







目录
1、更新了Residual Block,引入了SE注意力机制
一、MobileNet v3的改进之处与创新点
1、更新了Residual Block,引入了SE注意力机制
在MobileNet v2网络中,我们使用的Block叫“Residual BottleNeck Block”,模型如下:
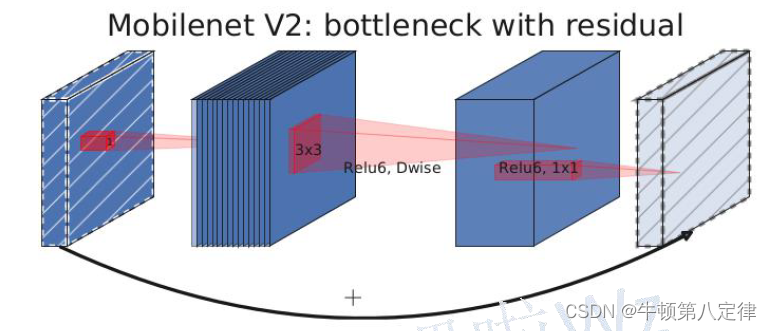
而在MobileNet v3网络中,更新了Block的结构,在DW卷积中间添加了一个注意力机制SE模块(Squeeze-and-Excitation),模型如下:
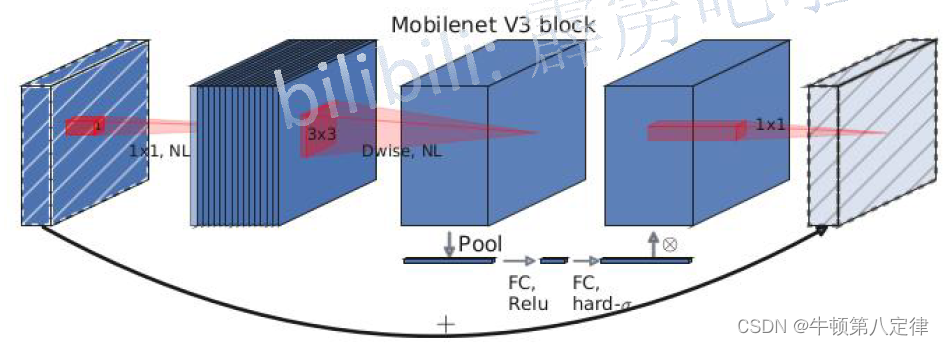
对比两个Block,我们可以发现如下变更:
(1)PW升维到DW处理,DW处理到SE模块之间使用了NL(非线性激活函数)的操作,但是暂未指定是何种非线性激活函数;
(2)中间增添了一个叫注意力机制的模块(SE:Squeeze-and-Excitation),
压缩与激励(SE),即:注意力机制。
名字的由来是因为它模拟了人类在处理信息时的注意力分配方式。
1、实践背景:人类的视觉系统在感知和理解环境中起着重要的作用。当我们观察一个场景或对象时,我们会自动地将注意力集中在最相关和有意义的部分上,而忽略其他不重要的细节。这种注意力分配的方式使得我们能够更加有效地处理信息,提取关键特征,并做出准确的决策。
2、理论背景:压缩与激励(SE)注意力机制模仿了这种注意力分配的过程。它通过学习每个通道的重要性分数,让模型自适应地决定每个通道在特征表示中的贡献程度。这些重要性分数反映了哪些通道对于当前任务或问题最具有相关性和重要性。通过使用这些分数来调整通道的激活值,模型能够更加集中地关注重要的特征并抑制无关的特征,从而提升网络的表征能力和性能。
3、实现:它通过自适应地学习通道之间的权重来提取有用的特征并抑制无关的特征。该机制由两个步骤组成:首先通过全局信息获取每个通道的重要性分数;然后使用这些分数来调整每个通道的激活值。
因此,压缩与激励(SE)被称为注意力机制,是因为它在模型中引入了一种类似于注意力的机制,使得模型能够自动地关注和强调重要的特征,提高模型的表达能力和性能。
以下是关于SE注意力机制的简单解释:
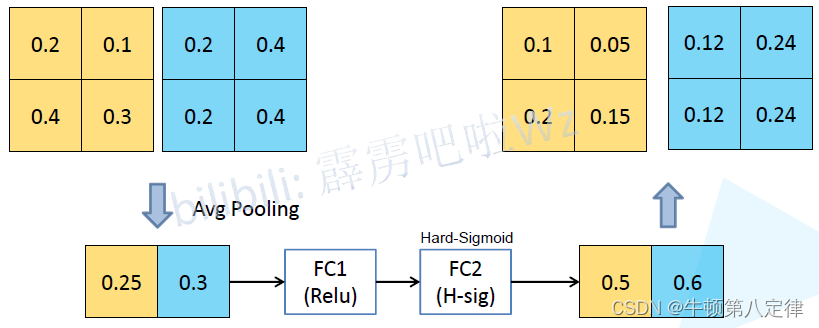
设有两种特征进行SE模块,经过平均池化,带ReLU的全连接层,以及带Hard-Sigmoid全连接层处理后,SE模块给出的分数为0.5和0.6(可以看出SE认为蓝色特征的信息相对而言更为重要),在完成对输入特征的重要性评估后,开始利用分数调整两个特征的信息,相对而言,抑制了黄色的特征,而更多地提取了蓝色特征。
2、重新设计了耗时层结构
这里先解释一下什么是耗时层:特指网络模型中计算复杂度较高、耗费大量时间的层或模块。
耗时层通常是指那些计算量较大的层或模块,它们在网络的前向传播过程中会消耗较多的时间和计算资源。具体而言,常见的耗时层包括深度可分离卷积(如 MobileNet 中使用的层)、卷积层、循环神经网络(如 LSTM、GRU)、注意力机制等。
对于训练任务而言,耗时层意味着更长的训练时间,而对于推理任务而言,耗时层意味着更长的推理时间。因此,在设计和优化深度学习模型时,通常需要考虑如何减少耗时层的数量和计算复杂度,以提高整体的效率和速度。
在MobileNet v3中,采用了以下两种方式减少了对耗时层对资源和时间的浪费:
(1)减少了第一个卷积层的卷积核个数:在v2版本中,第一个卷积层的卷积核个数是32,在v3中减少为16个,经过训练发现:准确率并无太大变化,但是训练耗时减少了2ms;
(2)精简了最后一部分层的结构:
以下是调整之前的最后一部分层的结构:
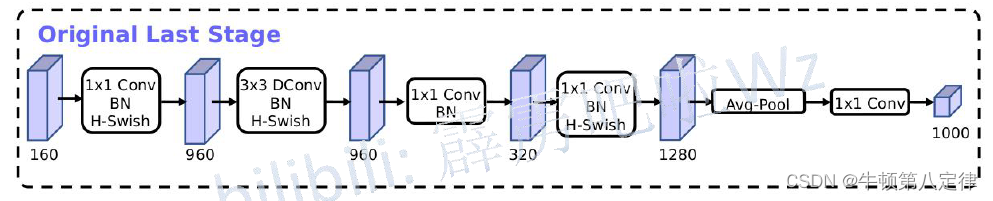
以下是调整过后的结构:
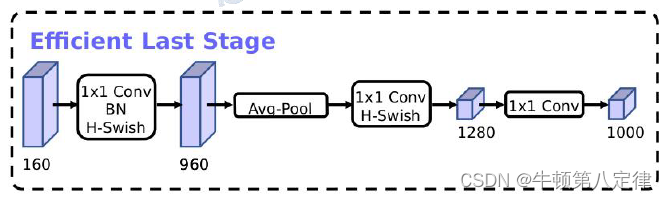
可以发现:v3结构的最后一部分减少了大量的卷积层,根据结论显示,如此调整过后,准确率无太大变化,而训练耗时下降了7ms。
3、重新设计了激活函数
为了提高准确度与精度,v3网络中使用了Swish非线性激活函数来代替ReLu,以下是Swish函数的函数表达式(其实就是x * Sigmoid(x)):
以下是Swish激活函数的函数图像:
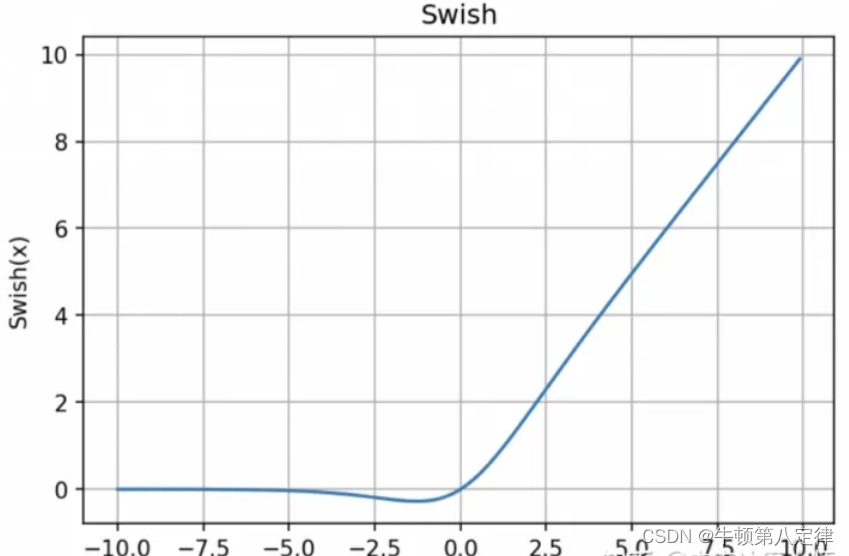
引入了Swish激活函数,虽然可以提高训练精度,但是也带来几个较大的问题:
由于Swish函数带有Sigmoid函数:
(1)计算、求导过程复杂;
(2)对量化过程不友好。
量化过程:指将浮点数格式的模型参数和激活值转换为更低位宽的定点数或整数表示的过程。这样做可以减少存储空间和计算复杂度,并提高模型在硬件设备上的运行效率。
Swish 函数对于量化过程确实具有一定的挑战性。由于 Swish 函数包含了 sigmoid 函数,而 sigmoid 函数在接近端点处的斜率非常小,这可能导致量化后的表示失去精度,并降低量化模型的性能。因此,在量化中,通常会选择其他的激活函数来代替 Swish 函数,以获得更好的量化结果。
