







课程
原课程链接:https://www.freecodecamp.org/chinese/learn/data-analysis-with-python/
我现在卡在第三个了,做不下去了,先搁这吧,分享一下做的笔记~

Jupyter Notebook安装
安装
jupyter notebook官网:Project Jupyter | Installing Jupyter
在Windows终端中输入:
pip install notebook
启动jupyter notebook:
jupyter notebook
常用快捷键
notebook中单元格有两种模式:编辑模式(edit mode)和命令模式(command mode),在编辑模式下可以编辑代码,在命令模式下运行代码。
| 【ESC】 | 切换到命令模式 | 【Enter】 | 切换到编辑模式 |
|---|---|---|---|
| 【M】 | 命令模式下切换单元格为Markdown | 【Y】 | 命令模式下切换单元格为Code |
| 【A】 | 在当前单元格上方(Above)新建单元格 | 【B】 | 在当前单元格下方(Below)新建单元格 |
| 【Ctrl-Enter】 | 运行当前单元格 | 【Shift-Enter】 | 运行当前单元格并选中下个单元格 |
| 双击【D】 | (命令模式下)删除单元格 | 【C】【V】 | 复制 粘贴 |
Numpy
vectorization, indexing, and broadcasting
Numpy数组
1、创建numpy数组、索引:
>>>b = np.array([0, .5, 1, 1.5, 2])
>>>b[0],b[2]
(0.0,1.0)
>>>b[1:-1]
array([0.5, 1. , 1.5])
>>>b[::2]
array([0., 1., 2.])
>>>b[[0,2,-1]]
array([0., 1., 2.])
>>># create an array filled with 0’s
>>>np.zeros(2)
array([0., 0.])
>>># create an array filled with 1’s
>>>np.ones(3)
array([1., 1., 1.])
>>># create an array with a range of elements
>>>np.arange(4)
array([0, 1, 2, 3])
>>># (first number, last number, step size)
>>>np.arange(2, 9, 2)
array([2, 4, 6, 8])
2、 指定数据类型(float, int64, int32, int16)
>>>x = np.ones(2, dtype=np.int16)
array([1, 1], dtype=int16)
>>>x.itemsize
2
>>>#x.itemsize * x.size
>>>x.nbytes
4
3、多维数组
>>>A = np.array([
[1,2,3],
[4,5,6]
])
>>>A.shape
(2,3)
>>>A.ndim
2
>>>A.size
6
>>>A[0] = 1
>>>A
array([[1, 1, 1],
[4, 5, 6]])
Numpy运算
1、Broadcasting
>>> 简单例子:numpy数组与标量值组合
>>> a = np.array([0,1,2,3])
>>> b = 10
>>> a*b
array([ 0, 10, 20, 30])
>>> a + b
array([10, 11, 12, 13])
>>> c = np.array([10,10,10,10])
>>>a*c
array([ 0, 10, 20, 30])
>>>a #注意,a本身没有改变
array([0, 1, 2, 3])
ab is more efficient than ac because broadcasting moves less memory around during the multiplication (bis a scalar rather than an array). (参考numpy文档)
2、线性代数 linear algebra
>>> A = np.array([
[1,2,3],
[4,5,6],
[7,8,9]
])
>>>B = np.array([
[6,5],
[4,3],
[2,3]
])
>>>A.dot(B) # 两个数组的点积
array([[20, 20],
[56, 53],
[92, 86]])
>>>A @ B # @运算符:计算二维数组之间的矩阵乘积
array([[20, 20],
[56, 53],
[92, 86]])
>>>B.T # 矩阵转置
array([[6, 4, 2],
[5, 3, 3]])
Numpy布尔值的数组
>>>a = np.arange(4)
>>>a[0],a[-1]
(0, 3)
>>># 使用布尔列表对数组元素进行筛选
>>>a[[True,False,False,True]]
array([0, 3])
>>># 创建一个布尔数组
>>>a >= 2
array([False,False,True,True])
>>>a[a>=2]
array([2, 3])
>>>a.mean()
1.5
>>># 筛选大于均值的元素
>>>a[a>a.mean()]
array([2, 3])
>>># 筛选小于等于均值的元素
>>>a[~(a>a.mean())]
array([0, 1])
Why is Numpy Faster?
