








系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序
Linux设备驱动开发详解
六、定时测量
1、时钟和定时器电路
- 实时时钟(RTC)
- 时间戳计数器(TSC)
- 可编程间隔定时器(PIT)
- CPU 本地定时器
- 高精度时间定时器(HPET)
- ACPI 电源管理定时器
2、Linux 计时体系结构
(1)计时体系机构的数据结构
- 定时器对象
- jiffies 变量
- xtime 变量
(2)软定时器和延迟函数
Linux定时器分为动态定时器(dynamic timer)和间隔定时器(interval timer)。第一种类型由内核使用,而间隔定时器可以由进程在用户态创建。
这里是有关 Linux 定时器的警告:因为对定时器函数的检查总是由可延迟函数进行,而可延迟函数被激活以后很长时间才能被执行,因此,内核不能确保定时器面数正好在定时到期时开始执行,而只能保证在适当的时间执行它们,或者假定延迟到几百毫秒之后执行它们。因此,对于必须严格遵守定时时间的那些实时应用而言,定时器并不适合。
除了软定时器外,内核还使用了延迟函数,它执行一个紧凑的指令循环直到指定的时间间隔用完。我们将在后面的 “延迟函数” 一节对它们进行讨论。
(a)动态定时器
动态定时器(dynamic timer)被动态地创建和撤消,对当前活动动态定时器的个数没有限制。
// include/linux/timer.h
struct timer_list {
struct list_head entry;
unsigned long expires;
void (*function)(unsigned long);
unsigned long data;
struct tvec_base *base;
#ifdef CONFIG_TIMER_STATS
void *start_site;
char start_comm[16];
int start_pid;
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
function 字段包含定时器到期时执行函数的地址。data 字段指定传递给定时器函数的参数。正是由于 data 字段,就可以定义一个单独的通用函数来处理多个设备驱动程序的超时问题,在 data 字段可以存放设备 ID,或其他有意义的数据,定时器函数可以用这些数据区分不同的设备。
expires 字段给出定时器到期时间,时间用节拍数表示,其值为系统启动以来所经过的节拍数。当 expires 的值小于或等于 jiffies 的值时,就说明计时器到期或终止。
entry 字段用于将软定时器插入双向循环链表队列中,该链表根据定时器 expires 字段的值将它们分组存放。我们将在本章后面描述使用这些链表的算法。
为了创建并激活一个动态定时器,内核必须:
- 如果需要,创建一个新的 timer_list 对象,比如说设为 t。这可以通过以下几种方式来进行:
- 在代码中定义一个静态全局变量。
- 在函数内定义一个局部变量:在这种情况下,这个对象存放在内核堆栈中。
- 在动态分配的描述符中包含这个对象。
- 调用 init_timer(&t) 函数初始化这个对象。实际上是把 t.base 指针字段置为 NULL 并把 t.lock 自旋锁设为 “打开”。
- 把定时器到期时激活函数的地址存入 function 字段。如果需要,把传递给函数的参数值存入 data 字段。
- 如果动态定时器还没有被插入到链表中,给 expires 字段赋一个合适的值并调用 add_timer(&t) 函数把 t 元素插入到合适的链表中
- 否则,如果动态定时器已经被插入到链表中,则调用 mod_timer() 函数来更新 expires 字段,这样也能将对象插入到合适的链表中(下面将讨论)。
动态定时器与竞争条件
// kernel/timer.c
int del_timer(struct timer_list *timer);
int del_timer_sync(struct timer_list *timer);
动态定时器的数据结构
选择合适的数据结构实现动态定时器并不是件容易的事。把所有定时器放在一个单独的链表中会降低系统的性能,因为在每个时钟节拍去扫描一个定时器的长链表太费时。另一方面,维护一个排序的链表效率也不高,因为插入和删除操作也非常费时。
解决的办法基于一种巧妙的数据结构,即把 expires 值划分成不同的大小,并允许动态定时器从大 expires 值的链表到小 expires 值的链表进行有效的过滤。此外,在多处理器系统中活动的动态定时器集合被分配到各个不同的 CPU 中。
动态定时器的主要数据结构是一个叫做 tvec_bases 的每 CPU 变量(参见第五章的 "每 CPU 变量"一节):它包含 NR_CPUS 个元素,系统中每个 CPU 各有一个。每个元素是一个 tvec_base_t 类型的数据结构、它包含相应 CPU 中处理动态定时器需要的所有数据。
// kernel/timer.c
#define TVN_BITS (CONFIG_BASE_SMALL ? 4 : 6)
#define TVR_BITS (CONFIG_BASE_SMALL ? 6 : 8)
#define TVN_SIZE (1 << TVN_BITS)
#define TVR_SIZE (1 << TVR_BITS)
struct tvec {
struct list_head vec[TVN_SIZE];
};
struct tvec_root {
struct list_head vec[TVR_SIZE];