(3)在移动设备上,计算资源有限,要计算Sigmoid函数成本开销很高。
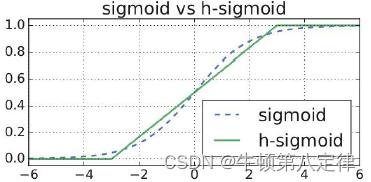
为了解决如上问题,在MobileNet v3中将Swish中的Sigmoid函数更改为如下形式,同时Sigmoid变更为Hard-Sigmoid:
那么整个Swish激活函数的表达式变更为如下形式,同时Swish变更为Hard-Swish:
更改后的Hard-Sigmoid函数图像与原来的Sigmoid图像相似,但是计算和求导过程方便了。
以下是Swish与Hard-Swish图像的比较:
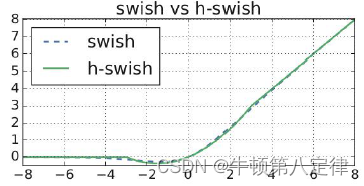
可见,更换后的激活函数图像与原始的激活函数图像大体一致,但在计算效率上却提高了。
二、MobileNet v3 - Large网络特征结构
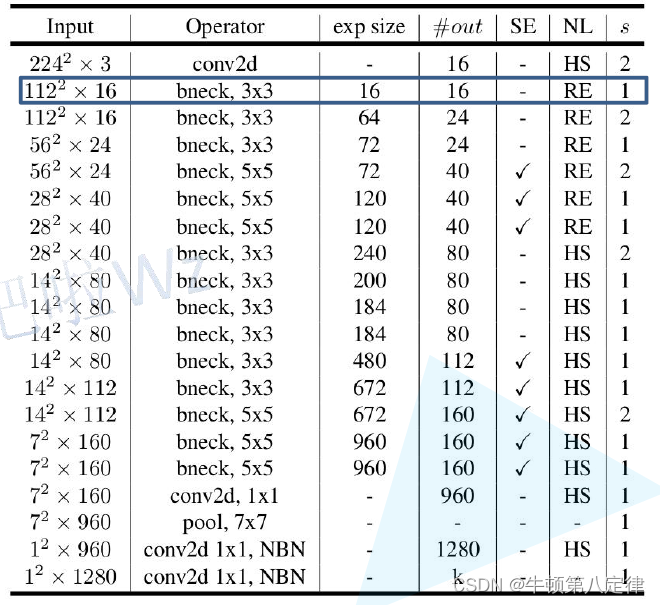
分析过程与MobileNet v2一样,但是要注意shortcut的添加条件,图中框住的部分可以分析出该部分是没有PW升维层的。
1、exp size:PW卷积升维后的通道数,换句话说就是膨胀因子计算后的通道结果
2、#out:该层输出通道数,记得赋给下一层的输入通道数变量
3、SE:表示该层是否需要注意力机制
4、NL:表示该层所使用的非线性激活函数是什么,RE表示ReLU,HS表示H-Swish
5、s:表示步幅stride,仅限第一次循环的第一个DW处理层
6、注意在进行卷积操作的时候要进行padding操作
在MobileNet-v3-Large网络中,所包含的特征层有以下信息:
(1)第一层:输入224*224*3,普通卷积,输出通道数为16,无PW升维扩张因子,核大小为3,步幅为2,用HardSwish激活,不执行SE模块;
(2)第二层:输入112*112*16,倒残差模块卷积,输出通道数为16,PW升维后通道为16,核大小为3*3,步幅为1,用ReLU激活,不执行SE模块,有捷径线;
(3)第三层:输入112*112*16,倒残差模块卷积,输出通道数为24,PW升维后通道为64,核大小3*3,步幅为2,用HardSwish激活,不执行SE模块;
(4)第四层:输入56*56*24,倒残差模块卷积,输出通道数为24,PW升维后通道为72,核大小3*3,步幅为1,用ReLU激活,不执行SE模块;
(5)第五层:输入56*56*24,倒残差模块卷积,输出通道数为40,PW升维后通道为72,核大小5*5,步幅为2,用ReLU激活,执行SE模块;
(6)第六层:输入28*28*40,倒残差模块卷积,输出通道数为40,PW升维后通道为120,核大小5*5,步幅为1,用ReLU激活,执行SE模块,有捷径线;
(7)第七层:输入28*28*40,倒残差模块卷积,输出通道数为40,PW升维后通道为120,核大小5*5,步幅为1,用ReLU激活,执行SE模块,有捷径线;
(8)第八层:输入28*28*40,倒残差模块卷积,输出通道数为80,PW升维后通道为240,核大小3*3,步幅为2,用HardSwish激活,不执行SE模块;
(9)第九层:输入14*14*80,倒残差模块卷积,输出通道数为80,PW升维后通道为200,核大小3*3,步幅为1,用HardSwish激活,不执行SE模块,有捷径线;
(10)第十层:输入14*14*80,倒残差模块卷积,输出通道数为80,PW升维后通道为184,核大小3*3,步幅为1,用HardSwish激活,不执行SE模块,有捷径线;
(11)第十一层:输入14*14*80,倒残差模块卷积,输出通道数为80,PW升维后通道为184,核大小3*3,步幅为1,用HardSwish激活,不执行SE模块,有捷径线;
(12)第十二层:输入14*14*80,倒残差模块卷积,输出通道为112,PW升维后通道为480,核大小3*3,步幅为1,用HardSwish激活,执行SE模块;
(13)第十三层:输入14*14*112,倒残差模块卷积,输出通道为112,PW升维后通道为672,核大小3*3,步幅为1,用HardSwish激活,执行SE模块,有捷径线;
(14)第十四层:输入14*14*112,倒残差模块卷积,输出通道为160,PW升维后通道为672,核大小5*5,步幅为2,用HardSwish激活,执行SE模块;
(15)第十五层:输入7*7*160,倒残差模块卷积,输出通道为160,PW升维后通道为960,核大小5*5,步幅为1,用HardSwish激活,执行SE模块,有捷径线;
(16)第十六层:输入7*7*160,倒残差模块卷积,输出通道为160,PW升维后通道为960,核大小5*5,步幅为1,用HardSwish激活,执行SE模块,有捷径线;
(17)第十七层:输入7*7*160,普通卷积,输出通道为960,用HardSwish激活,步幅为1;
(18)第十八层:输入7*7*960,池化层,核大小7*7;
分类器层
(1)第一层:输入1*1*960,普通卷积,核大小1*1,NBN,输出通道为1280,用HardSwish激活,步幅为1;
(2)第二层:输入1*1*1280,普通卷积,核大小1*1,NBN,输出通道为 k',不进行非线性激活,步幅为1;
