







一.简介
- BGP外部网关协议,是机制较为复杂的动态路由协议,我将逐步介绍,写出全网最详细的BGP介绍。
- 本文为结合了华为技术和新华三技术的大成,即结合了HCIA,HCIP,HCIE Datacom和H3CNE-RS+,H3CSE-RS+,H3CIE-RS+。本文将分为 BGP基础、BGP路径属性及路由反射器、BGP路由优选、MP-BGP 介绍、BGP高阶属性、 BGP的详细配置 六个大模块进行详细介绍。
二.BGP基础
1.前言
- 为方便管理规模不断扩大的网络,网络被分成了不同的AS(Autonomous System,自治系统)。早期,EGP(Exterior Gateway Protocol,外部网关协议)被用于实现在AS之间动态交换路由信息。但是EGP设计得比较简单,只发布网络可达的路由信息,而不对路由信息进行优选,同时也没有考虑环路避免等问题,很快就无法满足网络管理的要求。
- BGP是为取代最初的EGP而设计的另一种外部网关协议。不同于最初的EGP,BGP能够进行路由优选、避免路由环路、更高效率的传递路由和维护大量的路由信息。
- 本模块将介绍BGP的基本概念。
2.BGP概述
(1)AS
- OSPF、IS-IS等IGP路由协议在组织机构网络内部广泛应用随着网络规模扩大,网络中路由数量不断增长,IGP已无法管理大规模网络,AS的概念由此诞生。
- AS指的是在同一个组织管理下,使用统一选路策略的设备集合。
- 不同AS通过AS号区分,AS号存在16bit、32bit两种表示方式。IANA负责AS号的分发。
- 当不同AS之间需要进行通信时,在AS之间应使用何种路由协议进行路由的传递?
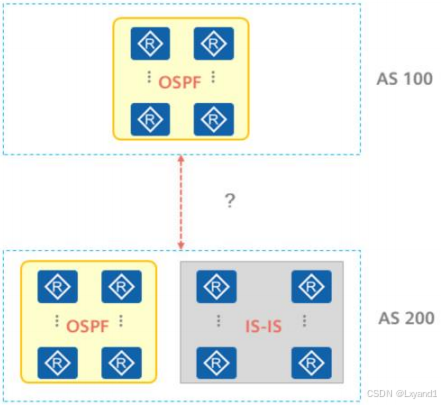
(2)使用IGP传递路由
- AS之间需要直连链路,或通过VPN协议构造逻辑直连(例如GRE Tunnel)进行邻居建立。
- AS之间可能是不同的机构、公司,相互之间无法完全信任使用IGP可能存在暴露AS内部的网络信息的风险。
- 整个网络规模扩大,路由数量进一步增加,路由表规模变大,路由收敛变慢,设备性能消耗加大。
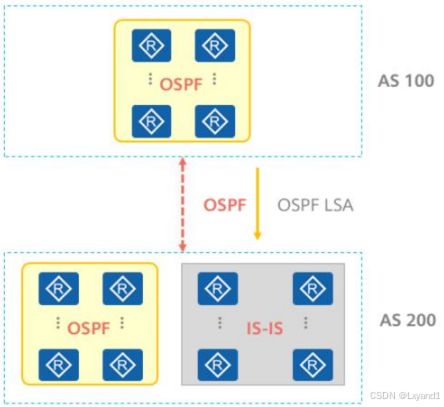
(3)使用BGP传递路由
为此在AS之间专门使用BGP(BorderGatewayProtocol,边界网关协议)协议进行路由传递,相较于传统的IGP协议:
- BGP基于TCP,只要能够建立TCP连接即可建立BGP
- 只传递路由信息,不会暴露AS内的拓扑信息。
- 触发式更新,而不是进行周期性更新。
(4)BGP发展历史

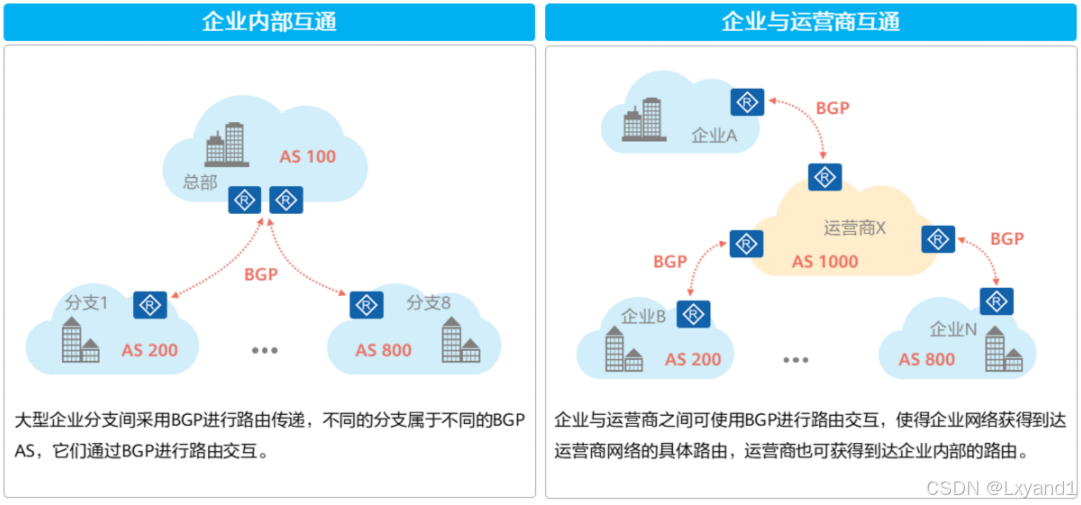
(5)BGP在企业中的应用
3.BGP的基本概念
(1)BGP概览
【1】BGP特性1

- BGP使用TCP为传输层协议,TCP端口号179。路由器之间的BGP会话基于TCP连接而建立。
- 运行BGP的路由器被称为BGP发言者(BGPSpeaker),或BGP路由器。
- 两个建立BGP会话的路由器互为对等体(Peer),BGP对等体之间交换BGP路由表。
- BGP路由器只发送增量的BGP路由更新,或进行触发式更新(不会周期性更新)。
- BGP能够承载大批量的路由前缀,可在大规模网络中应用。
【2】BGP特性2
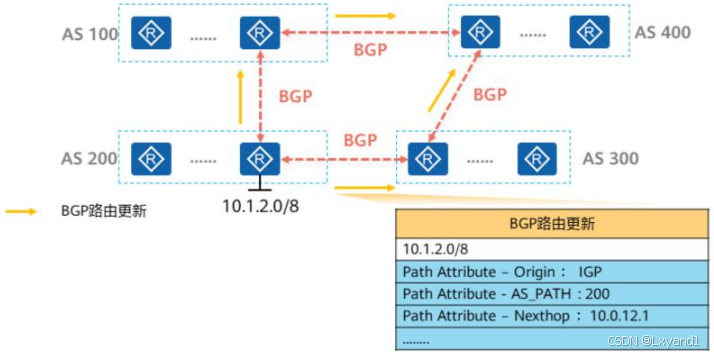
- BGP通常被称为路径矢量路由协议(Path-Vector Routing Protocol)。
- 每条BGP路由都携带多种路径属性(Path attribute),BGP可以通过这些路径属性控制路径选择,而不像IS-S、OSPF只能通过Cost控制路径选择,因此在路径选择上,BGP具有丰富的可操作性,可以在不同场景下选择最合适的路径控制方式。
(2)对等体关系
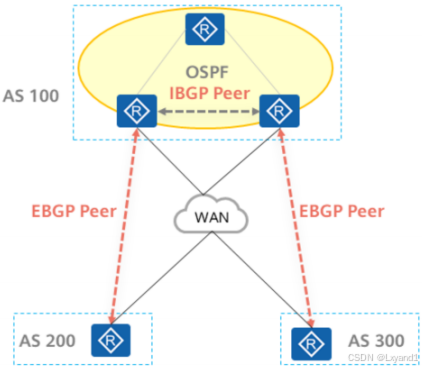
- 与OSPF、IS-IS等协议不同,BGP的会话是基于TCP建立的。建立BGP对等体关系的两台路由器并不要求必须直连。
- BGP存在两种对等体关系类型:EBGP及IBGP:
- EBGP(External BGP):位于不同自治系统的BGP路由器之间的BGP对等体关系。两台路由器之间要建立EBGP对等体关系,必须满足两个条件:
- 两个路由器所属AS不同(即AS号不同)。
- 在配置EBGP时,Peer命令所指定的对等体IP地址要求路由可达并且TCP连接能够正确建立。
- IBGP(Internal BGP):位于相同自治系统的BGP路由器之间的BGP邻接关系。
- EBGP(External BGP):位于不同自治系统的BGP路由器之间的BGP对等体关系。两台路由器之间要建立EBGP对等体关系,必须满足两个条件:
【1】BGP对等体关系建立1
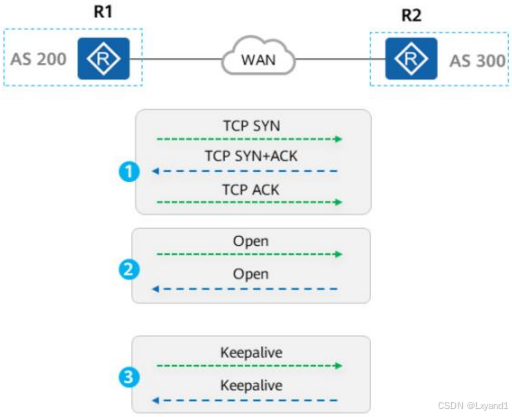
- 先启动BGP的一端先发起TCP连接,如上图所示,R1先启动BGP,R1使用随机端口号向R2的179端口发起TCP连接完成TCP连接的建立。
- 三次握手建立完成之后,R1、R2之间相互发送Open报文携带参数用于对等体建立,参数协商正常之后双方相互发送Keepalive报文,收到对端发送的Keepalive报文之后对等体建立成功,同时双方定期发送Keepalive报文用于保持连接。
- 其中Open报文中携带:
- My Autonomous System:自身AS号。
- Hold Time:用于协商后续Keepalive报文发送时间。
- BGP Identifier:自身RouterID。
- 注意:BGP建立对等体的对等体都会发起TCP三次握手,所以会建立两个TCP连接,但是实际BGP只会保留其中一个TCP连接,从Open报文中获取对端BGP Identifier之后BGP对等体会比较本端的Router ID和对端的Router ID大小,如果本端Router ID小于对端RouterID,则会关闭本地建立的TCP连接,使用由对端主动发起创建的TCP连接进行后续的BGP报文交互。
【2】BGP对等体关系建立2

- BGP对等体关系建立之后,BGP路由器发送BGP Update更新)报文通告路由到对等体。
【3】TCP连接源地址
- 缺省情况下,BGP使用报文出接口作为TCP连接的本地接口。
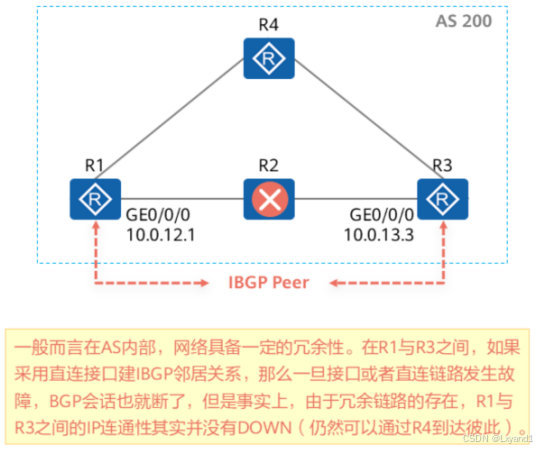
- 在部署IBGP对等体关系时,建议使用Loopback地址作为更新源地址。Loopback接口非常稳定,而且可以借助AS内的IGP和冗余拓扑来保证可靠性。
- 在部署EBGP对等体关系时,通常使用直连接口的IP地址作为源地址,如若使用Loopback接口建立EBGP对等体关系则应注意EBGP多跳问题。
(3)报文及状态机
- BGP存在5种类型的报文,不同类型的报文拥有相同的头部(header)。
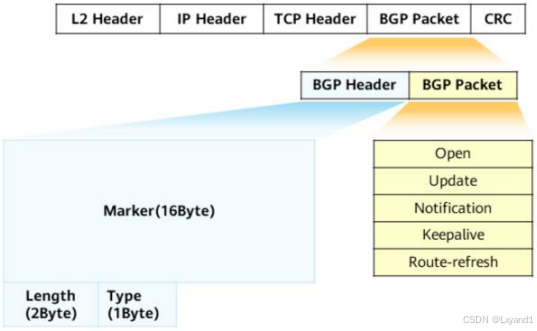
- 不同于常见的IGP协议,BGP使用TCP作为传输层协议,端口号179,这使得BGP支持在非直连的路由器之间建立对等体关系。
【1】BGP报文类型
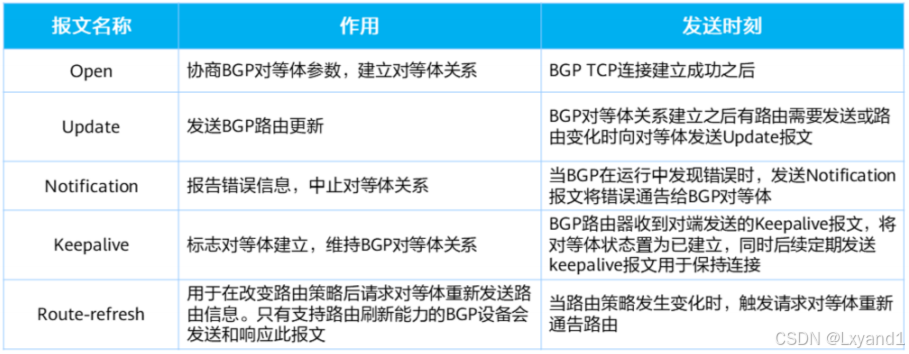
【2】报文头格式
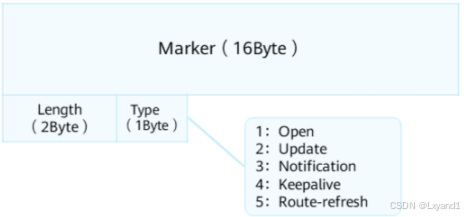
BGP五种报文都拥有相同的报文头,格式如左侧所示,主要字段解释如下:
- Marker:16Byte,用于标明BGP报文边界,所有bit均为“1”。
- Length:2Byte,BGP报文总长度(包括报文头在内)以Byte为单位。
- Type:1Byte,BGP报文的类型。其取值从1到5,分别表示Open、Update、Notification、Keepalive和Route-refresh 报文。
【3】Open报文

