






一、决策树概述
机器学习中的决策树是一种基本的监督学习算法,用于分类和回归任务。它通过构建一个树状结构来模拟一系列决策过程,从而实现对数据的预测和分类。
在决策树中,每个内部节点表示一个特征属性的判断条件,而每个分支代表该特征属性在某个取值范围上的输出,最后的叶节点表示分类结果。通过从根节点开始,根据特征属性的取值沿着决策树的分支进行遍历,最终到达叶节点,就可以得到对应的预测结果。
决策树的构建过程主要是基于信息论的原理,通过计算不同特征的信息增益或基尼指数等指标来评估其重要性,并选择最优的特征进行划分。这样,决策树能够逐渐地将数据划分为更纯的子集,从而提高分类或回归的准确性。
决策树具有直观易懂、易于解释和可视化等优点,因此在实际应用中得到了广泛的使用。然而,它也存在一些缺点,如容易过拟合、对噪声数据敏感等问题。为了克服这些缺点,研究者们提出了各种优化策略,如剪枝、集成学习等,以进一步提高决策树的性能。
总的来说,决策树是机器学习领域中一种重要且常用的算法,适用于各种分类和回归问题,能够帮助人们更好地理解和利用数据。
二、决策树的构建
1.总体过程
决策树学习的过程是通过逐步选择最优特征来构建树形结构,其中每个节点代表一个特征或属性,分支表示该特征的不同取值,叶节点表示最终的分类结果。
1) 开始:从根节点开始,考虑所有训练数据,并选择一个最佳特征进行分割,以使得各个子集在当前条件下能够得到最好的分类。
2) 如果子集已经被基本正确分类,将其归为叶节点,并停止进一步分割。
3) 如果仍有子集不能正确分类,继续选择新的最佳特征对其进行分割,构建相应的节点,直到所有子集都被正确分类或者无法再选择合适的特征为止。
4) 最终,每个子集都被分配到一个叶节点,表示其明确的类别,从而形成完整的决策树结构。
2、停止条件
-
当前结点包含的样本全部属于同一类,无需划分
-
当前属性集合为空,或是所有样本在所有属性上取值相同(所有条件都一样,但还是无法判断类别)
-
当前结点包含的样本集合为空,无法划分(没有对应的样本了)
3.选择划分属性的方法
首先了解几个名称概念
信息的定义:对应符号xi的信息定义为
其中p(xi)为选择该分类的概率。
熵:熵定义为信息的期望值,时集合信息的度量方式,熵是度量样本不纯度的指标,样本不纯度越大,熵越大,越无序。熵定义为
常见的构建决策树时选择最优划分属性的算法有ID3,C4.5和CART
(1)ID3(信息增益)简介
分析:
ID3算法是决策树算法中最基础的版本。它采用信息增益作为划分数据集的标准。信息增益衡量了一个属性划分数据集后,数据集不纯度的减少量。ID3算法通过计算每个属性的信息增益,选择信息增益最大的属性作为划分属性,然后递归地在子数据集上执行这个过程,直到满足停止条件(如所有样本属于同一类,或没有剩余属性可划分)。
信息增益是指通过某个特征对数据集进行划分所获得的信息量。信息增益越大,表示使用该特征进行划分能够使得数据集的不确定性减小得越多。
具体地,对于一个特征 A,数据集 D 的信息增益 𝐺𝑎𝑖𝑛(𝐷,𝐴),Gain(D,A) 可以用如下公式计算:
其中,H(D) 是数据集 D 的熵,V 是特征 A 可能的取值个数,Dv 是数据集 D 中特征 A 取值为 v 的样本子集,∣Dv∣ 是 Dv 的样本数量,∣D∣ 是数据集 D 的总样本数量。
信息增益衡量了在选择特征 A 进行划分后,数据集整体不确定性的减少程度。在构建决策树时,会选择信息增益最大的特征作为当前节点的划分特征,以达到最优的划分效果。
示例:
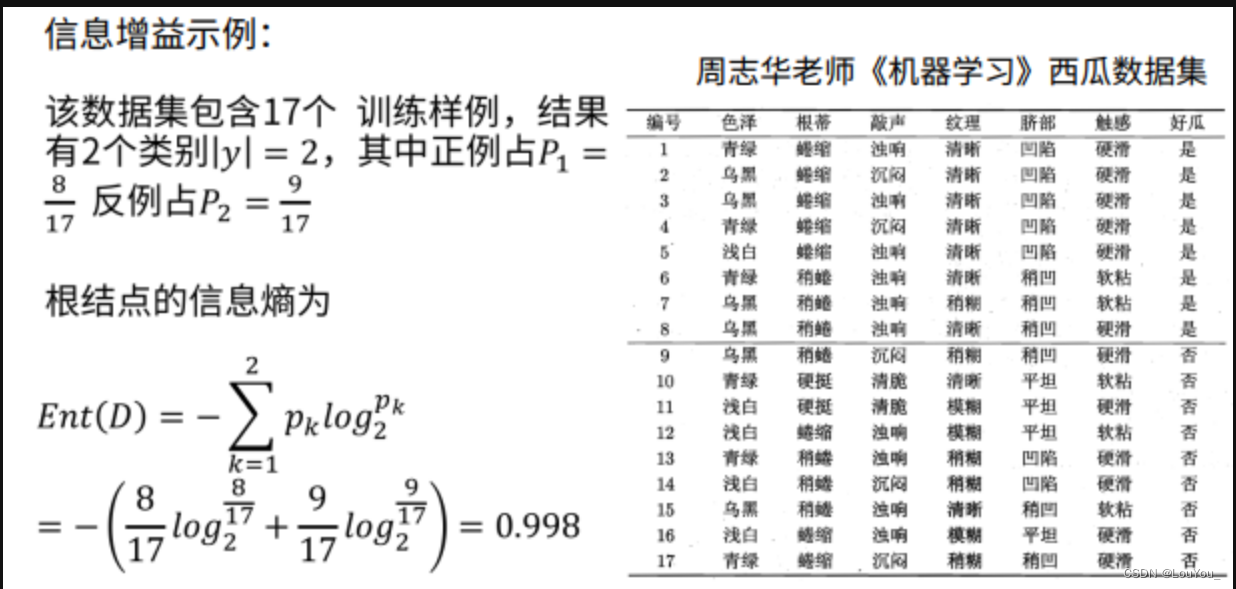



优点:
- 原理简单,易于理解和实现。
- 决策树直观易懂,方便解释和可视化。
缺点:
- 倾向于选择取值较多的属性,可能导致决策树过于复杂,容易过拟合。
- 不能处理连续属性或缺失值。
- 对噪声数据敏感。
(2)C4.5(信息增益率)简介
分析:
- 首先我们要知道ID3算法的缺陷:
假设某个特征有很多取值,那么在使用该特征进行划分时,可能会导致数据集被细分成很多个子集,每个子集中的样本数量较少。如果这个特征能够很好地将样本进行分类,即不同取值对应的类别分布比较纯净,那么通过这个特征划分后的信息增益可能会很大。