三、MobileNet v3 - Small网络特征结构
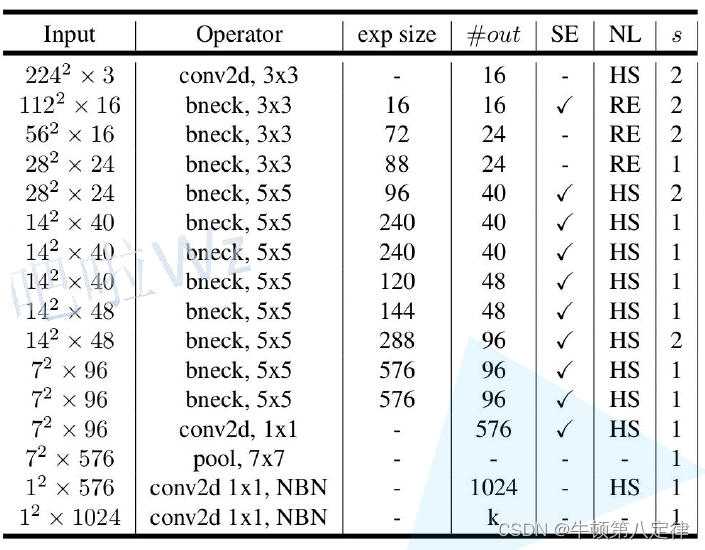
分析方法同Large,这里就不再赘述。
四、MobileNet-v3的模型代码搭建
1、导包
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial2、通道预调整方法
def _make_divisible(channel, divisor=8, min_channel=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
# 如果没有提供最小通道数,就把divisor赋值给最小通道数,默认为8
if min_channel is None:
min_channel = divisor
# 计算调整过后得到的新通道数,最小是8,计算公式:给定通道数 + divisor/2 的和,整除 divisor 再乘 divisor,得到的结果是divisor的倍数
new_channel = max(min_channel, int(channel + divisor / 2) // divisor * divisor)
# 如果调整后的通道数小于初始通道数的90%,则将调整过后的通道数再加一倍的divisor
if new_channel < 0.9 * channel:
new_channel += divisor
# 无论怎么调整通道数,最终返回的调整值都是divisor的倍数
return new_channelmake_divisible函数的构造器参数有:
1、channel:需要调整的通道数
2、divisor=8:除数,设置除数是多少,默认为8
3、min_channel:调整后的最小通道数,作用是防止调整后的通道数低于此值,默认为不设置(None)
返回值:使用本方法后,将会得到经过调整的通道数,且该通道数是8的倍数。
该方法的主要作用就是把通道数调整为8的倍数(一般情况下),便于模型训练,提高计算效率。根据代码描述,计算调整过后得到的新通道数,最小是8,计算公式:给定通道数 + divisor/2 的和,整除 divisor 再乘 divisor,得到的结果是divisor的倍数,无论怎么调整通道数,最终返回的调整值都是divisor的倍数。
3、卷积层 + 规范化层 + 激活层三合一封装
# 卷积层 + 规范化层 + 激活层 三合一封装
class ConvBNActivation(nn.Sequential):
def __init__(self,
input_channel: int,
output_channel: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
# Optional[Callable[..., nn.Module]]是一个注解,意味着它可以是一个可调用的对象(函数或类),该对象可以返回一个nn.Module的实例
# norm_layer:规范化层的配置,默认为None -> nn.BatchNorm2d
norm_layer: Optional[Callable[..., nn.Module]] = None,
# activation_layer:激活层的配置,默认为None -> nn.ReLU6
activation_layer: Optional[Callable[..., nn.Module]] = None):
# 进行卷积处理后输入尺寸W和H可能会发生变化,因此用padding填充被卷走的那一层数据
padding = (kernel_size - 1) // 2
# 如果规范化层和激活层不传入参数,则默认为批归一化和ReLU6;当然也可以自定义想传入的规范化对象和激活对象,此时不使用默认对象
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
# 一次性创建了卷积层、规范化层和激活层
# norm_layer和activation_layer已经在上述代码被赋值
# 首先,通过 nn.Conv2d 创建卷积层,传入了输入通道数、输出通道数、卷积核大小、步长、填充大小和分组数等参数。
# 然后,通过 norm_layer(output_channel) 创建规范化层,其中 output_channel 是卷积层的输出通道数。
# 最后,通过 activation_layer(inplace=True) 创建激活层,其中 inplace=True 表示原地激活。
super(ConvBNActivation, self).__init__(
nn.Conv2d(
in_channels=input_channel, out_channels=output_channel, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups,bias=False),
norm_layer(output_channel),
activation_layer(inplace=True))ConvBNActivation模块构造器参数含义:
1、input_channel:CBA模块的输入通道,需要int类型
2、output_channel:CBA模块的输出通道,需要int类型
3、kerner_size:CBA模块中卷积层的核大小,需要int类型,且默认为3
4、stride:CBA模块中的卷积层的步幅,且默认为1
5、groups:CBA模块中的卷积层的分组数,且默认为1,分组可以提高计算效率
6、norm_layer:CBA模块中的规范化层,可以自定义需要哪个规范化层进行归一化,默认为不自行设置(None)
7、activation_layer:CBA模块中的激活层,可以自定义需要哪个激活函数来进行激活,默认为不自行设置(None)
返回值:使用本方法后,将会创建三个连续的层(卷积层+规范层+激活层)
【注意】如果不在构造器中传入norm_layer和activation_layer的名称,则调用ConvBNActivation类的构造器后默认会创建BatchNorm()归一化层和ReLU6()激活层,如果想自定义创建某个特定的规范层和激活层,需要在构造器中键入想要创建的层的名称。
4、SE注意力机制模块
# SE模块封装:注意力机制
class SqueezeExcitation(nn.Module):
def __init__(self, input_channel: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_channel = _make_divisible(input_channel // squeeze_factor, 8)
# SE模块需要定义两个卷积层零件,一个负责特征图的压缩,一个负责特征图的还原
self.fc1 = nn.Conv2d(input_channel, squeeze_channel, 1)
self.fc2 = nn.Conv2d(squeeze_channel, input_channel, 1)
def forward(self, x: Tensor) -> Tensor:
# 这里的scale求的是对特征信息的重要性大小的表达,被称作缩放因子
# 如果该特征信息比较重要,scale会比较大,反之比较小
# SE模块的流程:x - 自适应平均池化层 - fc1压缩 - relu激活 - fc2还原 - hardsigmoid激活 - 得到scale - scale * x
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
SE模块构造器的参数含义:
1、input_channel:SE模块的输入通道数,需要int类型
2、squeeze_factor:压缩因子,对输入通道进行压缩操作,公式:input_channel // squeeze_factor,默认为4
返回值:scale * x:输入到SE模块的数据 x 与重要性分数相乘
5、倒残差块模块的基本参数封装
# MobileNet V3中倒残差块的网络配置属性信息初始化
class InvertedResidualConfig:
# 构造器
def __init__(self,
input_channel: int, # 输入通道数
kernel: int, # 卷积核大小
expand_channel: int, # 扩张后的通道数
output_channel: int, # 输出通道数
use_SE: bool, # 是否使用SE模块
activation: str, # 激活层是什么
stride: int, # 步幅是多少
# 较小的width_multi会减少模型复杂度和计算量,较大的width_multi则会增加模型的表达能力和性能。
width_multi: float): # 通道宽度的倍数因子,和MobileNet v2中的α超参数差不多
self.input_channel = self.adjust_channels(input_channel, width_multi)
self.kernel = kernel
self.expand_channel = self.adjust_channels(expand_channel, width_multi)
self.output_channel = self.adjust_channels(output_channel, width_multi)
self.use_SE = use_SE
self.use_HS = (activation == "HS") # whether using h-swish activation
self.stride = stride
# 这是一个静态方法,可以直接把width_multi乘在需要调整的channel数上,随后进行倍八通道调整
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)流程:输入 - PW1升维 - DW处理 - PW2降维 - 输出
其中,PW1需要输入通道,给出扩张通道;DW不改变通道,所以输入输出都是扩张通道,PW2需要扩张通道,给出输出通道;下一层倒残差的输入通道就是上一层倒残差的输出通道。