};
struct tvec_base {
spinlock_t lock;
struct timer_list *running_timer;
unsigned long timer_jiffies;
unsigned long next_timer;
struct tvec_root tv1;
struct tvec tv2;
struct tvec tv3;
struct tvec tv4;
struct tvec tv5;
} ____cacheline_aligned;
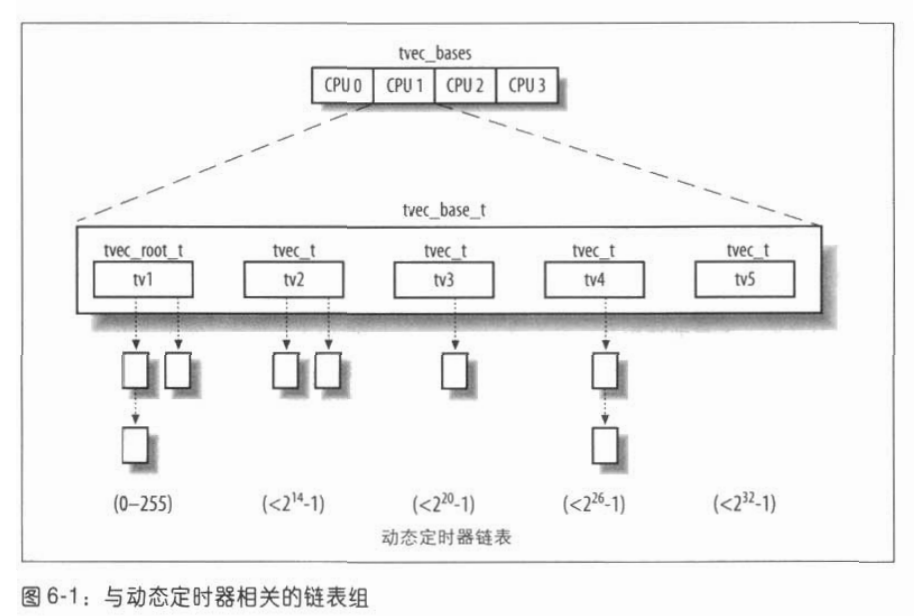
字段 tv1 的数据结构为 tvec_root_t 类型,它包含一个 vec 数组,这个数组由 256 个 list_head 元素组成(即由 256 个动态定时器链表组成)。这个结构包含了在紧接着到来的 255 个节拍内将要到期的所有动态定时器。
字段 tv2、tv3 和 tv4 的数据结构都是 tvec 类型,该类型有一个数组 vec(包含 64 个 list_head 元素)。这些链表包含在紧接着到来的 214-1(8+6)、 220-1(8+6+6) 以及 226-1(8+6+6+6) 个节拍内将要到期的所有动态定时器。
字段 tv5 与前面的字段几乎相同,但唯一区别就是 vec 数组的最后一项是一个大 expires 字段值的动态定时器链表。tv5 从不需要从其他的数组补充。图 6-1 用图例说明了 5 个链表组。
timer_jiffies 字段的值表示需要检查的动态定时器的最早到期时间:如果这个值与 jiffies 的值一样,说明可延迟函数没有积压; 如果这个值小于 jiffies,说明前几个节拍相关的可延迟函数必须处理。该字段在系统启动时被设置成 jiffies 的值,且只能由 run_timer_softirq() 函数(将在下一节描述)增加它的值。注意当处理动态定时器的可延迟函数在很长一段时间内都没有被执行时(例如由于这些函数被禁止或者已经执行了大量中断处理程序),timer_jiffies 字段可能会落后 jiffies 许多。
动态定时器处理
尽管软定时器具有巧妙的数据结构,但是对其处理是一种耗时的活动,所以不应该被时钟中断处理程序执行。在 Linux 2.6 中该活动由可延迟函数来执行,也就是由 TIMER_SOFTIRQ 软中断执行。
// kernel/timer.c
static void run_timer_softirq(struct softirq_action *h)
{
struct tvec_base *base = __get_cpu_var(tvec_bases);
hrtimer_run_pending();
if (time_after_eq(jiffies, base->timer_jiffies))
__run_timers(base);
}
static inline void __run_timers(struct tvec_base *base)
{
struct timer_list *timer;
spin_lock_irq(&base->lock);
while (time_after_eq(jiffies, base->timer_jiffies)) {
struct list_head work_list;
struct list_head *head = &work_list;
int index = base->timer_jiffies & TVR_MASK;
/*
* Cascade timers:
*/
if (!index &&
(!cascade(base, &base->tv2, INDEX(0))) &&
(!cascade(base, &base->tv3, INDEX(1))) &&
!cascade(base, &base->tv4, INDEX(2)))
cascade(base, &base->tv5, INDEX(3));
++base->timer_jiffies;
list_replace_init(base->tv1.vec + index, &work_list);
while (!list_empty(head)) {
void (*fn)(unsigned long);
unsigned long data;
timer = list_first_entry(head, struct timer_list,entry);
fn = timer->function;
data = timer->data;
timer_stats_account_timer(timer);
set_running_timer(base, timer);
detach_timer(timer, 1);
spin_unlock_irq(&base->lock);
{
int preempt_count = preempt_count();
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the timer from
* inside the function that is called from
* it, this we need to take into account for
* lockdep too. To avoid bogus "held lock
* freed" warnings as well as problems when
* looking into timer->lockdep_map, make a
* copy and use that here.
