







第九章 图像分割
图像分割可将一幅图像分割成有意义的区域,区域可以是图像的前景与背景或图像中一些单独的对象。区域可以利用一些诸如颜色、边界或近邻相似性等特征进行构建。
9.1 图割
图论中的图由若干节点和连接节点的边构成,分为有向图和无向图,并可能有与边相关联的权重。
图割的定义:图割是将一个有向图分割成两个互不相交的集合,可以解决很多计算机视觉方面的问题。
图割的基本思想:相似且彼此相近的像素应该划分到同一区域。
图割C(C是图中所有边的集合)的“代价”函数定义为所有割的边的权重求和相加:
E
c
u
t
=
∑
(
i
,
j
)
∈
C
w
i
j
E_{c u t}=\sum_{(i, j) \in C} w_{i j}
Ecut=(i,j)∈C∑wij
w
i
j
w_{ij}
wij是图中节点i到节点j的边(i,j)的权重,并且是对割C所有的边进行求和。
图割图像分割的思想是用图来表示图像,并对图进行划分以使割代价 E c u t E_{cut} Ecut最小。
在用图表示图像时,增加两个额外的节点,即源点和汇点,并仅考虑那些将源点和汇点分开的割。
寻找最小割等同于在源点和汇点间寻找最大流。
例如,下面的一个计算一幅较小的图的最大流、最小割的简单例子:
先创建有4个节点的有向图,4个节点的索引分别0…3,然后添边并为每条边指定特定的权重。边的权重用来衡量边的最大流容量。如图所示:

from pygraph.classes.digraph import digraph
from pygraph.algorithms.minmax import maximum_flow
gr = digraph()
gr.add_nodes([0,1,2,3])
gr.add_edge((0,1), wt=4)
gr.add_edge((1,2), wt=3)
gr.add_edge((2,3), wt=5)
gr.add_edge((0,2), wt=3)
gr.add_edge((1,3), wt=4)
flows,cuts = maximum_flow(gr, 0, 3)
print('flow is:' , flows)
print('cut is:' , cuts)
0是包含图源点的部分,1是与汇点相连的节点。
得到的运行结果是:
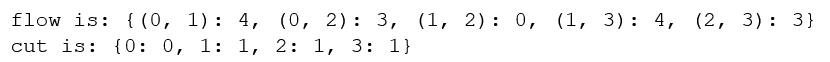