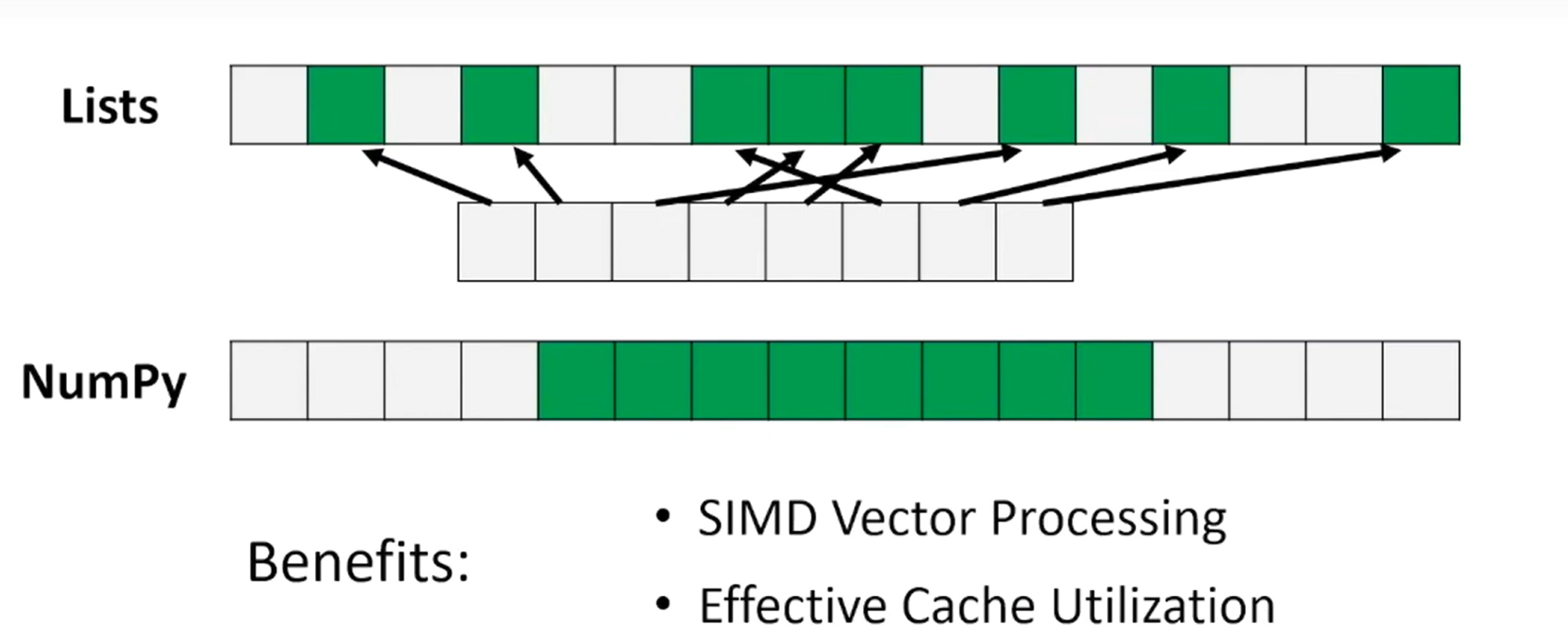
- fixed type:numpy数组元素具有固定大小且使用更少的内存,而电脑在读取更少的内存字节时速度更快;另一个原因是在遍历对象时没有类型检查。
>>>sys.getsizeof([1]) #含有一个元素的列表的大小(字节)
64
>>>np.array([1]).nbytes #含有一个元素的数组的大小(字节)
4
- contiguous memory
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZPTiEqX4-1680601842029)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/ea7d16e3-1af6-4985-8c4d-f0e47533f91d/Untitled.png)]
SIMD(Single Instruction Multiple Data):对批量的数据同时进行同样的操作以提高效率; 较高的缓存利用率
Pandas
Pandas Series
>>>g7_pop = pd.Series([35.467,63.951,80.940,60.665,127.061,64.511,318.523])
>>>g7_pop.values
array([ 35.467, 63.951, 80.94 , 60.665, 127.061, 64.511, 318.523])
>>>type(g7_pop.values) # numpy.ndarray
>>>g7_pop[0] # 类似于python列表,可以通过索引获取数据
>>>g7_pop.index = [ # 但与list类型不同的是,Series类型可以定义索引
'Canada',
'France',
'Germany',
'Italy',
'Japan',
'United Kingdom',
'United States']
>>>g7_pop
Canada 35.467
France 63.951
Germany 80.940
Italy 60.665
Japan 127.061
United Kingdom 64.511
United States 318.523
Name: G7 Population in millions, dtype: float64
>>> pd.Series({ # Series类型的对象看起来像“有序字典”,实际上,可以通过字典来创建Series
'Canada':35.467,
'France':63.951,
'Germany':80.940,
'Italy': 60.665,
'Japan':127.061,
'United Kingdom':64.511,
'United States':318.523
})
>>> #put it all together
>>>pd.Series([35.467, 63.951, 80.94 , 60.665, 127.061, 64.511, 318.523],
index=['Canada','France','Germany','Italy','Japan','United Kingdom','United States'],
name = "G7 Population in millions")
Pandas Series索引和条件选择
>>> g7_pop['Canada'] # 通过index进行索引
35.467
>>>g7_pop.loc['Canada'] #使用loc和index进行索引
>>>g7_pop.iloc[0] #使用iloc和数值进行索引
>>>g7_pop[['Canada','France']] # 一次筛选多个元素
>>>g7_pop.iloc[[0,1]]
>>>g7_pop['Canada':'Italy'] # 注意这里,'Italy'包含在返回的结果中
>>>g7_pop.iloc[0:3] # 但是这里,index=3的记录不包含在返回的结果,同python列表
# 条件选择
>>>g7_pop > 70 # boolean series
Canada False
France False
Germany True
Italy False
Japan True
United Kingdom False
United States True
Name: G7 Population in millions, dtype: bool
>>>g7_pop[g7_pop > 70] # 条件选择
Germany 80.940
Japan 127.061
United States 318.523