*/
struct lockdep_map lockdep_map =
timer->lockdep_map;
#endif
/*
* Couple the lock chain with the lock chain at
* del_timer_sync() by acquiring the lock_map
* around the fn() call here and in
* del_timer_sync().
*/
lock_map_acquire(&lockdep_map);
trace_timer_expire_entry(timer);
fn(data);
trace_timer_expire_exit(timer);
lock_map_release(&lockdep_map);
if (preempt_count != preempt_count()) {
printk(KERN_ERR "huh, entered %p "
"with preempt_count %08x, exited"
" with %08x?\n",
fn, preempt_count,
preempt_count());
BUG();
}
}
spin_lock_irq(&base->lock);
}
}
set_running_timer(base, NULL);
spin_unlock_irq(&base->lock);
}
run_timer_softirq() 函数是与 TIMER_SOFTIRQ 软中断请求相关的可延迟函数。它实质上执行如下操作:
-
把与本地 CPU 相关的 tvec_base_t 数据结构的地址存放到 base 本地变量中。
-
获得 base->lock 自旋锁并禁止本地中断。
-
开始执行一个 while 循环,当 base->timer_jiffies 大于 jiffies 的值时终止。在每一次循环过程中,执行下列子步骤:
- 计算 base->tv1 中链表的索引,该索引保存着下一次将要处理的定时器:
index = base->timer_jiffies & 255; - 如果索引值为 0,说明 base->tv1 中的所有链表已经被检查过了,所以为空:于是该通数通过调用 cascade() 来过滤动态定时器:
考虑第一次调用 cascade() 函数的情况:它接收 base 的地址、base->tv2 的地址、base->tv2(包括在紧接着到来的 256 个节拍内将要到期的定时器)中链表的索引作为参数。该索引值是通过观察 base->timer_jiffies 的特殊位上的值来决定的。
cascade() 函数将 base->tv2 中链表上的所有动态定时器移到 base->tv1 的适当链表上。然后,如果所有 base->tv2 中的链表不为空,它返回一个正值。如 base->tv2 中的链表为空,cascade() 将再次被调用,把 base->tv3 中的某个链表上包含的定时器填充到 base->tv2 上,如此等等。 - 使 base->timer_jiffies 的值加 1。
- 对于 base->tv1.vec[index] 链表上的每一个定时器,执行它所对应的定时器函数。特别说明的是,链表上的每个 timer_list 元素 t 实质上执行以下步骤:
(1)将 t 从 base->tv1 的链表上删除。
(2) 在多处理器系统中,将 base->running_timer 设置为 &t (t 的地址)。
(3)设置 t.base 为 NULL。
(4) 释放 base->lock 自旋锁,并允许本地中断。
(5) 传递 t.data 作为参数,执行定时器函数 t.function。
(6) 获得 base->lock 自旋锁,并禁止本地中断。
(7) 如果链表中还有其他定时器,则继续处理。 - 链表上的所有定时器已经被处理。继续执行最外层 while 循环的下一次循环。
- 计算 base->tv1 中链表的索引,该索引保存着下一次将要处理的定时器:
-
最外层的 while 循环结束,这就意味着所有到期的定时器已经被处理了。在多处理器系统中,设置 base->running_timer 为 NULL。
-
释放 base->lock 自旋锁并允许本地中断。
由于 jiffies 和 timer_jiffies 的值经常是一样的,所以最外层的 while 循环常常只执行一次。一般情况下,最外层循环会连续执行 jiffies - base->timer_jiffies + 1 次。此外,如果在 run_timer_softirq() 正在执行时发生了时钟中断,那么也得考虑在这个节拍所出现的到期动态定时器,因为 jiffies 变量的值是由全局时钟中断处理程序异步增加的(参见前面的 “时钟中断处理序” 一节)。
请注意,就在进入最外层循环前,run_timer_softirq() 要禁止中断并获取 base->lock 自旋锁,调用每个动态定时器函数前,激活中断并释放自旋锁,直到函数执行结束。这就保证了动态定时器的数据结构不被交错执行的内核控制路径所破坏。
综上所述可知,这种相当复杂的算法确保了极好的性能。让我们来看看为什么,为了简单起见,假定 TIMER_SOFTIRQ 软中断正好在相应的时钟中断发生后执行。那么,在 256 次中出现的 255 次时钟中断(也就是在 99.6% 的情况中),run_timer_softirq() 仅仅运行到期定时器的函数。为了周期性地补充 base->tv1.vec,在 64 次补充当中,63 次足以把 base->tv2 指向的链表分成 base->tv1 指向的 256 个链表。依次地,base->tv2.vec 数组必须在 0.006% 的情况下得到补充,即每 16.4 秒一次。类似地,每 17 分 28 秒补充一次 base->tv3.vec,每 18 小时 38 分补充一次 base->tv4.vec,而 base->tv5.vec 不需被补充。
