合几何先验,GDL可以提高模型的质量,并绕过与强制数据进入欧氏几何相关的几个瓶颈(例如特征工程)。此外,GDL提供了新的建模机会,例如在低数据状态下的数据增强。
三、Method
GDL在分子系统中的应用具有挑战性,部分原因是有多种有效的方法来表示相同的分子实体。分子的表征可以根据它们不同的抽象层次以及它们所捕获的物理化学和几何方面进行分类,同时GDL提供了用相同分子的不同表示形式进行实验的机会,并利用它们内在的几何特征来提高模型的质量。此外,由于其特征提取(特征学习)能力,GDL已多次被证明在为任务提供有关分子特性的洞察方面是有用的。这里将举例描述最流行的分子GDL方法及其在化学中的应用,并根据用于深度学习的各自分子表示进行分组:
1、分子图
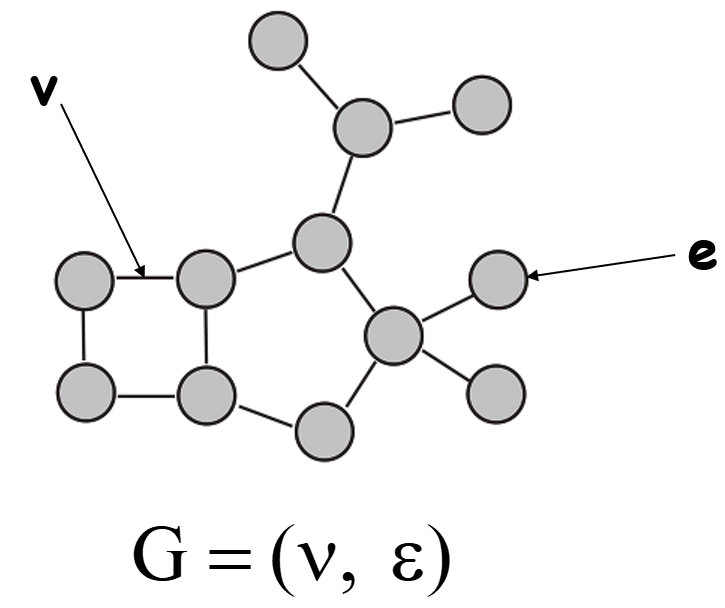
图是表示分子结构最直观的方法之一。任何分子都可以看作是一个数学图𝐺=(𝑉,𝐸),其顶点(𝑣𝑖∈𝑉)代表原子,其边(𝑒𝑖, 𝑗∈𝐸)构成原子之间的联系(如图)。在许多深度学习应用中,分子图可以进一步由一组顶点和边缘特征来表征。
致力于将图作为输入处理的深度学习方法通常被称GNN。当应用于分子时,GNN允许通过逐步聚合来自原子及其分子环境的信息来提取特征(如图)。这里应用于二维(2D)分子图采取消息传递图神经网络:左侧是二维分子图𝐺=(𝑉,𝐸)及其标记的顶点(原子)特征(𝑣𝑖∈𝑅𝑑𝑣)和边(键)特征(𝑒𝑖𝑗∈𝑅𝑑𝑒)。顶点特征经过每对顶点𝑣𝑖和𝑣𝑗,通过边𝑒𝑗,𝑖连接,通过定义的时间步数T的迭代消息传递来更新。在最后一个消息传递卷积之后,最终顶点𝑣𝑡𝑖可以(i)映射到键(yij)或原子(yi)属性,或者(ii)聚合形成分子特征(可以映射到分子属性y)。

基于图的方法的一个最新发展领域是SE(3)-和E(3)-等变GNN(等变消息传递网络),E(3)-等变消息传递图神经网络应用于三维(3D)分子图(如图),左侧为标记有原子特征(𝑣𝑖∈𝑅𝑑𝑣)及其在三维空间中的绝对坐标(𝑟𝑖∈𝑅3)和边缘特征(𝑒𝑖𝑗∈𝑅𝑑𝑒)的三维图𝐺=(𝑉,𝐸,𝑅)。迭代球面卷积用于获得数据驱动的原子特征(𝑣𝑇𝑖),它可以映射到原子性质或聚合,并映射到分子性质(分别为𝑦𝑖和𝑦)。

2、网格+曲面
