







一、多分类问题的基础知识
前面我们提到了多输入问题,二分类问题,都是基于以下这种流程图来展示的:
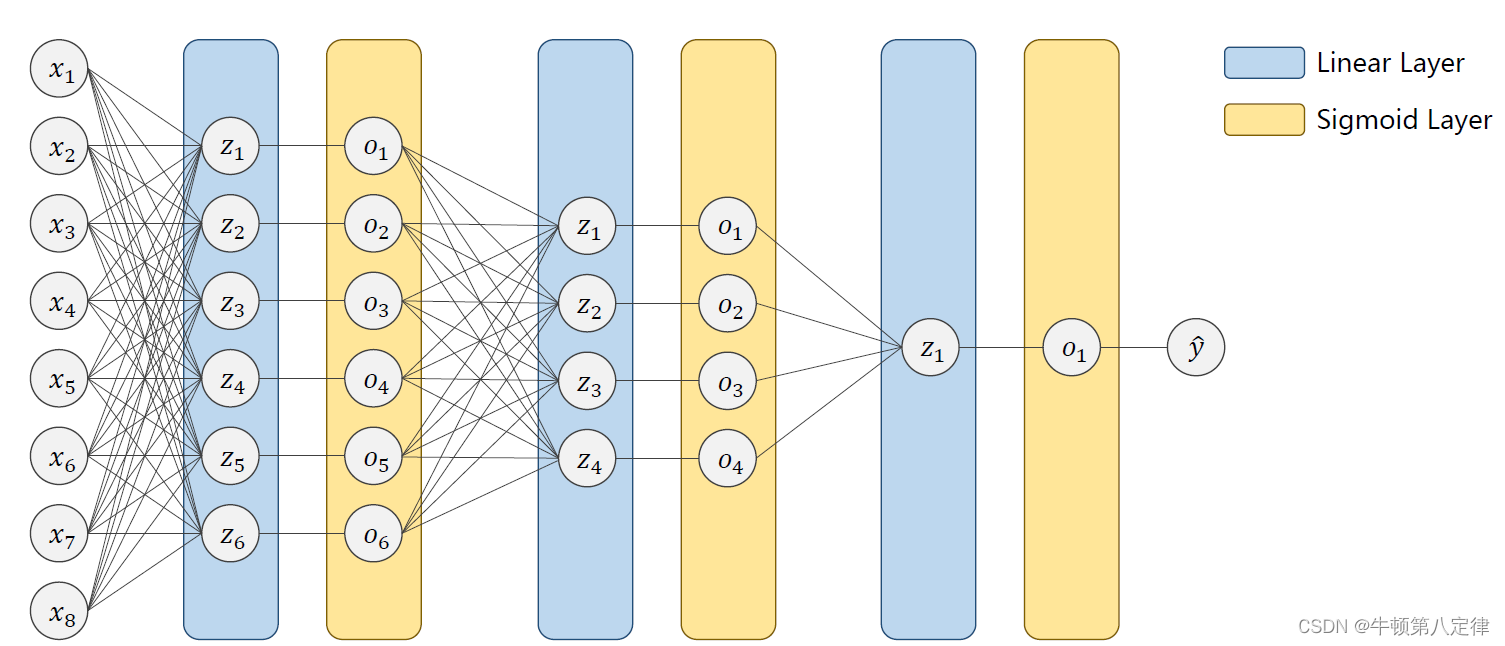
但在现实生活中,有较多的场景它的输出也是多输出的,比如我写一个数字,让模型来猜测这个数字到底是哪一个,此时,模型就有十种可能的输出(0~9)。
这里需要提到一个数据集MNIST,以下是GPT的解析:
MNIST(Modified National Institute of Standards and Technology)数据集是一个广泛使用的手写数字图像数据集,常用于机器学习和计算机视觉的实验和基准测试。以下是关于 MNIST 数据集的一些特点:
-
图像内容:MNIST 数据集包含了大量的手写数字图像,涵盖了数字 0 到 9。每张图像都是灰度图,尺寸为 28x28 像素。
-
标签信息:每个图像都有对应的标签,标识了图像所代表的数字。标签范围从 0 到 9。
-
训练集和测试集:MNIST 数据集被划分为两个部分:训练集和测试集。训练集包含 60,000 张图像,用于模型的训练和参数优化。测试集包含 10,000 张图像,用于评估模型的性能和泛化能力。
-