相比之下,如果一个特征只有少数几个取值,那么划分后的子集可能相对较少,每个子集中的样本数量可能会较多。即使这个特征能够很好地将样本进行分类,由于划分的子集较少,每个子集中的信息增益可能不会很大。
因此,ID3算法在选择最优特征时,更倾向于选择取值较多的属性,因为这些属性在划分数据集时可能会获得更大的信息增益,从而更好地区分数据。
- 所以我们选用相对值来衡量信息的增益,也就是信息增益率:
C4.5算法是ID3算法的改进版。它采用信息增益率作为划分数据集的标准,以克服ID3算法倾向于选择取值较多属性的问题。信息增益率在信息增益的基础上,考虑了划分后的子集的纯度,因此能够更准确地选择出最优的划分属性。此外,C4.5算法还能处理连续属性,并对缺失值进行处理。
信息增益率计算公式为:
Grain_ratio=
其中,Gain(D,A) 是特征 A 对数据集 D 的信息增益,属性熵IV(A) 的计算方式通常使用特征 A 取值的熵来表示。
需要注意的是: 增益率准则对可取数目较少的属性有所偏好,因此C4.5算法并不直接选择增益率最大的特征进行划分。而是采用了启发式: 先从候选划分特征中找出信息增益高于平均水平的属性。 再从中选出增益率最高的。
示例:参考决策树——ID3算法存在的问题实例详解,以及C4.5算法信息增益率的计算实例_以混合属性的天气问题为例,说明如何根据信息增益率来构建一个c4.5决策树-CSDN博客
优点:
- 解决了ID3算法倾向于选择取值较多属性的问题,减少了过拟合的风险。
- 能够处理连续属性和缺失值,提高了算法的适用性。
- 生成的决策树相对简洁,易于理解和解释。
缺点:
- 计算信息增益率时涉及对数运算,可能导致计算量较大。
- 依然可能受到噪声数据的影响。
(3)CART简介
分析:
CART算法(分类回归树算法)既可以用于分类任务,也可以用于回归任务。CART算法构建的是二叉树,即每个节点只有两个子节点。在构建过程中,CART算法使用“基尼指数”来选择划分属性。基尼指数衡量了数据集的不纯度,CART算法选择使得划分后基尼指数最小的属性作为划分属性。此外,CART算法还包括剪枝步骤,用于避免过拟合,提高模型的泛化能力。
优点:
- 可以处理分类和回归任务,适用范围广泛。
- 构建的是二叉树,模型结构相对简单,易于理解。
- 通过剪枝步骤避免过拟合,提高了模型的泛化能力。
缺点:
- 对某些复杂关系的数据集,可能不如其他方法效果好。
- 当数据集的特征较多时,计算量可能较大。
总结来说,ID3、C4.5和CART这三个决策树构建方法各有优缺点。在实际应用中,需要根据数据集的特点、问题的性质以及需求来选择合适的算法。例如,对于取值较多的属性,C4.5算法可能是一个更好的选择;对于需要处理连续属性或回归任务的情况,CART算法可能更适用。
三、ID3算法和C4.5算法的具体实现
采用了一个简单的例子来做决策树分类:
| 天气 | 温度 | 湿度 | 有风 | 是否打球 |
| 晴 | 炎热 | 高 | 否 | 是 |
| 晴 | 炎热 | 高 | 是 | 是 |
| 多云 | 凉爽 | 正常 | 否 | 否 |
| 雨 | 凉爽 | 正常 | 否 | 是 |
| 雨 | 凉爽 | 高 | 是 | 否 |
| 多云 | 凉爽 | 高 | 否 | 否 |
这个例子是一个简单的决策树示例,用于根据天气条件(晴、多云、雨)、温度(炎热、凉爽)、湿度(高、正常)、是否有风(是、否)等特征来预测是否适合打网球的决策树。数据集中包含了几个样本,每个样本有一组特征值以及一个目标值,即是否打网球。接下来通过两种方式来构建决策树。
1.ID3算法的实现
选择最佳属性
(1)首先,我们需要计算整个数据集的信息熵。
在这个数据集中,我们有两个类别:'否'和'是'。计算每个类别的概率:
- '否'的概率:3/6 = 0.5
- '是'的概率:3/6 = 0.5
因此,初始信息熵为:
H(S)=−(0.5log20.5+0.5log20.5)=1
(2)接下来,我们计算每个属性的信息增益。我们需要计算每个属性的条件信息熵,然后计算信息增益。
天气属性:
- '晴'条件下的子集:2个样本,2个'是',信息熵为0。