InvertedResidualConfig倒残差块模块的基本参数封装的构造器参数含义:
1、input_channel:PW1输入通道
2、kernel:DW核大小
3、expand_channel:扩张通道,PW1输出通道,DW输入 / 输出通道,PW2输入通道
4、output_channel:PW2输出通道,下一层PW1输入通道
5、use_SE:是否使用SE模块,接受布尔变量
6、activation:给定激活层的名字,接受字符串变量,根据代码内容,如果activation接受的字符串变量是“HS”,那么会使得use_HS = True
7、stride:DW核的步幅大小,也是下采样操作的开关
8、width_multi:通道数的倍数因子,与v2Net中的超参数α差不多,可以全局改变通道的数量
返回值:调用该模块的构造器后,可以在其他类中使用以下参数:
1、input_channel:PW1输入通道
2、kernel:DW核大小
3、expand_channel:扩张通道,PW1输出通道,DW输入 / 输出通道,PW2输入通道
4、output_channel:PW2输出通道,下一层PW1输入通道
5、use_SE:是否使用SE模块,接受布尔变量
6、use_HS:是否使用HardSwish模块,根据后文描述,如果该项是True,则使用HS,若不是,则使用ReLU
7、stride:DW核的步幅大小,也是下采样操作的开关
6、倒残差模块的模型封装
# 倒残差块网络封装:PW升维 - DW处理 - SE模块处理(按需使用) - PW降维(无需激活)
class InvertedResidual(nn.Module):
# 构造器:传入网络属性配置,传入规范化层
# 【注意】如果不写规范化层norm_layer,那么默认传入的规范化层为None,则ConvBNActivation会默认生成BatchNorm层)
def __init__(self,
IRNetConfig: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
# 限制网络初始化配置的stride参数必须为1和2
if IRNetConfig.stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 定义捷径线开关,并给定开启的条件
self.use_shortcut = (IRNetConfig.stride == 1 and IRNetConfig.input_channel == IRNetConfig.output_channel)
# 创建一个空的列表 layers 用于存储网络块的各个子模块
layers: List[nn.Module] = []
# 定义激活层所使用的激活函数,条件是:如果配置信息中的use_HS为True就使用Hardswish激活函数,否则用ReLU
activation_layer = nn.Hardswish if IRNetConfig.use_HS else nn.ReLU
# 如果输入通道和扩张后的通道不一样,说明要进行PW升维操作
if IRNetConfig.middle_channel != IRNetConfig.input_channel:
layers.append(ConvBNActivation(IRNetConfig.input_channel, IRNetConfig.middle_channel,
kernel_size=1, norm_layer=norm_layer,
activation_layer=activation_layer))
# 随后进行DW处理操作,通道数不发生变化
layers.append(ConvBNActivation(IRNetConfig.middle_channel, IRNetConfig.middle_channel,
kernel_size=IRNetConfig.kernel, stride=IRNetConfig.stride,
groups=IRNetConfig.middle_channel, norm_layer=norm_layer,
activation_layer=activation_layer))
# 根据配置信息中的use_SE,判断是否使用注意力机制模块
# SE模块在DW操作之后,所以传入SE的输入通道应该是DW的输出通道,即:middle_channel
# 这里在append注意力模块的时候,只传入了SE输入通道,还有一个参数是SqueezeFactor使用默认值4
if IRNetConfig.use_SE:
layers.append(SqueezeExcitation(IRNetConfig.middle_channel))
# PW降维操作
# nn.Identity 是 PyTorch 中的一个恒等函数(identity function)模块,它不进行任何操作,仅仅将输入的数据原封不动地返回。
layers.append(ConvBNActivation(IRNetConfig.middle_channel, IRNetConfig.output_channel,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity))