网格以有规律的间隔捕获系统的属性。根据系统中包含的维数,网格可以是1D(如序列)、2D(如RGB图像)、3D(如立方格)或更高维的。网格是由欧氏几何定义的,可以被认为是一个具有特定邻接关系的图,其中(i)顶点具有由网格的空间维度定义的固定顺序,并且(ii)每个顶点具有相同数量的相邻边,因此在结构上无法与所有其他顶点区分。这两个特性使得应用于网格的局部卷积具有固有的排列不变性,并为平移不变性提供了一个强大的几何先验(例如,通过卷积中的权值共享)。这些网格特性在很大程度上决定了卷积神经网络(CNNs)的成功,例如在CV、NLP和语音识别方面。
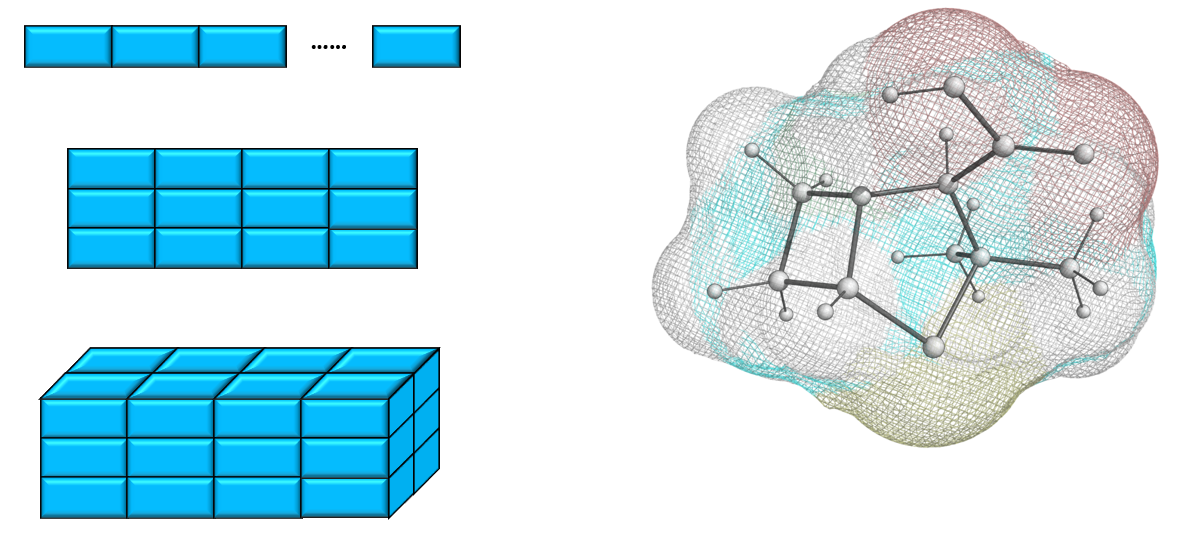
分子可以用不同的方式表示为网格。二维网格(如分子结构图)通常更适合可视化而不是预测,只有少数例外。分子表面可以定义为在距离每个原子中心一定距离处包围分子三维结构的表面。这种连续表面上的每一点都可以通过其化学(如疏水、静电)和几何特征(如局部形状、曲率)进一步表征。从几何角度来看,分子表面被认为是三维网格,即一组多边形(面),描述网格坐标在三维空间中的存在方式。它们的顶点可以用2D网格结构表示(网格上的四个顶点定义一个像素),也可以用3D图形结构表示。网格和图形结构使二维CNN、G-CNN和GNN的应用能够在基于网格的分子表面上学习。
与一些流行的深度学习方法类似,例如比较分子场分析(CoMFA)和比较分子相似指数分析(CoMSIA) ,3D网格通常用于捕获一个(或多个)分子构象内的性质的空间分布。这样的表示形式然后被用作3D-CNN的输入。3D-CNN的特点是比等变CNN具有更高的资源效率,到目前为止,等变CNN主要应用于小于1000个原子的分子。因此,当必须考虑蛋白质结构时,3D-CNN通常是选择的方法,例如,蛋白质配体结合亲和力预测或活性位点识别。
3、串
分子可以表示为分子串,即字母数字符号的线性序列。分子串最初是作为人工加密工具开发的,以补充系统化学命名法,后来适合于数据存储和检索。一些最流行的基于字符串的表示法是Wiswesser线表示法、Sybyl线表示法、国际化学标识符(InChI)、大分子分层编辑语言和简化分子输入线输入系统(SMILES)。
每种类型的线性表示都可以被认为是一种“化学语言”。事实上,这样的符号具有明确的语法,也就是说,不是所有可能的字母和数字字符的组合都会导致一个“化学上有效的”分子。此外,这些符号具有语义特性:根据字符串中元素的组合方式,相应的分子将具有不同的物理化学和生物特性。这些特征使得为语言和序列建模而开发的深度学习方法可以扩展到“化学语言建模”的分子串分析。