Open报文是TCP连接建立之后发送的第一个报文,用于建立BGP对等体之间的连接关系,报文格式如左侧所示,主要字段解释如下:
- Version:BGP的版本号。对于BGP 4来说,其值为4。
- My AS(autonomous system):本地AS号。通过比较两端的AS号可以判断对端是否和本端处于相同AS。
- Hold Time:保持时间。在建立对等体关系时两端要协商Hold Time,并保持一致。如果在这个时间内未收到对端发来的Keepalive报文或Update报文,则认为BGP连接中断。
- BGP Identifier:BGP标识符,以IP地址的形式表示用来识别BGP路由器。
- Opt Parm Len: Optional parameters的长度
- Optional parameters:宣告自身对于一些可选功能的支持,比如认证、多协议支持
- 除了IPv4单播路由信息,BGP4+还支持多种网络层协议(如IPv6、组播),在协商时BGP对等体之间会通过Optional parameters字段协商对网络层协议的支持能力。
【4】Update报文

- Update报文用于在对等体之间传递路由信息,可以用于发布、撤销路由。
- 一个Update报文可以通告具有相同路径属性的多条路由,这些路由保存在NLRI(Network Layer ReachableInformation,网络层可达信息)中。同时Update还可以携带多条不可达路由,用于告知对方撤销路由,这些保存在Withdrawn Routes字段中。
- 报文格式如左侧所示,主要字段解释如下:
- Withdrawn routes:不可达路由的列表。
- Path attributes:与NLRI相关的所有路径属性列表,每个路径属性由一个TLV(Type-Length-Value)三元组构成。
- NLRI:可达路由的前缀和前缀长度二元组。
- Unfeasible routes length:不可达路由字段的长度,以Byte为单位。如果为0则说明没有Withdrawn Routes字段。
- Total path attribute length:路径属性字段的长度,以Byte为单位。如果为0则说明没有Path Attributes 字段。
【5】Notification报文

- 当BGP检测到错误状态时(对等体关系建立时、建立之后都可能发生),就会向对等体发送Notification,告知对端错误原因。之后BGP连接将会立即中断。
- Error Code、Error subcode:差错码、差错子码,用于告知对端具体的错误类型。
- Data:用于辅助描述详细的错误内容,长度并不固定。
【6】Keepalive报文
- BGP路由器收到对端发送的Keepalive报文,将对等体状态置为已建立,同时后续定期发送keepalive报文用于保持连接。
- Keepalive报文格式中只包含报文头,没有附加其他任何字段。
【7】Route-refresh报文
![]()
- Route-refresh报文用来要求对等体重新发送指定地址族的路由信息,一般为本端修改了相关路由策略之后让对方重新发送Update报文,本端执行新的路由策略重新计算BGP路由。
- 相关字段内容如下:
- AFl:Address Family ldentifier,地址族标识,如IPv4。
- Res.:保留,8个bit必须置0。
- SAFl:Subsequent Address Family ldentifier,子地址族标识。
- 注意:
- 在Open报文协商时会协商是否支持Route-refresh,如果对等体支持Route-refresh能力则可以通过refresh bgp命令手工对BGP连接进行软复位,BGP软复位可以在不中断BGP连接的情况下重新刷新BGP路由表,并应用新的策略。
- 对于不支持Route-Refresh能力的BGP对等体,可以配置keep-all-routes命令,保留该对等体的所有原始路由,这样不需要复位BGP连接即可完成路由表的刷新。
- 缺省情况下未开启keep-all-routes。
【8】BGP状态机1
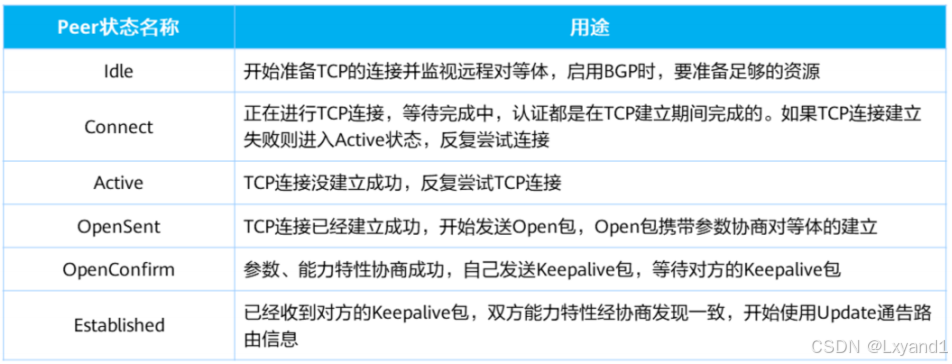
【9】BGP状态机2
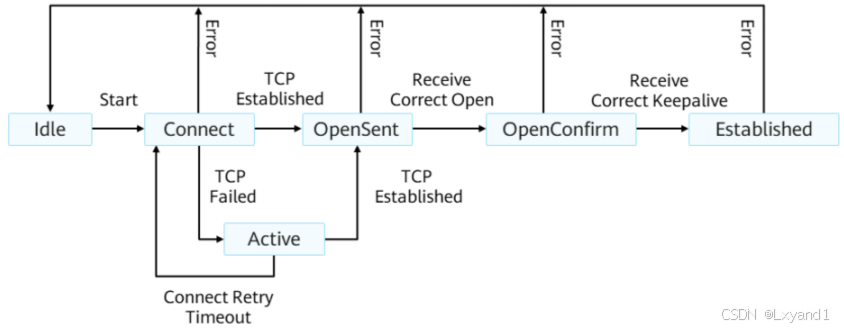
- Idle状态是BGP初始状态。在Idle状态下,BGP拒绝对等体发送的连接请求。只有在收到本设备的Start事件后,BGP才开始尝试和其它BGP对等体进行TCP连接,并转至Connect状态。
- Start事件是由一个操作者配置一个BGP过程,或者重置一个已经存在的过程或者路由器软件重置BGP过程引起的。
- 任何状态中收到Notification报文或TCP拆链通知等Error事件后,BGP都会转至Idle状态。
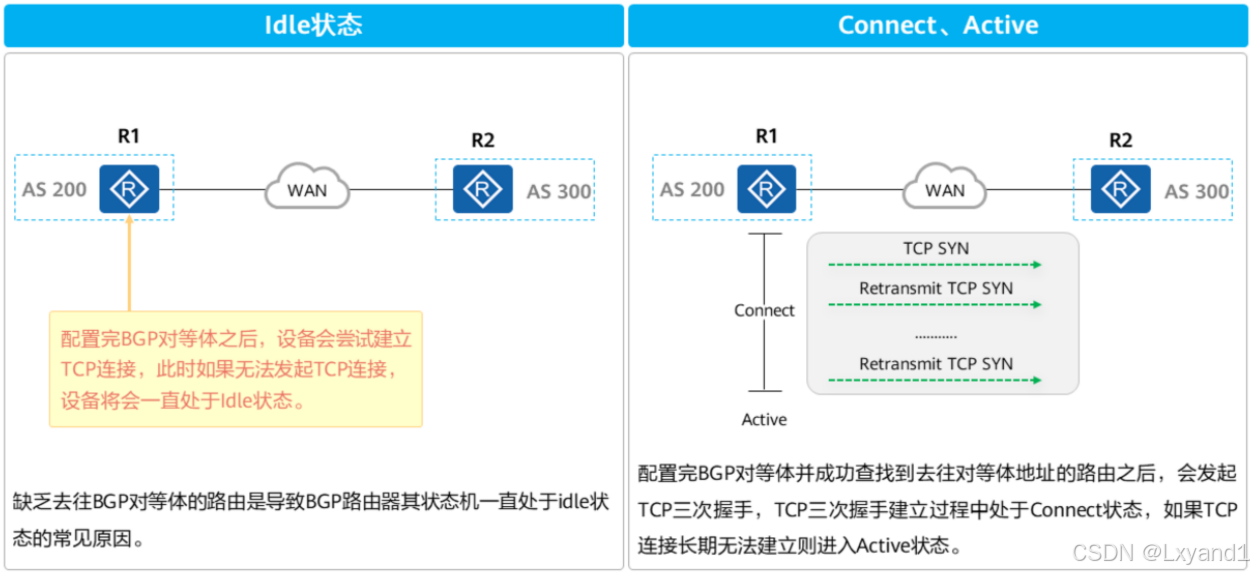
- 在Connect状态下,BGP启动连接重传定时器(Connect Retry),等待TCP完成连接。
- 如果TCP连接成功,那么BGP向对等体发送Open报文,并转至OpenSent状态。
- 如果TCP连接失败,那么BGP转至Active状态。
- 如果连接重传定时器超时,BGP仍没有收到BGP对等体的响应,那么BGP继续尝试和其它BGP对等体进行TCP连接,停留在Connect状态。
- 在Active状态下,BGP总是在试图建立TCP连接。
- 如果TCP连接成功,那么BGP向对等体发送Open报文,关闭连接重传定时器,并转至OpenSent状态。
- 如果TCP连接失败,那么BGP停留在Active状态。
- 如果连接重传定时器超时,BGP仍没有收到BGP对等体的响应,那么BGP转至Connect状态。
a.BGP状态机详解1
b.BGP状态机详解2
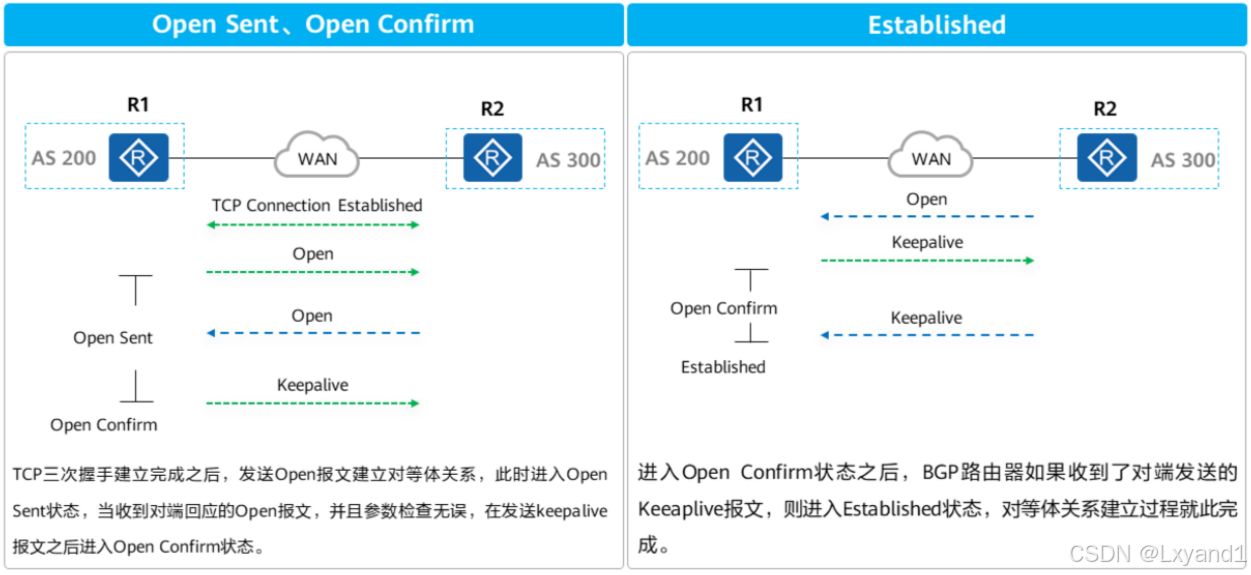
(4)BGP协议表项
【1】对等体表
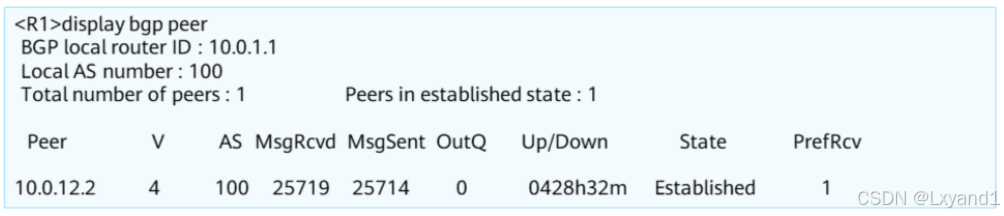
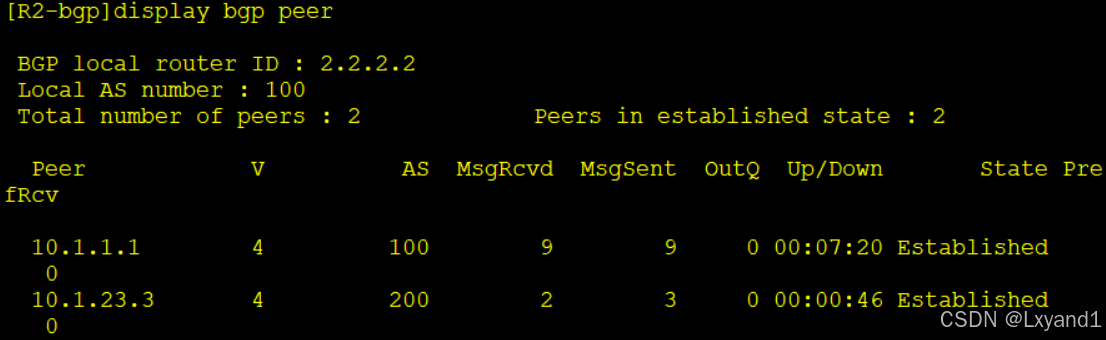
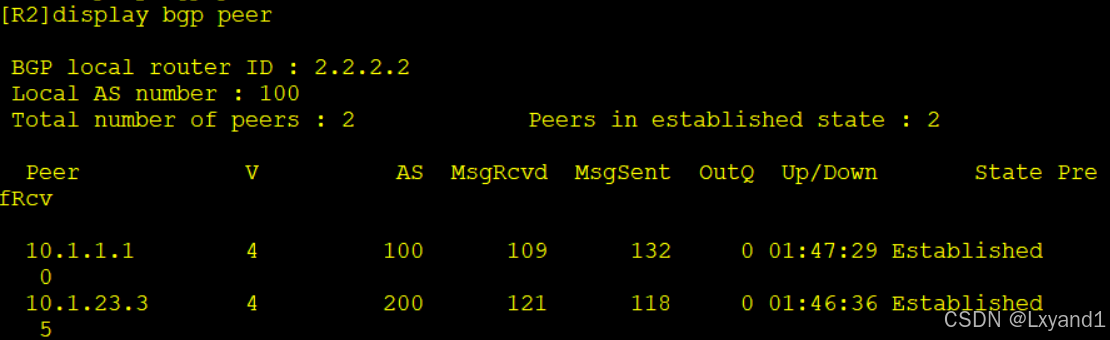
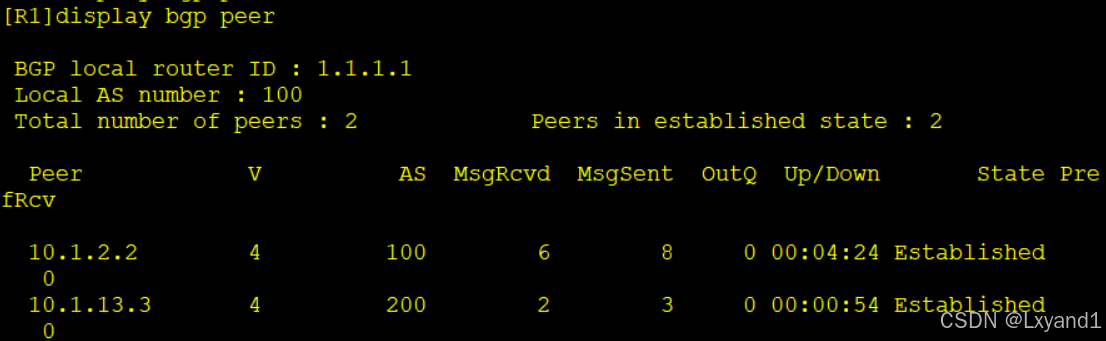
在设备上通过display bgp peer命令查看BGP对等体表,其中主要参数含义:
- Peer:对等体地址。
- V:version,版本号。
- AS:对等体AS号。
- Up/Down:该对等体已经存在up或者down的时间。
- State:对等体状态,这里显示的为BGP状态机的状态。
- PrefRcv:prefixreceived,从该对等体收到的路由前缀数目。
- MsqRcvd 、MsgSent:从对等体收到的报文个数,向对等体发送的报文个数。
- OutQ:out queue,对外发送报文队列中排队的个数,一般为0。
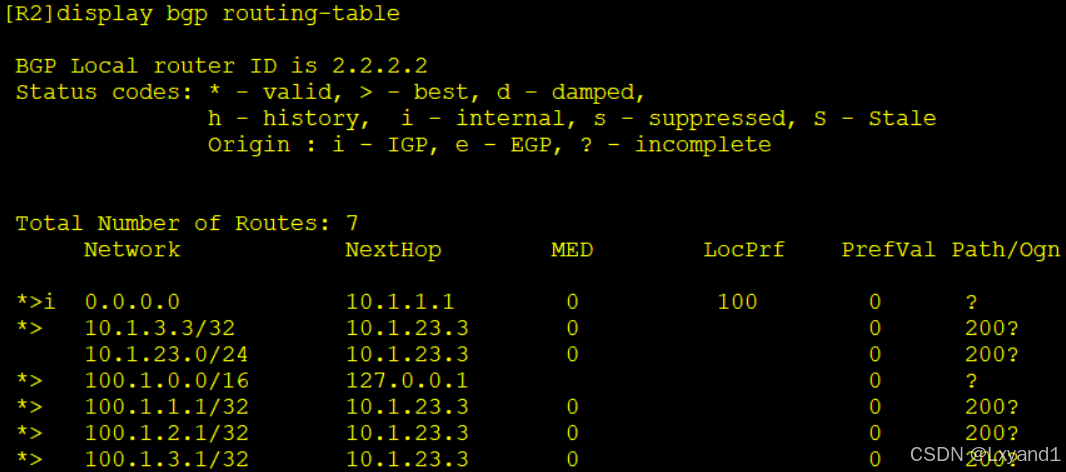
【2】路由表

