







Lab 6: Copy-on-Write Fork for xv6
- Lab Guide: https://pdos.csail.mit.edu/6.828/2020/labs/cow.html
- Lab Code: https://github.com/peakcrosser7/xv6-labs-2020/tree/cow
Implement copy-on write(hard)
要点
- 修改
uvmcopy(),usertrap(),copyout()等函数 - 对物理页记录引用数(reference count), 当引用数为 0 时才实际进行释放.
- 标记 COW 的 PTE, 利用保留的 RSW 比特位.
- 无可分配内存时杀死进程
步骤
1. 构造 COW 物理页的引用计数结构.
- 引用计数结构体数组.
根据指导书提示容易考虑使用数组来记录每个物理页的对应的引用数. 而数组的容量容易想到是使用最大物理地址(PHYSTOP>>12), 其中右移 12 位相当于除以 4096, 也就是一个物理页的大小.
对于数组大小可以进一步优化, 由于 COW 考虑的是用户进程的空间, 而根据 xv6 物理地址空间分布, 内存KERNBASE以下的地址映射的是外设, 无关 COW 机制, 因此可以将数组容量缩小至(PHYSTOP-KERNBASE)>>12.
如果进一步考虑, 实际上内核代码段和数据段同样无关 COW 机制, 可以进一步缩减数组大小, 但由于内核地址大小不为常量, 最终是由kernel/kernel.ld中的end变量记录(在kernel/kalloc.c中有该变量引用), 因此不为常量不能用于数组大小的定义.
而通过kernel/kalloc.c中kinit()函数可以得知, 实际可用于kalloc()分配的物理内存即从end开始, 也就是说对于内核代码段和数据段部分的引用计数将一直为 0. - 引用计数字段.
引用计数字段此处直接使用了uint8类型, 即单字节无符号整数, 因为考虑到 xv6 的最多可分配进程数NPROC为 64, 所以 1 个字节存储引用计数是足够的. - 引用计数的锁结构.
容易知道, 引用计数数组是一个全局数组, 即多进程都有可能对同一父进程进行fork()等操作, 从而引起引用计数的变化, 因此需要锁结构进行数据一致性的保护. 由于此处引用计数的变化比较简单, 因此考虑使用自旋锁struct spinlock.
此处考虑自旋锁的选择, 在kernel/kalloc.c中有kmem.lock专门用于维护kmem.freelist即空物理页链表. 这里可以直接借用该自旋锁. 当然也可以使用新的自旋锁, 这样可以保证kmem.lock功能的专一. 而考虑此处是一个引用计数的数组, 而数组中的不同元素即不同物理页的引用计数之间实际上是不存在并发问题的, 因此此处笔者对每一个物理页的引用计数对应一个自旋锁. 这样的好处在于不同物理页之间的并发性提高了, 当然也相对带来了一定的内存开销.
至于锁的初始化, 理论上需要initlock()函数, 但由于初始locked字段为0即可, 因此可以省去初始化每个物理页的自旋锁的步骤.
// COW reference count
struct {
uint8 ref_cnt;
struct spinlock lock;
} cows[(PHYSTOP - KERNBASE) >> 12];
2. 引用计数相关函数
- 为了方便, 此处引用计数结构体实际上是一个匿名结构体, 且定义的
cows数组仅在其文件内可访问. 引用计数的场景其实比较简单, 只有加 1 和减 1 两种操作, 因此此处定义了increfcnt()和decrefcnt()两个函数. 函数的输入均为物理地址pa, 通过减基地址KERNBASE然后右移 12 位便得到了该物理地址所在物理页的引用计数元素, 通过内置的自旋锁加锁后对计数ref_cnt进行加 1 或减 1 操作. 而两函数另一个区别在于decrefcnt()会将引用计数进行返回, 用于判断在计数降至 0 时将物理页内存进行释放.
// increase the reference count
void increfcnt(uint64 pa) {
if (pa < KERNBASE) {
return;
}
pa = (pa - KERNBASE) >> 12;
acquire(&cows[pa].lock);
++cows[pa].ref_cnt;
release(&cows[pa].lock);
}
// decrease the reference count
uint8 decrefcnt(uint64 pa) {
uint8 ret;
if (pa < KERNBASE) {
return 0;
}
pa = (pa - KERNBASE) >> 12;
acquire(&cows[pa].lock);
ret = --cows[pa].ref_cnt;
release(&cows[pa].lock);
return ret;
}
- 需要在
kernel/def.h中声明对引用计数加 1 和减 1 的函数原型.
// cow.c - lab6
void increfcnt(uint64 pa);
uint8 decrefcnt(uint64 pa);
- 此处笔者将 COW 机制的引用计数及其相关函数单独置于新文件
kernel/cow.c中, 因此需要在Makefile文件中添加对该文件编译链接.
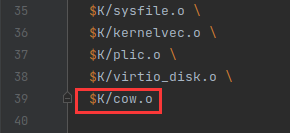
3. COW 标记位
对于 COW 机制下的物理页, 需要其对应的虚拟页的 PTE 的标记位进行区分, 用于在引发 page fault 时识别出是 COW 机制, 并进行新物理页的分配.
根据指导书提示, 可以使用 PTE 中保留的两个 RSW 比特位中的一位.

