






反绎学习
周志华2020CCF-GAIR演讲实录
1.逻辑推理与机器学习
1.1 逻辑推理
我们一般来说可以认为它是基于一阶逻辑规则的表示。这里我们看一个例子,这里面有三个子句,第一个字句:对于任意X和Y,如果X是Y的父母,那么X比Y年长;第二个字句:对于任何两个人,X是Y的妈妈,那么X就是Y的父母;第三:LuLu是FiFi的妈妈。现在如果我们问:谁更年长一些?那么如果从这样的一个逻辑系统,我们马上就可以知道,第三句话,我们知道Lulu是Fifi的妈妈,那么从第2句话我们就知道她是Fifi的父母。又从第1句话我们知道她肯定比Fifi年长。逻辑推理就是基于这样的一些逻辑规则描述出来的知识,来帮助我们做这样的推理判断。
1.2 机器学习
机器学习走的是另外一个路线。我们会收集很多的数据,比方说把这个数据组织成这么一个表格形式,每一行就是一个对象或者事件,每一列是刻画它的一个属性或特征,这就是所谓的“属性-值“表示形式。如果从逻辑的角度来看,这种表示是非常基础的命题逻辑的表示方式,可以把属性值表对应成逻辑真值表。而命题逻辑和硬件逻辑中间是有非常大的差别,很重要的就是有对于“任意”以及“存在”这样的量词会发生作用。一阶逻辑表示由于涉及量词,比方说如果要把“任意”这个量词拆开把每个可能的X当做一个样本,那就会变成无限大的样本集。如果把一阶逻辑中的谓词比方说“parent”当作一个属性,那么我们会发现,每个逻辑子句刻画的并不是某个样本,而是在刻画样本之间的某种关系。于是,当我们把谓词直接当做属性试图展开成普通数据集的时候,会发现数据集里甚至没有真正的属性-值的描述。
1.3 逻辑推理与机器学习的传统结合
逻辑推理非常容易来利用我们的知识, 而机器学习呢比较容易来利用数据、利用证据、事实。但是如果从人类决策来看,很多决策的时候同时要使用知识以及证据。那么这两者能不能很好地弄到一起去呢?
虽然很困难,但大家都知道,如果能把两者结合起来,可能会有更大的威力,因此历史上已经有很多研究者在做努力。我们可以归结是大致两个方向的努力。
-
一个方向主要是做逻辑推理方面的学者,尝试引入一些机器学习里面的基础的技术或者概念。我们举一个最简单的例子,每个逻辑子句是确定的:要么成立,要么不成立。我们现在可以给每个逻辑子句加上一个权重,一定程度上我们可以认为它反映这个子句成立的概率。比如说:如果一个人是大学三年级,另一个人是大学一年级,那么第一个人很可能比第二个人年长,这个可能性是80%。通过加一个0.8,我们就使得这个事实变成一个概率的成立。这样得到的带有概率权重的子句,就可以进行一定程度的概率推理。
-
另一个方向是从机器学习的角度,尝试把一些逻辑推理方面的东西引进来。比方说我们看到有这么一条子句,如果一个人他抽烟,那么他很有可能得癌症。有了这么一个知识,我们就可以在做贝叶斯网初始化的时候,把任何一个X,如果他smoke,我们就把它和cancer之间的这条边连起来,也就是说我们用这个初步的规则帮助我们做这个网络的初始化。初始化之后,原来贝叶斯网该怎么学就怎么学。
所以我们可以看上面这两大类做法。第一类,我们可以看到它是把机器学习往逻辑推理中引,但是后面主体还是通过推理来解决问题,所以我们称它是推理重而学习轻。第二种做法基本上是反过来,它把逻辑推理的技术往机器学习里面引,但是后期主要的解决问题是靠机器学习,所以我们称它是学习重而推理轻。总是一头重一头轻,这就意味着有一头的技术没有充分发挥威力。
因此, 最近提出了一个新的方案,叫做反绎学习(Abductive Learning)。
2.反绎学习
