







SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS(基于图卷积网络的半监督分类)
预备知识:
【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
从CNN到GCN的联系与区别——GCN从入门到精(fang)通(qi)
摘要
本文提出了一种在图结构数据上进行半监督学习的可扩展方法,这种方法是基于卷积神经网络的高效变体,它直接在图上操作。通过谱图卷积(spectral graph convolutions) 的局部一阶近似,来确定卷积网络结构。 该模型在图边数上线性缩放,并且学习编码局部图结构和节点特征的隐藏层表示。 在引文网络和知识图数据集上的一些实验中,证明了该方法在很大程度上优于相关方法。
1 导言
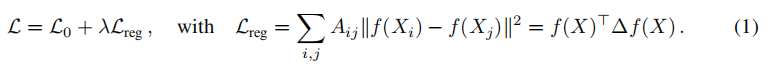
L
0
L_0
L0表示关于图的标记部分的监督损失;
f
(
⋅
)
f(·)
f(⋅)可以是一种类似神经网络的可微函数 ;
X
X
X为节点特征向量
X
i
X_i
Xi的矩阵;
Δ
=
D
−
A
Δ=D-A
Δ=D−A表示无向图
G
=
(
V
,
E
)
G=(V,E)
G=(V,E)的未归一化的图拉普拉斯,其中,N个节点
v
i
∈
V
v_i∈V
vi∈V,边
(
v
i
,
v
j
)
∈
E
(vi,vj)∈E
(vi,vj)∈E,邻接矩阵
A
A
A是N×N维(二进制或加权),度矩阵
D
D
D。
本文直接使用神经网络模型 f ( X , A ) f(X,A) f(X,A)对图结构进行编码,并在监督目标 L 0 L_0 L0上对所有带标签的节点进行训练,从而避免损失函数中基于图的显式正则化。将 f ( ⋅ ) f(·) f(⋅)条件化为图的邻接矩阵,将使模型能够从监督损失 L 0 L_0 L0上分配梯度信息,并使其能够学习有标签和无标签节点的表示。
2 图上的快速近似卷积
在本节中,提供了基于图的神经网络模型 f ( X , A ) f(X,A) f(X,A)的理论动机。
一个多层图卷积网络(GCN),其层间传播规则如下图所示:
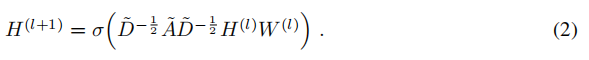
此处:
- A ~ = A + I N \tilde{A}=A+I_N A~=A+IN为无向图G的带自环邻接矩阵
- I N I_N IN为单位矩阵
- D ~ i i = ∑ j A ~ i j \tilde{D}_{ii}=∑_j\tilde{A}_{ij} D~ii=∑jA~ij
- W(l)是特定层的可训练权重矩阵
- σ ( ⋅ ) σ(·) σ(⋅)为激活函数,例: R e L U ReLU ReLU
- H(l)为第 l l l层的激活矩阵;H(0)=X
下文中表明这种传播规则的形式可以通过图上局部频谱滤波器的一阶近似来激励。
2.1 谱图卷积
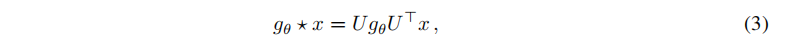
其中,
x
x
x为图节点的特征向量;
g
θ
=
d
i
a
g
(
θ
)
g_θ=diag(θ)
gθ=diag(θ)为卷积核,其中
θ
θ
θ为参数,可以将
g
θ
g_θ
gθ理解为L的特征值Λ的函数;
U
U
U为图的拉普拉斯矩阵
L
L
L的特征向量矩阵,其中拉普拉斯矩阵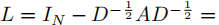
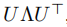 。
。
公式(3)的缺点在于计算太过复杂,卷积核的选取不合适,需要改进。