黑色最大流为4,红色为3,黄色为0,因此最大流为4+3+0=7

最小割为{0}、{1,2,3}
9.1.1 从图像创建图
给定一个邻域结构,可以利用图像像素作为节点定义一个图,除像素节点外,还需两个特定的节点——源点和汇点,分别代表图像的前景和背景,利用一个模型将所有像素与源点、汇点连接起来。
创建这样一个图的步骤:
每个像素节点都有一个从源点的传入边;
每个像素节点都有一个到汇点的传出边;
每个像素节点都有一条传入边和传出边连接到它的近邻。
为确定边的权重,需要一个能够确定这些像素点之间,像素点与源点、汇点之间边的权重(表示那条边的最大流)的分割模型。
像素i与像素j之间的边的权重记为wij,源点到像素i的权重记为wsj,像素i到汇点的权重记为wit
假定已经在前景和背景像素上训练出了一个贝叶斯分类器,就可以为前景和背景计算概率pF(Ii)和pB(Ii),其中,Ii是像素i的颜色向量。
w
s
i
=
p
F
(
I
i
)
p
F
(
I
i
)
+
p
B
(
I
i
)
w
i
t
=
p
B
(
I
i
)
p
F
(
I
i
)
+
p
B
(
I
i
)
w
i
j
=
κ
e
−
∣
l
i
−
I
j
∣
2
/
σ
\begin{aligned} w_{s i} &=\frac{p_{F}\left(I_{i}\right)}{p_{F}\left(I_{i}\right)+p_{B}\left(I_{i}\right)} \\ w_{i t} &=\frac{p_{B}\left(I_{i}\right)}{p_{F}\left(I_{i}\right)+p_{B}\left(I_{i}\right)} \\ w_{i j} &=\kappa \mathrm{e}^{-\left|l_{i}-I_{j}\right|^{2 / \sigma}} \end{aligned}
wsiwitwij=pF(Ii)+pB(Ii)pF(Ii)=pF(Ii)+pB(Ii)pB(Ii)=κe−∣li−Ij∣2/σ利用该模型,可以将每个像素的前景和背景(源点和汇点)连接起来,权重等于上面归一化后的概率。
wij描述了近邻间像素的相似性,相似像素权重趋近于κ,不相似的趋近于0,参数
σ
\sigma
σ表征了随着不相似性的增加,指数次幂衰减到0的快慢。
实例
创建名为graphcut.py的文件,用1标记前景训练数据,用-1标记背景训练数据的一幅标记图像。基于这种标记,在RGB值上可以训练出一个朴素贝叶斯分类器,然后计算每一像素的分类概率,这些计算出的分类概率就是从源点出来和到汇点去的边的权重,由此可以创建一个节点为n×m+2的图,为了简化像素的索引,我们将最后的两个索引作为源点和汇点的索引。
为了在图像上可视化覆盖的标记区域,可以利用contourf()函数填充图像等高线间的区域,参数alpha用于设置透明度。
图建立起来后便需要在最优位置对图进行分割,可以利用cut_graph()函数计算最小割并将输出结果重新格式化为一个带像素标记的二值图像。
综上,graphcut.py的文件为:
from pylab import *
from numpy import *
from pygraph.classes.digraph import digraph
from pygraph.algorithms.minmax import maximum_flow
import bayes
"""
Graph Cut image segmentation using max-flow/min-cut.
"""
def build_bayes_graph(im,labels,sigma=1e2,kappa=1):
""" Build a graph from 4-neighborhood of pixels.
Foreground and background is determined from
labels (1 for foreground, -1 for background, 0 otherwise)
and is modeled with naive Bayes classifiers."""
m,n = im.shape[:2]
# RGB vector version (one pixel per row)
vim = im.reshape((-1,3))
# RGB for foreground and background
foreground = im[labels==1].reshape((-1,3))
background = im[labels==-1].reshape((-1,3))
train_data = [foreground,background]
# train naive Bayes classifier
bc = bayes.BayesClassifier()
bc.train(train_data)
# get probabilities for all pixels
bc_lables,prob = bc.classify(vim)
prob_fg = prob[0]
prob_bg = prob[1]
# create graph with m*n+2 nodes
gr = digraph()
gr.add_nodes(range(m*n+2))
source = m*n # second to last is source
sink = m*n+1 # last node is sink
# normalize
for i in range(vim.shape[0]):
vim[i] = vim[i] / (linalg.norm(vim[i]) + 1e-9)
# go through all nodes and add edges
for i in range(m*n):
# add edge from source
gr.add_edge((source,i), wt=(prob_fg[i]/(prob_fg[i]+prob_bg[i])))
# add edge to sink
gr.add_edge((i,sink), wt=(prob_bg[i]/(prob_fg[i]+prob_bg[i])))
# add edges to neighbors
if i%n != 0: # left exists
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i-1])**2)/sigma)
gr.add_edge((i,i-1), wt=edge_wt)
if (i+1)%n != 0: # right exists
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i+1])**2)/sigma)
gr.add_edge((i,i+1), wt=edge_wt)
if i//n != 0: # up exists
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i-n])**2)/sigma)
gr.add_edge((i,i-n), wt=edge_wt)
if i//n != m-1: # down exists
edge_wt = kappa*exp(-1.0*sum((vim[i]-vim[i+n])**2)/sigma)
gr.add_edge((i,i+n), wt=edge_wt)
return gr
def cut_graph(gr,imsize):
""" Solve max flow of graph gr and return binary
labels of the resulting segmentation."""
m,n = imsize
source = m*n # second to last is source
sink = m*n+1 # last is sink
# cut the graph
flows,cuts = maximum_flow(gr,source,sink)
# convert graph to image with labels
res = zeros(m*n)
for pos,label in list(cuts.items())[:-2]: #don't add source/sink
res[pos] = label
return res.reshape((m,n))
def save_as_pdf(gr,filename,show_weights=False):
from pygraph.readwrite.dot import write
import gv
dot = write(gr, weighted=show_weights)
gvv = gv.readstring(dot)
gv.layout(gvv,'fdp')
gv.render(gvv,'pdf',filename)
def show_labeling(im,labels):
""" Show image with foreground and background areas.
labels = 1 for foreground, -1 for background, 0 otherwise."""
imshow(im)
contour(labels,[-0.5,0.5])
contourf(labels,[-1,-0.5],colors='b',alpha=0.25)
contourf(labels,[0.5,1],colors='r',alpha=0.25)
#axis('off')
xticks([])
yticks([])
比如下面的例子,将读取一幅图像,从图像的两个矩形区域估算出类概率,然后创建一个图:
代码为:
#运行速度较慢
from scipy.misc import imresize
import graphcut
from PIL import Image
from pylab import *
im = array(Image.open("empire.jpg"))
im = imresize(im, 0.07)
size = im.shape[:2]
# add two rectangular training regions
labels = zeros(size)
labels[3:18, 3:18] = -1
labels[-18:-3, -18:-3] = 1
# create graph
gr = graphcut.build_bayes_graph(im, labels,sigma=1e2,kappa=10)
# cut the graph
res = graphcut.cut_graph(gr, size)
# figure()
# graphcut.show_labeling(im, labels)
figure()
imshow(res)
gray()
axis('off')
show()
得到的运行结果为:

k=1:

k=3:

k=5:

变量kappa(方程中的K)决定了近邻像素间边的相对权重。随着K值增大,分割边界将变得更平滑,并且细节部分也逐步丢失。
9.1.2 用户交互式分割
利用一些方法将图像分割与用户交互结合起来。
首先定义一个辅助函数用以读取这些标注图像,格式化这些标注图像便于将其传递给背景和前景训练模型函数,矩形框中只包含背景标记。下一步创建图并分割,由于有用户输入,所以以处那些在标记背景区域里有任何前景的结果。最后绘制出分割结果,并通过设置这些勾选标记到一个空列表来移去这些勾选标记。这样就可以得到一个很好的边框。
代码为:
# -*- coding: utf-8 -*-
from scipy.misc import imresize
import graphcut
from numpy import *
from PIL import Image
def create_msr_labels(m,lasso=False):
""" 从用户的注释中创建用于训练的标记矩阵 """
labels = zeros(im.shape[:2])
# 背景
labels[m==0] = -1
labels[m==64] = -1
#前景
if lasso:
labels[m == 255] = 1
else:
labels[m == 128] = 1
return labels
# 载入图像和注释图
im = array(Image.open('1.jpg'))
m = array(Image.open('1.bmp'))
# 调整大小
scale = 0.1
im = imresize(im, scale, interp='bilinear')
m = imresize(m, scale, interp='nearest')
# 创建训练标记
labels = create_msr_labels(m,False)
# 用注释创建图
g = graphcut.build_bayes_graph(im, labels, kappa=1)
# 图割
res = graphcut.cut_graph(g, im.shape[:2])
# 去除背景部分
res[m==0] = 1
res[m==64] = 1
# 绘制分割结果
figure()
imshow(res)
gray()
xticks([])
yticks([])
savefig('1.pdf')
ValueError: too many values to unpack (expected 2)
有报错,还未解决
9.2 利用聚类进行分割
上一节中的图割问题通过在图像的图上利用最大流、最小割找到了一种离散解决方案,本节中,将使用基于谱图理论的归一化分割算法,将像素相似和空间近似结合起来对图像进行分割。
该方法来自定义一个分割损失函数,该损失函数不仅考虑了组的大小而且还用划分的大小对该损失函数进行“归一化”。归一化后的分割损失函数为:
E
n
c
u
t
=
E
c
u
t
∑
i
∈
A
w
i
x
+
E
c
u
t
∑
j
∈
B
w
j
x
E_{n c u t}=\frac{E_{c u t}}{\sum_{i \in A} w_{i x}}+\frac{E_{c u t}}{\sum_{j \in B} w_{j x}}
Encut=∑i∈AwixEcut+∑j∈BwjxEcut
A和B表示两个割集,并在图中分别对A和B中所有其他节点的权重求和相加,相加求和项称为association。
定义W为边的权重矩阵,矩阵中的元素wij为连接像素i和像素j边的权重,D为对W每行元素求和后构成的对角矩阵,即
D
=
d
i
a
g
(
d
i
)
D=diag(d_i)
D=diag(di),
d
i
=
Σ
j
w
i
j
d_i=\Sigma_{j}w_{ij}
di=Σjwij,归一化分割可以通过最小化下面的优化问题而求得:
min
y
y
T
(
D
−
W
)
y
y
T
D
y
\min _{y} \frac{\mathbf{y}^{T}(\boldsymbol{D}-\boldsymbol{W}) \mathbf{y}}{\mathbf{y}^{T} \boldsymbol{D} \mathbf{y}}
yminyTDyyT(D−W)y向量y包含的是离散标记,这些离散标记满足对于b为常数
y
i
∈
1
,
−
b
y_i∈{1,-b}
yi∈1,−b的约束,
y
T
D
y^TD
yTD求和为0.通过松弛约束条件并让y取任意实数,该问题可以变为一个容易求解的特征分解问题。松弛该问题后,该问题便成为求解拉普拉斯矩阵特征向量问题:
L
=
D
−
1
/
2
W
D
−
1
/
2
L=D^{-1/2}WD^{-1/2}
L=D−1/2WD−1/2
接下来的工作是如何定义像素间边的权重wij
利用原始归一化割中的边的权重,通过下式给出连接像素i和像素j的边的权重:
w
i
j
=
e
−
∣
l
i
−
I
j
β
f
/
σ
8
e
−
∣
x