在人类对知识的处理上,或者说对现实问题的抽象上,我们通常有两种做法,即演绎(从一般到特殊)和归纳(从特殊到一般)
反绎的意思就是首先从一个不完备的观察出发,然后希望得到一个关于某一个我们特别关心的集合的最可能的解释。
2.1 一个小例子: 玛雅历法
直接理解这句话可能有困难。我们给出一个例子,是关于怎么去破译玛雅历法这么一个故事。
大家知道中美洲有一个古老的玛雅文明。他们建立起了非常复杂、精致的历法系统,具体是有三套历法。

左边这三个石柱子上画出了很多的图案,每个图案它会表达一个含义。
中间红色方框中间的5个图像对应了玛雅的一个历法叫做长历。这是一组看起来像是IP地址的数字,它实际是不严格的20进制,描述了一个日期,就是玛雅文明认为从创世开始一共经过了多少天。这里面第1个和第4个是什么含义还不知道,所以打了问号,第2个图像对应于18,第3个对应于5,最后一个对应于0。
接下来,蓝色框出来这两位,对应于玛雅的神历。左边图像的含义未知;右边这个符号已经知道代表一个东西叫做Ahau。这两位结合起来也代表了一天。
最后这两位是13 Mac,对应玛雅的太阳历,是说这一年第13个月第14天。
如果这三个历法里的问号都清楚了,那么这一天的定位就非常精确了。现在需要把这三个问号破译出来。我们有一个重要的知识:这三个历法系统,由于它们指的是同一天,那么揭示出来的这三个问号的值一定会使这三个计数达到一致。
那我们看看考古学家会怎么做这个事。拿到这个图像之后,他们首先根据以往破译图像的经验去“猜“ 这些数字是什么。但这很难,考古学家现在只知道这两个红色的应该是同一个数,蓝色的应该是另外一个数,但这个红色的既有可能是1,也有可能是8,也有可能是9。因为玛雅人刻石柱是手工而不是机器做的,每次都有变化。比方说大家看到最上面这个红色的图像,它好像和这个1最左边这个很像,和8的第二个也很像,跟9最右边的这个也比较像。
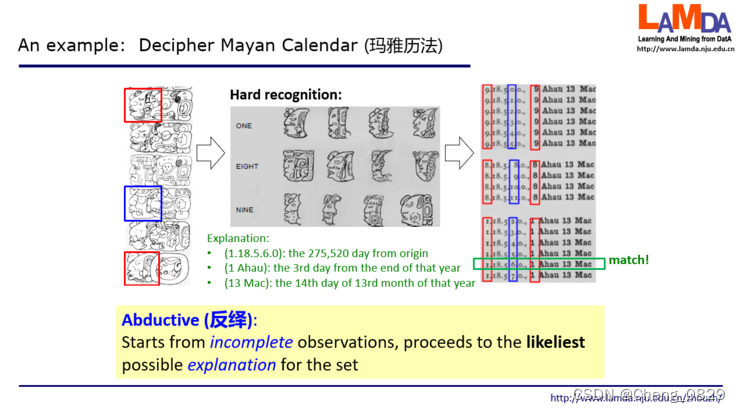
然后接下来考古学家做什么呢?他们把可能的情况全部展开。比方说如果我们认为红色的这个是1,那我们现在这个蓝色的就有几种可能,2 3 4 5 6 7这些可能都有,例如右边的最下面一行是1.18.5.7.0,这是从观察到的图像得出的猜测。也就是说从观测到的石柱,他们得出了这么几个可能的假设。接下来的一步,他们就要利用所掌握的知识来做判断。
所掌握的知识是告诉我们现在这三个历法系统,它对应的日期应该是同一天。这里恰好找到红色是1、蓝色是6的这一行,对应的破译结果是长历的创世以来第275520天,恰好是神历中一年的倒数第三天,也恰好是太阳历中第13个月的第14天,一切都一致了!于是,这就得到了结果。
这就是反绎的一个简单过程。
我们回顾一下,首先它来自一个不完备的观察,有的图像是什么我们知道,有的图像是什么我们不知道。然后基于这个观察,我们得到一个假设。有了这个假设之后,根据我们的知识来找一个最可能的解释。而这个解释就是现在红色,蓝色这个我们当前所关心的集合。这就是反绎的含义。
2.2 推广
我们从这个例子推广到机器学习。首先我们要有很多instance,这是我们的样本。我们要有很多label,这是关于训练样本的已经知道的结果。我们把它合起来做监督学习,训练出一个分类器。
反绎学习的设置不太一样。我们有一些样本,但只有样本的表现,不知道结果。这就类似于刚才在玛雅这个故事里面我们看到很多图像,但这个图像对应的含义是什么还不知道。反绎学习中假设有一个知识库,这就类似于刚才考古学家所拥有的关于历法的知识。同时我们还有一个初始分类器.