简单与标准化:MNIST 数据集是一个相对简单和标准化的数据集,图像均为黑白灰度,数字样本清晰可辨,没有太多噪声或变异。
-
广泛应用:由于其简单性和标准化特征,MNIST 数据集成为许多机器学习模型的基准测试之一。它经常用于验证模型的有效性、比较不同算法的性能,并作为教学和研究的示例数据集。
-
相对有限:与现实世界的复杂图像数据相比,MNIST 数据集的规模相对较小。这使得训练和评估过程更加高效,但也需要注意模型在更大、更复杂数据集上的性能。
总体而言,MNIST 数据集是一个常用的手写数字图像数据集,具有简单和标准化的特点,常用于机器学习领域的图像分类和识别任务。
在给定输入后,经过多层中间线性层和激活层,最终输出,便会有十个输出预测数据。
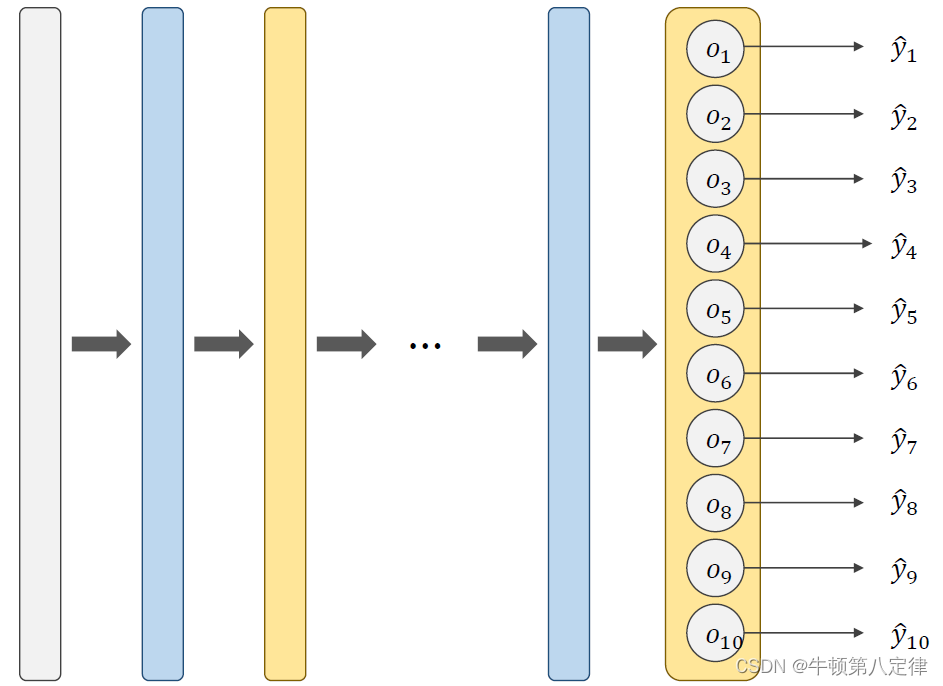
例如:是1的预测值是0.7,是2的预测值是0.6,...,是9的预测值是0.75。
显然这样的结果会让人觉得感觉会有比较大的概率会是1,2,9,毕竟它们的概率都相对较高,所以我们更希望输出预测值之间是具有竞争性的,何为竞争性?就是我大,你们都得小。不会出现都大的情况。当然,输出之间具有竞争性,需要满足以下两个条件:
(1)它们各自的概率都得 ≥ 0;
(2)它们的概率之和加起来 = 1.