# 将以上子模块按顺序添加到 nn.Sequential 中,形成一个整体的倒残差网络块。
self.IRNetBlock = nn.Sequential(*layers)
# 获取到倒残差网络块输出的通道数
self.IRNetBlock_output_channels = IRNetConfig.output_channel
# is_downSample 属性表示是否进行了步长大于 1 的操作,即是否进行了下采样。
self.is_downSample = (IRNetConfig.stride > 1)
# IRNetBlock对输入x的处理流程,输入x是个Tensor,输出也是Tensor
def forward(self, x: Tensor) -> Tensor:
NetOutput = self.IRNetBlock(x)
if self.use_shortcut:
NetOutput += x
return NetOutput
7、MobileNet v3网络的基本结构与封装
# 定义了三合一模块和倒残差模块后,接下来可以定义整个v3版本的网络了
# v3网络的流程:Conv(1) - 一大堆IRNetBlock - Conv(-1) - AvgPool - FC(1) - FC(2)
class MobileNetV3(nn.Module):
# 构造器
def __init__(self,
# 倒残差模块的配置:用List列表来装载一大堆倒残差模块的网络配置信息,注意:不包括普通卷积
IRNetBlock_Config_List: List[InvertedResidualConfig],
# 分类器最后一层的输入通道数,也是整个处理过程中最后的输出通道
classifier_last_channel: int,
# 分类器最终需要分类的数量
num_classes: int = 1000,
# 用于构建何种倒残差模块的构造器对象,默认构造(None -> InvertedResidual模块)
IRNetBlock: Optional[Callable[..., nn.Module]] = None,
# 用于构建何种规范化层的对象,默认传入(None -> BatchNorm2d模块)
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
# 如果传入了空的倒残差模块的配置信息,则报错
if not IRNetBlock_Config_List:
raise ValueError("The inverted_residual_setting should not be empty.")
# 如果 inverted_residual_setting 不是 List[InvertedResidualConfig] 类型,则抛出类型错误。
elif not (isinstance(IRNetBlock_Config_List, List) and
all([isinstance(s, InvertedResidualConfig) for s in IRNetBlock_Config_List])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
# 如果有封装多个不同的倒残差模块的类,可以自定义使用哪一个倒残差模块
# 如果没有手动传入用于构建倒残差块的对象,则默认使用InvertedResidual倒残差模块,赋给IRNetBlock
if IRNetBlock is None:
IRNetBlock = InvertedResidual
# 同上,如果没有手动传入用于构建规范化层的构造对象,则默认使用BatchNorm2d规范层
# 且通过偏函数方法partial,来修改BatchNorm2d中的eps超参数和momentum超参数为对应的值,然后生成BN层赋给norm_layer
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
# 用于装载各个层定义和属性的容器,之后倒入Sequential中
layers: List[nn.Module] = []
# 特征层第一层:普通卷积,通道信息为:3 - ? - 16
# 3是原始图像输入的RGB通道数,16可以是普通卷积输出通道数,也是第一层倒残差块的输入通道数
firstConv_input_channel = 3
firstConv_output_channel = IRNetBlock_Config_List[0].input_channel # 16
# 加入到容器
layers.append(ConvBNActivation(firstConv_input_channel, firstConv_output_channel,
kernel_size=3, stride=2, norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# 倒残差模块层组,循环遍历IRNetBlock的配置信息