- 在设备上通过display bgp routing-table查看BGP路由表:
- Network:路由的目的网络地址以及网络掩码。
- NextHop:下一跳地址。
- 如果想要查看某条路由更加详细的信息,可以通过display bgp routing-table ipv4-address{mask/mask-length}查看该命令会将匹配的BGP路由信息详细展示。
(5)路由生成
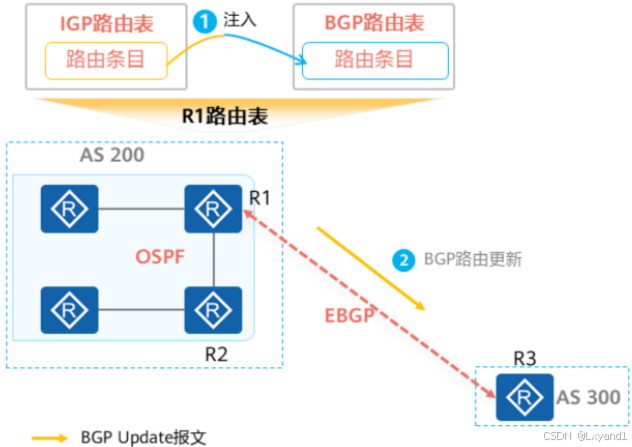
- 不同于IGP路由协议,BGP自身并不会发现并计算产生路由,BGP将IGP路由表中的路由注入到BGP路由表中,并通过Update报文传递给BGP对等体。
- BGP注入路由的方式有两种:
- Network
- import-route
- 与IGP协议相同,BGP支持根据已有的路由条目进行聚合,生成聚合路由。
【1】Network注入路由1
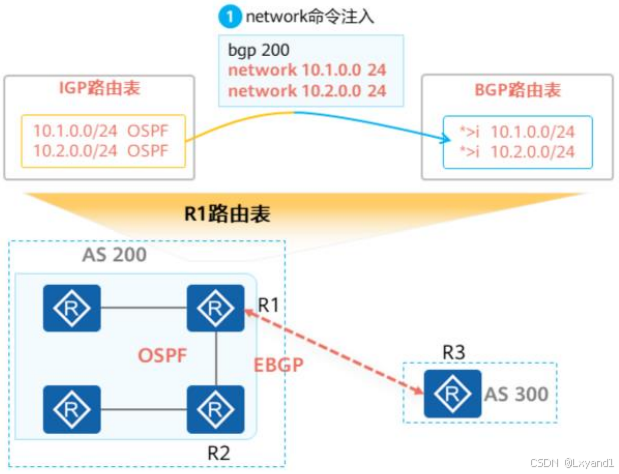
通过Network方式注入路由:
- AS200内的BGP路由器已经通过IGP协议OSPF学习到了两条路由:10.1.0.0/24和10.2.0.0/24,在BGP进程内通过network命令注入这两条路由,这两条路由将会出现在本地的BGP路由表中。
【2】Network注入路由2
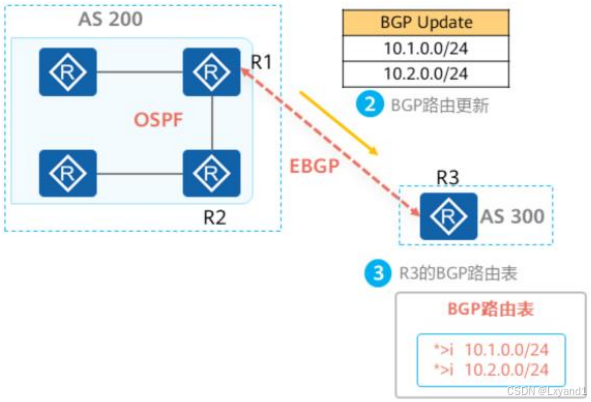
接上面:
- AS200内的BGP路由器通过Update报文将路由传递给AS300内的BGP路由器。
- AS300内的BGP路由器收到路由后,将这两条路由加入到本地的BGP路由表中。
【3】import-route方式注入路由
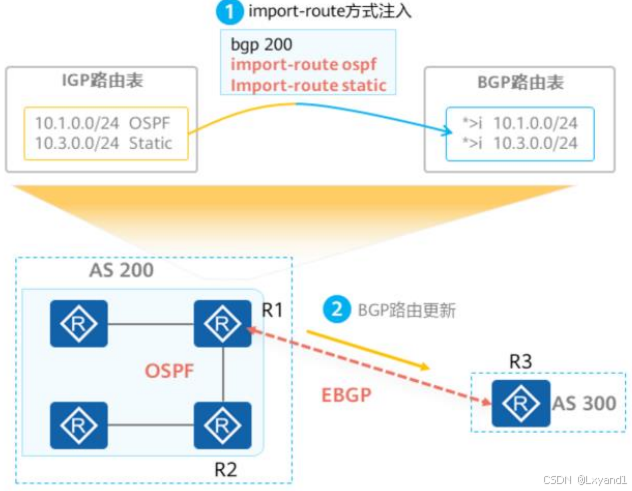
Network方式注入路由虽然是精确注入,但是只能一条条配置逐条注入IP路由表中的路由,如果注入的路由条目很多配置命令将会非常复杂,为此可以使用import-route方式,将:
- 直连路由
- 静态路由
- OSPF路由
- IS-IS路由
等协议的路由注入到BGP路由表中。
【4】BGP聚合路由
与众多IGP协议相同,BGP同样支持路由的手工聚合,在BGP配置视图中使用aggregate命令可以执行BGP路由手工聚合,在BGP已经学习到相应的明细路由情况下,设备会向BGP注入指定的聚合路由。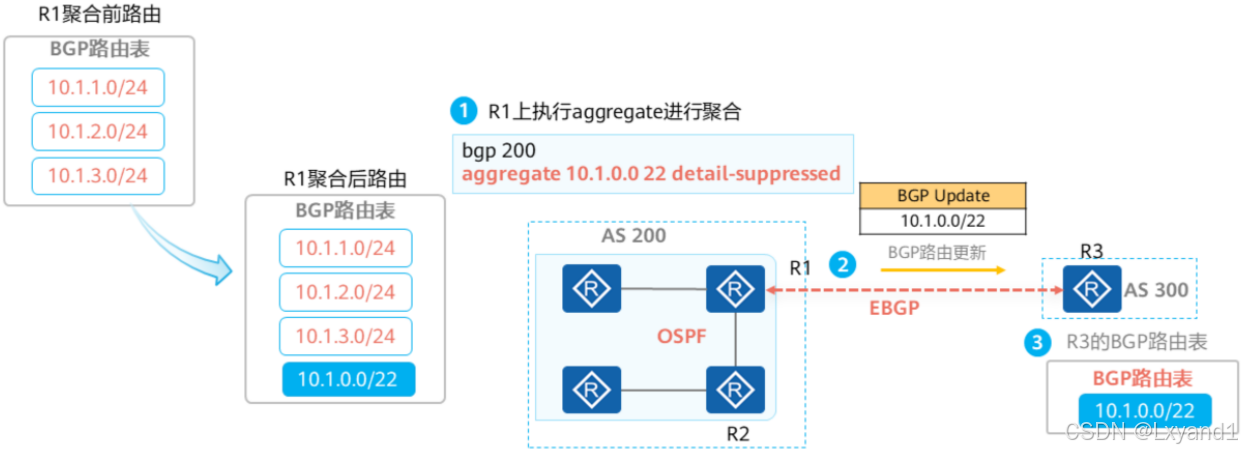
- 执行聚合之后,在本地的BGP路由表中除了原本的明细路由条目之外,还会多出一条聚合的路由条目。
- 如果在执行聚合时指定了detail-suppressed,则BGP只会向对等体通告聚合后的路由,而不通告聚合前的明细路由。
- 在聚合时配置了抑制明细路由的参数,R3上查看路由表,将只能看到BGP路由:10.1.0.0/22,无法看到聚合前的明细路由。
(6)通告原则
- BGP通过network、import-route、aggregate聚合方式生成BGP路由后,通过Update报文将BGP路由传递给对等体。
- BGP通告遵循以下原则:
- 只发布最优路由。
- 从EBGP对等体获取的路由,会发布给所有对等体。
- IBGP水平分割:从IBGP对等体获取的路由,不会发送给IBGP对等体。
- BGP同步规则指的是:当一台路由器从自己的IBGP对等体学习到一条BGP路由时(这类路由被称为IBGF路由),它将不能使用该条路由或把这条路由通告给自己的EBGP对等体,除非它又从IGP协议(例如OSPF等,此处也包含静态路由)学习到这条路由,也就是要求IBGP路由与IGP路由同步。同步规则主要用于规避BGP路由黑洞问题。
【1】BGP路由通告原则一
第一条原则:只发布最优且有效(即下一跳地址可达)路由。
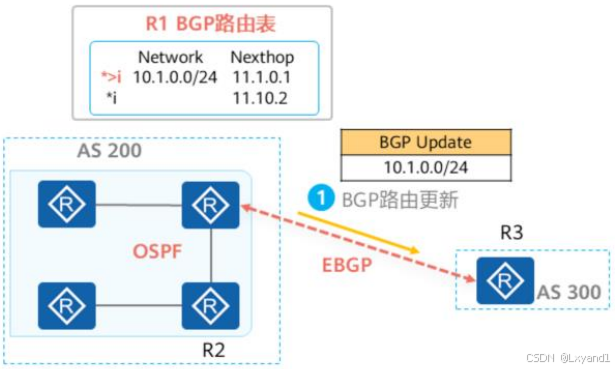
- 通过display bgp routing-table命令可以查看BGP路由表。

- 在BGP路由表中同时存在以下两个标志的路由为最优、有效:
- *:代表有效
- >:代表最优
【2】BGP路由通告原则二
第二条原则:从EBGP对等体获取的路由,会发布给所有对等体。
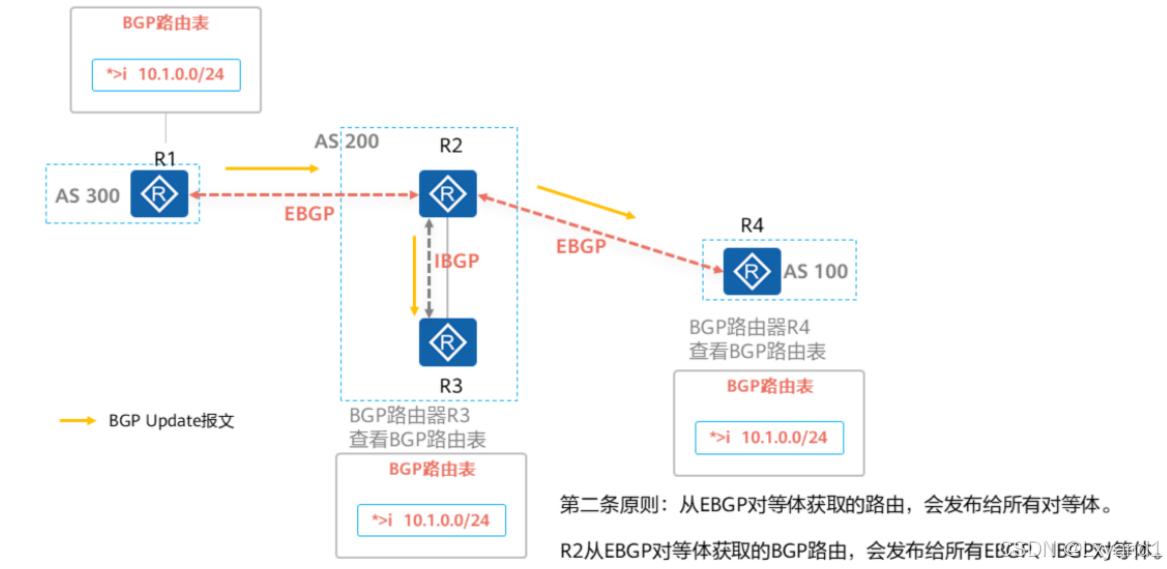
【3】BGP路由通告原则三1
- 第三条原则:从IBGP对等体获取的BGP路由,不会再发送给其他IBGP对等体。
- 该条原则也被称为“IBGP水平分割‘’。
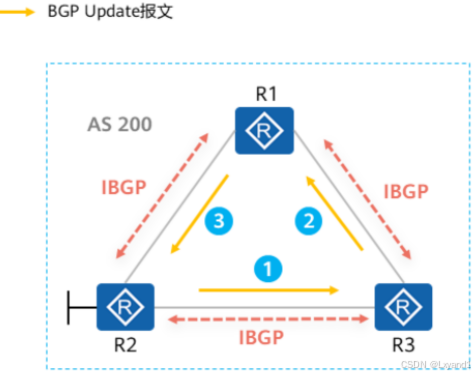
- 如图所示,如果IBGP对等体学习到的路由会继续传递给其他的IBGP对等体:
- R2将一条路由传递给了IBGP对等体R3。
- R3收到路由之后传递给IBGP对等体R1。
- R1继续传递给IBGP对等体R2。
- 路由环路形成。
【4】BGP路由通告原则三2
- 第三条原则可能会带来新的问题,如下所示当BGP路由器R2将路由传递给BGP路由器R1时由于第三条原则限制,R1无法将BGP路由传递给R3,R3将无法学习到路由。

