




SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
原文链接:[SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS]([1609.02907] Semi-Supervised Classification with Graph Convolutional Networks)
代码仓库:代码 ps:原作者使用的语言是Tensorflow
这是一篇发表于ICLR2017的论文,也是属于上古真神,解读其的博客不胜枚举。故此博客不多赘述数学公式的推导过程,而是更多的从“直觉”角度展示这篇论文的图卷积方法,如果想要“更数学”的内容,可以参阅图卷积网络(Graph Convolutional Networks, GCN)详细介绍-CSDN博客这篇博客。
1:Motivation & Contributions
2017年正是CNN大行其道的时代。由于CNN在图像任务上取得的亮眼表现,自然会有人尝试将其用于不同的任务,本文便是将其稍作变换,并用于图,进行节点预测任务的例子。
作者对其任务的描述为“半监督”式的学习任务,也就是已知图上一些节点的信息,填补图上未知点的信息。本算法的时间复杂度是线性的,所以随着节点个数的增多,资源消耗是线性增加的,表明其在大规模数据集上的应用潜能。并且,作者开创性的提出了“图卷积”这种操作,为后续的很多工作提供了思路。
2:Methodology
作者的所有工作都可以用一个数学表达式概括:
H
(
l
+
1
)
=
σ
(
D
~
−
1
2
A
~
D
~
−
1
2
H
(
l
)
W
(
l
)
)
(1)
H(l+1) = σ (\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}) \tag{1}
H(l+1)=σ(D~−21A~D~−21H(l)W(l))(1)
下面我将从直觉的角度仔细分析其中字母代表的意义。
其中
A
~
\tilde{A}
A~为优化过的邻接矩阵,计算公式如下,其中
I
N
I_N
IN为单位矩阵:
A
~
=
A
+
λ
I
N
\tilde{A}=A+\lambda I_{N}
A~=A+λIN
这里为什么说
A
~
\tilde{A}
A~是优化过的邻接矩阵呢,因为原始的邻接矩阵并没有考虑自身这个节点。优化过的邻接矩阵就用某种权重将其加入其中,参与训练,这是符合逻辑的。
D
~
\tilde{D}
D~代表的是每个节点的度。后者是一个对角矩阵,详细的计算公式如下:
D
~
i
i
=
∑
j
A
~
i
j
\tilde{D}_{ii}=\sum_{j}\tilde{A}_{ij}
D~ii=j∑A~ij
W矩阵为一个可学习的权重矩阵。原论文中使用了两个W,其中
W
0
W^0
W0的作用是将输入维度映射到隐藏层的维度,而
W
1
W^1
W1则是将隐藏层维度映射到输出层维度。并且使用梯度下降法进行训练。
σ
(
)
\sigma()
σ()则是激活函数。
我们可以很轻松的理解(1)式中的 D ~ − 1 2 A ~ D ~ − 1 2 \tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}} D~−21A~D~−21部分。其实就是一个归一化的过程,为了防止度过大或者过小的节点造成太大的影响,导致梯度消失或者爆炸,影响训练效果。具体为什么可以归一化,不需要深究太多,涉及线性代数的知识。
所以,这个函数是符合我们认知与直觉的,并没有特别晦涩的内容。
3:Experiments
- 在与其他方法的比较上,GCN取得了SOTA的性能。
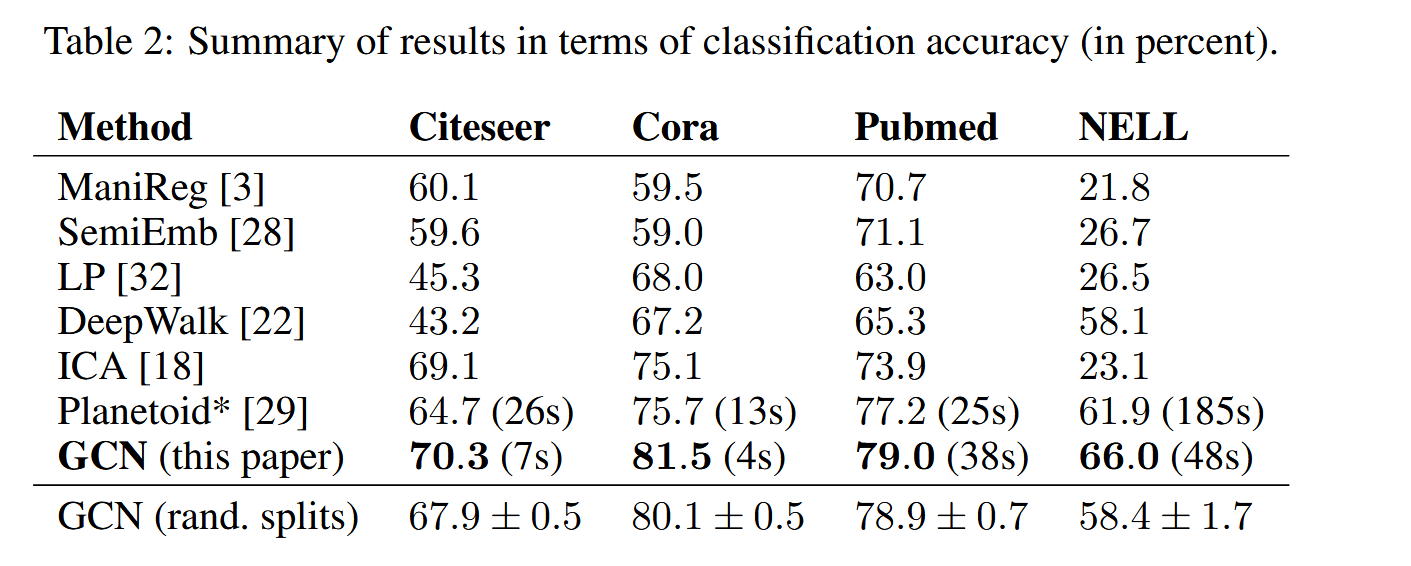
- 当然,作者也对式(1)中的传播方程进行了消融实验,验证其最优性。结果如下:

可以看到,作者选择的传播方程确实达到了最优的性能。
- 作者也给出了训练的时间消耗。
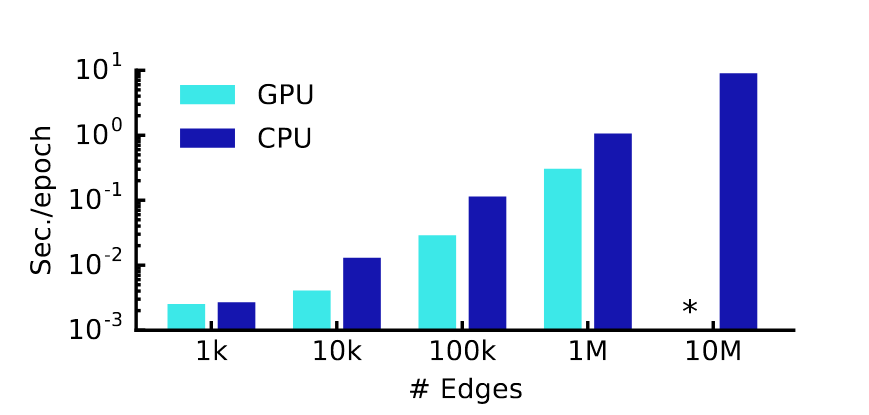
我们可以看到,在边个数为10M时,GPU就超出了训练时间限制。大家可能会好奇,为什么GPU训练的分明比CPU更快,但是在10M的时候GPU的柱状图就消失了。其实作者也给出来了原因,是Out-of-Memory error!
3.1 Limitations
- 上面已经进行了一些引入了。作者在最后的实验中也给出了相关的数据,在边的数量到达10M时,GPU训练的模型就超出了内存限制。这是因为,作者在训练一个网络的时候,使用的是full-batch,一次性读取了所有的节点进图中。有人可能会问了,为什么不分多个batch呢。作者也提出了这个想法,但是,你想,如果一个节点的度很大的话,我们在训练的时候还是需要将其相邻的节点都读入的,这是不可避免地。所以,作者也认为这是未来优化的一个方向。
- 作者的原始传播方程中,对某个节点的所有相邻节点的权重设置的都是一样的,这显然不符合我们的认知。所以,如何动态的对不同的节点设置不同的权重,是未来的一个研究方向。
Insights
- 作者将CNN应用于图网络中,提出了一种崭新的方法。但是,后续的研究也指出,GCN的层数没法设置的很深,即使是增加了残差网络的思想,还是没办法训练很深的网络。因为,一旦设置的很深之后,一个节点就会过度的学习离他很远的节点的信息,所有节点的特征会被“Smooth”掉。但是,不设置的很深,又没办法学习到很复杂的特征,所以,这是一种矛盾,也是限制GCN进一步发展的瓶颈。
- 当然,作者这种移花接木的创新形式很有意思。后续的很多重要工作都是这样,例如Transformer,就是将其从原始的翻译任务移植到对话,视觉等领域,产生了很多里程碑式的工作。

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









