






线程池介绍见:https://blog.csdn.net/Lllpppyyyl/article/details/138313837?spm=1001.2014.3001.5502
1、如何实现?
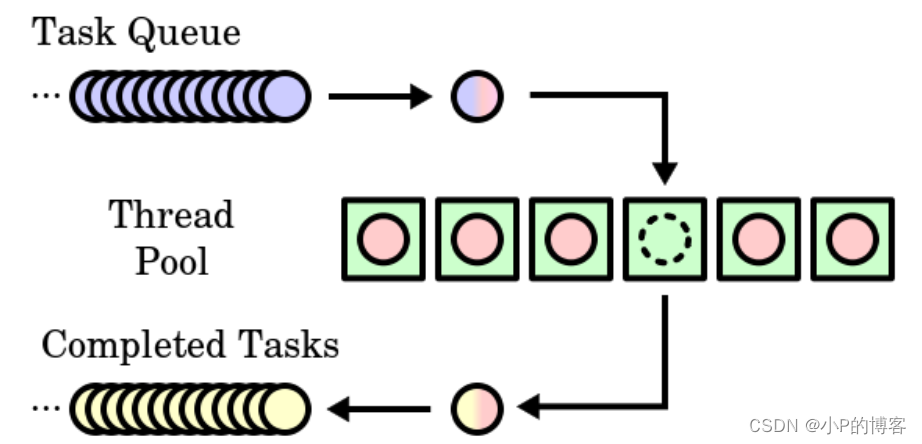
首先,从上往下看,我们使用一个队列来存储Task Queue。入队的操作即是将一个任务提交到Task Queue.
当表示一个任务时,通常可以使用一个函数来表示。这个函数可能有不确定数量和类型的参数。为了处理这种情况,我们可以使用可变参数函数模板。但是,由于函数参数的类型是未知的,我们需要一种通用的方式来处理它们。为了解决这个问题,我们可以使用 std::bind、std::function 和 std::packaged_task 等功能来进行层层封装,以处理不同类型的参数和返回值。
其中一个难点在于如何将不同类型的参数统一起来。通过使用 std::bind,我们可以将函数及其参数绑定成一个可调用对象,使其具有相同的函数签名。然后,我们可以将这些可调用对象存储在 std::function 对象中,这样就可以在不同的上下文中使用它们,而无需关心其具体类型。
同步和互斥操作也是关键。在多线程环境中,我们需要确保任务的执行是线程安全的。因此,我们需要使用互斥锁来保护共享资源,以确保在多个线程同时访问时,不会发生数据竞争和其他并发问题。通过使用互斥锁,我们可以确保在适当的时候对共享资源进行同步操作,从而避免出现不一致的结果。
其次,线程池的工作原理是关键。我们使用一个 vector 来存储线程对象。主要思路是,当没有任务时,线程保持非活跃状态;当有任务到来时,线程开始执行任务。在这个过程中,我们利用了 lambda 表达式的特性,以及同步和互斥操作。
在线程池中,我们通过将任务函数包装成可调用对象,并将其存储在任务队列中。然后,每个线程从任务队列中获取任务并执行。通过使用互斥锁来保护任务队列,我们确保多个线程不会同时修改任务队列,从而避免了竞争条件和其他并发问题的发生。当没有任务可用时,线程会等待,直到有新的任务被提交。这种机制确保了线程池的高效利用,并且在需要时可以动态地调整线程的数量。
最后,让我们来实现线程池的析构函数。我们可以使用一个布尔变量来标记是否需要停止使用线程池。当需要析构线程池时,我们唤醒所有线程,并逐个执行 join 操作。
在析构函数中,我们首先将布尔变量设置为 true,以通知所有线程停止执行任务。然后,我们使用条件变量来唤醒所有线程,告知它们条件已经改变,需要重新检查是否需要停止执行任务。最后,我们遍历线程池中的所有线程,并对每个线程执行 join 操作,等待它们的执行完成。
通过这种方式,我们可以确保在线程池对象被析构时,所有的线程都会被正确地停止和销毁,从而保证了线程池的正常关闭。
2、示例代码
#ifndef __THREADPOOL_H
#define __THREADPOOL_H
#include<thread>
#include<condition_variable>
#include<mutex>
#include<vector>
#include<queue>
#include<future>
class ThreadPool
{
private:
bool m_stop;
std::vector<std::thread> m_thread;
std::queue<std::function<void()>>tasks;
std::mutex m_mutex;
std::condition_variable m_cv;
public:
explicit ThreadPool(size_t ThreadNum)
:m_stop(false)
{
for(size_t i = 0; i < ThreadNum; ++i)
{
m_thread.emplace_back(
[this](){
for (; ; )
{
std::function<void()>task;
{
std::unique_lock<std::mutex> lk(m_mutex);
m_cv.wait(lk,[this](){
return m_stop || !tasks.empty();
});
if (m_stop && tasks.empty())
{
return;
}
task = std::move(tasks.front());
tasks.pop();
}
task();
}
}
);
}
}
//删除了拷贝构造函数
//通过将其声明为 delete,编译器将禁止使用拷贝构造函数创建线程池对象的副本。
ThreadPool(const ThreadPool&) = delete;
//删除了移动构造函数
//通过将其声明为 delete,编译器将禁止使用移动构造函数移动线程池对象。
ThreadPool(ThreadPool &&) = delete;
//拷贝赋值运算符
//这意味着禁止使用另一个线程池对象来初始化当前线程池对象的内容,
//也禁止将一个线程池对象的内容赋值给另一个线程池对象
//因为线程池可能管理着共享的资源,进行拷贝赋值会导致资源的不正确管理
ThreadPool& operator=(const ThreadPool &) = delete;
//这行代码删除了移动赋值运算符
//这意味着禁止使用右值引用(通过移动语义)来初始化当前线程池对象的内容