为此,我们需要在输出预测数据之前,再加入一个变换层,专业术语叫做Softmax层,它是输出前的最后一个线性层,以下是Softmax函数:
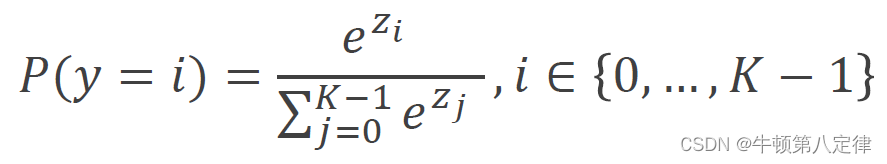
展开看就是:
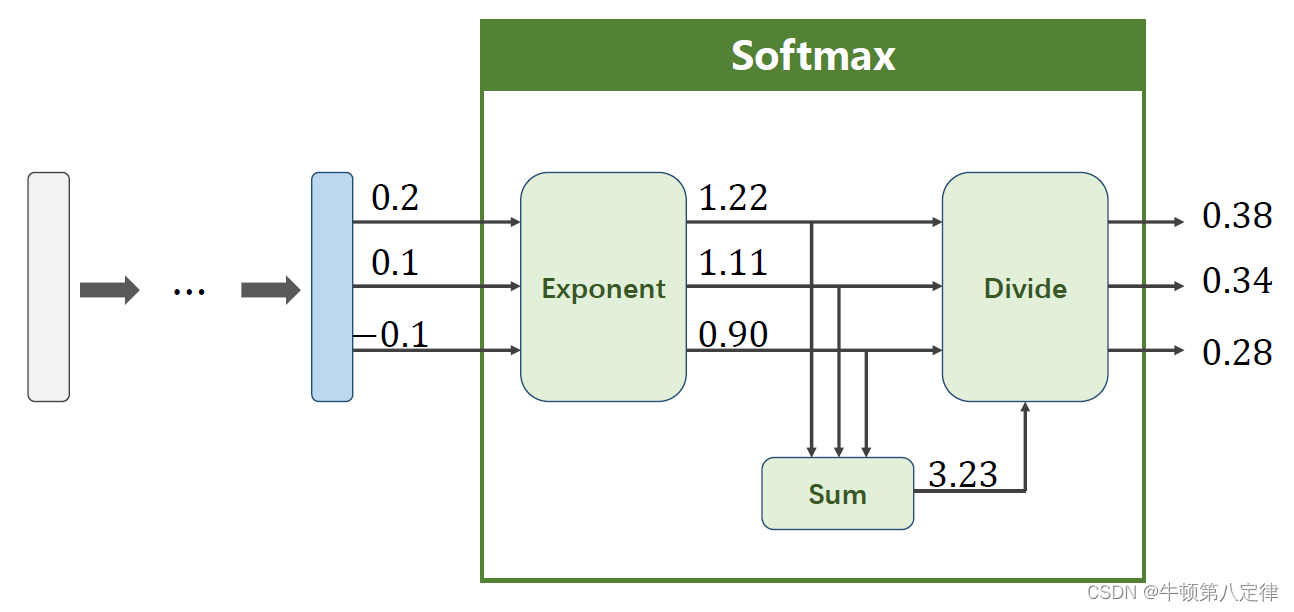
上图给了一个小例子,我们假设输出模拟的是数字1,数字2,数字3分别的概率,相当于模型给出了它觉得这输入是(1,2,3)的概率分别是0.38,0.34,0.28,显然模型认为是第一个输出更为准确,那么如何计算这些预测输出的损失值呢?