- '多云'条件下的子集:2个样本,2个'否',信息熵为0(纯数据集)。
- '雨'条件下的子集:2个样本,1个'否',1个'是',信息熵为1。
天气属性的信息增益为:
G(天气)=H(S)−2/6H(’晴’)−2/6H(’多云’)−2/6H(’雨’)=1−0−0−2/6=0.667
温度属性:
- '炎热'条件下的子集:2个样本,2个'是',信息熵为0(纯数据集)。
- '凉爽'条件下的子集:4个样本,3个'否',1个'是',
信息熵为-(3/4(log(3/4))+1/4(log(1/4)))=0.811。
温度属性的信息增益为:
G(温度)=H(S)−2/6H(’炎热’)−4/6H(’凉爽’)=1−0−(4/6)*0.811=0.459
湿度属性:
- '高'条件下的子集:4个样本,2个'否',2个'是',信息熵为1。
- '正常'条件下的子集:2个样本,1个'否',1个'是',信息熵为1。
湿度属性的信息增益为0
(3)选择最佳属性
根据计算结果,天气属性的信息增益最大(0.667),因此我们选择天气属性作为决策树的根节点。
(4)递归构建决策树
使用选定的最佳属性将数据集划分为子集。 对每个子集递归执行上述步骤,直到满足停止条件(例如,所有子集都属于同一类别,或者子集的大小小于某个阈值)。
实现代码:
from math import log
import operator
# 计算给定数据集的香农熵
def calc_shannon_entropy(data_set):
num_entries = len(data_set) # 数据集的长度,即样本数量
label_counts = {} # 用于统计每个类别的出现次数的字典
for feature_vec in data_set: # 遍历数据集的每个样本
current_label = feature_vec[-1] # 获取样本的类别
if current_label not in label_counts.keys(): # 如果类别不在统计字典中,则加入
label_counts[current_label] = 0
label_counts[current_label] += 1 # 类别出现次数加1
entropy = 0.0 # 初始化香农熵为0
for key in label_counts: # 遍历每个类别
prob = float(label_counts[key]) / num_entries # 计算类别出现的概率
entropy -= prob * log(prob, 2) # 根据香农熵公式累加
return entropy
# 按给定特征划分数据集
def split_data_set(data_set, axis, value):
ret_data_set = [] # 用于存储划分后的数据集
for feature_vec in data_set: # 遍历数据集的每个样本
if feature_vec[axis] == value: # 如果样本的第axis个特征等于给定值
reduced_feature_vec = feature_vec[:axis] # 则将该特征从样本中去除
reduced_feature_vec.extend(feature_vec[axis+1:]) # 将剩余特征重新组合
ret_data_set.append(reduced_feature_vec) # 将处理后的样本加入到划分后的数据集中
return ret_data_set
# 选择最好的数据集划分特征
def choose_best_feature_to_split(data_set):
num_features = len(data_set[0]) - 1 # 获取特征数量
base_entropy = calc_shannon_entropy(data_set) # 计算数据集的原始香农熵
best_info_gain = 0.0
best_feature = -1 # 初始化最佳划分特征的索引为-1
for i in range(num_features): # 遍历每个特征
feat_list = [example[i] for example in data_set] # 获取数据集中每个样本的第i个特征
