







疫情当前,共克时坚。今天来试着爬取疫情情况,用js代码
第一步依旧准备好要用到的库:
import requests import json from openpyxl import Workbook
接着来打开url
步骤:右击,检查
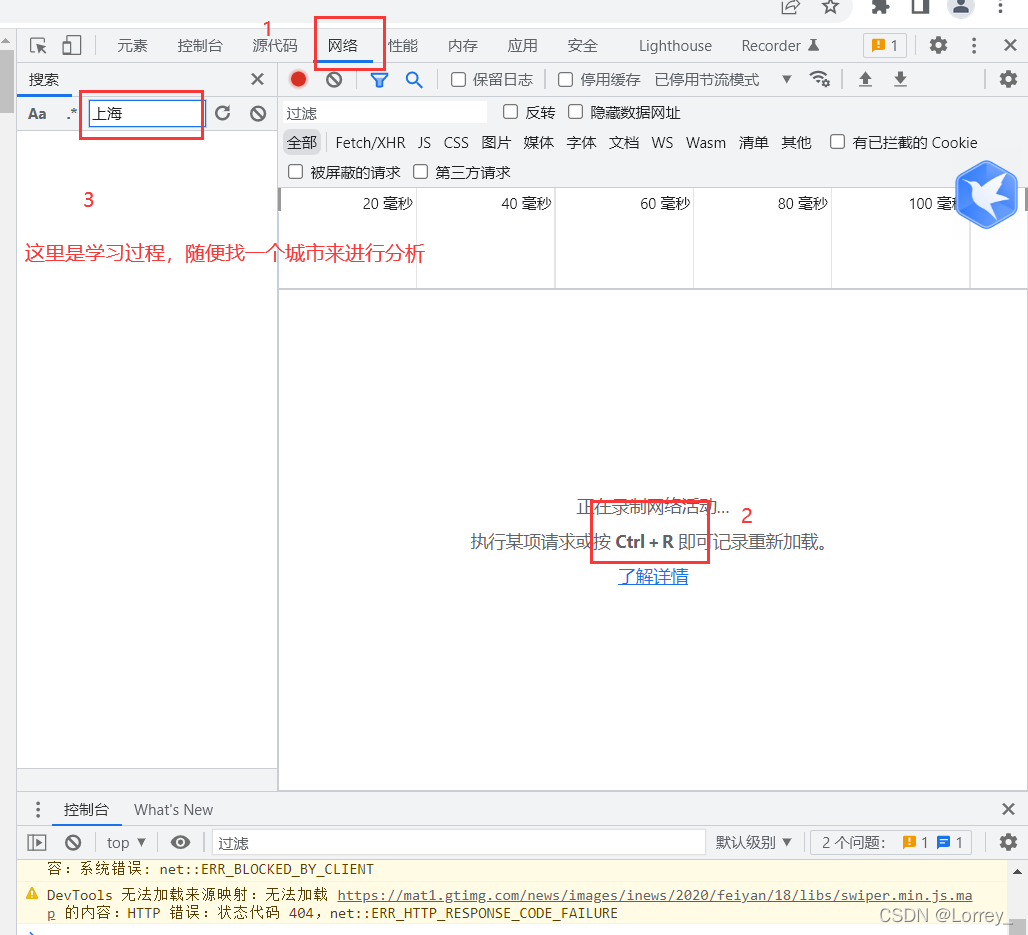
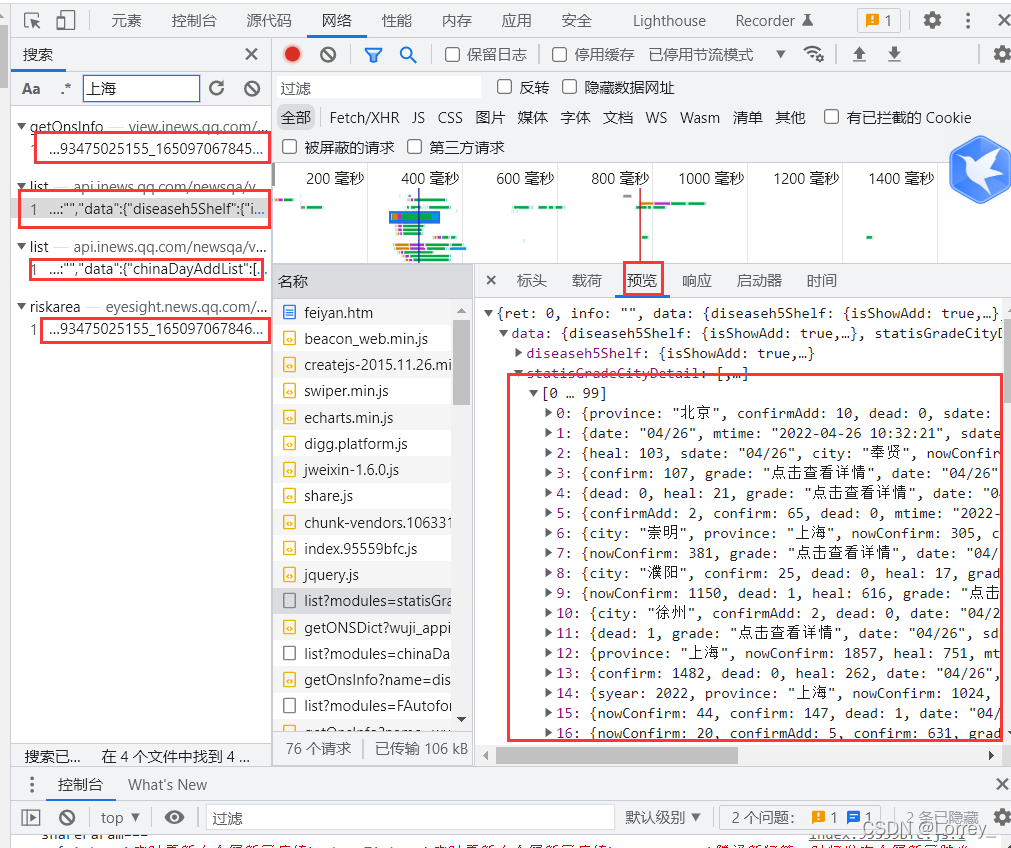
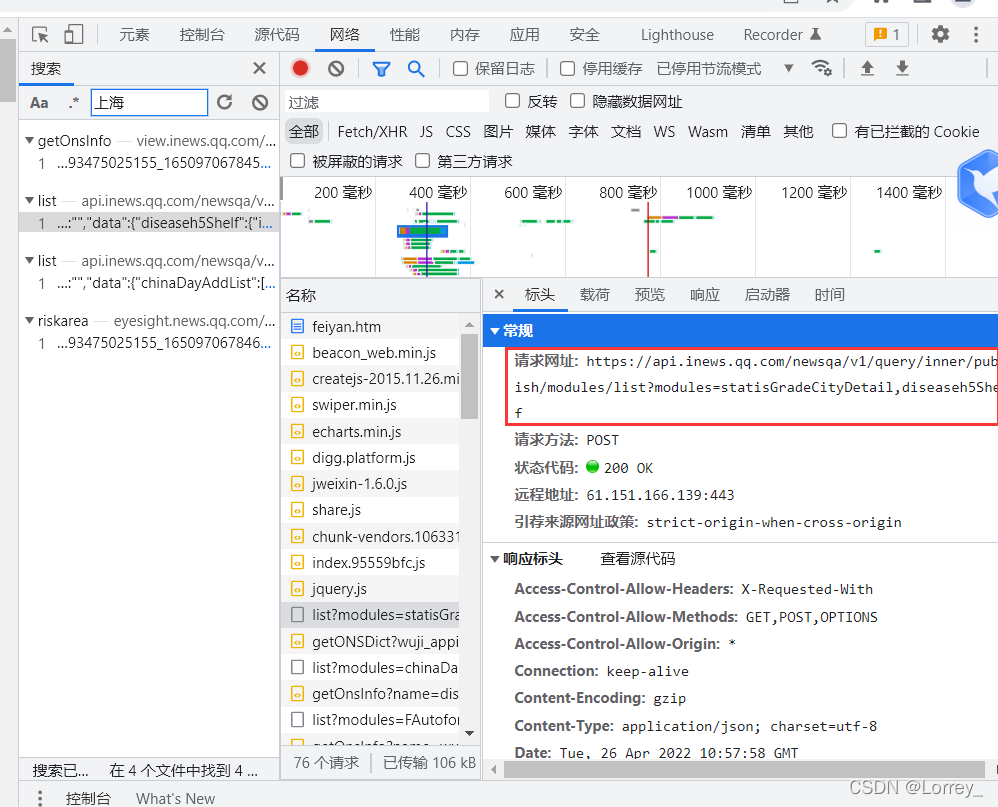
确定了url,可以开始初步代码了
url='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
r=requests.get(url)
retext=r.text接下来通过分析js代码找到了我们需要的内容
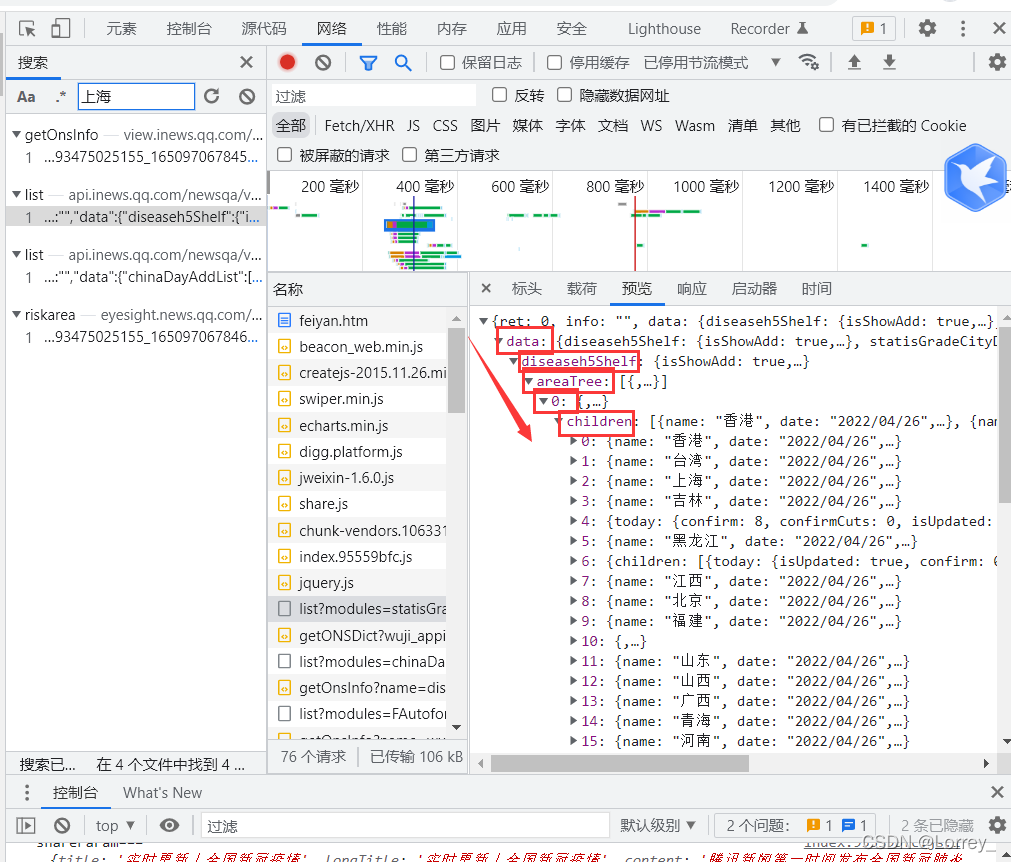
于是我们就可以这样写
citylist=data['data']['diseaseh5Shelf']['areaTree'][0]['children']
内容找到了,接下来插入到字典中
for i in citylist:
#print(i['name'],i['total']['nowConfirm'],i['total']['wzz'])
alist.append([i['name'],i['total']['nowConfirm'],i['total']['wzz']])
print(alist)
最后,保存Excel
filename='今日疫情.xlsx'
wb=Workbook()
sheet=wb.active
sheet.append(['省份','新增','无症状'])
#
for i in alist:
sheet.append(i)
wb.save(filename)
完整代码如下:
import requests
import json
from openpyxl import Workbook
from openpyxl import load_workbook
url='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=statisGradeCityDetail,diseaseh5Shelf'
r=requests.get(url)
retext=r.text
data=json.loads(retext)
citylist=data['data']['diseaseh5Shelf']['areaTree'][0]['children']
alist=[]
for i in citylist:
#print(i['name'],i['total']['nowConfirm'],i['total']['wzz'])
alist.append([i['name'],i['total']['nowConfirm'],i['total']['wzz']])
print(alist)
filename='今日疫情.xlsx'
wb=Workbook()
sheet=wb.active
sheet.append(['省份','新增','无症状'])
#
for i in alist:
sheet.append(i)
wb.save(filename)
打开xlsx文件便是我们要爬取的内容,任务完成
















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