动态定时器应用之一:nanosleep()系统调用
为了说明前面所有活动的结果如何在内核中实际使用,我们给出创建和使用进程延时的例子。
让我们考虑 nanosleep() 系统调用的服务例程程,即 sys_nanosleep(),它接收一个指向 timespec 结构的指针作为参数,并将调用进程挂起直到特定的时间间隔用完。服务例程首先调用 copy_from_user() 将包含在 timespec 结构(用户态下)中的值复制到局部变量 t 中。假设 timespec 结构定义了一个非空的延迟,接着函数执行如下代码:
current->state = TASK_INTERRUPTIBLE;
remaining = schedule_timeout(timespec_to_jiffies(&t)+1);
timespec_to_jiffies() 函数将存放在 timespec 结构中的时间间隔转换成节拍数。为保险起见,sys_nanosleep() 为 timespec_to_jiffies() 计算出的值加上一个节拍。
内核使用动态定时器来实现进程的延时。它们出现在 schedule_timeout() 函数中,该
函数执行下列语句:
struct timer_list timer;
unsigned long expire = timeout + jiffies;
init_timer(&timer);
timer.expires = expire;
timer.data = (unsigned long) current;
timer.function = process_timeout;
add_timer(&timer);
schedule(); /* 进程挂起直到定时器到时 */
del_singleshot_timer_sync(&timer);
timeout = expire - jiffies;
return (timeout < 0 ? 0 : timeout);
当 schedule() 被调用时,就选择另一个进程执行; 当前一个进程恢复执行时,该函数就删除这个动态定时器。在最后一句中,函数返回的值有两种可能,0 表示延时到期,timeout 表示如果进程因某些其他原因被唤醒,到延时到期时还剩余的节拍数。
当延时到期时,内核执行下列函数:
void process_timeout(unsigned long __data) {
wake_up_process((task_t *)__data);
}
process_timeout() 接收进程描述符指针作为它的参数,该指针存放在定时器对象的 data 字段。结果,挂起的进程被唤醒。
一旦进程被唤醒,它就继续执行 sys_nanosleep() 系统调用。如果 schedule_timeout() 返回的值表明进程延时到期(值为 0),系统调用就结束。否则,系统调用将自动重新启动,正如第十一章的 “系统调用的重新执行” 一节中解释的那样。
(b)延迟函数
当内核需要等待一个较短的时间间隔 —— 比方说,不超过几毫秒时,就无需使用软定时器。例如,通常设备驱动器会等待预先定义的数个微秒直到硬件完成某些操作。由于动态定时器通常有很大的设置开销和一个相当大的最小等待时间(1ms),所以设备驱动器使用它会很不方便。
在这些情况下,内核使用 udelay() 和 ndelay() 函数:前者接收一个微秒级的时间间隔作为它的参数,并在指定的延迟结束后返回,后者与前者类似,但是指定延迟的参数是纳秒级的。
可参考 ==> 4、延迟执行
3、与定时测量相关的系统调用
(1)time() 和 gettimeofday() 系统调用
time()
返回从 1970 年 1 月 1 日午夜(UTC)开始所走过的秒数。
gettimeofday()
返回从 1970 年 1 月 1 日午夜(UTC)开始所走过的秒数及在前 1 秒内走过的微秒数,这个值存放在数据结构 timeval 中
(2)adjtimex() 系统调用
网络定时协议(NTP)
(3)setitimer() 和 alarm() 系统调用
setitimer() 系统调用可以激活间隔定时器。
#include <sys/time.h>
int setitimer(int which, const struct itimerval *new_value,
struct itimerval *old_value);
(4)与POSIX定时器相关的系统调用

七、进程调度
1、调度策略

2、调度程序所使用的函数

八、内存管理
1、页框管理
(1)页描述符
内核必须记录每个页框当前的状态。例如,内核必须能区分哪些页框包含的是属于进程的页,而哪些页框包含的是内核代码或内核数据。类似地,内核还必须能够确定动态内存中的页框是否空闲。如果动态内存中的页框不包含有用的数据,那么这个页框就是空闲的。在以下情况下页框是不空闲的:包含用户态进程的数据、某个软件高速缓存的数据、动态分配的内核数据结构、设备驱动程序缓冲的数据、内核模块的代码等等。
页框的状态信息保存在一个类型为 page 的页描述符中,其中的字段如表 8-1 所示。所有的页描述符存放在 mem_map 数组中。因为每个描述往长度为 32 字节。所以 mem_map 所需要的空间略小于整个 RAM 的 1%。virt_to_page(addr) 宏产生线性地址 addr 对应的页描述符地址。pfn_to_page(pfn) 宏产生与页框号 Pfn 对应的页描述符地址。