i
−
x
j
β
/
σ
d
w_{i j}=\mathrm{e}^{-\mid l_{i}-I_{j} \beta^{f / \sigma_{8}}} \mathrm{e}^{-\mid x_{i}-x_{j}{ }^{\beta} / \sigma_{d}}
wij=e−∣li−Ijβf/σ8e−∣xi−xjβ/σd创建ncut.py文件来体现上面的叙述:
from PIL import Image
from pylab import *
from numpy import *
from scipy.cluster.vq import *
def cluster(S,k,ndim):
""" Spectral clustering from a similarity matrix."""
# check for symmetry
if sum(abs(S-S.T)) > 1e-10:
print('not symmetric')
# create Laplacian matrix
rowsum = sum(abs(S),axis=0)
D = diag(1 / sqrt(rowsum + 1e-6))
L = dot(D,dot(S,D))
# compute eigenvectors of L
U,sigma,V = linalg.svd(L,full_matrices=False)
# create feature vector from ndim first eigenvectors
# by stacking eigenvectors as columns
features = array(V[:ndim]).T
# k-means
features = whiten(features)
centroids,distortion = kmeans(features,k)
code,distance = vq(features,centroids)
return code,V
def ncut_graph_matrix(im,sigma_d=1e2,sigma_g=1e-2):
""" Create matrix for normalized cut. The parameters are
the weights for pixel distance and pixel similarity. """
m,n = im.shape[:2]
N = m*n
# normalize and create feature vector of RGB or grayscale
if len(im.shape)==3:
for i in range(3):
im[:,:,i] = im[:,:,i] / im[:,:,i].max()
vim = im.reshape((-1,3))
else:
im = im / im.max()
vim = im.flatten()
# x,y coordinates for distance computation
xx,yy = meshgrid(range(n),range(m))
x,y = xx.flatten(),yy.flatten()
# create matrix with edge weights
W = zeros((N,N),'f')
for i in range(N):
for j in range(i,N):
d = (x[i]-x[j])**2 + (y[i]-y[j])**2
W[i,j] = W[j,i] = exp(-1.0*sum((vim[i]-vim[j])**2)/sigma_g) * exp(-d/sigma_d)
return W
现在利用该算法,在一些样本图像上进行测试:
# -*- coding: utf-8 -*-
import ncut
import cv2
import numpy as np
from pylab import *
from PIL import Image
from scipy.misc import imresize
im = array(Image.open('empire.jpg'))
m,n = im.shape[:2]
# 调整图像的尺寸大小为 (wid,wid)
wid = 50
rim = imresize(im,(wid,wid),interp='bilinear')
rim = array(rim,'f')
# 创建归一化割矩阵
A = ncut.ncut_graph_matrix(rim,sigma_d=1,sigma_g=1e-2)
# 聚类
code,V = ncut.cluster(A,k=3,ndim=3)
# 变换到原来的图像大小
codeim = imresize(code.reshape(wid,wid),(m,n),interp='nearest')
# 绘制分割结果
figure()
imshow(codeim)
gray()
show()
运行结果为:




9.3 变分法
当优化的对象是函数时,优化问题称为变分问题,解决这类问题的算法称为变分法。
如果用一组曲线 Γ \Gamma Γ将图像分离成两个区域 Ω 1 \Omega_1 Ω1和 Ω 2 \Omega_2 Ω2,分割是通过最小化Chan-Vese模型能量函数给出的:
E ( Γ ) = λ length ( Γ ) + ∫ Ω 1 ( I − c 1 ) 2 d x + ∫ Ω 2 ( I − c 2 ) 2 d x E(\Gamma)=\lambda \operatorname{length}(\Gamma)+\int_{\Omega_{1}}\left(I-c_{1}\right)^{2} \mathrm{~d} \mathbf{x}+\int_{\Omega_{2}}\left(I-c_{2}\right)^{2} \mathrm{~d} \mathbf{x} E(Γ)=λlength(Γ)+∫Ω1(I−c1)2 dx+∫Ω2(I−c2)2 dx
该能量函数用来度量与内部平均灰度常数c1和外部平均灰度常数c2的偏差。
由分片常数图像 U = χ 1 c 1 + χ 2 c 2 U=\chi_{1} c_{1}+\chi_{2} c_{2} U=χ1c1+χ2c2,将上式重写为:
E ( Γ ) = λ ∣ c 1 − c 2 ∣ 2 ∫ ∣ ∇ U ∣ d x + ∥ I − U ∥ 2 E(\Gamma)=\lambda \frac{\left|c_{1}-c_{2}\right|}{2} \int|\nabla U| \mathrm{d} \mathbf{x}+\|I-U\|^{2} E(Γ)=λ2∣c1−c2∣∫∣∇U∣dx+∥I−U∥2
如果用 λ|c1-c2| 替换ROF方程中的 λ 得到的公式为:
min
U
∥
I
−
U
∥
2
+
2
λ
J
(
U
)
\min _{U}\|\boldsymbol{I}-\boldsymbol{U}\|^{2}+2 \lambda J(\boldsymbol{U})
Umin∥I−U∥2+2λJ(U)最小化Chan-Vese模型现在转变成为设定阈值的ROF降噪问题
下面是一幅难以分割图像的分割结果:
阈值为0.4:

阈值为0.8:

代码为:
import rof
from pylab import *
from PIL import Image
import scipy.misc
#im = array(Image.open('../data/ceramic-houses_t0.png').convert("L"))
im = array(Image.open('5.png').convert("L"))
figure()
gray()
subplot(131)
axis('off')
imshow(im)
U, T = rof.denoise(im, im, tolerance=0.001)
subplot(132)
axis('off')
imshow(U)
t = 0.4 # ceramic-houses_t0 threshold
# t = 0.8 # flower32_t0 threshold
seg_im = U < t*U.max()
#scipy.misc.imsave('ceramic-houses_t0_result.pdf', seg_im)
scipy.misc.imsave('5.pdf', seg_im)
subplot(133)
axis('off')
imshow(seg_im)
show()















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









