






1、Web目录信息搜集
robots.txt robots.txt 文件规定了搜索引擎抓取工具可以/无法请求抓取您网站上的哪些网页或文件。通常管理员会将一些不希望被爬虫爬取的页面写到这个文件里面,所以我们通常可以通过这个文件获取到一些特殊目录:
敏感文件 用扫描器扫描目录,这时候你需要一本强大的字典,重在平时积累。字典越强扫描处的结果可能越多,这一步主要扫出网站的管理员入口,一些敏感文件(.mdb,.excel,.word,.zip,.rar),查看是否存在源代码泄露。常见有.git文件泄露,.svn文件泄露,.DB_store文件泄露,WEB-INF/web.xml泄露。目录扫描有两种方式,使用目录字典进行暴力才接存在该目录或文件返回200或者403;使用爬虫爬行主页上的所有链接,对每个链接进行再次爬行,收集这个域名下的所有链接,然后总结出需要的信息。
通过以下命令安装dirhunt
python -m pip install dirhunt
扫描一个网站可通过以下命令进行扫描(请使用实际实验给到的靶机ip地址):
dirhunt http://172.16.32.224
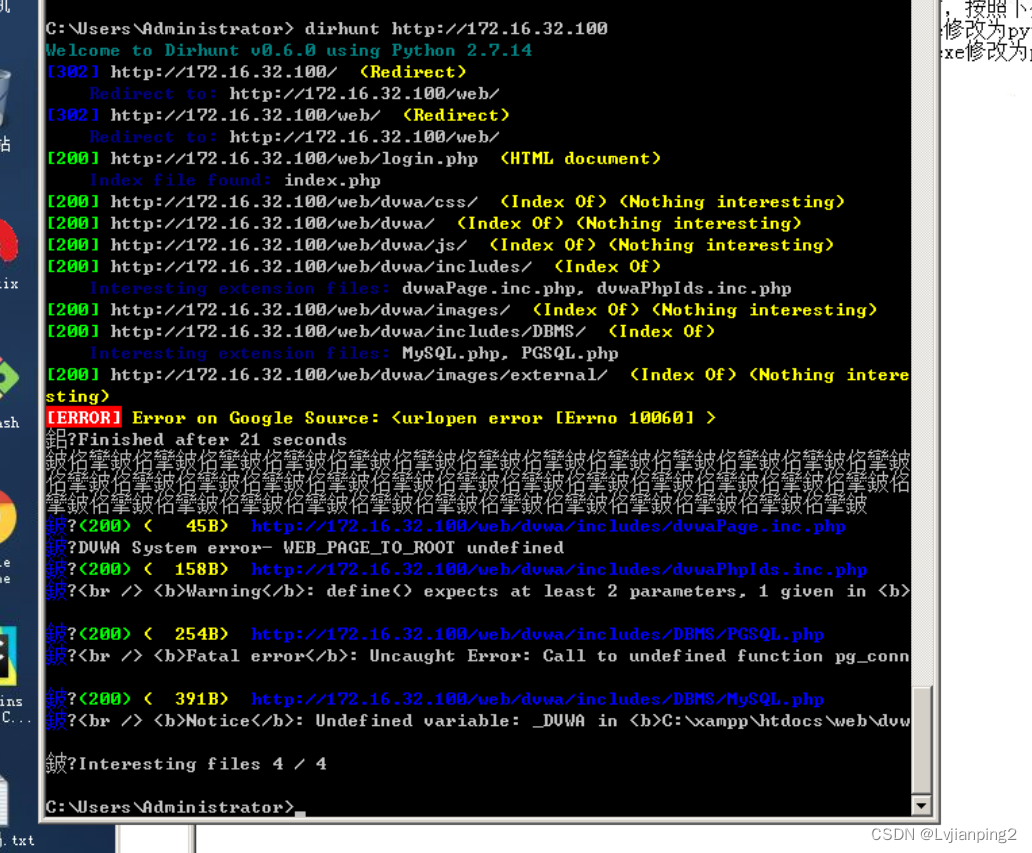
由于此网站需要登录,所以可以扫到的目录并不多。类似的工具如dirsearch、OpenDoor、Burpsuite等。
2、Web指纹识别
这个主要是主机系统的识别,网站程序的识别,cms等等,准确获取Web服务器及其承载的应用的类型及版本对Web站点的安全测试有重要意义。在线识别网站如:
https://whatcms.org/
通过此网站可识别部分CMS,如识别http://www.discuz.net
可识别该网站使用的CMS为Discuz。
另外可用于识别的工具如WhatWeb。具体使用方式为:
whatweb www.discuz.net
whatweb需要ruby环境支持。
在线测试网站为:
https://www.whatweb.net/















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