// include/linux/mm_types.h
/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
*/
struct page {
/* 一组标志(参见表 8-2)。也对页框所在的管理区进行编号 */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/* 页框的引用计数器 */
atomic_t _count; /* Usage count, see below. */
union {
/* 页框中的页表项数目(如果没有则为 -1) */
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
struct { /* SLUB */
u16 inuse;
u16 objects;
};
};
union {
struct {
/* 可用于正在使用页的内核成分(例如,在缓冲页的情况下它是一个缓冲器
* 头指针;参见第15章的 “块缓冲区和缓冲区首部” 一节)。如果页是
* 空闲的,则该字段由伙伴系统使用 */
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
/* 当页被插入页高速缓存中时使用(参见第15章 “页高速缓存” 一节),
* 或者当页属于匿名区时使用(参见第17章的 “匿名页的反向映射”
* 一节) */
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
/* 作为不同的含义被几种内核成分使用。例如,它在页磁盘映像
* 或匿名区中标识存放在页框中的数据的位置(参见第15章),
* 或者它存放一个换出页标识符(第17章) */
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
/* 包含页的最近最少使用(LRU)双向链表的指针 */
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
};
这里详细地描述以下两个字段:
- _count
页的引用计数器。如果该字段为 -1,则相应页框空闲,并可被分配给任一进程或内核本身;如果该字段的值大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放一些内核数据结构。page_count() 函数返回 _court 加 1 后的值,也就是该页的使用者的数目。 - flags
包含多达 32 个用来描述页框状态的标志(参见表 8-2)。对于每个 PG_xyz 标志,内核都定义了操纵其值的一些宏。通常,PageXyz 宏返回标志的值,而 SetPageXyz 和 ClearPageXyz 宏分别设置和清除相应的位。

(2)非一致内存访问(NUMA)
我们习惯上认为计算机内存是一种均匀、共享的资源。在忽略硬件高速缓存作用的情况下,我们期望不管内存单元处于何处,也不管 CPU 处于何处,CPU 对内存单元的访问都需要相同的时间。可惜,这种假设在某些体系结构上并不总是成立。例如,对于某些多处理器 Alpha 或 MIPS 计算机,这就不成立。
Linux 2.6 支持非一致内在访问(Non-Uniform Memory Access ,NUMA)模型,在这种模型中,给定 CPU 对不同内存单元的访问时间可能不一样。系统的物理内存被划分为几个节点(node)。在一个单独的节点内,任一给定 CPU 访问页面所需的时间都是相同的。然而,对不同的 CPU,这个时间可能就不同。对每个 CPU 而言,内核都试图把耗时节点的访问次数减到最少,这就要小心地选择 CPU 最常引用的内核数据结构的存放位置(注 1)。
每个节点中的物理内存又可以分为几个管理区(Eone),这我们将在下一节介绍。每个节点都有一个类型为 pg_data_t 的描述符,它的字段如表 8-3 所示。所有节点的描述符存放在一个单向链表中,它的第一个元素由 pgdat_list 变量指向。
// include/linux/mmzone.h
typedef struct pglist_data {
/* 节点中管理区描述符的数组 */
struct zone node_zones[MAX_NR_ZONES];
/* 页分配器使用的 zonelist 数据结构的数组
* (参见后面 “内存管理区” 一节) */
struct zonelist node_zonelists[MAX_ZONELISTS];
/* 节点中管理区的个数 */
int nr_zones;
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
/* 节点中页描述符的数组 */
struct page *node_mem_map;
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
struct page_cgroup *node_page_cgroup;
#endif
#endif
#ifndef CONFIG_NO_BOOTMEM
/* 用在内核初始化阶段 */
struct bootmem_data *bdata;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* Nests above zone->lock and zone->size_seqlock.
