







 本文详细介绍了SPSS中的聚类分析,包括K均值聚类、层次聚类和两步聚类算法,并通过移动通讯客户细分和体操裁判打分倾向聚类的案例进行解析。聚类分析主要用于数据简化、市场细分等,其目的是将具有相似特征的对象归为一类。K均值聚类要求预先设定类别数,而层次聚类则依据距离进行逐步合并。两步聚类适合处理大数据集并能自动决定最佳分类数。聚类分析需注意距离测量方法的选择、无关变量的影响、共线性问题、异常值处理以及分类数的确定。
本文详细介绍了SPSS中的聚类分析,包括K均值聚类、层次聚类和两步聚类算法,并通过移动通讯客户细分和体操裁判打分倾向聚类的案例进行解析。聚类分析主要用于数据简化、市场细分等,其目的是将具有相似特征的对象归为一类。K均值聚类要求预先设定类别数,而层次聚类则依据距离进行逐步合并。两步聚类适合处理大数据集并能自动决定最佳分类数。聚类分析需注意距离测量方法的选择、无关变量的影响、共线性问题、异常值处理以及分类数的确定。
SPSS(十五)spss之聚类分析(图文+数据集)
聚类分析简介
按照个体(记录)的特征将它们分类,使同一类别内的个体具有尽可能高的同质性,而类别之间则具有尽可能高的异质性。
为了得到比较合理的分类,首先要采用适当的指标来定量地描述研究对象之间的联系的紧密程度。
假定研究对象均用所谓的“点”来表示。
在聚类分析中,一般的规则是将“距离”较小的点归为同一类,将“距离”较大的点归为不同的类。
常见的是对个体分类,也可以对变量分类,但对于变量分类此时一般使用相似系数作为“距离”测量指标
- 聚类分析前所有个体所属的类别是未知的,类别个数一般也未知,分析的依据就是原始数据,可能事先没有任何有关类别的信息可参考。