# append里面的IRNetBlock在上文有赋值,为InvertedResidual,该对象的构造器参数为Config配置信息,norm_layer规范层名字
for IRNetBlock_Config in IRNetBlock_Config_List:
layers.append(IRNetBlock(IRNetBlock_Config, norm_layer))
# 特征层最后的卷积层:该层的输入通道就是最后一个倒残差模块输出通道
lastConv_input_channel = IRNetBlock_Config_List[-1].output_channel # 160
lastConv_output_channel = 6 * lastConv_input_channel # 960
layers.append(ConvBNActivation(lastConv_input_channel, lastConv_output_channel,
kernel_size=1, norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# 把装载了特征层的容器倒入Sequential生成特征层执行列表
self.features = nn.Sequential(*layers)
# 平均池化层
self.avgpool = nn.AdaptiveAvgPool2d(1)
# 分类器
# 全连接层1(IC:特征层最后的输出通道960;OC:分类器最后的输出通道1280),HS激活,Dropout
# 全连接层2(IC:分类器最后的输出通道1280;OC:整个网络需要分类的数量5),不激活
self.classifier = nn.Sequential(nn.Linear(lastConv_output_channel, classifier_last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(classifier_last_channel, num_classes))
# # initial weights
# for m in self.modules():
# if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode="fan_out")
# if m.bias is not None:
# nn.init.zeros_(m.bias)
# elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
# nn.init.ones_(m.weight)
# nn.init.zeros_(m.bias)
# elif isinstance(m, nn.Linear):
# nn.init.normal_(m.weight, 0, 0.01)
# nn.init.zeros_(m.bias)
def forward(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x8、MobileNet v3 - Large 网络的搭建
# 开始构建MobileNet v3 Large网络
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
# 通过偏函数的方式,指定IRConfig方法内的width_multi参数默认为1.0,称为局部默认赋值,赋值完毕后将IRConfig赋值给bottleneck_config
# 同样地,通过偏函数的方式,指定adjust_channels函数中的width_multi参数默认为1.0,赋值完毕后将该方法赋给adjust_channels
width_multi = 1.0
IRNetBlock_Config = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
# 当 "reduce_tail" 设置为 True 时,会将 C4 和 C5 之间所有的特征层的通道数减半(除以2),反之不进行减半操作。
# 这个操作旨在减少检测和分割任务中骨干网络中的通道冗余,从而减少计算量和内存消耗。
if reduced_tail == True:
reduce_divider = 2
else:
reduce_divider = 1
IRNetBlock_Config_List = [
# input_channel, kernel, middle_channel, output_channel, use_SE, activation, stride
IRNetBlock_Config(16, 3, 16, 16, False, "RE", 1),
IRNetBlock_Config(16, 3, 64, 24, False, "RE", 2), # C1
IRNetBlock_Config(24, 3, 72, 24, False, "RE", 1),
IRNetBlock_Config(24, 5, 72, 40, True, "RE", 2), # C2