*/
spinlock_t node_size_lock;
#endif
/* 节点中第一个页框的下标 */
unsigned long node_start_pfn;
/* 内存节点的大小,不包括洞(以页框为单位) */
unsigned long node_present_pages; /* total number of physical pages */
/* 节点的大小,包括洞(以页框为单位) */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
/* 节点标识符 */
int node_id;
/* kswapd 页换出守护进程使用的等待队列
* (参加第17章的 “周期回收” 一节) */
wait_queue_head_t kswapd_wait;
/* 指针指向 kswapd 内核线程的进程描述符 */
struct task_struct *kswapd;
/* kswapd 将要创建的空闲块大小取对数的值 */
int kswapd_max_order;
} pg_data_t;
我们同样只关注 80x86 体系结构。IBM 兼容 PC 使用一致访问内存(UMA)模型,因此,并不真正需要 NUMA 的支持。然而,即使 NUMA 的支持没有编译进内核,Linux 还是使用节点,不过,这是一个单独的节点,它包含了系统中所有的物理内存。因此,pgdat_list 变量指向一个链表,此链表是由一个元素组成的,这个元素就是节点 0 描述符,它被存放在 contig_page_data 变量中。
在 80x86 结构中,把物理内存分组在一个单独的节点中可能显得没有用处,但是,这种方式有助于内存代码的处理更具有可移植性,因为内核假定在所有的体系结构中物理内存都被划分为一个或多个节点。
(3)内存区管理
在一个理想的计算机体系结构中,一个页框就是一个内存存储单元,可用于任何事情:存放内核数据和用户数据、缓冲磁盘数据等等。任何种类的数据页都可以存放在任何页框中,没有什么限制。
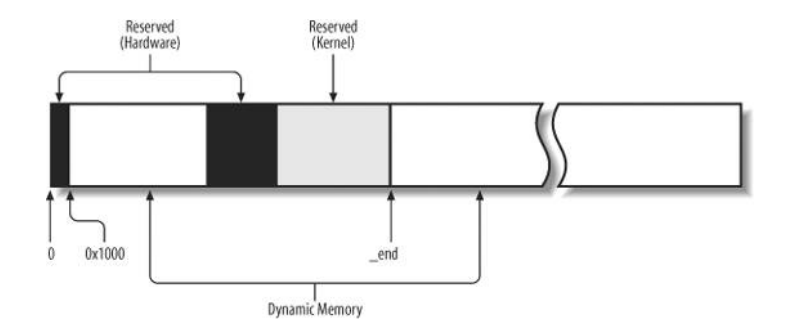
但是,实际的计算机体系结构有硬件的制约,这限制了页框可以使用的方式。尤其是,Linux 内核必须处理 80x86 体系结构的两种硬件约束:
-
ISA 总线的直接内存存取(DMA)处理器有一个严格的限制:它们只能对 RAM 的前 16MB 寻址。
-
在具有大容量 RAM 的现代 32 位计算机中,CPU 不能直接访问所有的物理内存,因为线性地址空间太小。
为了应对这两种限制,Linux 2.6 把每个内在节点的物理内在划分为 3 个管理区(zone)。在 80x86 UMA 体系结拉中的管理区为:
-
ZONE_DMA
包含低于 16 MB 的内存页框 -
ZONE_NORMAL
包含高于 16 MB 且低于 896 MB 的内存页框 -