unique_vals = set(feat_list) # 获取第i个特征的唯一取值
new_entropy = 0.0
for value in unique_vals: # 对第i个特征的每个取值进行划分
sub_data_set = split_data_set(data_set, i, value) # 划分数据集
prob = len(sub_data_set) / float(len(data_set)) # 计算划分后的数据集占比
new_entropy += prob * calc_shannon_entropy(sub_data_set) # 计算划分后的香农熵
info_gain = base_entropy - new_entropy # 计算信息增益
if (info_gain > best_info_gain): # 更新最佳划分特征
best_info_gain = info_gain
best_feature = i
return best_feature
# 创建决策树
def majority_cnt(class_list):
class_count = {} # 用于统计每个类别的出现次数的字典
for vote in class_list: # 遍历类别列表
if vote not in class_count.keys(): # 如果类别不在统计字典中,则加入
class_count[vote] = 0
class_count[vote] += 1 # 类别出现次数加1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) # 对类别按出现次数进行排序
return sorted_class_count[0][0] # 返回出现次数最多的类别
def create_tree(data_set, labels):
class_list = [example[-1] for example in data_set] # 获取数据集的类别列表
if class_list.count(class_list[0]) == len(class_list): # 如果所有样本都属于同一类别,则停止划分
return class_list[0]
if len(data_set[0]) == 1: # 如果遍历完所有特征,则返回出现次数最多的类别
return majority_cnt(class_list)
best_feature = choose_best_feature_to_split(data_set) # 选择最佳划分特征
best_feature_label = labels[best_feature] # 获取最佳划分特征的名称
my_tree = {best_feature_label: {}} # 初始化决策树
del(labels[best_feature]) # 删除已经使用的特征
feat_values = [example[best_feature] for example in data_set] # 获取最佳划分特征的取值列表
unique_vals = set(feat_values) # 获取最佳划分特征的唯一取值
for value in unique_vals: # 遍历最佳划分特征的每个取值
sub_labels = labels[:] # 复制特征名称列表
my_tree[best_feature_label][value] = create_tree(split_data_set(data_set, best_feature, value), sub_labels) # 递归创建子树
return my_tree
# 中文数据集示例
data_set = [
['晴', '炎热', '高', '否', '是'], # 第一个样本
['晴', '炎热', '高', '是', '是'], # 第二个样本
['多云', '凉爽', '正常', '否', '否'], # 第三个样本
['雨', '凉爽', '正常', '否', '是'], # 第四个样本