- 为解决该问题可以采用AS内IBGP全互联的方式,即:R2、R3之间建立非直连的IBGP对等体关系以此让BGP路由器R2将路由传递给BGP路由器R3。
【5】BGP路由通告原则四1
- 第四条原则:当一台路由器从自己的IBGP对等体学习到一条BGP路由时(这类路由被称为IBGP路由),它将不能使用该条路由或把这条路由通告给自己的EBGP对等体,除非它又从IGP协议(例如OSPF等,此处也包含静态路由)学习到这条路由,该条规则也被称为BGP同步原则。
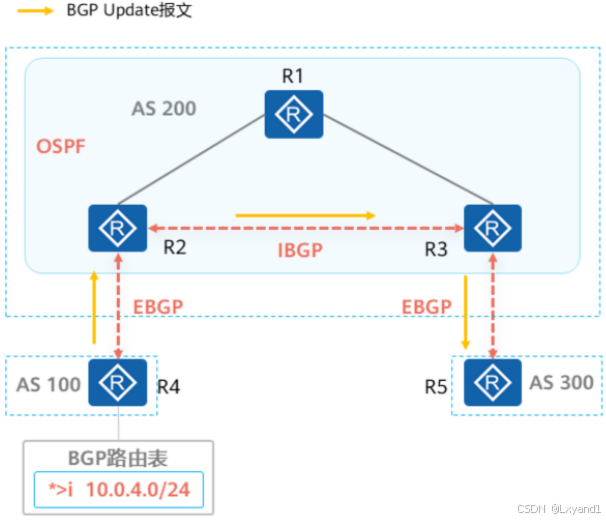
如图所示:
- BGP路由器R4上存在一条路由10.0.4.0/24,R4将其传递给了R2。
- R2将路由传递给非直连IBGP对等体R3。
- R3将路由传递给R5。
- 之后R5向10.0.4.4发起访问
【6】BGP路由通告原则四2
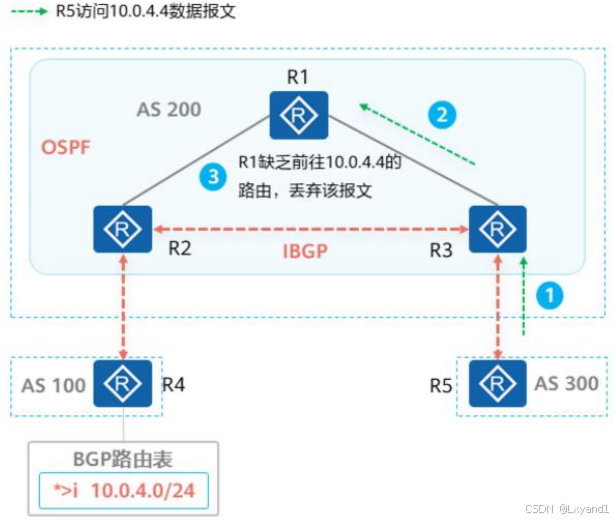
R5访间10.0.4.4:
- R5查找路由表,将报文发送给R3。
- R3收到报文后查找路由表,匹配到一条BGP路由,其下一跳为R2,但是R2为非直连下一跳,需要进行路由迭代,通过IGP学习到的路由迭代出下一跳为R1。R3将报文发送给R1。
- R1收到报文后查找路由表,因为R1并非BGP路由器未与R2建立IBGP对等体关系,因此R1上并无BGP路由10.0.4.0/24,路由查找失败,R1将报文丢弃。
- 产生该问题根本原因为AS200域内未运行BGP的路由器并无从BGP学习到的路由条目,查找路由失败,导致R1丢弃报文。为此制定了BGP同步原则:
- 当BGP的路由条目也存在于IGP路由表时才对外发送,以图中场景为例,当R3查看IGP路由表,OSPF路由表中并无路由10.0.4.0/24,因此并不会向R5发送该路由,自然也不会产生后续的访问失败问题。
- 解决该问题的方式有:
- 将BGP路由重分发到IGP中,基本不会使用该方式。
- 建立全互联的IBGP对等体关系,让全网所有路由器都拥有BGP路由。
4.BGP的基本配置命令

5.模块总结
如果您认证学完本模块后,您将能够:
- 描述BGP基本概念
- 描述BGP的对等体类型
- 阐明BGP对等体建立过程
- 阐明BGP状态机
- 实现BGP基本配置
三.BGP路径属性及路由反射器
1.前言
- 任何一条BGP路由都拥有多个路径属性(Path Attributes),当路由器通告BGP路由给它的对等体时,该路由将会携带多个路径属性,这些属性描述了BGP路由的各项特征,同时在某些场景下也会影响BGP路由优选的决策。
- IBGP水平分割规则用于防止AS内部产生环路,在很大程度上杜绝了IBGP路由产生环路的可能性,但是同时也带来了新的问题:BGP路由在AS内部只能传递一跳,如果建立IBGP对等体全互联模型又会加重设备的负担。
- 本模块将会介绍BGP路径属性以及路由反射器的相关知识。
2.BGP路径属性
(1)路径属性
- 任何一条BGP路由都拥有多个路径属性。
- 当路由器将BGP路由通告给它的对等体时,一并被通告的还有路由所携带的各个路径属性。
- BGP的路径属性将影响路由优选。
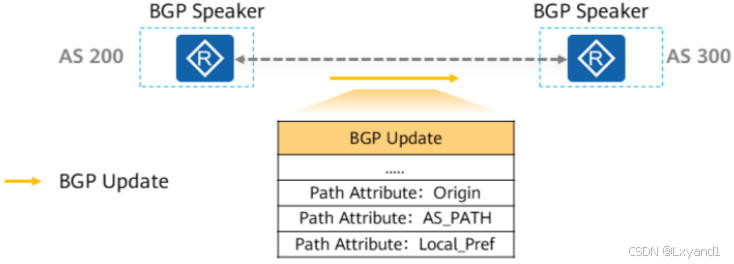
(2)路径属性分类
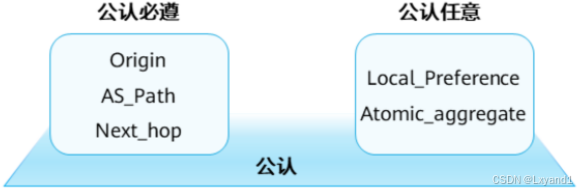
- 公认属性是所有BGP路由器都必须能够识别的属性
- 公认属性可以分为两类:
- 公认必遵(Well-known Mandatory):必须包括在每个Update消息里。
- 公认任意(Well-known Discretionary):可能包括在某些Update消息里。
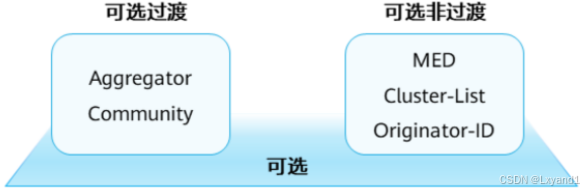
- 可选属性不需要都被BGP路由器所识别
- 可选属性可以分为两类:
- 可选过渡(OptionalTransitive):BGP设备不识别此类属性依然会接受该类属性并通告给其他对等体。
- 可选非过渡(OptionalNon-transitive):BGP设备不识别此类属性会忽略该属性,且不会通告给其他对等体。
(3)公认必遵
【1】AS_Path
a.概要
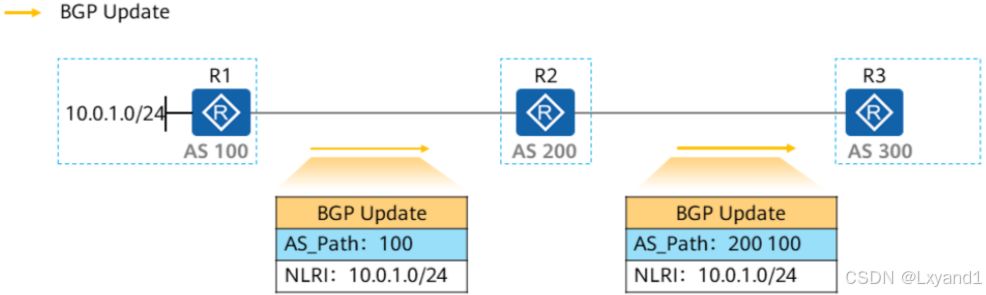
- 该属性为公认必遵属性,是前往目标网络的路由经过的AS号列表。
- 作用:确保路由在EBGP对等体之间传递无环;另外也作为路由优选的衡量标准之一。
- 路由在被通告给EBGP对等体时,路由器会在该路由的AS_Path中追加上本地的AS号;路由被通告给IBGP对等体时,AS_Path不会发生改变。
b.防环
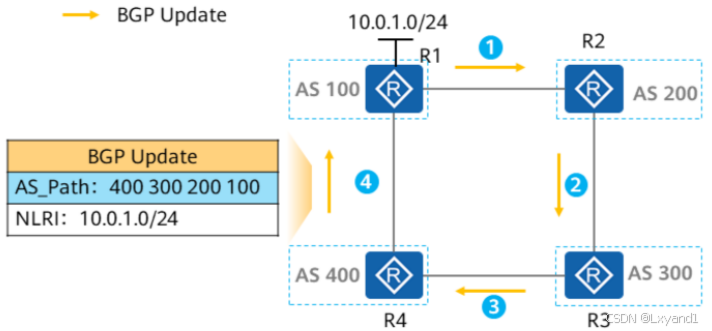
- R1从R4收到的BGP路由更新中AS_Path属性数值为:400 300 200 100,存在自身AS号,不接收该路由,从而防止了路由环路的产生。
c.AS_Path影响路由优选
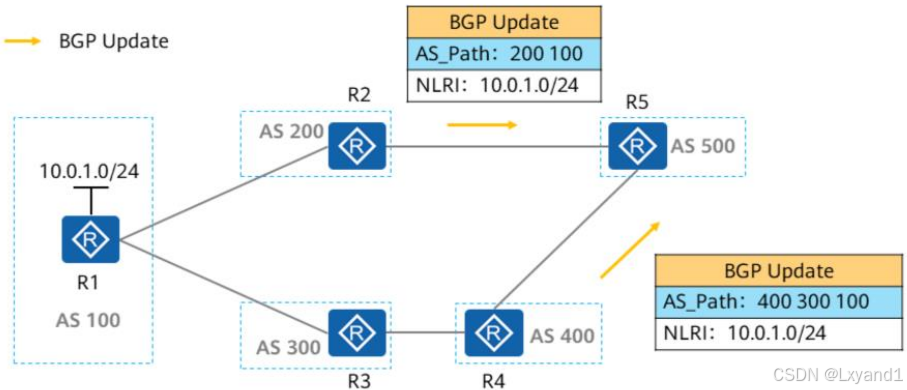
- AS_Path的重要作用之一便是影响BGP路由的优选,在上图中,R5同时从R2及R4学习到去往10.0.1.0/24网段的BGP路由,在其他条件相同的情况下,R5会优选R2通告的路由,因为该条路由的AS_Path属性值较短,也即AS号的个数更少。
d.AS_Path类型
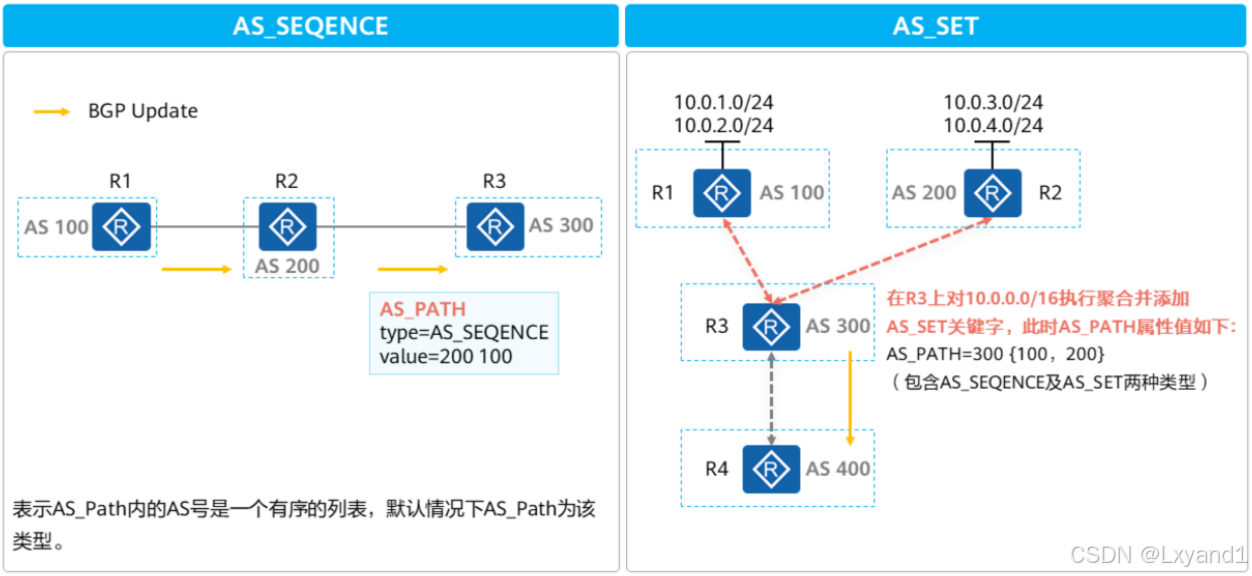
- 路由聚合解决了两类问题,一是减轻了设备的负担,二是隐藏了明细的路由信息,减少了路由震荡的影响。但是路由聚合后,AS Path属性丢失,存在产生环路的风险,为此可以通过AS SET类型的AS Path属性携带聚合前的AS路径信息。
- 当发生路由聚合后,如果需要聚合路由携带所有明细路由中AS Path属性携带的AS号防止环路,则在配置聚合的命令中增加as-set参数。
- 在AS SET的示例中AS 300内发生了路由聚合并配置了as-set参数,则聚合路由会将明细路由的AS Path信息用一个AS-Set集表示(放在中括号几里的AS号信息,该集合内的AS号没有先后顺序),在聚合路由中携带用以防止环路。
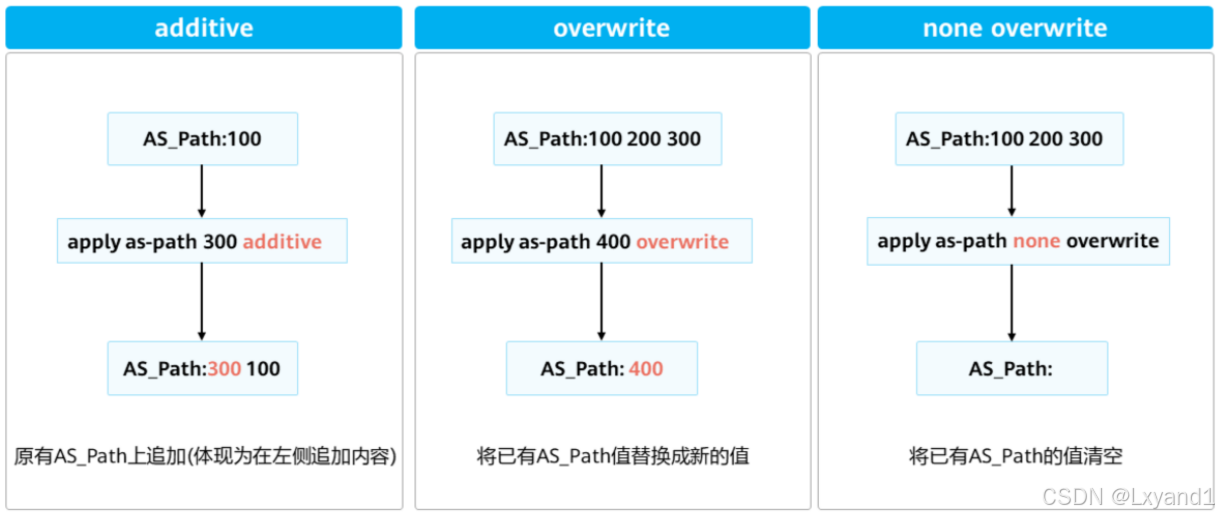
e.修改AS_Path
- 使用Route-Policy修改BGP路由的AS Path属性时,可以使用以下三种方式:
【2】Origin
a.概要

