






引言
上一篇文章我学习了基本的扫描算子SeqScan,跟踪学习了主要的执行流程。这篇文章我将学习索引扫描算子IndexScan。
代码位置
src\gausskernel\runtime\executor\nodeIndexscan.cpp
名词解释
索引
1.什么是索引
数据库索引是为了提高查询速度而设立了一种数据结构。例如,日常生活中查字典时,可以通过拼音或者部首+笔画数快速地查找汉字,这里的拼音、部首、笔顺等都可以算作索引,如果没有了索引,就只能阅读整本字典,一一查找所需的汉字,这与建立索引相比,无疑是效率很低的做法。因此,建立索引能显著提高查询的速度和效率。
同样,数据库中,默认扫描方式是全表扫描,而建立了索引之后,扫描时会直接定位到索引值对应的行数,大大减少遍历的次数。
2.索引适用的条件
索引是一种数据结构,会占用一定的存储空间,并且需要额外维护,不是所有情况下都适合建立索引。例如:
- 经常INSERT、DELETE、UPDATE 的字段不适合建立索引,因为,每此执行这些语句后都要更新索引。
- 数据过滤性差的字段不适合建立索引,例如性别。对过滤性差的字段建立索引提高的效率并不高,甚至会负提升。
- 当表较小时不适合建立索引,此时建立索引提高的效率不足以补偿建立索引带来的维护以及存储成本。
3.索引的数据结构
索引采用B+ Tree作为其数据结构。
一个B+ Tree有如下特征:
- 非叶子节点最多有m(m>=2)个孩子结点,最少有[m/2]+1个孩子结点([]是取整函数)。
- 只有叶子结点存储表中字段的实际行号。
- 每个结点都存储索引key。
- 叶子结点间通过链表连接起来。
结构示意如图(图中是一颗三叉B+ Tree):
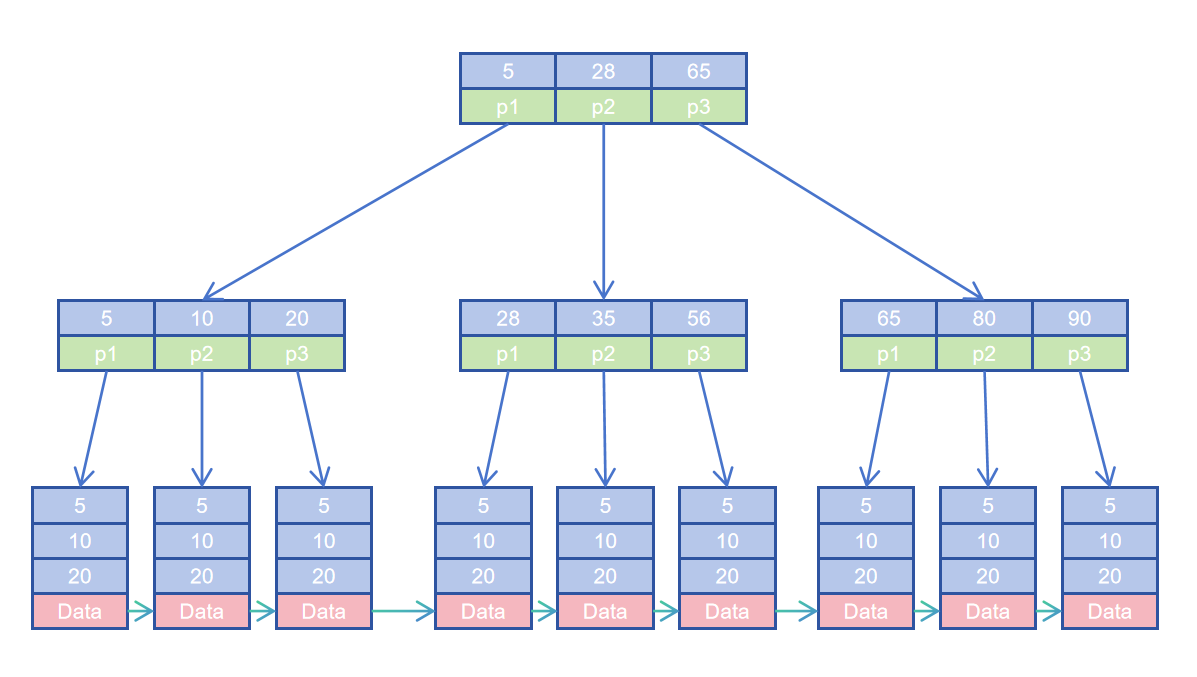
图中数字代表key。例如根节点5 28 65代表p1子树里所有节点的key必须在[5,28)内,p2子树里所有节点的key必须在[28,65)内,p3子树结点的key>=65。
Data即为通过索引key值定位到的数据。
关于B+ Tree的插入和删除等操作,这里就不再讲解,有兴趣的读者可以在网上搜索相关内容。
4.索引采用B+ Tree的好处
- 索引效率高,占用内存少的情况下能存入大量的索引。
- 适用性广泛,能较好地支持单点查询,范围查询等。
代码解读
ExecIndexScan
IndexSCan算子的关键代码是ExecIndexScan函数,其代码如下。
//代码清单1TupleTableSlot* ExecIndexScan(IndexScanState* node){/** If we have runtime keys and they've not already been set up, do it now.*/if (node->iss_NumRuntimeKeys != 0 && !node->iss_RuntimeKeysReady) {/** set a flag for partitioned table, so we can deal with it specially* when we rescan the partitioned table*/if (node->ss.isPartTbl) {if (PointerIsValid(node->ss.partitions)) {node->ss.ss_ReScan = true;ExecReScan((PlanState*)node);}} else {ExecReScan((PlanState*)node);}}return ExecScan(&node->ss, (ExecScanAccessMtd)IndexNext, (ExecScanRecheckMtd)IndexRecheck);}
传入参数
ExecIndexScan函数的传入参数是一个IndexScanState*类型的指针。
IndexScanState结构体定义如下:
typedef struct IndexScanState {ScanState ss; /* its first field is NodeTag */List* indexqualorig;ScanKey iss_ScanKeys;int iss_NumScanKeys;ScanKey iss_OrderByKeys;int iss_NumOrderByKeys;IndexRuntimeKeyInfo* iss_RuntimeKeys;int iss_NumRuntimeKeys;bool iss_RuntimeKeysReady;ExprContext* iss_RuntimeContext;Relation iss_RelationDesc;IndexScanDesc iss_ScanDesc;List* iss_IndexPartitionList;LOCKMODE lockMode;Relation iss_CurrentIndexPartition;} IndexScanState;
主要字段解释如下:
| 类型 | 命名 | 含义 |
|---|---|---|
| ScanState | ss | 扫描状态基类 |
| List* | indexqualorig | 索引限定表达式的执行状态 |
| ScanKey | iss_ScanKeys | 索引里key值 |
| int | iss_NumScanKeys | 扫描时的key值数量 |
| IndexRuntimeKeyInfo* | iss_RuntimeKeys | 当前key |
| int | iss_NumRuntimeKeys | 当前key数量 |
| ScanKey | iss_OrderByKeys | 排序key |
| int | iss_NumOrderByKeys | 排序key数量 |
执行过程
如果结点正在被运行,则调用ExecReScan重置扫描,更新新的参数信息。
然后调用ExecScan函数并返回一个元组。
小结
本篇文章中我学习了IndexScan算子的关键函数,并且介绍了opengauss中索引及其采用的数据结构。下一篇文章:TidScan算子。















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