Name: G7 Population in millions, dtype: float64
>>>#选取人口数大于均值的元素
>>>g7_pop[g7_pop > g7_pop.mean()]
#修改元素值
>>>g7_pop['Canada'] = 48.5
Pandas DataFrames
>>>df = pd.DataFrame({
'Population':[35.467,63.951,80.94,60.665,127.061,64.511,318.523],
'GDP':[17892742,1232423,34231421,12431344,124342,45235235,4524525],
'Surface Area':[3423425,546342,235254,2352354,5425242,23525,674322],
'HDI':[0.913,0.888,0.916,0.873,0.891,0.907,0.915],
'Continent':['America','Europe','Europe','Europe','Asia','Europe','America']
})
>>>df
Population GDP Surface Area HDI Continent
0 35.467 17892742 3423425 0.913 America
1 63.951 1232423 546342 0.888 Europe
2 80.940 34231421 235254 0.916 Europe
3 60.665 12431344 2352354 0.873 Europe
4 127.061 124342 5425242 0.891 Asia
5 64.511 45235235 23525 0.907 Europe
6 318.523 4524525 674322 0.915 America
>>># 重新设置索引列
>>>df.index = ['Canada','France','Gernmany','Italy','Japan','United Kingdom','United States']
Population GDP Surface Area HDI Continent
Canada 35.467 17892742 3423425 0.913 America
France 63.951 1232423 546342 0.888 Europe
Gernmany 80.940 34231421 235254 0.916 Europe
Italy 60.665 12431344 2352354 0.873 Europe
Japan 127.061 124342 5425242 0.891 Asia
United Kingdom 64.511 45235235 23525 0.907 Europe
United States 318.523 4524525 674322 0.915 America
>>>df.columns # 获取表头
Index(['Population', 'GDP', 'Surface Area', 'HDI', 'Continent'], dtype='object')
>>>df.index # 获取索引列
>>>df.info # 获取表信息
>>>df.size # 获取表中数据个数
>>>df.shape # 获取表的大小,(行数,列数)
>>>df.describe() # 数字类型列的统计信息
Population GDP Surface Area HDI
count 7.000000 7.000000e+00 7.000000e+00 7.000000
mean 107.302571 1.652458e+07 1.811495e+06 0.900429
std 97.249970 1.733628e+07 2.021763e+06 0.016592
min 35.467000 1.243420e+05 2.352500e+04 0.873000
25% 62.308000 2.878474e+06 3.907980e+05 0.889500
50% 64.511000 1.243134e+07 6.743220e+05 0.907000
75% 104.000500 2.606208e+07 2.887890e+06 0.914000
max 18.523000 4.523524e+07 5.425242e+06 0.916000
# Indexing
>>>df['Population'] # 选取Population列
>>>df.loc['Canada'] # 选取Canada行
>>>df.loc['France':'Italy'] # 选取France到Italy的行,Italy这一行是包括在里面的