- 该属性为公认必遵属性,它标识了BGP路由的起源。如上表所示,根据路由被引入BGP的方式不同,存在三种类型的Origin。
- 当去往同一个目的地存在多条不同Origin属性的路由时,在其他条件都相同的情况下,BGP将按如Origin的下顺序优选路由:IGP>EGP>Incomplete。
b.Origin在BGP表中的显示

【3】Next_Hop
- 该属性是一个公认必遵属性,用于指定到达目标网络的下一跳地址。
- 当路由器学习到BGP路由后,需对BGP路由的Next_Hop属性值进行检查,该属性值(IP地址)必须在本地路由可达,如果不可达,则这条BGP路由不可用。
- 在不同的场景中,设备对BGP路由的缺省Next Hop属性值的设置规则如下:
- BGP路由器在向EBGP对等体发布某条路由时,会把该路由信息的下一跳属性设置为本地与对端建立BGP邻居关系的接口地址。
- BGP路由器将本地始发路由发布给IBGP对等体时,会把该路由信息的下一跳属性设置为本地与对端建立BGP邻居关系的接口地址。
- 路由器在收到EBGP对等体所通告的BGP路由后,在将路由传递给自己的IBGP对等体时,会保持路由的NextHop属性值不变。
- 如果路由器收到某条BGP路由,该路由的Next Hop属性值与EBGP对等体(更新对象)同属一个网段,那么该条路由的Next Hop地址将保持不变并传递给它的BGP对等体。
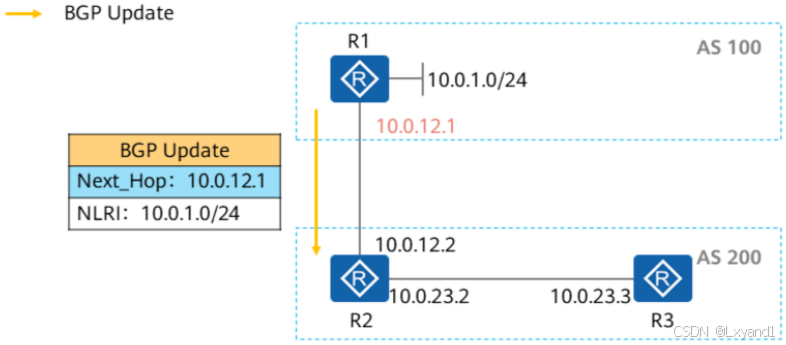
a.Next_Hop的缺省操作1
- 路由器将BGP路由通告给自己的EBGP对等体时,将该路由的Next_Hop设置为自己的TCP连接源地址。
b.Next_Hop的缺省操作2
路由器在收到EBGP对等体所通告的BGP路由后,在将路由传递给自己的IBGP对等体时,会保持路由的Next Hop属性值不变。
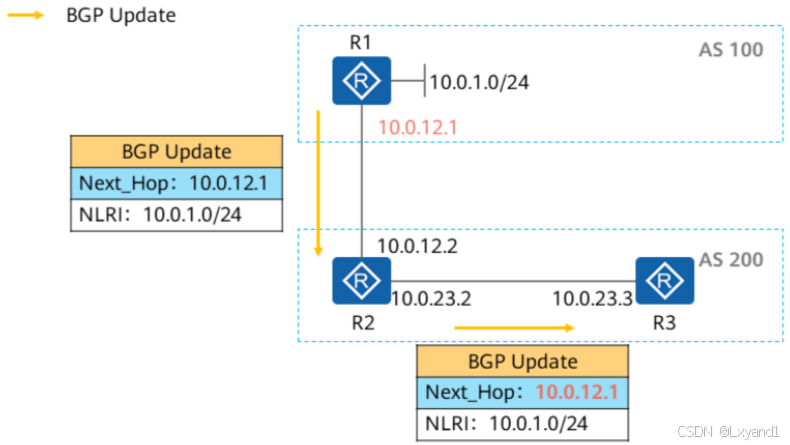
c.Next_Hop的缺省操作3
如果路由器收到某条BGP路由,该路由的Next Hop属性值与EBGP对等体(更新对象)同属一个网段,那么该条路由的Next Hop地址将保持不变并传递给它的BGP对等体。
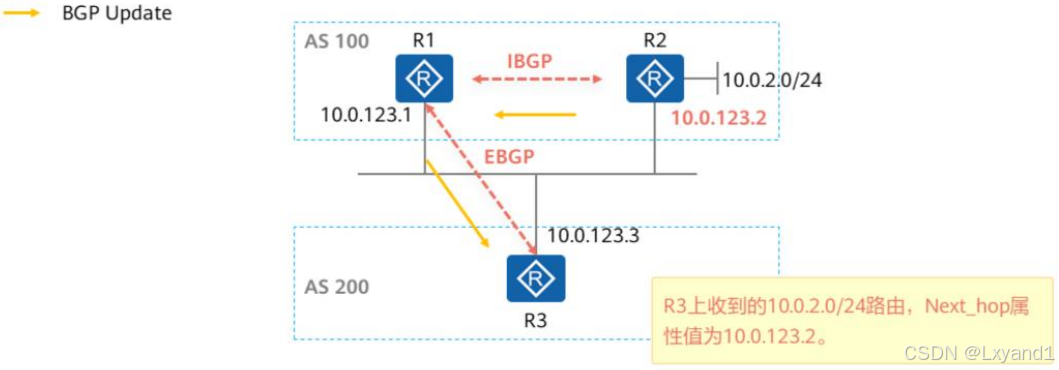
d.修改Next_Hop属性
- 使用peer next-hop-local命令可以在设置向IBGP对等体(组)通告路由时,把下一跳属性设为自身的TCP连接源地址。
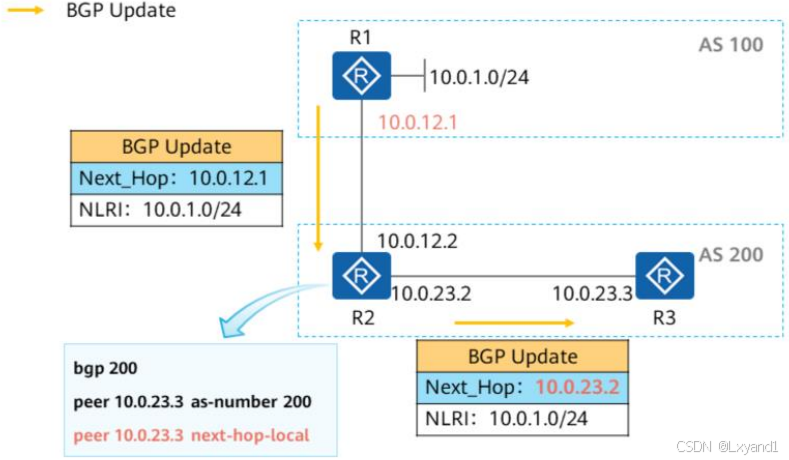
(4)公认任意
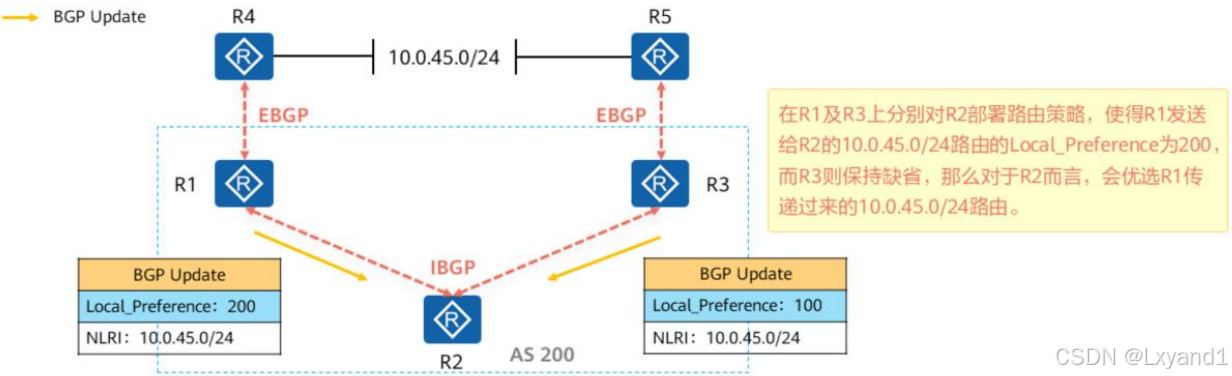
【1】Local_Preference
a.概要
- Local_Preference即本地优先级属性,是公认任意属性,可以用于告诉AS中的路由器,哪条路径是离开本AS的首选路径。
- Local Preference属性值越大则BGP路由越优。缺省的Local Preference值为100。
- 该属性只能被传递给IBGP对等体,而不能传递给EBGP对等体。
b.在BGP路由表中查看Local_Preference

c.Local_Preference注意事项
- Local_Preference属性只能在IBGP对等体间传递(除非做了策略否则Local_Preference值在IBGP对等体间传递过程中不会丢失),而不能在EBGP对等体间传递,如果在EBGP对等体间收到的路由的路径属性中携带了Local Preference,则会进行错误处理。
- 但是可以在AS边界路由器上使用lmport方向的策略来修改LocalPreference属性值。也就是在收到路由之后在本地为路由赋予Local Preference。
- 使用bgp default local-preference命令修改缺省Local Preference值,该值缺省为100。
- 路由器在向其EBGP对等体发送路由更新时,不能携带Local_Preference属性,但是对方接收路由之后,会在本地为这条路由赋一个缺省Local_Preference值(100),然后再将路由传递给自己的IBGP对等体。
- 本地使用network命令及import-route命令引入的路由, Local_Preference为缺省值100,并能在AS内向其他IBGP对等体传递,传递过程中除非受路由策略影响,否则LocalPreference不变。
(5)可选过渡
【1】Community
a.技术背景1
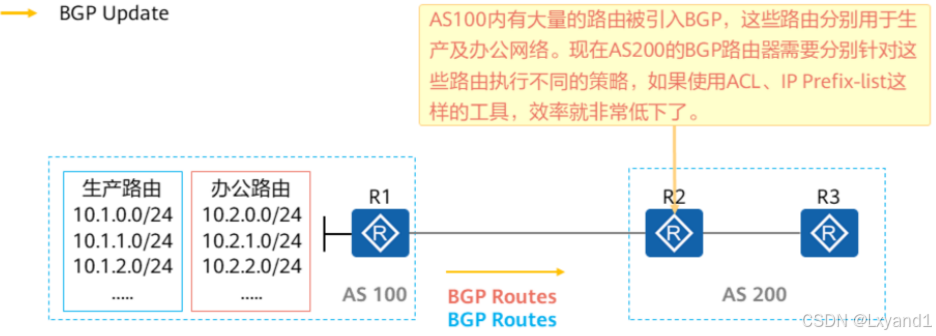
b.技术背景2
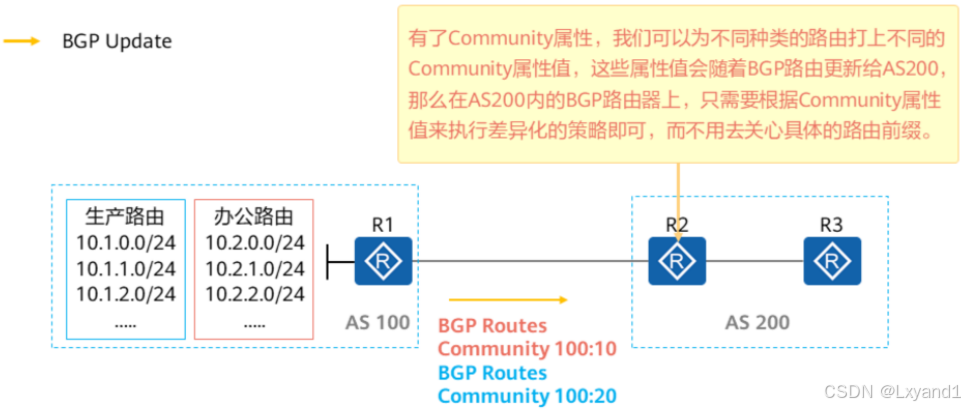
c.Community属性
- Community(团体)属性为可选过渡属性,是一种路由标记,用于简化路由策略的执行。
- 可以将某些路由分配一个特定的Community属性值,之后就可以基于Community值而不是网络前缀/掩码信息来匹配路由并执行相应的策略了。
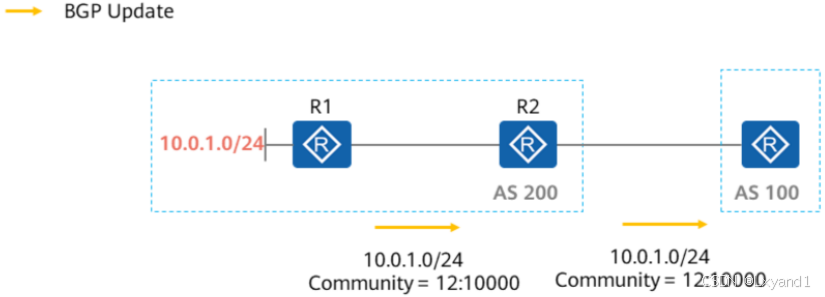
d.格式
- Community属性值长度为32bit,也就是4Byte。可使用两种形式呈现:
- 十进制整数格式。
- AA:NN格式,其中AA表示AS号,NN是自定义的编号。