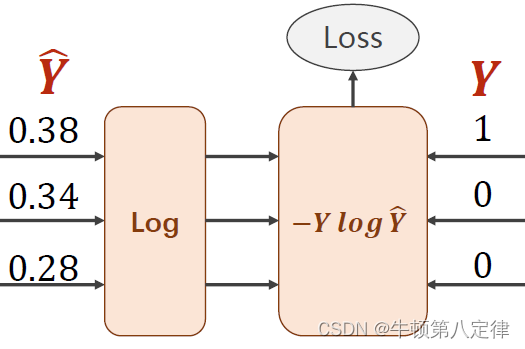
如果我们知道实际的标签值label,而label告诉我们答案确实这个输入是1,那么我们就可以把实际的label值设置为(1,0,0),这里的1表示True,0表示False,相当于就是(数字1,数字2,数字3)=(True,False,False)。
损失函数公式选取为如下:
![]()
至此,我们的模型构建就基本上补充完成了。
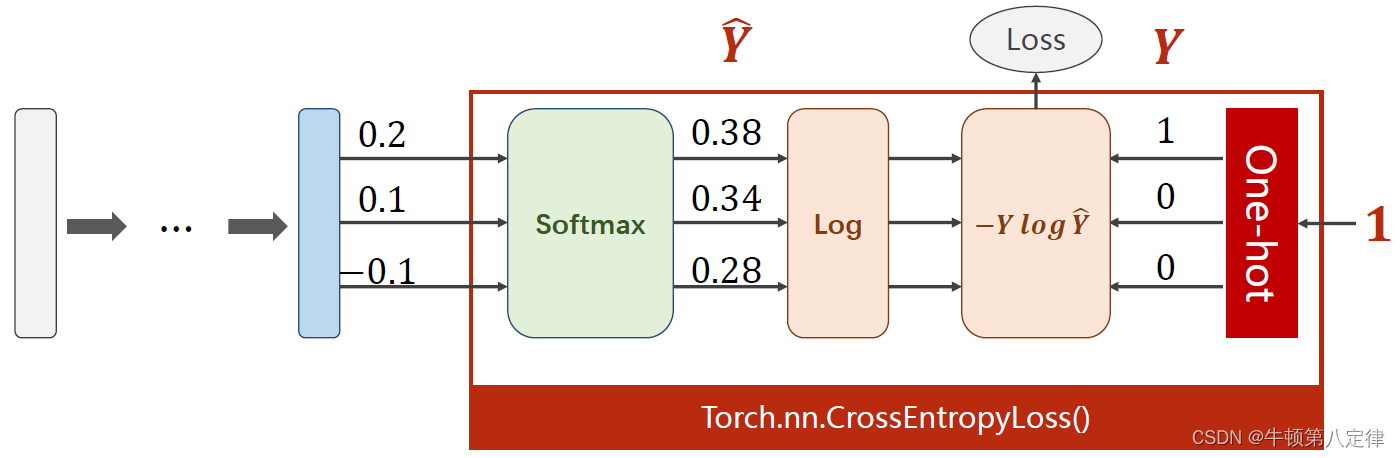
这里选取的torch.nn.CrossEntropyLoss()指的是交叉熵损失模型。
在这里,我们可以事先模拟一下 y_pred 和 y 之间的Loss计算:

见上图,我们可以知道,y 的实际标签值是(2,0,1),表示的意思是实际的y应该是(数字2,数字0,数字1),接下来我们来看模型给出的预测值,先看第一行tensor = (0.1,0.2,0.9),在还没有进行Softmax变换之前,我们其实能看出来它的意思是“第一个输入进来的数字,它认为是0的广义概率是0.1,是1的广义概率是0.2,是2的广义概率是0.9”。
再看第二行tensor = (1.1,0.1,0.2),同理,它认为是数字0的广义概率是1.1,1的广义概率是0.1,2的广义概率是0.2,第三行同理不再叙述,所以可以看出 y_pred1 对样本的预测还是比较准确的,在通过CELoss损失模型之后,它的Loss应该会比较的低。
反观 y_pred2 ,按照刚才的逻辑理解,可以得出它的Loss会比较高。
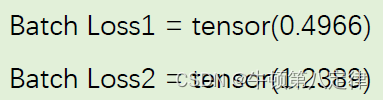
二、代码实现
0、导包
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim(1)transforms:torchvision.transforms 模块提供了一系列图像预处理函数,可以用于数据加载、增强和转换,例如调整大小、裁剪、旋转等。 (2)datasets:torchvision.datasets 模块包含了常用的计算机视觉数据集,如MNIST、CIFAR10等,可以方便地从这些数据集中加载和预处理数据。 (3)DataLoader:torch.utils.data.DataLoader类 是PyTorch中用于数据加载和批量处理的工具类,可以将数据集加载到内存并按照指定的batch_size分成小批次供模型使用。 (4)F:torch.nn.functional 模块包含了各种神经网络的函数和操作,例如激活函数、损失函数等。通过F可以调用这些函数来构建神经网络模型。 (5)optim:torch.optim 模块提供了优化算法的实现,用于更新模型的参数以最小化损失函数,例如随机梯度下降(SGD)、Adam等。
1、创建数据预处理对象,数据集和DataLoader
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
1、这段代码通过transforms.Compose()方法定义了一个数据预处理的变量transform,用于将图像数据转换为张量并进行标准化操作。 2、transforms.ToTensor():将图像数据转换为张量形式。它会将取值范围为[0, 255]的图像像素值除以255,并将其转换为浮点型张量,取值范围变为[0.0, 1.0]。 3、transforms.Normalize((0.1307,), (0.3081,)):对张量进行标准化操作,使得每个通道的均值为0.1307,标准差为0.3081。这里的参数是由于在MNIST数据集上进行了统计计算得到的。 4、定义完属性后,通过transforms.Compose()函数,将多个数据预处理操作组合成一个预处理管道,按顺序依次进行处理。 对于一个输入的图像数据,经过以上定义的transform操作后,会依次进行如下操作: (1)将图像转换为张量; (2)对张量进行标准化。 这样,最终得到的数据就是经过预处理的张量形式,可以用于输入到模型中进行训练或推理。
关于图像数据的预处理,还有以下几个细节需要知道:

我们的图像是宽28高28,像素0~255的,经过transform预处理后,会被处理为可以识别的Pytorch张量形式,而且会被处理为(通道数1,宽28,高28),像素为float(0~1),但是在神经网络输入层,通过DataLoader加载进内存的批量输入的张量数据,其实是四维张量(N,1,28,28),这里的N是批处理样本的总量。当然,我们会把这个四维张量再进行一次维度变换,具体实现见后续说明。
定义完预处理管道transform后,开始创建数据集和DataLoader。
batch_size = 64