['雨', '凉爽', '高', '是', '否'], # 第五个样本
['多云', '凉爽', '高', '否', '否'] # 第六个样本
]
labels = ['天气', '温度', '湿度', '有风', '是否打球'] # 特征名称
decision_tree = create_tree(data_set, labels) # 创建决策树
print(decision_tree) # 打印决策树
运行结果:

2. C4.5算法的实现
(1)首先,我们需要计算整个数据集的信息熵,这与ID3算法中的计算方式相同。根据给出的数据集,我们已经知道初始信息熵为1。
(2)接下来,我们计算每个属性的信息增益,这也是与ID3算法相同的步骤。我们已经计算了天气、温度和湿度属性的信息增益,分别为0.667、0.459和0。
(3)在C4.5中,我们需要计算每个属性的分裂信息值(Split Information),这是为了衡量属性取值的分布情况。分裂信息值越小,表示该属性的取值分布越均匀。
天气属性有3个取值('晴'、'多云'、'雨'),每个取值在数据集中出现2次,因此其分裂信息值为:
温度属性有2个取值('炎热'、'凉爽'),出现次数分别为2和4,因此其分裂信息值为:
湿度属性也有2个取值('高'、'正常'),每个取值出现4次,因此其分裂信息值与天气属性相同:
(4)然后,我们使用信息增益和分裂信息值来计算每个属性的信息增益率(Gain Ratio)。信息增益率的计算公式为:
根据之前的计算,我们可以得到:
GrainRatio(天气)=
GrainRatio(温度)=
GrainRatio(湿度)=
(5)选择最佳属性
在C4.5中,我们选择具有最大信息增益率的属性作为最佳属性。根据上面的计算,我们需要比较天气和温度属性的信息增益率来确定哪个更大。所以选择温度作为根节点属性。
(6)递归构建决策树
使用选定的最佳属性(假设为天气属性)将数据集划分为子集。然后,对每个子集递归执行上述步骤,直到满足停止条件(例如,所有子集都属于同一类别,或者子集的大小小于某个阈值)。
代码:
from math import log # 导入math模块中的log函数,用于计算对数
# 计算给定数据集的香农熵
def calc_shannon_entropy(data_set):
num_entries = len(data_set) # 计算数据集中的样本数量
label_counts = {} # 创建一个字典,用于统计每个类别的样本数量
for feature_vec in data_set: # 遍历数据集中的每个特征向量
current_label = feature_vec[-1] # 获取当前样本的类别标签
if current_label not in label_counts.keys(): # 如果类别标签尚未在字典中,则添加
label_counts[current_label] = 0
label_counts[current_label] += 1 # 增加对应类别标签的计数
entropy = 0.0 # 初始化熵值为0.0
for key in label_counts: # 对于字典中的每个类别标签
prob = float(label_counts[key]) / num_entries # 计算该类别标签的概率
entropy -= prob * log(prob, 2) # 根据概率计算熵并更新
return entropy # 返回计算得到的熵值
# 按给定特征划分数据集
def split_data_set(data_set, axis, value):
ret_data_set = [] # 初始化返回的数据集列表
for feature_vec in data_set: # 遍历原始数据集中的每个特征向量
if feature_vec[axis] == value: # 如果特征向量的指定特征等于给定的值
reduced_feature_vec = feature_vec[:axis] # 从特征向量的开始到指定特征之前的部分
reduced_feature_vec.extend(feature_vec[axis+1:]) # 将指定特征之后的部分添加到reduced_feature_vec