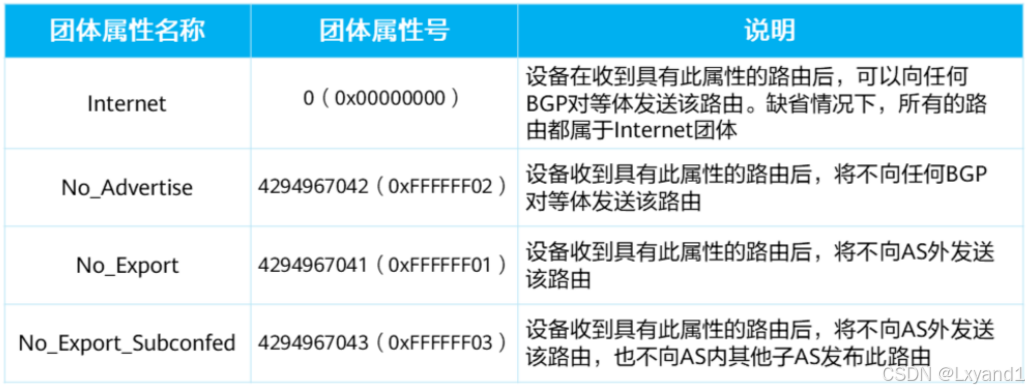
e.公认Community属性
(6)可选非过渡
【1】MED
a.概要
- MED(Multi-Exit Discriminator,多出口鉴别器)是可选非过渡属性,是一种度量值,用于向外部对等体指出进入本AS的首选路径,即当进入本AS的入口有多个时,AS可以使用MED动态地影响其他AS选择进入的路径。
- MED属性值越小则BGP路由越优。
- MED主要用于在AS之间影响BGP的选路。MED被传递给EBGP对等体后,对等体在其AS内传递路由时,携带该MED值但将路由再次传递给其EBGP对等体时,缺省不会携带MED属性。
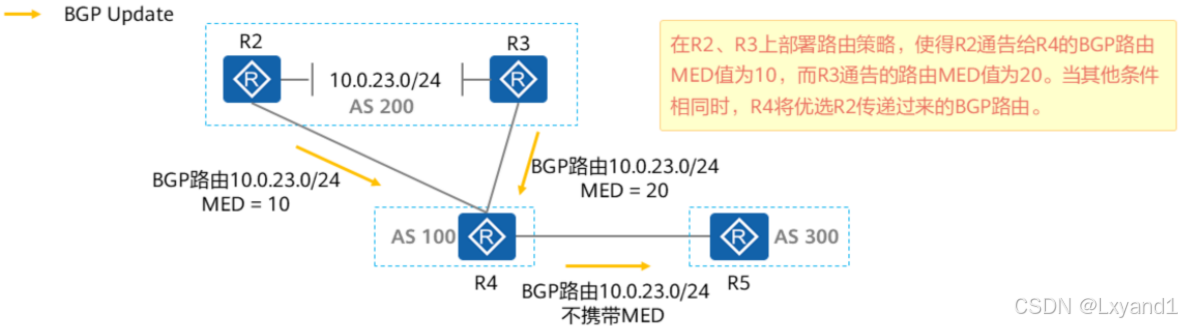
b.一些注意事项
- 缺省情况下,路由器只比较来自同一相邻AS的BGP路由的MED值,也就是说如果去往同一个目的地的两条路由来自不同的相邻AS,则不进行MED值的比较。
- 一台BGP路由器将路由通告给EBGP对等体时,是否携带MED属性,需要根据以下条件进行判断不对EBGP对等体使用策略的情况下):
- 如果该BGP路由是本地始发(本地通过network或import-route命令引入)的,则缺省携带MED属性发送给EBGP对等体。
- 如果该BGP路由为从BGP对等体学习到,那么该路由传递给EBGP对等体时缺省不会携带MED属性。
- 在IBGP对等体之间传递路由时,MED值会被保留并传递,除非部署了策略,否则MED值在传递过程中不发生改变也不会丢失。
c.MED的默认操作1
- 如果路由器通过IGP学习到一条路由,并通过network或import-route的方式将路由引入BGP,产生的BGP路由的MED值继承路由在IGP中的metric。例如图中如果R2通过OSPF学习到了10.0.1.0/24路由,并且该路由在R2的全局路由表中OSPF Cost=100,那么当R2将路由networK进BGP后,产生的BGP路由的MED值为100。
- 如果路由器将本地直连、静态路由通过network或import-route的方式引入BGP,那么这条BGP路由的MED为0,因为直连、静态路由cost为0。
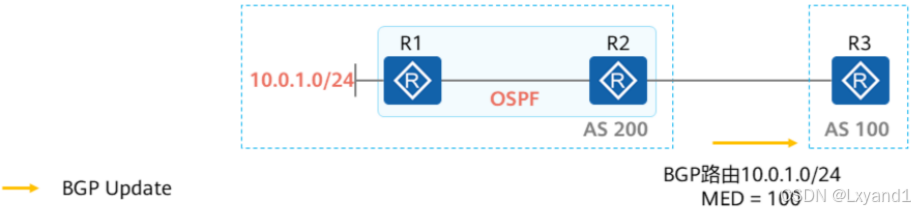
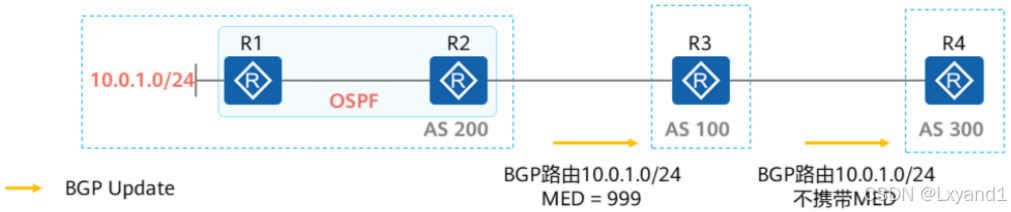
d.MED的默认操作2
- 如果路由器通过BGP学习到其他对等体传递过来的路由,那么将路由更新给自己的EBGP对等体时,默认是不携带MED的。这就是所谓的:“MED不会跨AS传递”。例如在图中,如果R3从R2学习到一条携带了MED属性的BGP路由,则它将该路由通告给R4时,缺省是不会携带MED属性的。
- 可以使用default med命令修改缺省的MED值,default med命令只对本设备上用import-route命令引入的路由和BGP的聚合路由生效。例如在R2上配置default med 999,那么R2通过import-route及aggregate命令产生的路由传递给R3时,路由携带的MED为999。
(7)Atomic_Aggregate及Aggregator
- Atomic_Aggregate属于公认任意属性,而Aggregator属性属于可选过渡属性。
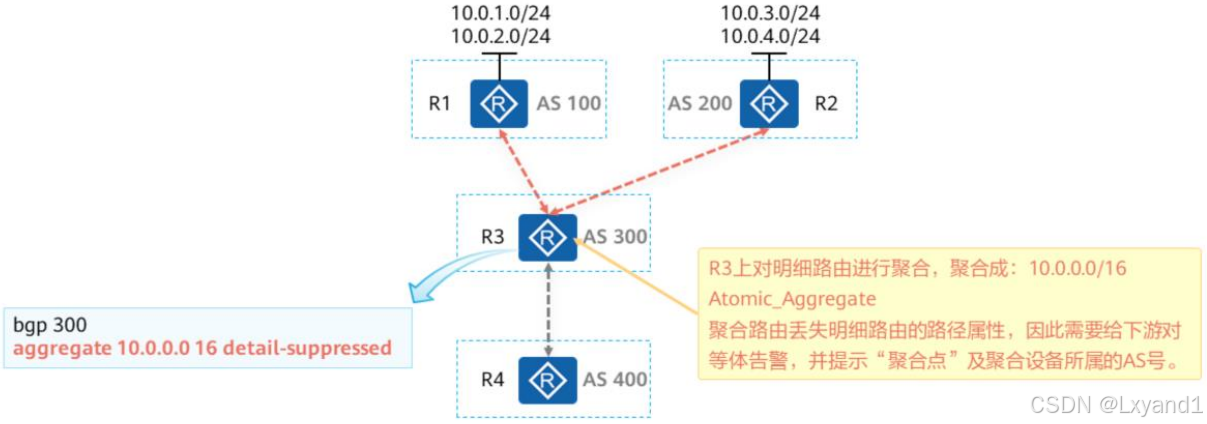
- R3上通过aggregate命令将BGP路由10.0.1.0/24、10.0.2.0/24、10.0.3.0/24、10.0.4.0/24聚合成了10.0.0.0/16,并使用detail-suppressed抑制了明细路由的对外发布,R3只会将聚合后的BGP路由传递给R4,而不传递聚合前的明细路由。
- Atomic _Aggregate是一个公认任意属性,它只相当于一种预警标记,而并不承载任何信息。当路由器收到一条BGP路由更新且发现该条路由携带Atomic_Aggregate属性时,它便知道该条路由可能出现了路径属性的丢失,此时该路由器把这条路由再通告给其他对等体时,需保留路由的Atomic_Aggregate属性。另外,收到该路由更新的路由器不能将这条路由再度明细化。
- 另一个重要的属性是Aggregator,这是一个可选过渡属性,当路由聚合被执行时,执行路由聚合操作的路由器可以为该聚合路由添加Aggregator属性,并在该属性中记录本地AS号及自己的Router-ID,因此Aggregator属性用于标记路由聚合行为发生在哪个AS及哪台BGP路由器上
【1】查看聚合之后的路由
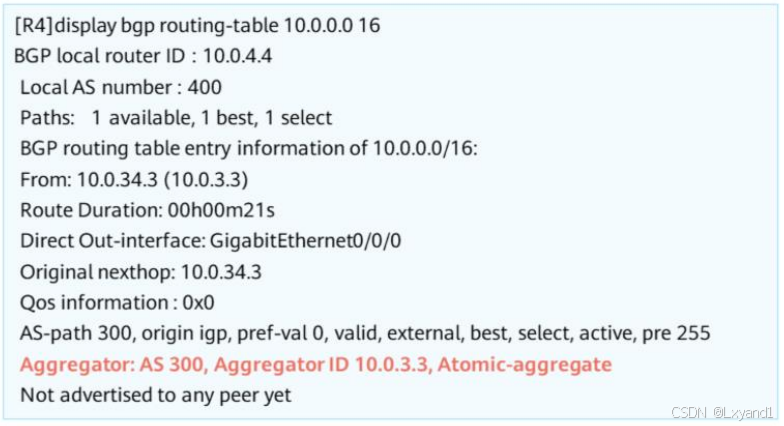
- 在BGP路由详细信息中可与看到Aggregator属性记录了聚合设备的AS号、RouterID,同时通过Atomic-Aggregate属性标明该路由为聚合路由。
(8)Preferred-Value介绍
- Preferred-Value(协议首选值)是华为设备的特有属性,该属性仅在本地有效。当BGP路由表中存在到相同目的地的路由时,将优先选择Preferred-Value值高的路由。
- 取值范围:0~65535;该值越大,则路由越优先。
- Preferred-Value只能在路由器本地配置,而且只影响本设备的路由优选。该属性不会传递给任何BGP对等体。
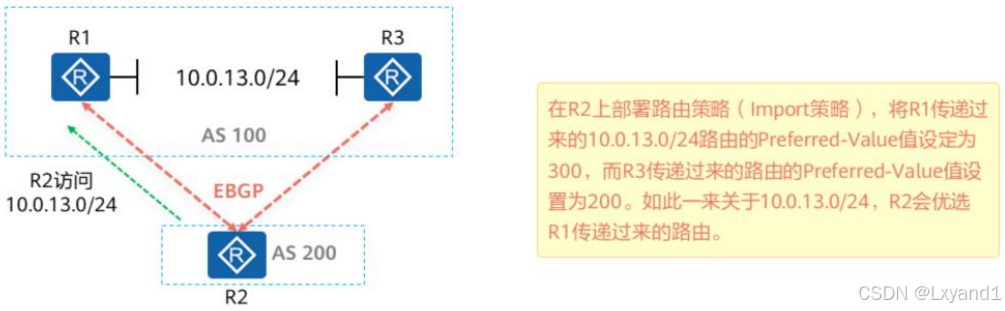
【1】在BGP路由表中查看Preferred-Value
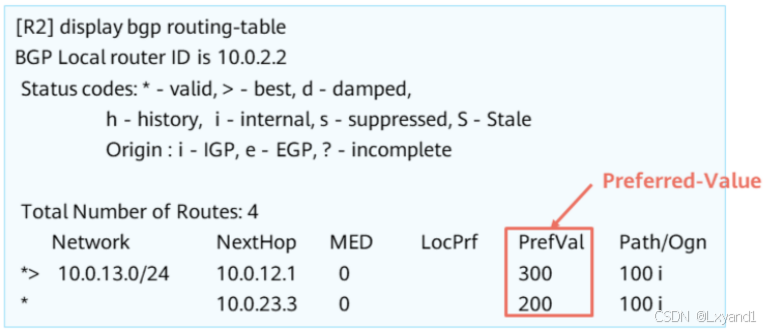
- Preferred-Value为300的BGP路由优于Preferred-Value为200的路由,在BGP路由表中来自10.0.12.1的BGP路由为最优。
3.BGP路由反射器
(1)中转AS中的IBGP问题
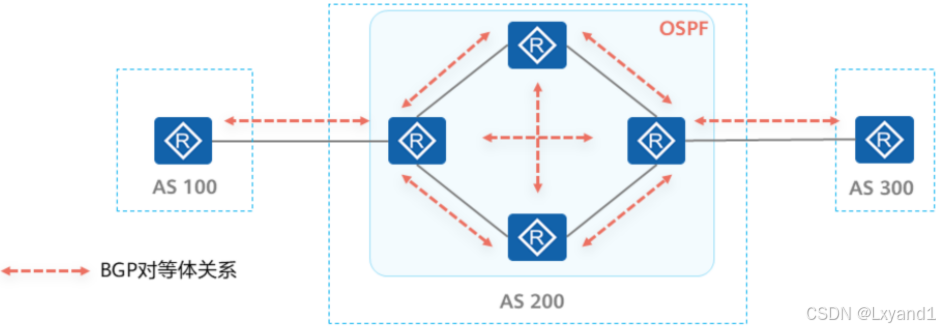
- 由于水平分割的原因,为了保证中转AS200所有的BGP路由器都能学习到完整的BGP路由,就必须在AS内实现IBGP全互联。然而实现IBGP全互联存在诸多短板:
- 路由器需维护大量的TCP及BGP连接,尤其在路由器数量较多时;
- AS内BGP网络的可扩展性较差。
- 为此可以采用路由反射器技术。
(2)路由反射器角色
- 引入路由反射器之后存在两种角色:
- RR(Route Reflector):路由反射器
- Client:RR客户端
- RR会将学习的路由反射出去,从而使得IBGP路由在AS内传播无需建立IBGP全互联。
- 将一台BGP路由器指定为RR的同时,还需要指定其Client。至于Client本身,无需做任何配置,它并不知晓网络中存在RR。
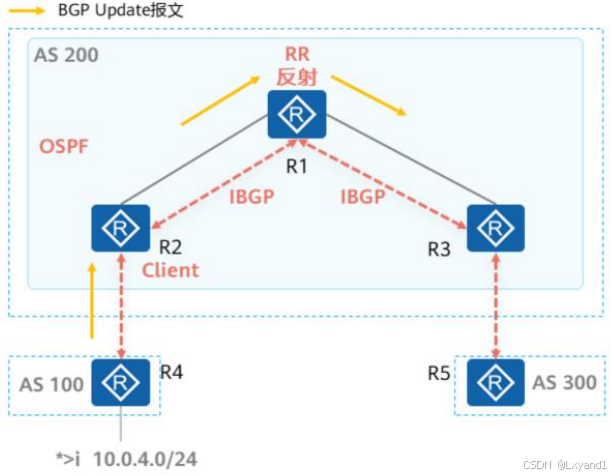
(3)路由反射规则
RR在接收BGP路由时:
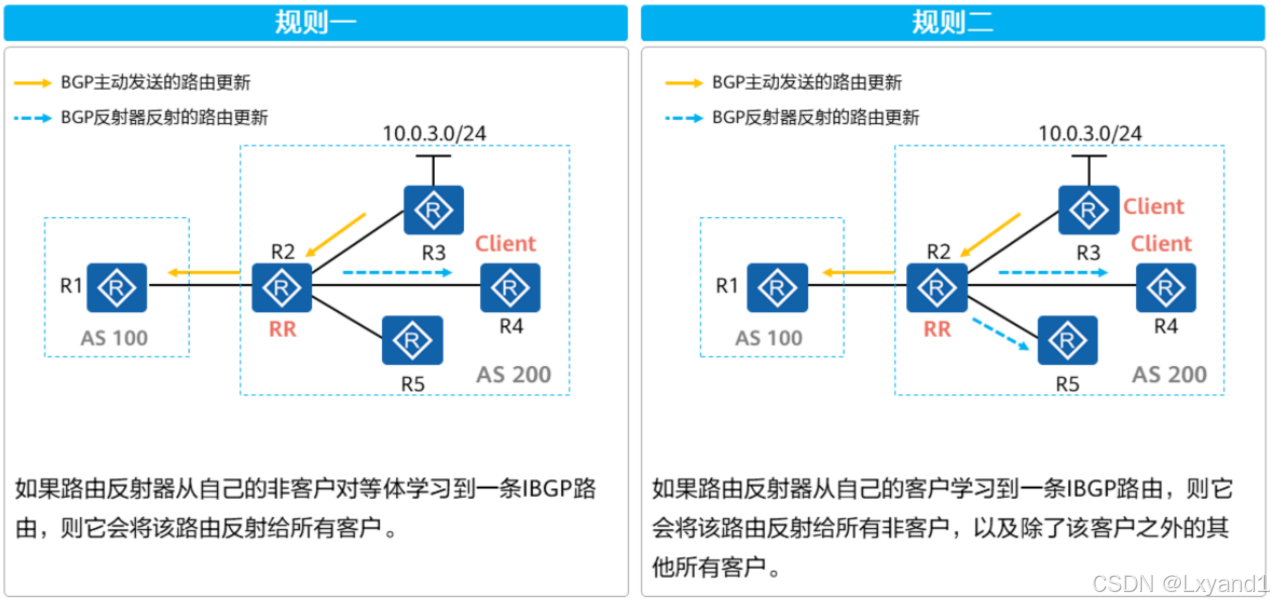
- 如果路由反射器从自己的非客户对等体学习到一条IBGP路由,则它会将该路由反射给所有客户。
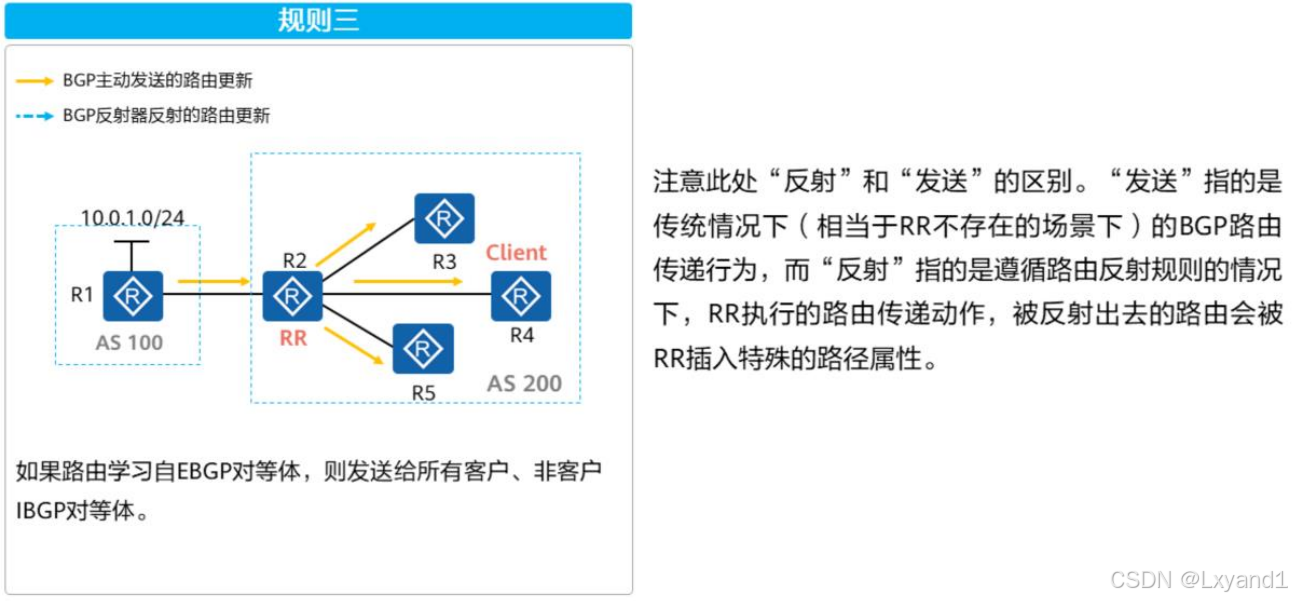
- 如果路由反射器从自己的客户学习到一条IBGP路由,则它会将该路由反射给所有非客户,以及除了该客户之外的其他所有客户
- 如果路由学习自EBGP对等体,则发送给所有客户、非客户IBGP对等体。
【1】反射规则实例1
【2】反射规则实例2
(4)RR场景下的路由防环
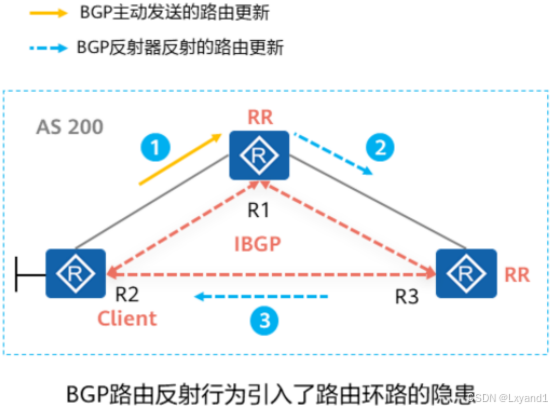
- RR的设定使得IBGP水平分割原则失效,这就可能导致环路的产生,为此RR会为BGP路由添加两个特殊的路径属性来避免出现环路:
- Originator_ID
- Cluster_List
- Originator_lD、Cluster_List属性都属于可选非过渡类型。
【1】Originator_ID
- RR将一条BGP路由进行反射时会在反射出去的路由中增加Originator_ID,其值为本地AS中通告该路由的BGP路由器RouterID。
- 若AS内存在多个RR,则Originator_ID属性由第一个RR创建,并且不被后续的RR(若有)所更改。
- 当BGP路由器收到一条携带Originator_D属性的IBGP路由,并且Originator_ID属性值与自身的RouterID相同,则它会忽略关于该条路由的更新。
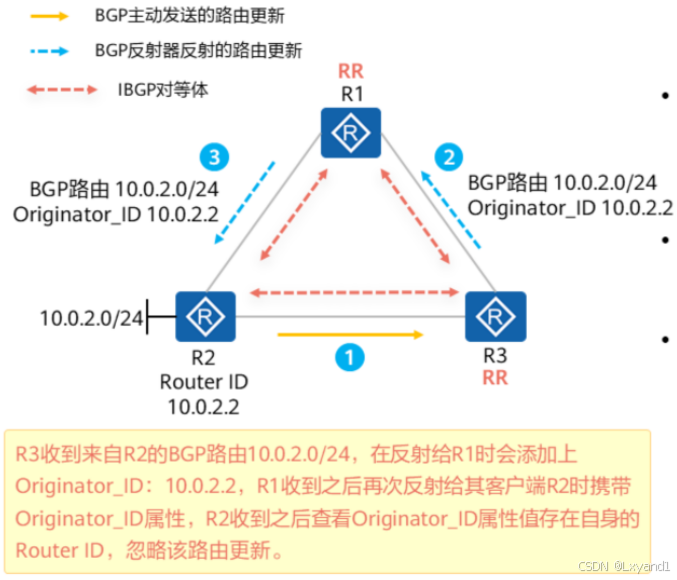
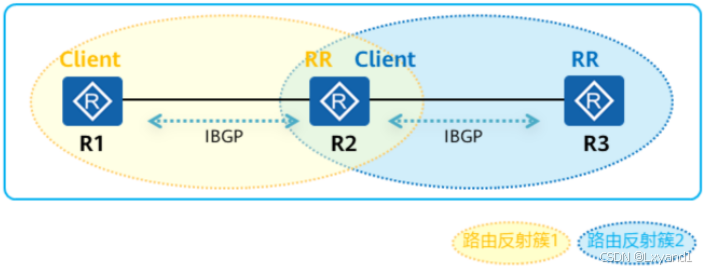
【2】路由反射簇(Cluster)
- 路由反射簇包括反射器RR及其Client。一个AS内允许存在多个路由反射簇(如下图)。
- 每一个簇都有唯一的簇ID(Cluster_ID,缺省时为RR的BGP RouterID)。
- 当一条路由被反射器反射后,该RR(该簇)的Cluster_ID就会被添加至路由的Cluster_list属性中。
- 当RR收到一条携带Cluster_list属性的BGP路由,且该属性值中包含该簇的Cluster_ID时,RR认为该条路由存在环路,因此将忽略关于该条路由的更新。
【3】Cluster_List
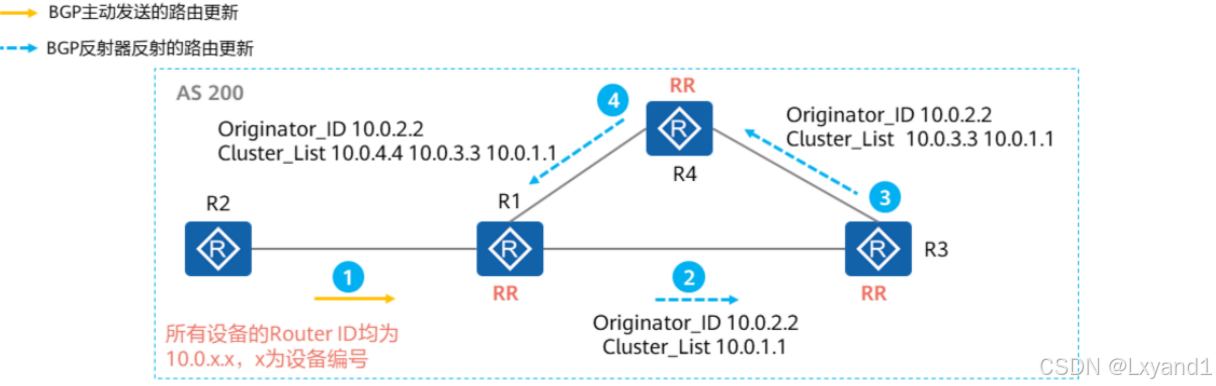
- R2发送给R1的路由,经过R1反射给R3时除了添加Originator_ID之外还会添加Cluster_List:10.0.1.1。R3再次反射给R4时,Cluster List值为:10.0.3.3 10.0.1.1,R4再次反射给R1时Cluster List值为:10.0.4.4 10.0.3.3 10.0.1.1。
- 当R4将路由反射给R1时,R1发现Cluster List包含了自身Cluster ID,判断存在环路,从而忽略该路由更新。
(5)RR应用举例
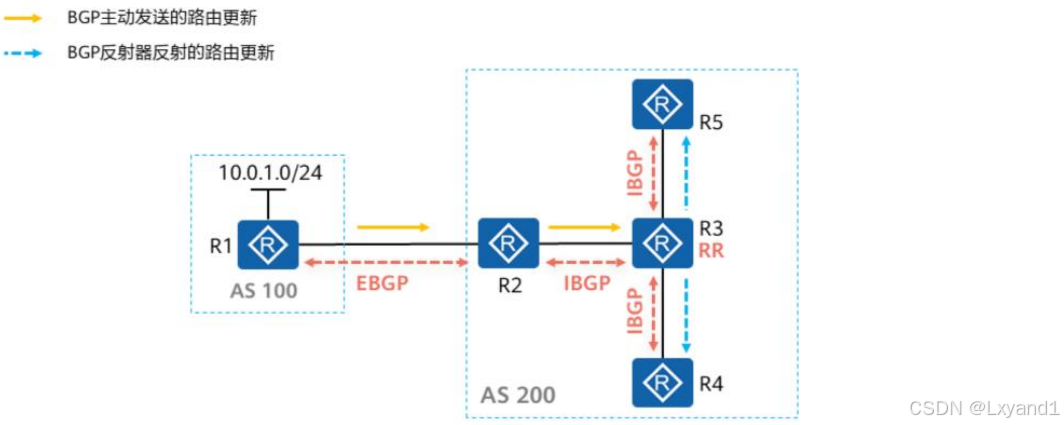
- R1向BGP发布了10.0.1.0/24路由,R2会从R1学习到该路由并且将其通告给R3,但是R3从R2学习到的这条IBGP路由由于水平分割规则的存在故而不能够再被通告给R4及R5,为此可以将R3设置为RR,R4、R5作为其客户端,这样R4、R5即可正常学习到BGP路由10.0.1.0/24。
(6)配置命令介绍