# 通过datasets.MNIST()函数,写入MNIST数据集的资源路径,设置为训练集
# 如果已经下载了MNIST,download写为False,反之写True
# 预处理对象就使用刚才定义好的transform数据预处理管道
train_dataset = datasets.MNIST(root="dataset/mnist",
train=True,
download=False,
transform=transform)
# 创建DataLoader对象,从train_dataset里面加载数据,打乱顺序
# 批量样本容量为64
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
# 此处是测试集数据集,所以train要改为False,其余没变化
test_dataset = datasets.MNIST(root="dataset/mnist",
train=False,
download=False,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)2、创建模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
# 由于输入特征维度是784,所以第一个参数填784
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# 这里将输入进来的四维张量(N,1,28,28)变更为二维张量(N,784)
# 其实是把每一个样本宽28高28的样本特征给铺平为一个行向量了
# N表示样本总数,即第一行:是第一个样本的特征,有784个,以此类推
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 【注意】最后一个线性层输出后,不需要激活
y_pred = self.l5(x)
return y_pred
model = Model()问题:为什么要把(N,1,28,28)的四维张量,通过view(-1,784)变更为一个二维张量?
1、在神经网络中,全连接层的输入是一个二维张量,其形状通常是
(batch_size, input_size),其中batch_size表示输入的样本数量,input_size表示每个样本的特征维度。2、在处理图像数据时,我们通常将图像展平为一维向量,然后作为全连接层的输入。因此,在预处理后的四维张量
(N, 1, 28, 28)中,我们需要使用view方法将其转换为二维张量(N, 784)。view(-1, 784)中的-1参数表示根据其他维度的大小自动推断出该维度的大小。这样,可以根据实际的输入样本数量N来自动计算出合适的第一维度大小。3、通过对预处理后的四维输入张量进行
view(-1, 784)操作,我们将每个样本的(1, 28, 28)的像素值展平为了长度为 784 的一维向量,以便能够作为全连接层的输入。4、这种处理方式允许神经网络对每个像素进行独立的处理,并从中学习到更高级的特征表示,以完成特定的任务(如图像分类)。
3、创建损失函数模型与优化器
CELoss = torch.nn.CrossEntropyLoss()
SGD_optim = optim.SGD(model.parameters(), lr=0.03, momentum=0.7)对于momentum冲量参数的解释:
1、参数
momentum是随机梯度下降(SGD)优化算法中的一个超参数,用于加速优化过程并帮助跳出局部最优解。它引入了前一次更新的动量,使得在更新时具有惯性。选择合适的momentum值通常是一个经验性的过程,可以尝试不同的值来找到最佳结果。2、一般而言,较小的
momentum值(如0.5)可以提供一定的平滑性并帮助跳出局部最优解,而较大的momentum值(如0.9)则可能导致学习率的增加,从而加快优化的速度。3、当遇到训练过程中的振荡或学习速度缓慢时,增加
momentum值可能会有所帮助。然而,如果momentum设置得太高,也可能导致优化过程不稳定或震荡。因此,最佳的momentum值取决于具体的问题和数据集。4、建议使用默认值(0.5)作为起始点,并根据实际问题进行微调。可以通过尝试不同的
momentum值来评估模型的性能,选择在验证集上表现最好的值。
4、训练环节
def train(epoch):
running_loss = 0.0
# enumerate(x, y)返回值是(index, tensor(), tensor())
# batch_index 接收 index
# data 接收属于输入的tensor和实际目标的tensor
for batch_index, data in enumerate(train_loader, 1):
train_inputs, train_label = data