在 kernel/riscv.h 中定义 COW 标志位.

4. 修改 uvmcopy() 函数
uvmcopy()函数用于在fork()时子进程拷贝父进程的用户页表. 而 COW 实际上影响的就是该部分, 并非实际拷贝, 而是将子进程虚拟页同样映射在与父进程相同的物理页上. 因此对于该函数主要修改之处就是将原本的kalloc()分配去掉.- 此外, 由于是写时复制, 因此需要对父进程和子进程该物理页对应的虚拟页 PTE 的标志位进行处理, 移除原本的写标志位
PTE_W, 并添加 COW 标志位PTE_COW. - 在最后需要调用
increfcnt()对当前物理页的引用计数加 1.
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem; // lab6
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
// clear PTE_W adn add COW flags - lab6
flags = (PTE_FLAGS(*pte) & (~PTE_W)) | PTE_COW;
*pte = PA2PTE(pa) | flags; // update old pte - lab6
// not allocate new page - lab6
// if((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, pa, flags) != 0){ // use the same pa as the old - lab6
// kfree(mem); // lab6
goto err;
}
increfcnt(pa); // increase reference count - lab6
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
- 注: 对于错误处理
err:标签后的uvmunmap()函数的第四个参数do_free也可能会考虑将do_free参数置为 0. 但此处不能修改. 这需要结合后续对free()函数的改动,free()只有计数为 0 时才会真正将物理页进行释放, 若此处将do_free参数置为 0, 则会导致uvmunmap()出错前映射的物理页的引用计数不会还原, 影响物理页的正确释放.
5. 构造 COW 机制函数
- 此处考虑的是修改
usertrap()和copyout()两个函数, 来对 COW 的页进行处理. 原本笔者是进行的分别实现, 但实际上需要的操作处理是一致的, 因此构造了函数walkcowaddr()进行了统一处理. 此外, 若没有该函数, 则就需要将原walk()函数添加原型到kernel/defs.h中用于获取虚拟地址对应的 PTE, 笔者认为这样增大了该函数的作用域, 并不是很好的解决方案. - 通过
walkcowaddr()函数名也可以看出, 其和walkaddr()函数是类似的, 主要就增加了对 COW 页面的处理. 之所以未直接修改walkaddr()是考虑到调用函数的场景不同. - 对于
walkcowaddr(), 当前面对va和pte的判断保留, 然后添加对PTE_W标志位的判断, 若无该标记, 则进一步判断是否有PTE_COW标志位. 因为无论是引发 page fault 还是copyout(), 都是在写操作时才会考虑进行 COW 操作, 读操作可以正常进行, 而写操作时当前页面不可读, 若无PTE_COW标记位则该物理页本身就不可写, 直接返回 0 表示失败; 反之有PTE_COW标记位则表明需要进行 COW 操作, 接着分配新的物理页并重新映射的用户页表中, 并返回新的物理地址. 需要注意新的物理页的PTE_COW标志位需要移除, 而PTE_W标志位需要添加, 正好与uvmcopy()复制时是相反的. - 这里取消原映射
uvmunmap()函数的第四个参数do_free是置 1 的, 即将原映射的物理内存进行释放, 同样是结合free()函数的修改, 会对物理页引用计数减 1, 只有到 0 后才实际释放.
// lab6
uint64 walkcowaddr(pagetable_t pagetable, uint64 va) {
pte_t *pte;
uint64 pa;
char* mem;
uint flags;
if (va >= MAXVA)
return 0;
pte = walk(pagetable, va, 0);
if (pte == 0)
return 0;
if ((*pte & PTE_V) == 0)
return 0;
if ((*pte & PTE_U) == 0)
return 0;
pa = PTE2PA(*pte);
// 判断写标志位是否没有
if ((*pte & PTE_W) == 0) {
// pte without COW flag cannot allocate page
if ((*pte & PTE_COW) == 0) {
return 0;
}
// 分配新物理页
if ((mem = kalloc()) == 0) {
return 0;
}
// 拷贝页表内容
memmove(mem, (void*)pa, PGSIZE);
// 更新标志位
flags = (PTE_FLAGS(*pte) & (~PTE_COW)) | PTE_W;
// 取消原映射
uvmunmap(pagetable, PGROUNDDOWN(va), 1, 1);
// 更新新映射
if (mappages(pagetable, PGROUNDDOWN(va), PGSIZE, (uint64)mem, flags) != 0) {
kfree(mem);
return 0;
}
return (uint64)mem; // COW情况下返回新物理地址
}
return pa;