因此,有人提出了另一种卷积核设计方法,即 g θ ( Λ ) g_θ(Λ) gθ(Λ)可以用切比雪夫多项式 T k ( x ) T_k(x) Tk(x)的截断展开很好地逼近,直到 K t h K_{th} Kth为止。
切比雪夫多项式:
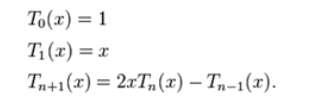
新的卷积核:
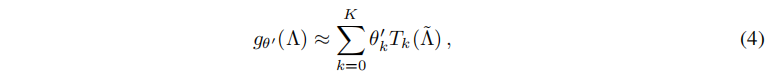
其中,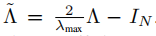 ,
λ
m
a
x
λ_{max}
λmax表示L的最大特征值,θ’∈Rk是切比雪夫系数的向量。
,
λ
m
a
x
λ_{max}
λmax表示L的最大特征值,θ’∈Rk是切比雪夫系数的向量。
基于该卷积核,得到的卷积公式如下:
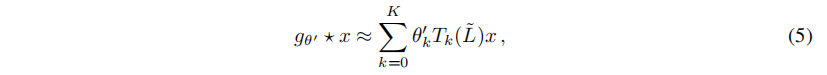
其中,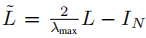 。
。
公式(5)是拉普拉斯算子中的K阶多项式,也就是说,它只取决于距离中心节点(K阶邻域)最大K步的节点。
公式(5)复杂度 O ( ∣ E ∣ ) O(|E|) O(∣E∣),即边数的线性关系,计算复杂性大大降低。
2.2 分层线性模型
可以通过堆叠多个形式为公式(5)的卷积层来建立一个GCN模型。
想象一下,我们将层间卷积运算限制在 K = 1 K=1 K=1(见式5),即函数与L的关系是线性的,因此是图上拉普拉斯谱的线性函数。这样,我们仍然可以通过叠加多个这样的层来恢复一类丰富的卷积滤波函数,但我们并不局限于诸如切比雪夫多项式给出的明确参数化。 我们直观地期望,这样的模型可以缓解局部邻域结构上的过拟合问题,适用于具有非常宽的节点度分布的图,如社交网络、引用网络、知识图和许多其他现实世界的图数据集。此外,对于一个固定的计算预算,这种层间线性公式允许我们建立更深层次的模型,这种做法被认为可以提高一些领域的建模能力。
在GCN的这种线性公式中,我们进一步近似于
λ
m
a
x
λ_{max}
λmax≈2,因为我们可以预测到神经网络参数将在训练过程中适应这种规模的变化。此时公式(5)将简化为下式:
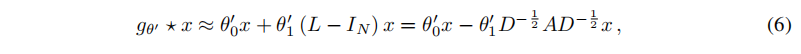
此公式具有两个自由参数:
θ
0
θ_0
θ0、
θ
1
θ_1
θ1,滤波器参数将被整个图共享。连续应用这种形式的滤波器,可以有效地卷积节点的K阶邻域,其中k是模型中连续滤波操作或卷积层的数目。
在实践中,为了解决过拟合问题和尽量减少每层的操作次数(如矩阵乘法),进一步约束参数的数量可能是有益的。这得到如下表达:
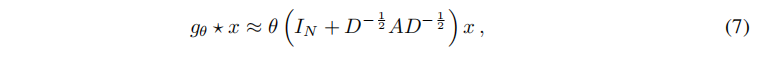
令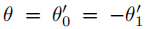 ,注意
,注意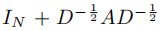 在[0,2]范围内有特征值,在深度神经网络模型中使用该算子的重复应用会导致数值不稳定性和爆炸or消失梯度。 因此介绍下面的归一化技巧:
在[0,2]范围内有特征值,在深度神经网络模型中使用该算子的重复应用会导致数值不稳定性和爆炸or消失梯度。 因此介绍下面的归一化技巧:
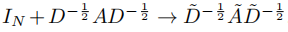
其中,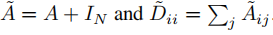 。
。
我们可以将这个定义推广到具有C个输入通道(即每个节点的C维特征向量)的信号X∈RN×C和F个滤波器,feature maps具体如下:
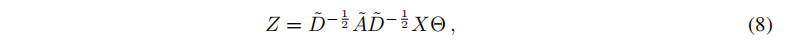
其中,
θ
θ
θ∈RC×F是滤波器参数矩阵,
Z
Z
Z∈RN×F是卷积信号矩阵。
3 半监督节点分类
在引入了模型 f ( X , A ) f(X,A) f(X,A)在图上进行高效的信息传播后,我们可以回到半监督节点分类的问题上。
我们可以通过调整我们的模型 f ( X , A ) f(X,A) f(X,A),来放松通常在半监督学习中所做的假设。希望模型可以在【邻接矩阵 A A A中包含着(数据 X X X没有表达出来的)信息】这种情况下更有用。
一个整体的多层半监督GCN模型如下图所示:
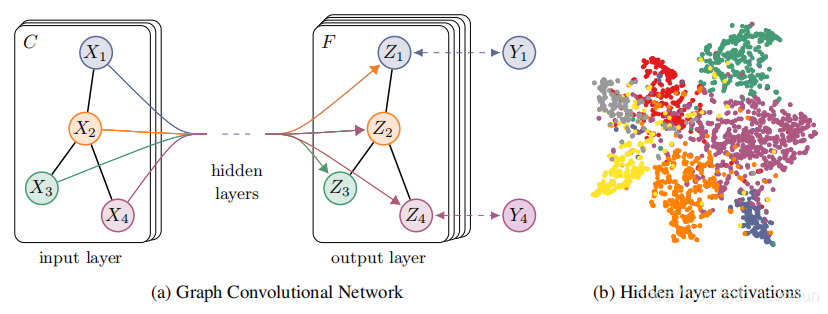
左(a)为用于半监督学习的多层图卷积网络(GCN)的示意图,输入层有
C
C
C个输入,中间有若干隐藏层,输出层有
F
F
F个feature map;图的结构(边用黑线表示)在层之间共享;标签用
Y
i
Y_i
Yi表示。
右(b):一个两层GCN在Cora数据集上(使用了5%的标签)训练得到的隐藏层激活值的形象化表示(通过t-SNE,一种非监督非线性降维),颜色表示文档类别。
3.1 例子
下面,我们考虑在具有对称邻接矩阵A(二进制或加权)的图上进行半监督节点分类的两层GCN。
预处理操作:
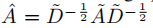
这使得我们的正向模型更加简洁:
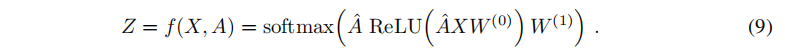
- W(0)∈RC×H为输入层-到-隐藏层的权重矩阵,该隐藏层具有 H H H个特征映射
- W(1)∈RH×F为隐藏层-到-输出层的权重矩阵
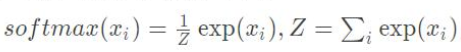 ,作用在每一行上
,作用在每一行上
接下来,对于半监督多类别分类,我们评估所有标记标签的交叉熵误差:
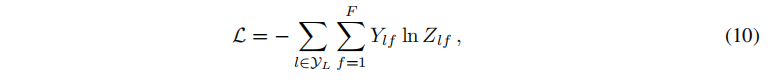
其中,
y
L
y_L
yL为具有标签的节点索引集。
利用梯度下降训练神经网络权值W(0)和W(1)。我们在每次训练迭代中使用完整的数据集来执行批处理梯度下降,这是一个可行的选项,只要数据集适合内存。对于A使用稀疏表示,即边数是线性的。【?】通过dropout引入训练过程中的随机性。我们将内存效率扩展与小批随机梯度下降留作以后的工作。
3.2 实现
利用TensorFlow,基于GPU的【稀疏-密集矩阵乘法】高效实现公式(9)。
4 相关工作
4.1 基于图的半监督学习
近年来,人们提出了大量使用图表示的半监督学习方法,其中大多数分为两大类:使用某种形式的显式图拉普拉斯正则化的方法和基于图嵌入的方法。图拉普拉斯正则化的著名例子包括 label propagation, manifold regularization和深度半监督嵌入。
最近,人们的注意力转移到了用skip-gram model启发的方法学习图嵌入的模型上。 DeepWalk等人通过预测节点的局部邻域来学习嵌入,从图上的随机游走中采样。有人用更复杂的随机游走或广度优先搜索方案扩展了DeepWalk的方法。 然而,对于所有这些方法,需要一个包括随机行走生成和半监督训练的多步骤管道,其中每一步都必须单独优化。有人通过在学习嵌入的过程中注入标签信息来缓解这一问题。
4.2 图上的神经网络