ZONE_HIGHMEM
包含从 896MB 开始高于 896 MB 的内存页框
ZONE_DMA 和 ZONE_NORMAL 区包含内存的 “常规” 页框,通过把它们线性地映射到线性地址空间的第 4 个 GB,内核就可以直接进行访问(参见第二章的 “内核页表” 一节)。相反,ZONE_HIGHMEM 区包含的内存页不能由内核直接访问。尽管它们也线性地映射到了线性地址空间的第 4 个 GB(参见本章后面 “高端内存页框的内核映射” 一节)。在 64 位体系结构上 ZONE_HIGHMEM 区总是空的。
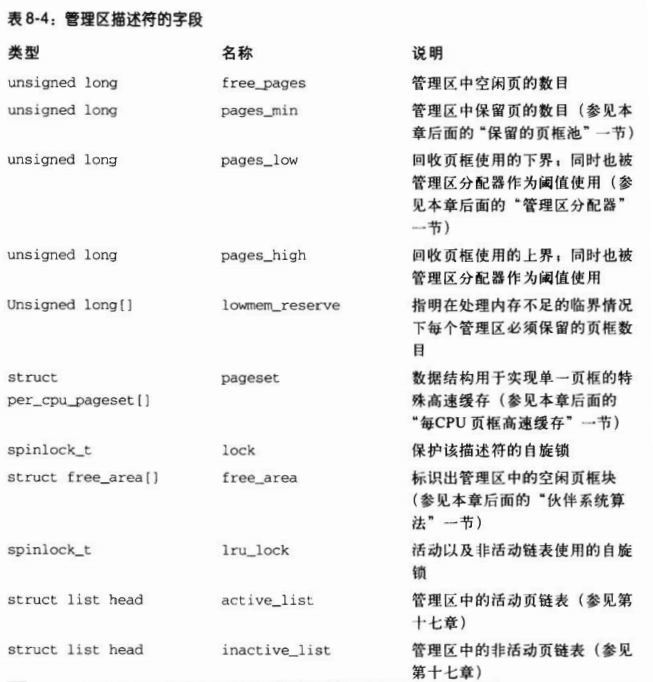
每个内存管理区都有自己的描述符。它的字段如表 8-4 所示。
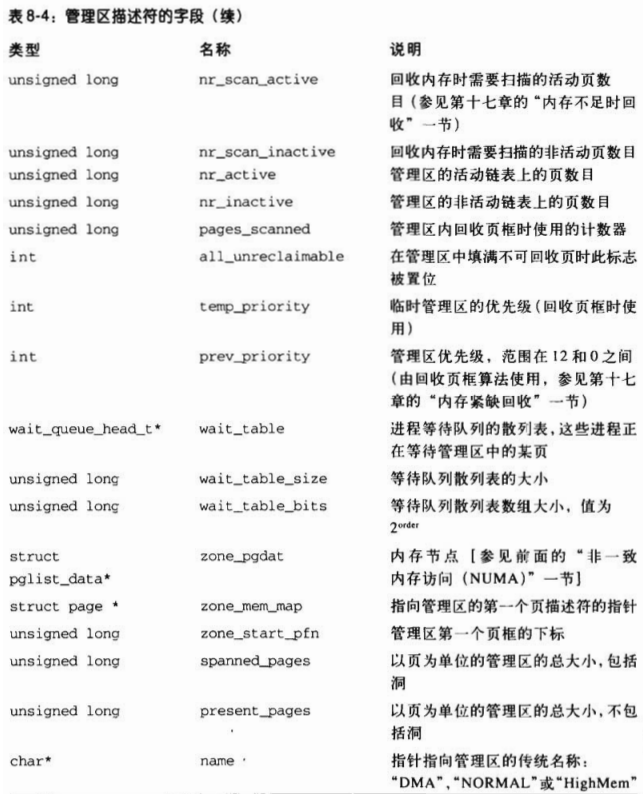
管理区结构中的许多字段用于回收页框,相关内容将在第十七章中描述。
每个页描述符都有到内存节点和到节点内管理区(包含相应页框)的链接。为节省空间,这些链接的存放方式与典型的指针不同,而是被编码成索引存放在 flags 字段的高位。
实际上,刻画页框的标志的数目是有限的,因此保留 flags 字段的最高位来编码特定内存节点和管理区号总是可能的(注 3)。page_zone() 函数接收一个页描述符的地址作为它的参数;它读取页描述符中 flags 字段的最高位,然后通过查看 zone_table 数组来确定相应管理区描述符的地址。在启动时用所有内存节点的所有管理区描述符的地址初始化这个数组。
当内核调用一个内存分配函数时,必须指明请求页框所在的管理区。内核通常指明它愿意使用哪个管理区。例如,如果一个页框必须直接映射在线性地址的第 4 个 GB,但它又不用于 ISA DMA 的传输,那么,内核不是在 ZONE_NORMAL 区就是在 ZONE_DMA 区请求一个页框。当然,如果 ZONE_NORMAL 没有空闲页框,那么,应该从 ZONE_DMA 获取页框。为了在内存分配请求中指定首选管理区,内核使用 zonelist 数据结构,这就是管理区描述符指针数组。
注 3:为索引保留的位的数目取决于内核是否支持 NUMA 模型以及 flags 字段的大小。如果不支持 NUMA,那么 flags 字段中管理区索引占两位、节点索引占一位(通常设为 0)。在 NUMA 32 位体系结构上,flags 中管理区索引占两位,节点数目占六位。最后,在 NUMA 64 位体系结构上,64 位的 flags 字段中管理区索引占两位,节点数目占十位。
(4)保留的页框池
可以用两种不同的方法来满足内存分配请求。如果有足够的空闲内存可用,请求就会被立刻满足。否则,必须回收一些内存,并且将发出请求的内核控制路径阻塞,直到有内存被释放。