SMILES字符串——其中字母用于表示原子,符号和数字用于编码键类型、连通性、分支和立体化学——已成为基于序列的深度学习中最常用的数据表示方法。对于每个分子,通过SMILES算法得到一串T符号(“标记”)(𝑠 = {𝑠1, 𝑠2,…, 𝑠𝑇}),它编码分子连通性,这里通过表示对应原子在图(左)和字符串(右)中的位置的颜色来表示。尽管其他几种字符串表示已经与深度学习相结合进行了测试,例如国际化学标识符(InChI)、DeepSMILES和自引用嵌入式字符串,但SMILES仍然是化学语言建模的实际表示选择。

这里提出了一种机器学习算法——化学语言模型,可以处理分子序列作为输入和/或输出。化学语言建模最常用的算法是递归神经网络(RNNs)和Transformers
RNN(循环神经网络)是将序列数据处理成欧氏结构进行处理的神经网络,是一个动态系统的模型,其中网络在第t个时间点(即序列中的第t个位置)的隐藏状态(h𝑡)依赖于当前观测(𝑠𝑡)和之前的隐藏状态(h𝑡−1),其可以处理任意长度的序列输入,并提供任意长度的输出。RNN通常以“自回归”的方式使用,即在给定当前隐藏状态(h𝑡)和序列的前面部分的情况下,预测在时间步长𝑡+1时下一个可能的元素的概率分布。这里是在任何序列位置t,学习预测给定当前序列({𝑠1, 𝑠2,…,𝑠𝑡})的序列s的下一个标记𝑠𝑡+1和隐藏状态h𝑡。

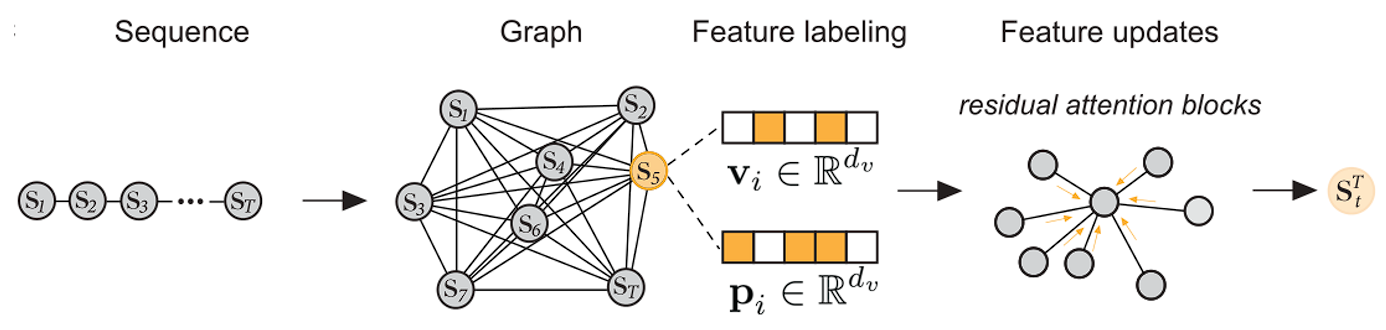
Transformers,将序列数据处理为非欧氏结构,通过将序列编码为(i)全连通图,或(ii)序列连通图,其中每个标记仅与序列中的前一个标记相连。前一种方法通常用于特征提取,而后一种方法用于下一个标记预测。标记的位置信息通常采用位置嵌入或正弦位置编码进行编码。Transformers将图形处理与所谓的注意层结合起来,且注意层允许transformer关注(“注意”)每个预测的感知相关标记。这里是基于Transformers的语言模型,其中输入序列结构为图。顶点根据它们的标识(例如,通过标记嵌入,𝑣𝑖∈𝑅𝑑𝑣)和它们在序列中的位置(例如,通过正弦位置编码,𝑝𝑖∈𝑅𝑑𝑣)来特征化。在Transformers学习过程中,顶点通过剩余注意块更新。通过T个注意层后,得到每个标记的单个特征表示𝑠𝑇𝑡。
其他深度学习方法依赖于基于字符串的表示来进行从头设计,例如条件生成对抗网络(GAN)和变分自编码器。然而与RNN相比,大多数这些模型在自动学习SMILES语法方面的能力有限或相当。目前1D CNN和自注意网络已与SMILES一起用于性质预测,关于氨基酸序列的深度学习也被证明可以与基于人类工程特征的方法进行性能预测。
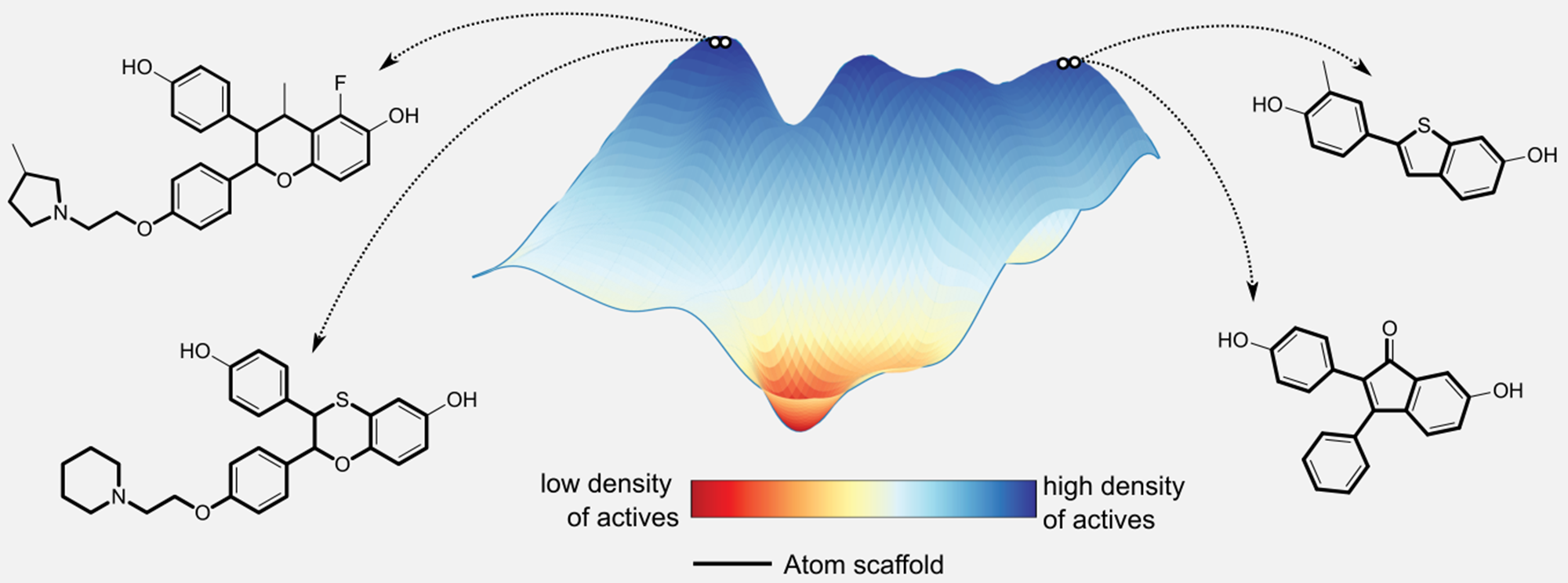