- 在这个学习中,我们先把所有的数据提供给这个初始分类器,这个初始分类器就会猜出一个结果,比方说红色的可能是1等等。
- 然后得到这个结果之后,我们就会把它转化成一个知识推理系统它能够接受的符号表示。比如说从这些label里面,得到了A,非B,非C等等。
- 那么接下来这一步,我们就要根据知识库里面的知识来发现有没有什么东西是不一致的?刚才在玛雅历法的故事里,第一轮就一致了,但在一般的任务中未必那么早就能发现一致的结果。
- 如果有不一致,我们能不能找到某一个东西,一旦修改之后它就能变成一致?这就是我们要去找最小的不一致。假设我们现在找到,只要把这个非C改成C,那么得到的事实就和知识都一致了。我们就把它改过来,这就是红色的这个部分。那这就是一个反绎的结果。
- 而反绎出来的这个C,我们现在会回到原来的label中,把这个label把它改掉,接下来我们就用修改过的label和原来的数据一起来训练一个新分类器。不断迭代下去,一直到分类器不发生变化,或者我们得到的事实和知识库完全一致,这时候就停止了。
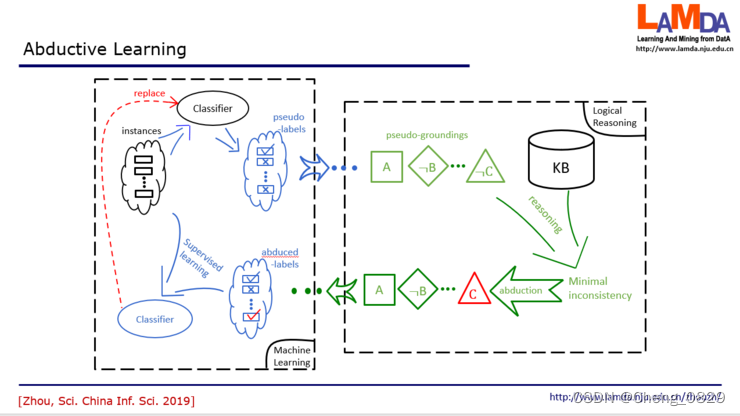
可以看到,左边这一半就是在做机器学习,而右边这一半是在做逻辑推理。而且,它不是说一头重一头轻,而是这两者互相依赖,一直这样循环处理的一个过程
Abductive Learning
1. Logical Reasoning and Machine learning
1.1 Logical reasoning
It is generally a representation based on first-order logic rules. Here we look at an example of three clauses, the first sentence: for any X and Y, if X is the parent of Y, then X is older than Y; For any two people, if X is Y’s mother, then X is Y’s parent. Third: LuLu is FiFi’s mother. Now if we ask: Who is older? So if from such a logical system, we immediately know that, in the third sentence, we know that Lulu is Fifi’s mother, then in the second sentence, we know that she is Fifi’s parent. We know from the first sentence that she is older than Fifi. Logical reasoning is based on the knowledge described by some logical rules to help us make such reasoning and judgment.
1.2 Machine learning
Machine learning goes the other way. We collect many data. For example, we organize this data into a table form, where each row is an object or event, and each column is a property or feature that characterizes it, called an “attribute-value” representation. From a logical point of view, this representation is a fundamental representation of propositional logic, which can correspond to the attribute value table as a logical truth table. There is a big difference between propositional logic and hardware logic, and it is essential that quantifiers such as “arbitrary” and “existence” operate. First-order logic says that because it involves quantifiers, for example, if we were to take apart the quantifier “any” and treat every possible X as a sample, we would have an infinite set of samples. Suppose we consider a predicate in first-order logic, such as “parent,” as an attribute. In that case, we will find that each logical clause does not describe a sample but rather a relationship between samples. Thus, when we try to expand the predicate directly as an attribute into a standard dataset, we find that there needs to be a fundamental property-value description.
1.3 Traditional Combinations of logical reasoning and machine learning
Logical reasoning is straightforward to use our knowledge, whereas machine learning is much easier to use data, evidence, and facts. However, if we look at human decision-making, much decision-making involves both knowledge and evidence. So can the two go together well?
It is challenging, but everyone knows combining the two can have more power, so many researchers have tried to do this throughout history. We can boil down to efforts in two broad directions.
-
One direction is to be a scholar of logical reasoning. tries to introduce some basic techniques or concepts in machine learning. Let us take the most straightforward example where every logical clause is deterministic: it either holds or does not. We can now attach a weight to each logical clause. To some extent, it reflects the probability that the clause is valid. For example, if one person is junior and the other is a freshman, there is an 80% chance that the first person is older than the second. By adding a 0.8, we make this fact a probability. In this way, the clauses with probability weights can be used for probabilistic reasoning to a certain extent.
-
Another direction is from the machine learning perspective, trying to bring in some logical reasoning. For example, if a person smokes, they are more likely to get cancer. With this knowledge, we can connect any X, if it is smoke, to the edge between it and cancer when we initialize the Bayesian network. We use this preliminary rule to help us initialize the network. After initialization, the original Bayesian network should learn how to learn.
So we can look at the two categories above. The first category introduces machine learning to logical reasoning. However, the later subject still uses reasoning to solve the problem, so we call it reasoning more important than learning. The second approach is the reverse. It introduces analytical reasoning techniques into machine learning. However, the main problem-solving in the later stage depends on machine learning, so we call it “learning is heavy, and reasoning is light.” It is always heavy on one side and light on the other, which means that the technology on one side needs to be fully used.