- 严格说来聚类分析并不是纯粹的统计技术,它不像其它多元分析法那样,需要从样本去推断总体。一般都涉及不到有关统计量的分布,也不需要进行显著性检验。
- 聚类分析更像是一种建立假设的方法,而对相关假设的检验还需要借助其它统计方法。
注意:聚类分析更像是一种建立假设的方法,而对于相关假设的检验还需要借助其他统计的方法,比如判别分析、T-检验、方差分析等,看聚类出来的几个类别是否存在差异
聚类的用途
- 设计抽样方案(分层抽样)
- 预分析过程(先通过聚类分析达到简化数据的目的,将众多的个体先聚集成比较好处理的几个类别或子集,然后再进行后续的多元分析)
- 细分市场、个体消费行为划分(先聚类,然后再利用判别分析进一步研究各个群体之间的差异)
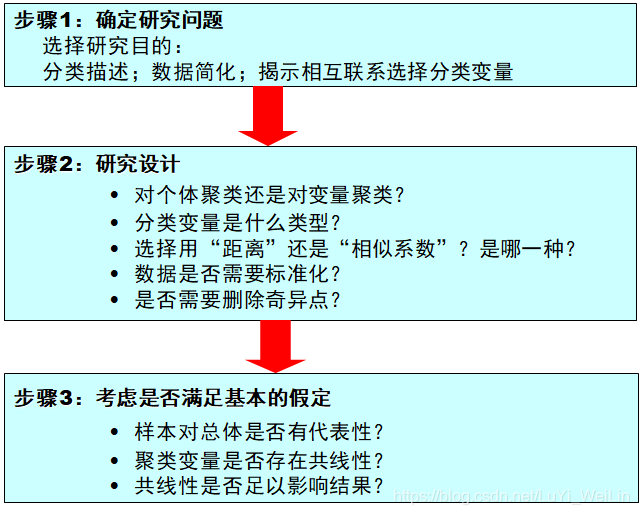
聚类分析的基本步骤总结

聚类方法
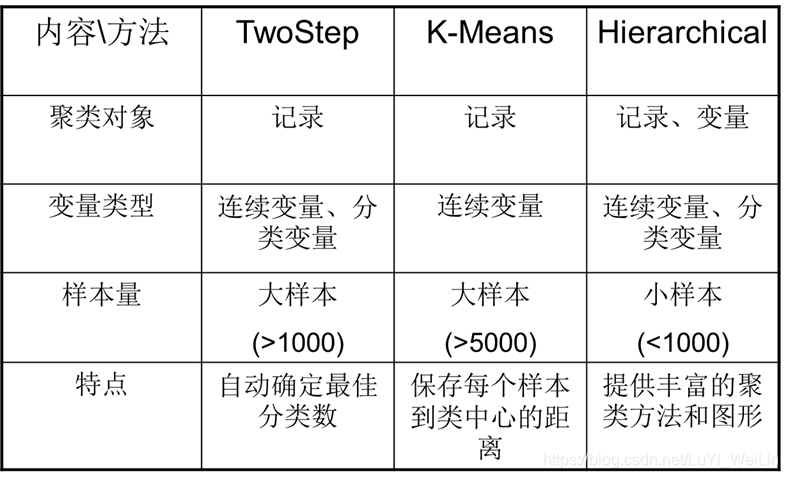
K均值聚类(K-means Cluster)
方法原理
- 选择(或人为指定)某些记录作为凝聚点
- 按就近原则将其余记录向凝聚点凝集
- 计算出各个初始分类的中心位置(均值)
- 用计算出的中心位置重新进行聚类
- 如此反复循环,直到凝聚点位置收敛为止
方法特点
- 要求已知类别数
- 可人为指定初始位置
- 节省运算时间
- 样本量过大时有必要考虑
- 只能使用连续性变量
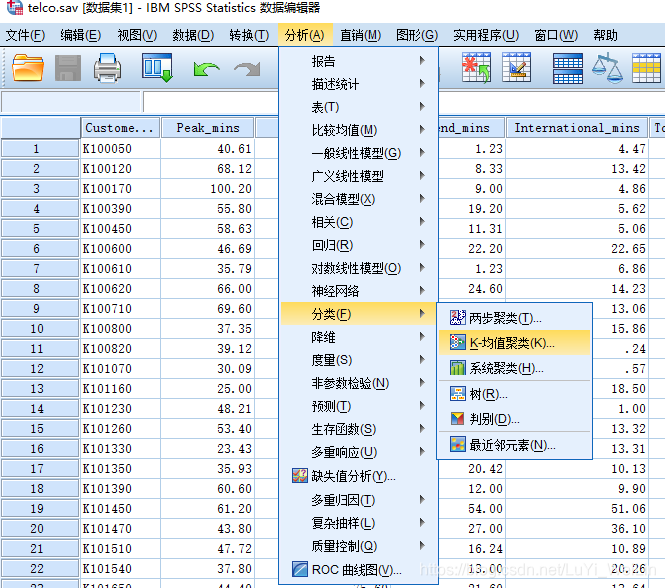
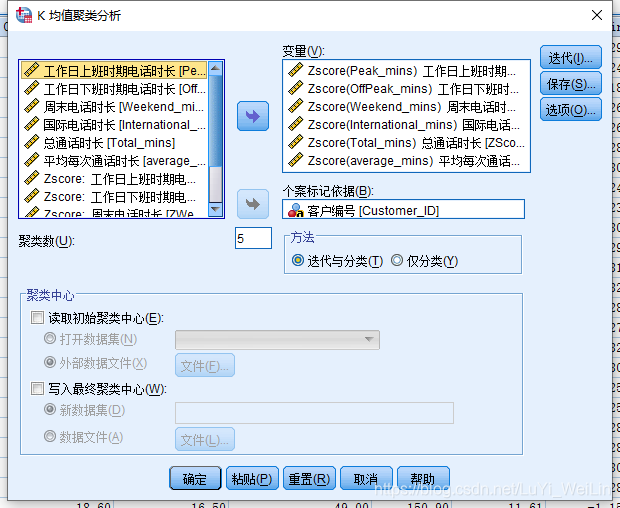
案例:移动通讯客户细分
数据包含6个变量
是客户编号(Customer_ID)