4.模块总结
如果您认证学完本模块后,您将能够:
- 描述BGP常见的路径属性及作用
- 描述BGP路由反射器的概念及应用场景
- 描述BGP路由反射器的规则及工作机制
四.BGP路由优选
1.前言
- BGP是一个应用非常广泛的边界网关路由协议,在全球范围内被大量部署。BGP定义了多种路径属性,并且拥有丰富的路由策略工具,这使得BGP在路由操控和路径决策上变得非常灵活。
- 针对BGP路由的各种属性的操作都可能影响路由的优选,从而对网络的流量产生影响因此掌握BGP路由的优选规则十分重要。
- 本模块将会详细学习BGP路由的优选规则。
2.BGP路由优选规则
当到达同一个目的网段存在多条路由时,BGP通过如下的次序进行路由优选:
- 丢弃下一跳不可达的路由
- 【1】优选Preferred-Value属性值最大的路由
- 【2】优选Local Preference属性值最大的路由。
- 【3】本地始发的BGP路由优于从其他对等体学习到的路由,本地始发的路由优先级:优选手动聚合>自动聚合>network>import>从对等体学到的。
- 【4】优选AS Path属性值最短的路由。
- 【5】优选Origin属性最优的路由。Origin属性值按优先级从高到低的排列是:IGP、EGP及Incomplete。
- 【6】优选MED属性值最小的路由。
- 【7】优选从EBGP对等体学来的路由(EBGP路由优先级高于IBGP路由)。
- 【8】优选到Next Hop的IGP度量值最小的路由。
- 【9】优选Cluster List最短的路由。
- 【10】优选RouterID(Orginator ID)最小的设备通告的路由。
- 【11】优选具有最小IP地址的对等体通告的路由。
总结以上规律就会发现,【1】和【2】取值越大越优,其余的取值越小越优。
注意:前八条属性全部相同时可形成路由负载分担。
3.模块总结
如果您认真学完本模块,您将能够:
- 描述BGP路由优选规则
- 实现BGP路由控制
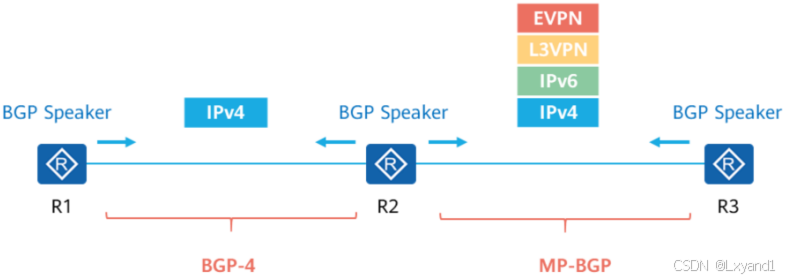
五.MP-BGP 介绍
1.前言
标准BGP-4仅支持IPv4单播地址,为了支持更多的网络层协议,MP-BGP(MultiprotocolExtensions for BGP-4)(RFC4760)被提出作为BGP-4的扩展允许不同类型的地址族在BGP中同时分发,例如IPv4组播、IPv6、L3VPN、EVPN等。
2.MP-BGP
(1)概念
MP-BGP(Multiprotocol Extensions for BGP-4)在RFC4760中被定义,用于实现BGP-4的扩展以允许BGP携带多种网络层协议(例如IPv6、L3VPN、EVPN等)。这种扩展有很好的后向兼容性,即一个支持MP-BGP的路由器可以和一个仅支持BGP-4的路由器交互。
(2)BGP-4扩展
- BGP-4中IPv4特有的三个信息是NEXT_HOP属性、AGGREGATOR和IPV4 NLRI。因此为了支持多种网络层协议,BGP-4需要增加两种能力:
- 关联其他网络层协议下一跳信息的能力。
- 关联其他网络层协议NLRI的能力。
- 这种两种能力被互联网数字分配机构(IANA)统称为地址族(AddressFamily,AF)。
- 为了实现后向兼容性,协议规定MP-BGP增加两种新的属性,MP_REACH_NLRI和MP_UNREACH_NLRI,分别用于表示可达的目的信息和不可达的目的信息。这两种属性都属于可选非过渡。