下图展示了几何深度学习(GDL)如何被用来解释经过训练的模型学习到的结构活动景观。从一个公开的包含雌激素受体结合信息的分子数据集开始,训练了一个E(3)-等变图神经网络(6个隐藏层,每层128个隐藏神经元),并分析了学习到的特征及其与雌激素受体结合配体的关系。图中显示了对所学分子特征的分析以及这些特征如何与化学空间中活性和非活性分子的密度有关。该网络基于分子的实验生物活性和结构特征(如原子支架)成功分离了分子,并可能为使用可解释GDL的AI提供新的机遇。
四、Conclusion
化学中的几何深度学习使研究人员能够利用不同非结构化分子表示的对称性,从而使可用的分子结构生成和性质预测计算模型具有更大的灵活性和多功能性。这种方法代表了基于分子描述符或其他人为设计的特征的经典化学信息学方法的有效替代方案。对于通常以需要高度工程化规则为特征的建模任务(例如,从头设计的化学转换和CASP的反应位点规范),GDL的好处已被一致认可。在已发表的GDL应用中,每种分子表示(分子字符串、分子图、分子网格和分子表面)都显示出其特有的优缺点。

像SMILES这样的分子串已被证明特别适合生成式深度学习任务。这种成功可能是由于这种化学语言的语法相对简单,便于进行下一个标记和序列到序列的预测。但对于分子性质的预测,SMILES字符串由于其非单一性而受到限制。
分子图在性质预测方面表现出特别的用处,部分原因是它们具有可解释性和易于包含所需的边缘和节点特征。三维信息的整合(例如,与等变信息传递)对于量子化学相关的建模是很有用的,然而在药物发现应用中,这种方法往往不能明显地平衡模型增加的复杂性。E(3)-等变图神经网络也被应用于构象感知的从头设计,但尚未有前瞻性的实验验证研究发表;
分子网格已经成为大型分子系统三维表示的事实上的标准,因为(i)它们能够以用户定义的分辨率(体素密度)捕获信息,(ii)输入网格的欧氏结构。
最后,分子表面目前处于GDL的前沿。在不久的将来GDL在分子表面或许会有许多有趣的应用。
GDL的未来展望:
1)为进一步研究GDL在化学中的应用和影响,需要在算法复杂性、性能和模型可解释性之间做出最佳权衡;
2)GDL在分子特征提取方面的潜力尚未被充分挖掘,缺少基准框架系统的评估人工智能学习的数据驱动特征的有效性。
3)在尚未深入研究的一些分子表征中应用GDL,如量子和电子表征。
















 4392
4392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