ret_data_set.append(reduced_feature_vec) # 将不包含指定特征的新特征向量添加到返回的数据集列表
return ret_data_set # 返回根据指定特征划分后的数据集
# 选择最好的数据集划分特征(C4.5算法)
def choose_best_feature_to_split_C45(data_set):
num_features = len(data_set[0]) - 1 # 计算数据集中特征的数量(减去类别标签)
base_entropy = calc_shannon_entropy(data_set) # 计算整个数据集的熵
best_info_gain_ratio = 0.0 # 初始化最佳信息增益比为0.0
best_feature = -1 # 初始化最佳特征为-1
for i in range(num_features): # 对于每个特征
feat_list = [example[i] for example in data_set] # 获取该特征的所有值
unique_vals = set(feat_list) # 获取该特征的所有不同值
new_entropy = 0.0 # 初始化新熵为0.0
split_info = 0.0 # 初始化分割信息为0.0
for value in unique_vals: # 对于该特征的每个不同值
sub_data_set = split_data_set(data_set, i, value) # 根据特征值划分数据集
prob = len(sub_data_set) / float(len(data_set)) # 计算划分后数据集的概率
new_entropy += prob * calc_shannon_entropy(sub_data_set) # 计算新熵并更新
split_info -= prob * log(prob, 2) # 更新分割信息
info_gain = base_entropy - new_entropy # 计算信息增益
if split_info == 0: # 如果分割信息为0,则跳过
continue
info_gain_ratio = info_gain / split_info # 计算信息增益比
if info_gain_ratio > best_info_gain_ratio: # 如果当前的信息增益比大于最佳信息增益比
best_info_gain_ratio = info_gain_ratio # 更新最佳信息增益比
best_feature = i # 更新最佳特征
return best_feature # 返回最佳特征的索引
# 创建决策树
def create_tree_C45(data_set, labels):
class_list = [example[-1] for example in data_set] # 获取数据集中所有样本的类别标签
if class_list.count(class_list[0]) == len(class_list): # 如果所有样本的类别标签都相同
return class_list[0] # 返回该类别标签作为决策树的叶节点
if len(data_set[0]) == 1: # 如果只剩下类别标签一个特征
return max(set(class_list), key=class_list.count) # 返回出现次数最多的类别标签作为叶节点
best_feature = choose_best_feature_to_split_C45(data_set) # 选择最佳特征
best_feature_label = labels[best_feature] # 获取最佳特征的名称
my_tree = {best_feature_label: {}} # 创建决策树的当前节点
del(labels[best_feature]) # 从特征名称列表中移除最佳特征
feat_values = [example[best_feature] for example in data_set] # 获取最佳特征的所有值