之前图上的神经网络作为循环神经网络的一种形式被介绍。前者的框架需要重复应用收缩映射作为传播函数,直到节点表示达到稳定的定点。后来在原有的图神经网络框架中引入了现代循环神经网络训练的实践,缓解了这一限制。 Duvenaud介绍了一种类似卷积的图上传播规则和图级分类的方法。他们的方法需要学习节点度数特定的权重矩阵,而这种方法无法扩展到具有宽节点【?】度分布的大型图中。 而我们的模型则是每层使用一个单一的权重矩阵,并通过适当的邻接矩阵的归一化来处理不同的节点度。
最近介绍了一种基于图的神经网络的节点分类的相关方法。它们报告了O(N2)的复杂性,限制了可能的应用范围。在另一个不同而又相关的模型中,Niepert将图形局部转换为序列,并将其输入到传统的1D卷积神经网络中,这需要在预处理步骤中定义一个节点排序。
我们的方法基于谱图卷积神经网络,由Bruna等人(2014)中引入,后来由Defferrard等人(2016)用快速局部卷积扩展。与这些工作相比,我们在这里考虑了在规模显著更大的网络中进行传感器节点(transductive node)分类的任务。我们表明,在这种情况下,可以对Bruna等人(2014)和Defferrard等人(2016)的原始框架引入一些简化(见2.2节),以提高大规模网络的可扩展性和分类性能。
5 实验
- 引用网络中的半监督文档分类
- 从知识图中提取的二分图中的半监督实体分类
- 各种图传播模型的评价
- 随机图的运行时分析
5.1 数据集

在引用网络数据集——Citeseer, Cora和Pubmed中,节点是文献,边代表了文献间的引用关系。Label rate表示用于训练的标记节点数除以每个数据集中的节点总数。
NELL是从具有55,864个关系节点和9,891个实体节点的知识图中提取的二分图数据集。
引用网络(Citation networks):
Citeseer, Cora和Pubmed这3个数据集包含每个文档的稀疏词袋特征向量和文档之间的引用链接列表。我们将引用链接视为(无向)边,并构造一个二元对称邻接矩阵A。每个文档都有一个类标签。训练时,我们每个类只用20个标签,但全部都是特征向量。
NELL:
NELL是从引入的知识图中提取的数据集。知识图是一组用有方向、有标签的边(关系)连接的实体。 我们为每个实体对(e1,r,e2)分别分配关系节点r1和r2,作为(e1,r1)和(e2,r2)。实体节点用稀疏特征向量描述。我们通过为每个关系节点分配一个唯一的one-hot表示来扩展NELL中的特征数量,有效地实现了每个节点具有61,278维的稀疏特征向量。这里的半监督任务考虑了训练集中每个类只有一个标记示例的极端情况。如果节点
i
i
i和
j
j
j之间存在一个或多个边,我们通过设置
A
i
j
=
1
A_{ij}=1
Aij=1从该图中构造一个二进制对称邻接矩阵。
Random graphs:
我们模拟各种大小的随机图数据集,用于测量每个epoch的训练时间。对于具有
N
N
N个节点的数据集,我们创建一个随机图,均匀地随机分配
2
N
2N
2N条边。我们将单位矩阵
I
N
I_N
IN作为输入特征矩阵
X
X
X,从而隐式地采用一种无特征的方法,其中模型只被告知每个节点的标识,由唯一的一个one-hot向量指定。
参考论文:
【GCN】论文笔记:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
对于SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS的理解
《SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS》论文阅读(一)

















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