SGD_optim.zero_grad()
train_outputs = model(train_inputs)
loss = CELoss(train_outputs, train_label)
loss.backward()
SGD_optim.step()
running_loss += loss.item()
if batch_index % 300 == 0:
print(f"第{epoch + 1}轮训练,批次{batch_index}, 平均损失值Loss = {running_loss / 100 } ")
running_loss = 0.05、测试环节
def test():
test_correct_number = 0
test_label_number = 0
# with torch.no_grad():这是一个上下文管理器,用于禁用梯度计算,以减少内存消耗和加速计算。在测试过程中,我们无需计算梯度。
with torch.no_grad():
for data in test_loader:
test_inputs, test_label = data
test_outputs = model(test_inputs)
# test_outputs里面的每一行记录的是对这十个样本(0~9)预测的概率分布,我们不关心概率是多少,只关心最大概率出现的索引下标是多少
# _, predict_index = torch.max(outputs.data, dim=1):用于找到张量outputs.data每行中的最大值及最大值对应的索引
# 此处抛弃了最大概率是多少这个数据,只保留了出现最大概率的索引值
# dim=1表示沿着第1维度(其实就是行维度)去找最大值的索引下标
_, predict_index = torch.max(test_outputs.data, dim=1)
# test_label_number += test_labels.size(0):累加当前批次中样本的数量到test_label_number变量中,用于统计测试集样本的总数。
# 根据前面设置的批处理数量是64,那么这里的测试单批次总量也应该是64
# += 表示测试完一批数据就加64,一直加下去,直到停止,最后作为准确度计算的分母
test_label_number += test_label.size(0)
# correct_num += (predicted_index == labels).sum().item():统计当前批次中预测正确的样本数。
# predicted_index == labels 会生成一个布尔型张量标记哪些样本被正确预测。
# (predicted_index == labels).sum().item()会计算预测正确的样本数量,并将其加到test_correct_number变量中。
# sum计算布尔张量,在布尔张量中true就是1,false就是0,因此所有的true加起来(即很多1加起来)就是猜对的总数
test_correct_number += (predict_index == test_label).sum().item()
print(f"测试集中的准确度:{test_correct_number / test_label_number * 100 :.3f} %")6、开始训练+测试
if __name__ == '__main__':
# 一共完成10轮运算
# 每一轮运算包含:训练一轮,测试一轮
# 可以通过测试准确度看到模型训练的成果是否在逐渐提高
for epoch in range(10):
train(epoch)
test()7、数据结论记录
第1轮训练,批次300, 平均损失值Loss = 3.0226465751230718
第1轮训练,批次600, 平均损失值Loss = 0.7251205147802829
第1轮训练,批次900, 平均损失值Loss = 0.47879536816850304
测试集中的准确度:95.500 %
第2轮训练,批次300, 平均损失值Loss = 0.356071755848825
第2轮训练,批次600, 平均损失值Loss = 0.3027562460117042
第2轮训练,批次900, 平均损失值Loss = 0.2895173557382077
测试集中的准确度:97.280 %
第3轮训练,批次300, 平均损失值Loss = 0.2054564890009351
第3轮训练,批次600, 平均损失值Loss = 0.20665094554424285
第3轮训练,批次900, 平均损失值Loss = 0.20372300767572596
测试集中的准确度:97.700 %