工作日上班时期电话时长(Peak_mins)
工作日下班时期电话时长(OffPeak_mins)
周末电话时长(Weekend_mins)
国际电话时长(International_mins)
总通话时长(Total_mins)
平均每次通话时长(average_mins)
根据前期的调研,研究者认为移动用户应当被分为5个主要群体,现希望得到相应的定量聚类结果。
(由于数据集过多,可到我的资源下载“spss之聚类分析--移动通讯客户细分”)
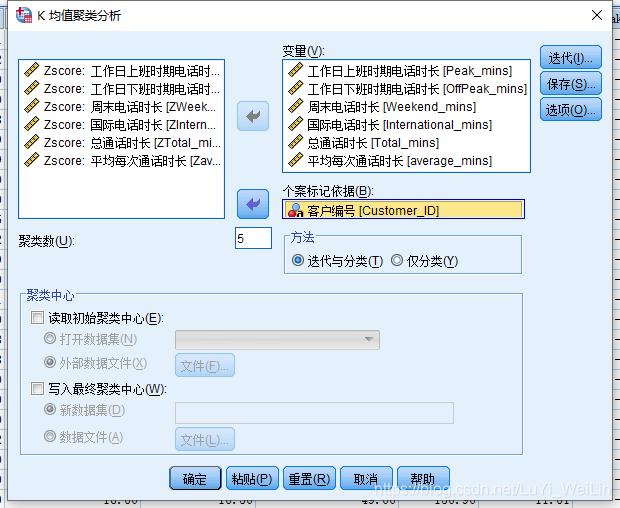
看到结果无法收敛,所以重新设置迭代次数,让其收敛
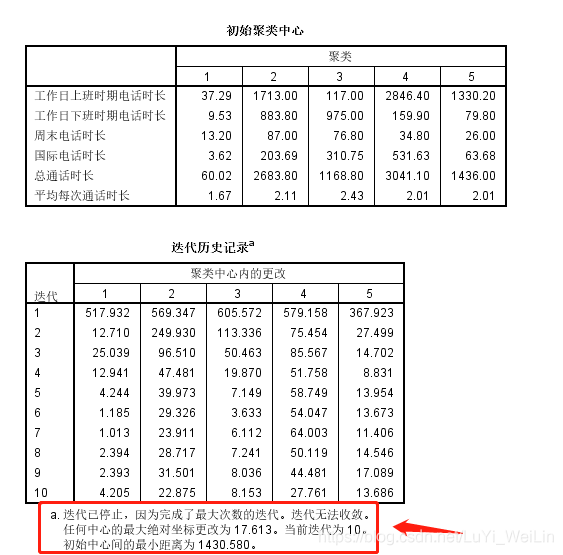
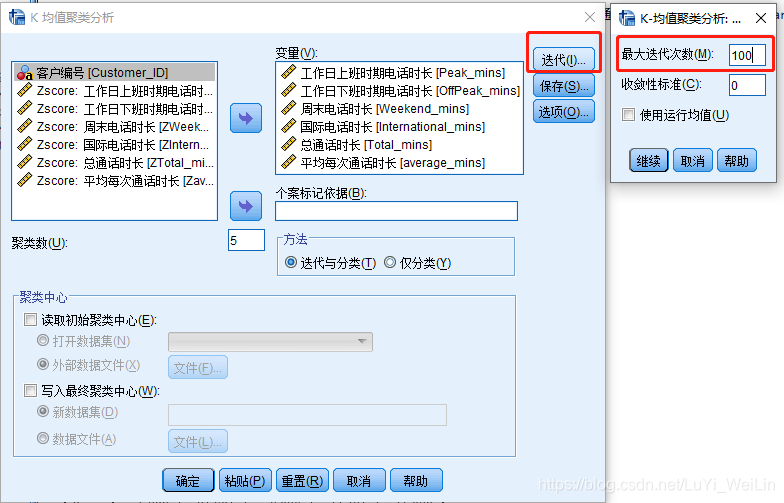
但是最终聚类出来,结果怪怪的
各变量测量尺度,量纲不一样,聚类计算其距离时量纲大的对结果影响大
如何进行标化呢?
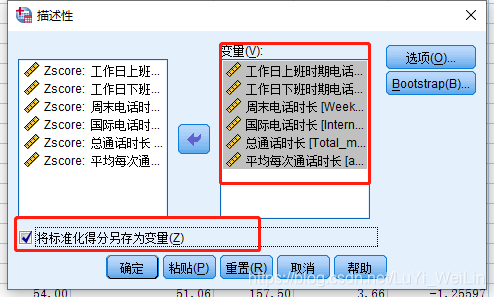

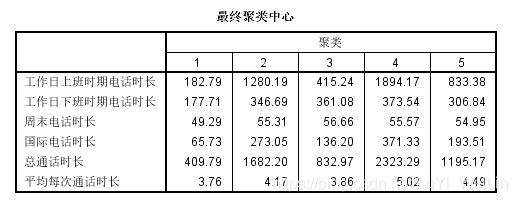
重新聚类
标准化的变量,一般在正负3以内,0代表平均水平
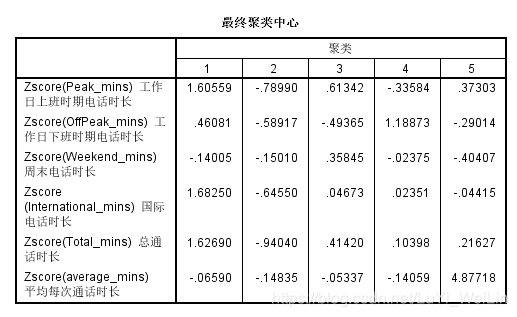
但是我们想看原始变量的原始水平,不看这标准化的
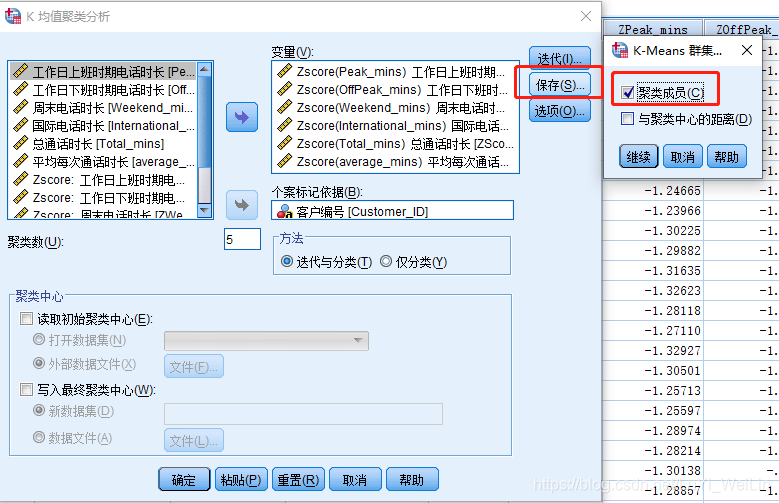
保存个案被划分为哪个类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