>>>df.iloc[-1] # 选取最后一行
>>>df.loc['France':'Italy','Population':'HDI'] # df.loc[dim1,dim2]
Population GDP Surface Area HDI
France 63.951 1232423 546342 0.888
Gernmany 80.940 34231421 235254 0.916
Italy 60.665 12431344 2352354 0.873
Pandas 条件选择和DataFrames的修改
# 条件选择
>>>df['Population']>70
Canada False
France False
Gernmany True
Italy False
Japan True
United Kingdom False
United States True
Name: Population, dtype: bool
>>>df.loc[df['Population']>70] # 选择人口数大于70(百万)的国家
Population GDP Surface Area HDI Continent
Gernmany 80.940 34231421 235254 0.916 Europe
Japan 127.061 124342 5425242 0.891 Asia
United States 318.523 4524525 674322 0.915 America
>>>df.loc[df['Population']>70,'Population':'HDI'] # 同时对行和列进行选择
Population GDP Surface Area HDI
Gernmany 80.940 34231421 235254 0.916
Japan 127.061 124342 5425242 0.891
United States 318.523 4524525 674322 0.915
# 丢弃值
>>>df.drop('Canada') # 通过索引
>>>df.drop(columns=['Population','HDI']) # drop columns
# Broadcasting operation
>>>crisis = pd.Series([-1_000_000,-0.3],index=['GDP','HDI'])
>>>df[['GDP','HDI']] + crisis # Dataframe和Series对象相加,前者的columns和后者的index一致
# Modifying DataFrames
>>>langs = pd.Series(
['French','Germany','Italy'],
index = ['France','Gernmany','Italy'],
name = 'Language'
)
>>>df['Language'] = langs
>>>df
Population GDP Surface Area HDI Continent Language
Canada 35.467 17892742 3423425 0.913 America NaN
France 63.951 1232423 546342 0.888 Europe French
Gernmany 80.940 34231421 235254 0.916 Europe Germany
Italy 60.665 12431344 2352354 0.873 Europe Italy
Japan 127.061 124342 5425242 0.891 Asia NaN
United Kingdom 64.511 45235235 23525 0.907 Europe NaN
United States 318.523 4524525 674322 0.915 America NaN
# 其他未赋值的行填充为NaN
DataFrame 创建列
>>>df['GDP']/df['Population'] # Series类型
>>>df['GDP Per Capita'] = df['GDP'] / df['Population'] # Creating columns from other columns
Matplotlib
数据分析
数据清理
数据清理的四个步骤
1、处理缺失数据: 识别与修复
>>>import pandas as pd
>>># 1.pandas有一些函数来识别缺失值
>>># pd.isnull() pd.isna()可以用来识别缺失值
>>># pd.notnull() pd.notna()可以用来识别有效值
>>>pd.isnull(np.nan)
True