第4轮训练,批次300, 平均损失值Loss = 0.12797174502979033
第4轮训练,批次600, 平均损失值Loss = 0.1419861066993326
第4轮训练,批次900, 平均损失值Loss = 0.14839778115740046
测试集中的准确度:97.730 %
第5轮训练,批次300, 平均损失值Loss = 0.11033611462102272
第5轮训练,批次600, 平均损失值Loss = 0.09992307906912173
第5轮训练,批次900, 平均损失值Loss = 0.09007804239459802
测试集中的准确度:97.690 %
第6轮训练,批次300, 平均损失值Loss = 0.06334008003032068
第6轮训练,批次600, 平均损失值Loss = 0.07630506619403604
第6轮训练,批次900, 平均损失值Loss = 0.07176257771003293
测试集中的准确度:97.770 %
第7轮训练,批次300, 平均损失值Loss = 0.040907738982932644
第7轮训练,批次600, 平均损失值Loss = 0.06570716403599362
第7轮训练,批次900, 平均损失值Loss = 0.06026086087047588
测试集中的准确度:97.780 %
第8轮训练,批次300, 平均损失值Loss = 0.04238070914303535
第8轮训练,批次600, 平均损失值Loss = 0.04749378668129793
第8轮训练,批次900, 平均损失值Loss = 0.046455078224971656
测试集中的准确度:97.890 %
第9轮训练,批次300, 平均损失值Loss = 0.03108949002053123
第9轮训练,批次600, 平均损失值Loss = 0.04065773483838711
第9轮训练,批次900, 平均损失值Loss = 0.03811355385361821
测试集中的准确度:98.090 %
第10轮训练,批次300, 平均损失值Loss = 0.025494235943551758
第10轮训练,批次600, 平均损失值Loss = 0.03636479816655992
第10轮训练,批次900, 平均损失值Loss = 0.04561891401463072
测试集中的准确度:97.930 %
*8、准确度突破不了的大体原因
测试准确度不能继续提高或突破一定水平可能有以下几个原因:
-
模型复杂度不足:模型的表达能力限制了其对复杂数据分布的拟合能力。这种情况下,可以尝试增加模型的容量,例如增加隐藏层的数量或神经元的个数,以提高模型的表达能力。
-
数据集问题:测试准确度受限于训练数据的质量和多样性。如果训练集中存在标注错误、样本不平衡或噪声等问题,模型可能无法准确地学习到数据的真实分布。在这种情况下,可以考虑优化数据集,例如进行数据清洗、增强或添加新的泛化能力。
-
梯度消失或梯度爆炸:当使用一些深层网络结构时,梯度消失或梯度爆炸的问题可能会导致模型无法收敛或过早饱和。可以通过改变激活函数、调整权重初始化方法、使用批归一化等技术来缓解这些问题。
-
学习率设置不当:学习率过大可能导致模型发散,学习率过小可能导致模型收敛缓慢或陷入局部最优。可以尝试调整学习率,使用学习率衰减策略或更高级的优化算法来改进模型收敛速度和性能。
-
过拟合:当模型在训练集上的表现很好,但在测试集上表现不佳时,可能是由于过拟合造成的。过拟合指模型过度拟合了训练集中的噪声和细节,导致对新样本的泛化能力较差。可以尝试使用正则化技术(如L1、L2正则化)、增加数据集的多样性、提前停止训练或使用更复杂的模型结构来减少过拟合。
改进测试准确度的方法包括:
-
调整模型架构:增加模型的深度、宽度或添加更多的隐藏层,以增加模型的表达能力。
-
数据增强:通过应用旋转、缩放、平移、翻转等变换来扩充训练集,以增加数据的多样性。
-
正则化:使用L1、L2正则化等方法来减小模型的复杂度,防止过拟合。
-
优化算法:尝试使用其他优化算法,如Adam、Adagrad等,或者使用学习率衰减策略来改进模型的收敛性能。
-
集成学习:通过结合多个模型的预测结果,使用投票、平均等方式进行集成,以提高模型的泛化能力和准确度。
-
超参数调优:通过网格搜索、随机搜索等方法来寻找最佳的超参数组合,如学习率、批大小等。
-
更大的数据集:尝试获得更大规模的训练数据集,以提高模型的泛化能力。
-
提前停止训练:当测试集上的准确度不再提升或开始下降时,可以提前停止训练,避免过拟合。















 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