Therefore, recently a new scheme called Abductive Learning has been proposed.
2. Abductive Learning
In the process of human knowledge, or the abstraction of real problems, we usually have two methods, namely, deduction (from general to particular) and induction (from unique to general)
An inversion means starting from an incomplete observation and hoping to get the best possible explanation for a particular set we care about.
2.1 A small example: the Mayan calendar
It may be challenging to understand this sentence directly. Let us give an example of how to decipher the Mayan calendar.
We know there was an ancient Mayan civilization in Central America. They set up a very complex and elaborate calendar system: three calendars.
The three stone pillars on the left are painted with many patterns, each with meaning.
The five images in the middle of the red square correspond to a Mayan calendar called Long calendar. It is a set of numbers that look like IP addresses, but it is in base 20, loosely, and it describes a date, which is how many days the Mayans thought had passed since the world’s creation. The meaning of the first and fourth have yet to be discovered, so there is a question mark. The second graph corresponds to 18, the third to 5, and the last to 0.
Next, framed in blue, these two correspond to the Mayan calendar. The image’s meaning on the left is still being determined; The symbol on the right is already known to represent something called Ahau. Together, these two represent a day.
The last two are 13 Mac, corresponding to the Mayan solar calendar, the 14th day of the 13th month of the year.
The day is precisely positioned if the question mark in all three calendars is clear. Now we need to decipher the three question marks. We have a critical piece of knowledge: THESE three calendar systems, since they refer to the same day, then the revealed values of the three question marks must bring the three counts into agreement.
So let us see what archaeologists do with this. Given the image, they first tried to “guess” the numbers based on previous experience deciphering images. However, it is hard. All archaeologists know right now is that the two red ones should be the same number, and the blue ones should be another number, but the red ones could be one, eight, or nine. Because the Mayans carved the pillars by hand, not by machine, it changed every time. For example, if we look at the top red image, it looks a lot like the leftmost image of 1, the second image of 8, and the rightmost image of 9.
So what do archaeologists do next? They all the possible scenarios. For example, if the red one is 1, we have several possibilities for the blue one, including 2, 3, 4, 5, 6, and 7. For example, the bottom row on the right is 1.18.5.7.0, a guess from the observed image. They came up with several possible hypotheses from what they saw of the pillars. The next step is to use their knowledge to make judgments.
We know that all three calendar systems now correspond to the same date. Here happens to find the red is 1, the blue is 6 of this line, the corresponding deciphered result is the long calendar since the creation of the 275,520 days, which is exactly the third day of a year in the divine calendar, is also precisely the 13th month in the solar calendar of the 14th day, everything is consistent! So, this is the answer.
This is a simple process of inverse flow.
So let us review. First of all, it comes from an incomplete observation. Some of the images we know, and others we do not know. And then, based on that observation, we have a hypothesis. Given this hypothesis, let us look for the most likely explanation based on our knowledge. Moreover, that explanation is the red and blue set we are currently interested in. That is what the inverse flow means.
# # 2.2 Generalization
Let us generalize from this example to machine learning. First, we will have many instances, so this is our sample. We will have many labels, which are the known results of the training samples. We put it all together to do supervised learning to train a classifier.
The setting is quite different. We have some samples, but only the performance of the samples. We do not know the results. It is similar to what we saw in the story of the Maya, where we saw many images, but we needed to know what that images meant. Inverse learning assumes a knowledge base similar to archaeologists’ knowledge about calendars. We also have an initial classifier.
- In this learning, we first provide all the data to the initial classifier, which will guess a result. For example, red may be one.
- After obtaining this result, we transform it into a symbolic representation that a knowledge inference system can accept. From these labels, we get A, not B or C.
- In the next step, we need to find out what is inconsistent according to the knowledge in the knowledge bank. In the story of the Mayan calendar, there was agreement on the first round, but it is only sometimes possible to find agreement early on in everyday tasks.
- If there are inconsistencies, can we find something that, once modified, becomes consistent? That is where we are going to find the slightest inconsistency. If we now find, change this not C to C, we have the same facts as the knowledge. So let us change it, so this is the red part. So this is an inverse flow.
- For the C, we will return to the original label and change the label. Next, we will train a new classifier using the modified label and the original data. We keep iterating until either the classifier does not change, or the facts we get are the same as the knowledge base, and then we stop.
As we can see, the left half is machine learning, and the right is doing logical reasoning. Moreover, it does not mean that one is heavy and the other is light. It means that the two are interdependent, and the two are constantly in a cycle.















 1314
1314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