ThreadPool& operator=(const ThreadPool &&) = delete;
//std::unique_lock<std::mutex> lk(m_mutex);
//创建了一个 std::unique_lock 对象 lk,用于锁定互斥锁 m_mutex
//这样做是为了确保在修改 m_stop 变量时线程安全。
//m_stop = true;
//将 m_stop 变量设置为 true,表示线程池应该停止
//这个操作会通知所有线程从任务队列中获取任务时,发现线程池已经停止,从而退出循环,停止执行任务
~ThreadPool()
{
std::unique_lock<std::mutex> lk(m_mutex);
m_stop = true;
//通知所有正在等待条件变量 m_cv 的线程,告知它们条件已经改变。
//这会唤醒所有因为等待条件变量而阻塞的线程,
//让它们可以检查是否需要退出执行。
m_cv.notify_all();
//遍历线程池中的所有线程
for (auto& threads: m_thread)
{
//对每个线程调用 join() 方法,等待线程的执行结束
threads.join();
}
}
template<typename F, typename... Args>
auto submit(F&& f, Args&&... args)->std::future<decltype(f(args...))>{
//创建了一个 std::packaged_task 对象
//并通过 std::bind 绑定了函数对象 f 和它的参数 args...
//使用 std::make_shared 创建了一个 shared_ptr 来管理这个 std::packaged_task 对象
//以确保任务的生命周期延长到任务执行完成后。
auto taskPtr = std::make_shared<std::packaged_task<decltype(f(args...))()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
//新的作用域,用于锁定互斥锁并向任务队列中添加任务
{
std::unique_lock<std::mutex> lk(m_mutex);
if (m_stop)
{
throw std::runtime_error("submit on stopped ThreadPool");
}
//向任务队列中添加一个 lambda 表达式
//这个 lambda 表达式捕获了 taskPtr
//并在执行时调用 (*taskPtr)(),即执行绑定的任务函数
tasks.emplace([taskPtr](){(*taskPtr)();});
}
//通知一个等待条件变量 m_cv 的线程,告知它有新的任务可以执行
m_cv.notify_one();
//返回任务的 std::future 对象,用于获取任务的结果。
return taskPtr->get_future();
}
};
#endif3、测试代码
#include<iostream>
#include<vector>
#include<future>
#include<functional>
#include"ThreadPool.h"
#include<random>
//生成真正随机的种子
std::random_device rd;
//使用 rd() 作为种子,以保每次程序运行时都会生成不同的随机数序列
std::mt19937 mt(rd());
//区间 [-100, 100] 内均匀分布的随机整数
std::uniform_int_distribution<int> dist(-100,100);
//std::bind 绑定 dist 和 mt,创建了一个名为 rand 的函数对象
auto rnd = std::bind(dist,mt);
void simulate_hard_computation()
{
//使当前线程休眠一段时间
std::this_thread::sleep_for(std::chrono::milliseconds(200+rnd()));
}
void multiply(const int a, const int b)
{
simulate_hard_computation();
const int ans = a * b;
std::cout << a << " * " << b << " = " << ans << std::endl;
}
int main()
{
ThreadPool _pool(4);
for (int i = 0; i < 8; i++)
{
_pool.submit(multiply,i,i+1);
}
std::this_thread::sleep_for(std::chrono::seconds(2));
return 0;
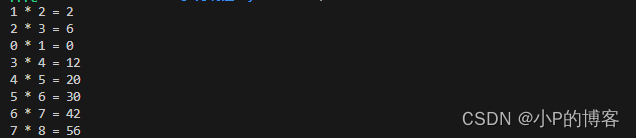
}4、测试结果
参考资料:
GitHub - mtrebi/thread-pool: Thread pool implementation using c++11 threads















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