不过,当请求内存时,一些内核控制路径不能被阻塞 —— 例如,这种情况发生在处理中断或在执行临界区内的代码时。在这些情况下,一条内核控制路径应当产生原子内存分配请求(使用 GFP_ATOMIC 标志; 参见稍后的 “分区页框分配器” 一节)。原子请求、从不被阻塞:如果没有足够的空闲页,则仅仅是分配失败而已。
尽管无法保证一个原子内存分配请求决不失败,但是内核会设法尽量减少这种不幸事件发生的可能性。为做到这一点,内核为原子内存分配请求保留了一个页框池,只有在内存不足时才使用。
保留内存的数量(以 KB 为单位)存放在 min_free_kbytes 变量中。它的初始值在内核初始化时设置,并取决于直接映射到内核线性地址空间第 4 个 GB 的物理内存的数量 —— 也就是说,取决于包含在 ZONE_DMA 和 ZONE_NORMAL 内存管理区内的页框数目:
保留池的大小 = 16 × 直接映射内存 ( K B ) 保留池的大小 = \sqrt{16 \times 直接映射内存}(KB) 保留池的大小=16×直接映射内存(KB)
但是,min_free_kbytes 的初始值不能小于 128 也不能大于 65536(注 4)。ZONE_DMA 和 ZONE_NORMAL 内存管理区将一定数量的页框贡献给保留内存,这个数目与两个管理区的相对大小成比例。例如,如果 ZONE_NORMAL 管理区比 ZONE_DMA 大 8 倍,那么页框的 7/8 从 ZONE_NORMAL 获得,而 1/8 从 ZONE_DMA 获得。
管理区描述符的 pages_min 字段存储了管理区内保留页框的数目。正如我们将在第十七章看到的,这个字段和 pages_low、pages_high 字段一起还在页框回收算法中起作用。 pages_low 字段总是被设为 pages_min 的值的 5/4,而 pages_high 总是被设为 pages_min 的值的 3/2。
注 4: 稍后系统管理员可以通过写入 /proc/sys/vm/min_free_kbytes 文件或通过发出一个适当的 sysctl() 系统调用来更改保留内存的数量。
(5)分区页框分配器
被称作分区页框分配器(zoned page frame allocator)的内核子系统,处理对连续页框组的内存分配请求。它的主要组成如图 8-2 所示。
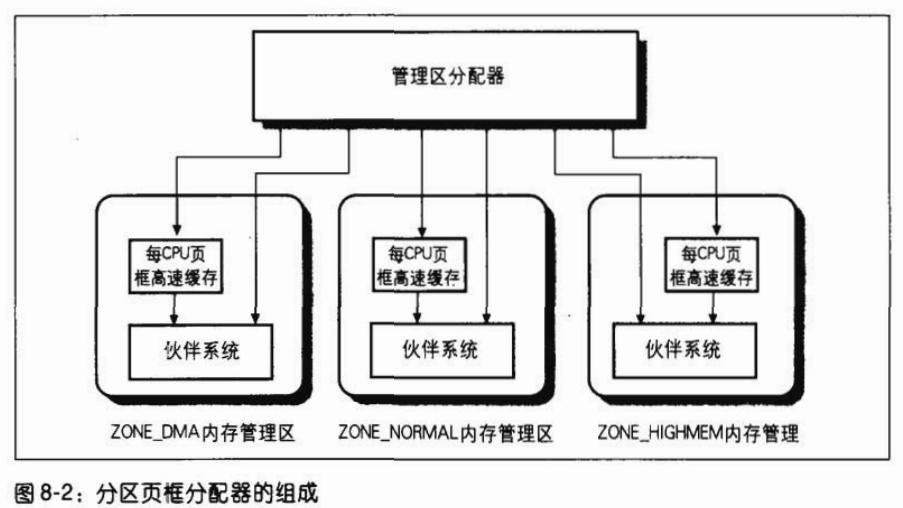
其中,名为 “管理区分配器” 部分接受动态内存分配与释放的请求。在请求分配的情况下,该部分搜索一个能满足所请求的一组连续页框内存的管理区(参见后面的 “管理区分配器” 一节)。在每个管理区内,页框被名为伙伴系统(参见后面的 “伙伴系统算法” 一节)的部分来处理。为达到更好的系统性能,一小部分页框保留在高速缓存中用于快速地满足对单个页框的分配请求 (参见后面的 “每 CPU 页框高速缓存” 一节)。














 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