unique_vals = set(feat_values) # 获取最佳特征的所有不同值
for value in unique_vals: # 对于最佳特征的每个不同值
sub_labels = labels[:] # 获取剩余特征的副本
my_tree[best_feature_label][value] = create_tree_C45(split_data_set(data_set, best_feature, value), sub_labels) # 递归创建子树
return my_tree # 返回创建的决策树
# 中文数据集示例
data_set = [
['晴', '炎热', '高', '否', '是'], # 第一个样本
['晴', '炎热', '高', '是', '是'], # 第二个样本
['多云', '凉爽', '正常', '否', '否'], # 第三个样本
['雨', '凉爽', '正常', '否', '是'], # 第四个样本
['雨', '凉爽', '高', '是', '否'], # 第五个样本
['多云', '凉爽', '高', '否', '否'] # 第六个样本
]
labels = ['天气', '温度', '湿度', '有风', '是否打球'] # 特征名称列表
decision_tree_C45 = create_tree_C45(data_set, labels) # 使用C4.5算法创建决策树
print(decision_tree_C45) # 打印创建的决策树与ID3算法不同的是在选择最好的数据集划分特征时是通过信息增益率info_gain_ratio = info_gain / split_info来进行一个选择操作的。
运行结果:

四、实验总结
-
ID3算法实现:
- 实验首先采用ID3算法,该算法使用信息增益作为划分数据集的标准。通过计算每个特征的信息增益,选择信息增益最大的特征作为决策树的节点,递归地对数据集进行划分,直到满足停止条件。
- 实验中,我们计算了每个特征的信息增益,并选择了信息增益最大的“天气”特征作为根节点,然后对数据集进行了划分,并递归地构建了决策树。
-
C4.5算法实现:
- 鉴于ID3算法倾向于选择取值较多的属性,可能导致过拟合的问题,实验进一步采用了C4.5算法。C4.5算法通过计算信息增益率来选择特征,该指标在信息增益的基础上考虑了属性的分裂信息,从而更平衡地评估特征的重要性。
- 在C4.5算法的实现中,我们计算了每个特征的信息增益和分裂信息,进而得到了信息增益率,并选择了信息增益率最大的特征进行划分,构建了决策树。
- 遇到的问题:
(1)信息增益计算错误:
在初次计算信息增益时,错误地将一个属性的多个类别视为了一个类别,导致信息增益计算结果不准确。
解决过程:重新审视了信息增益的计算方法,确保对每个类别的概率进行了准确计算,并使用了正确的对数运算。
(2)递归函数编写复杂:
在实现递归创建决策树的函数时,由于逻辑复杂,难以确保每次递归都能正确处理数据集和返回结果。
解决过程:将递归函数简化,采用更清晰的代码结构,并添加了详细的注释来解释每一步的作用。
4. 实验结果:
- 实验结果显示,ID3和C4.5算法都能成功地构建决策树,并为给定的数据集提供了分类模型。两种算法在构建过程中的主要区别在于特征选择的标准不同,这影响了最终决策树的结构。
5.算法比较:
- ID3算法实现简单,易于理解,但倾向于选择取值多的特征,可能导致决策树过于复杂。
- C4.5算法在ID3的基础上进行了改进,通过信息增益率的选择标准,减少了过拟合的风险,并且能够处理连续属性和缺失值,提高了算法的适用性。
6.实验反思:
- 实验中,我们体会到了决策树算法在分类问题上的应用和效果,同时也认识到了不同决策树构建算法之间的差异和适用场景。
- 通过实验,我们了解到决策树虽然直观易懂,但在面对高维数据和噪声数据时可能会有局限性,因此在实际应用中需要根据具体情况选择合适的算法,并考虑采用剪枝等策略来优化模型。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