}
- 在编写好
walkcowaddr()函数后, 便只需在usertrap()和copyout()中调用即可. 对于前者, 和 Lazy Allocation 相同, 需要增加一个 trap 的判断条件, 但此处只考虑r_scause()==15的条件, 因为只有在 store 指令写操作时触发 page fault 才考虑 COW 机制, 而不是和 Lazy Allocation 一样需要读写均考虑. 对于copyout()函数则比较简单, 只需要将原本的walkaddr()更改为walkcowaddr()即可.
void
usertrap(void)
{
// ...
if(r_scause() == 8){
// ...
} else if(r_scause() == 15) { // COW - lab6
if (walkcowaddr(p->pagetable, r_stval()) == 0) {
goto bad;
}
} else if((which_dev = devintr()) != 0){
// ok
} else {
bad: // lab6
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
// ...
}
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pa0 = walkcowaddr(pagetable, va0); // with COW - lab6
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
6. 修改引用计数相关函数
上文只在 uvmcopy() 中考虑了引用计数的操作, 因此最后很重要的是对引用计数的其他相关函数进行修改, 保证引用计数的整个流程中数组的正确性.
- 根据指导书, 首先考虑的就是
kernel/kalloc.c的kalloc()函数. 在调用该函数时, 则表明需要将一个物理页分配给一个进程, 并对应一虚拟页. 因此, 需要调用increfcnt()函数对引用计数加 1, 即从原本的 0 加至 1.
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
// init page's ref_cnt to 1 - lab6
increfcnt((uint64)r);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
- 接下来就是
kalloc()函数对应的kernel/kalloc.c中的kfree()函数, 用于物理页的释放. 在真正将物理页回收到kmem.freelist前, 需要对物理页的引用计数减 1, 并判断是否为 0, 若不为 0 则表明仍有其他进程引用该物理页, 则直接返回不回收; 反之才进行真正的回收.
该改动也对照了上文中do_free参数为 1 的情况, 因为在kfree()中首先是对引用计数进行减 1, 只有减至 0 才会真正释放.
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// decrease the page's reference count
// and not place the page back if its reference count isn't 0
// - lab6
if (decrefcnt((uint64) pa)) {
return;
}
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
- 需要同样进行修改的还有
kernel/kalloc.c中的freerange()函数. 该函数被kinit()函数调用, 其主要作用就是对物理内存空间中未使用的部分以物理页划分调用kfree()将其添加至kmem.freelist中. 这里的问题在于对于cows数组中的ref_cnt字段初始值为 0, 在初始调用freerange()的free()函数时会将引用计数减 1, 由于其类型为uint8, 会产生下溢变为255, 从而不能将物理页回收至kmem.freelist中, 引发错误. 因此, 需要在调用free()之前再调用increfcnt()来先将引用计数变为 1, 这样在free()时正好可以减至 0 进行回收.
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE) {
increfcnt((uint64)p); // lab6
kfree(p);
}
}
遇到问题
- xv6 启动时报
kalloc的 panic, 如下图所示:
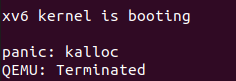
解决: 该问题很难直接调试得到, gdb 调试会发现在初始化内核地址空间调用kalloc()时会出现无页面可分配即kalloc()返回 0 的情况. 最后经过反复分析, 发现原因即在于freerange()未对引用计数先加 1, 导致kmem.freelist无物理页可分配. 上文已具体描述. - 在 xv6 中运行
cowtest出现remap的 panic. 如下图所示:
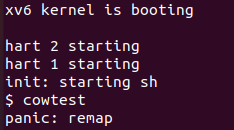
解决: 该问题即出现了虚拟页重映射, 原因在于walkcowaddr()中未调用uvmunmap()先将移除原映射.
测试
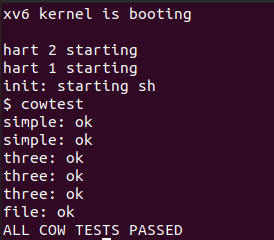
- 在 xv6 中执行
cowtest:
- 在 xv6 中执行
usertests:

make grade测试:
















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