IRNetBlock_Config(40, 5, 120, 40, True, "RE", 1),
IRNetBlock_Config(40, 5, 120, 40, True, "RE", 1),
IRNetBlock_Config(40, 3, 240, 80, False, "HS", 2), # C3
IRNetBlock_Config(80, 3, 200, 80, False, "HS", 1),
IRNetBlock_Config(80, 3, 184, 80, False, "HS", 1),
IRNetBlock_Config(80, 3, 184, 80, False, "HS", 1),
IRNetBlock_Config(80, 3, 480, 112, True, "HS", 1),
IRNetBlock_Config(112, 3, 672, 112, True, "HS", 1),
IRNetBlock_Config(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
IRNetBlock_Config(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
IRNetBlock_Config(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
classifier_last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(IRNetBlock_Config_List=IRNetBlock_Config_List,
classifier_last_channel=classifier_last_channel,
num_classes=num_classes)
在拥有了MobileNet v3网络的封装后(里面也包含了三合一封装块,SE封装块,倒残差模块的配置信息封装,倒残差结构的封装块4个字块),我们只需要按照MobileNet v3封装块的构造器所需要的信息,传入v3 - Large网络的配置信息,就可以得到Large网络了。
从代码来看,MobileNet v3网络需要传入的参数有:
(1)倒残差块的配置信息列表:IRNetBlock_Config_List
(2)分类器最后的输出通道:即 1280
(3)分类器输出的分类数量:即 5
根据理论部分讲解的Large网络的配置信息,写好IRNetBlock的配置信息列表即可。
9、MobileNet v3 - Small 网络的搭建
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
IRNet_Config = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
if reduced_tail == True:
reduce_divider = 2
else:
reduce_divider = 1
IRNetBlock_Config_List = [
# input_channel, kernel, middle_channel, output_channel, use_SE, activation, stride
IRNet_Config(16, 3, 16, 16, True, "RE", 2), # C1
IRNet_Config(16, 3, 72, 24, False, "RE", 2), # C2
IRNet_Config(24, 3, 88, 24, False, "RE", 1),
IRNet_Config(24, 5, 96, 40, True, "HS", 2), # C3
IRNet_Config(40, 5, 240, 40, True, "HS", 1),
IRNet_Config(40, 5, 240, 40, True, "HS", 1),
IRNet_Config(40, 5, 120, 48, True, "HS", 1),
IRNet_Config(48, 5, 144, 48, True, "HS", 1),
IRNet_Config(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
IRNet_Config(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
IRNet_Config(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(IRNetBlock_Config_List=IRNetBlock_Config_List,
classifier_last_channel=last_channel,
num_classes=num_classes)同理可得,模仿(8)小节即可理解v3 - Small网络的搭建流程,不多赘述。

















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