>>>pd.isnull(None)
True
>>>pd.notnull(3)
True
>>>pd.notnull(pd.Series([1,np.nan,7]))
0 True
1 False
2 True
dtype: bool
>>>pd.isnull(pd.DataFrame({
'Column A':[1,np.nan,2],
'Column B':[np.nan,np.nan,2],
'Column C':[1,np.nan,np.nan],
}))
Column A Column B Column C
0 False True False
1 True True True
2 False False True
# 2.过滤掉缺失值
>>>s = pd.Series([1,2,3,np.nan,np.nan,4])
>>>pd.notnull(s).sum() # 计算非空值的个数
4
>>># 布尔值存储为整型,所以计算布尔数组的和即可以得到值为True的个数
>>>s[pd.notnull(s)] # (1)过滤掉无效值
0 1.0
1 2.0
2 3.0
5 4.0
dtype: float64
>>>s.notnull() #notnull等 也是Series和DataFrame类型对象的方法
0 True
1 True
2 True
3 False
4 False
5 True
dtype: bool
>>>s[s.notnull()] # (2) 过滤掉无效值
>>>s.dropna() # (3) 过滤掉无效值 前两种方法和这种方法比起来显得冗长和重复
从CSV和TXT中读取数据
使用read_csv()方法从CSV中读取数据
>>>import pandas as pd
>>>df = pd.read_csv('btc-market-price.csv',header = None)
>>>df.head()
0 1
0 2/4/17 0:00 1099.169125
1 3/4/17 0:00 1141.813
2 4/4/17 0:00 ?
3 5/4/17 0:00 1133.079314
4 6/4/17 0:00 -
>>>df = pd.read_csv('btc-market-price.csv',
header = None,
na_values = ['','-','?'], # 使用na_values设置指定值为Nan
names = ['Timestamp','Price'], # 表头
dtype = {'Price':'float'})) # 设置数据类型
Timestamp Price
0 2/4/17 0:00 1099.169125
1 3/4/17 0:00 1141.813000
2 4/4/17 0:00 NaN
3 5/4/17 0:00 1133.079314
4 6/4/17 0:00 NaN
>>>df['Timestamp'] = pd.to_datetime(df['Timestamp']) # 对时间列的处理: to_datetime()
>>>df = pd.read_csv('btc-market-price.csv',
header = None,
na_values = ['','-','?'],
names = ['Timestamp','Price'],
dtype = {'Price':'float'},
parse_dates = [0], # 使用 parse_date 参数处理日期列
index_col = [0]) # 使用 index_col 参数设置索引列
# 更多参数-----------------------------------------
# 有的csv文件以'>'作为分隔符,需要设置sep参数 如sep='>'
# skiprows = 2 跳过前两行(包括列名行); skiprows = [1,3] 跳过第一行、第三行(表头行为第零行)
# skip_blank_lines=False 空行被加载为NaN, 默认为True即忽略空行
>>># 加载特定列
>>>pd.read_csv('exam_review.csv',sep='>',usecols=['first_name','last_name','age'])
>>>pd.read_csv('exam_review.csv',sep='>',usecols=[0,1,2]) # 使用数字代替列名
>>>df.to_csv('out.csv',index=None) # 保存数据到csv文件里















 2452
2452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