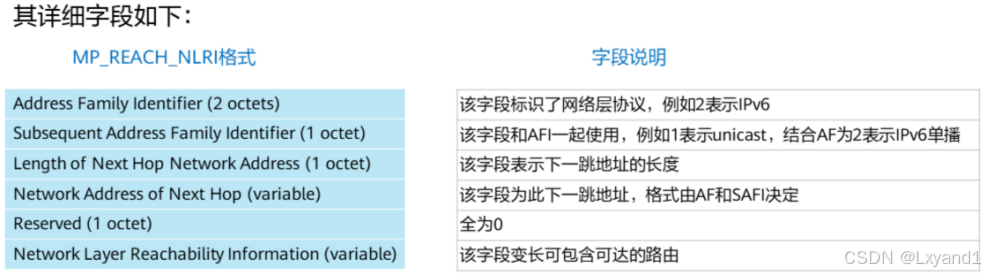
(3)MP_REACH_NLRI
MP REACH NLRI被携带于BGP Update报文中,有以下作用:
- 通告可达的路由给BGP邻居
- 通告可达路由的下一跳给BGP邻居
(4)MP_UNREACH_NLRI
MP UNREACH NLRI被携带于BGP Update报文中,用于撤销不可达的路由。

3.模块总结
如果您认真学完本模块,应该对MP-BGP有一定的初步了解,后续我会持续写EVPN的详解,可以持续关注。
六.BGP高阶属性
1.前言
- 在大型网络中通常会部署BGP,相比于IGP,BGP拥有更加灵活的路由控制能力每一条BGP路由都可以携带多个路径属性,针对其属性也有特有的路由匹配工具,包括:AS_Path Filter和Community Filter。根据实际组网需求,可以实施路由策略,控制路由的接收和发布。
- 同时,为了提升网络性能,BGP提供了各种高级特性以及多种组网部署方案。
- 本模块将介绍BGP路由控制的原理与配置,介绍常用的BGP高级特性,包括:ORF、对等体组、安全特性、4字节AS号,还会介绍BGP路由反射器的组网部署方式。
2.BGP路由控制
(1)概述
BGP路由控制包括控制路由的发布和接收。
- BGP路由控制一般通过路由策略实现,即通过路由匹配工具匹配特定路由,再通过路由策略工具对路由的发布和接收进行控制。
- 路由匹配工具:ACL(AccessControlList,访问控制列表),IP Prefix List(地址前缀列表),AS_Path Filter(AS路径过滤器),CommunityFilter(团体属性过滤器)等。
- 路由策路工具:Filter-Policy和Route-Policy。
- BGP可以通过匹配AS_Path和Community等属性进行路由控制。
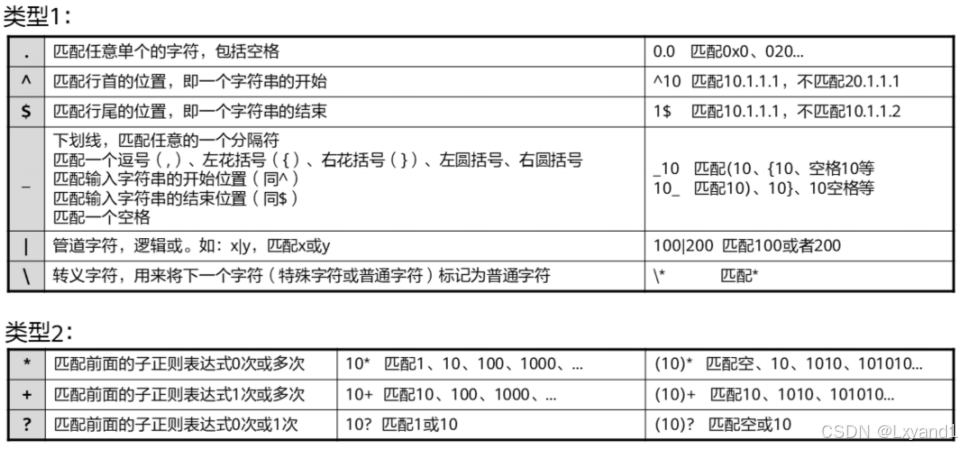
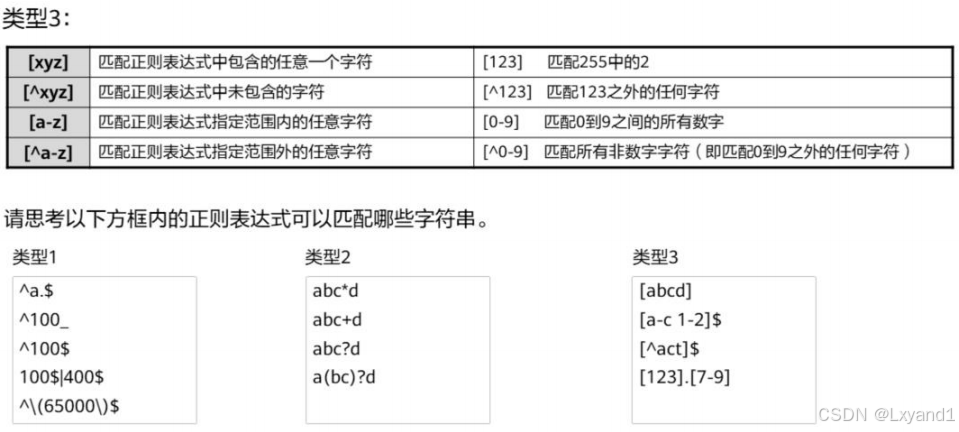
(2)正则表达式
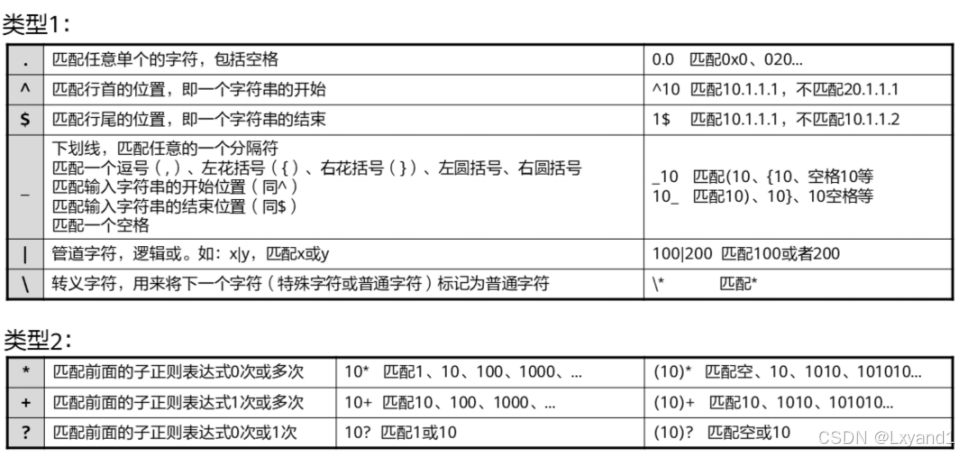
- 正则表达式是按照一定的模板来匹配字符串的公式,由普通字符(如字符a到z)和特殊字符组成。
- 普通字符:匹配的对象是普通字符本身。
- 包括所有的大写和小写字母、数字、标点符号以及一些特殊符号。
- 例如:a匹配abc中的a,10匹配10.113.25.155中的10,@匹配xxx@xxx.com中的@。
- 特殊字符:配合普通字符匹配复杂或特殊的字符串组合。
- 位于普通字符之前或之后用来限制或扩充普通字符的独立控制字符或占位符。
- 用来描述它前面的字符的重复使用方式。
- 限定一个完整的范围。
【1】特殊字符举例1
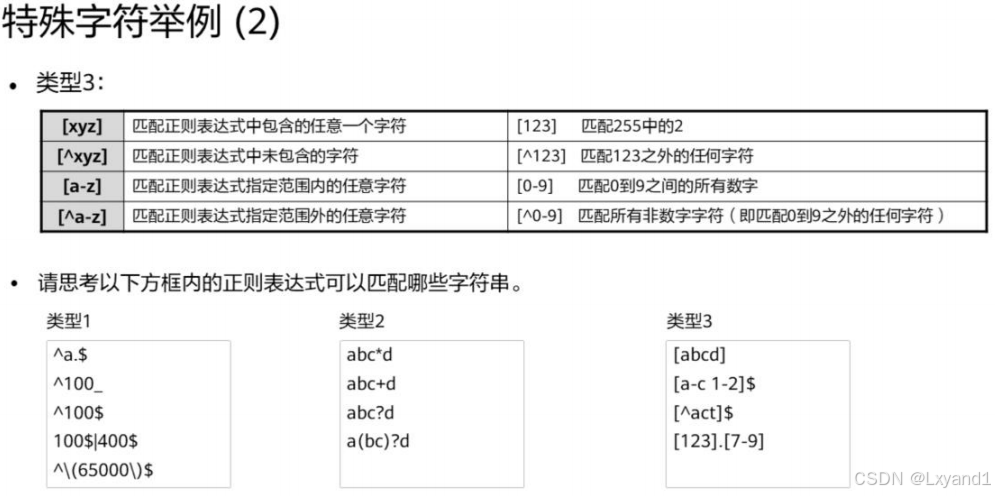
【2】特殊字符举例2
(3)路由匹配工具:AS_Path Filter
【1】概述
- AS Path Filter是将BGP中的AS Path属性作为匹配条件的过滤器,利用BGP路由携带的AS Path列表对路由进行过滤。
- 在不希望接收某些AS的路由时,可以利用AS Path Filter对携带这些AS号的路由进行过滤,从而实现拒绝某些路由。
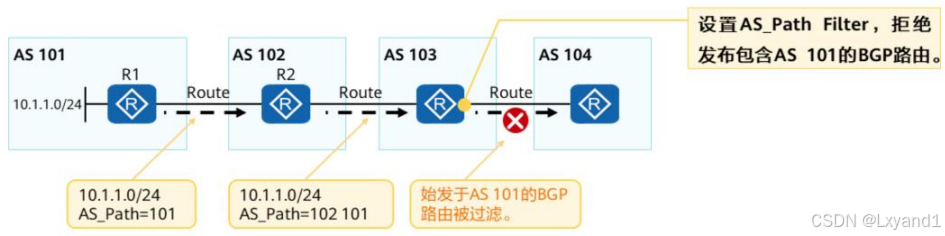
【2】使用正则表达式匹配AS_Path

【3】AS_Path Filter的基础配置命令

(4)路由匹配工具:Community Filter
【1】概述
- community Filter与Community属性配合使用,可以在不便使用IP Prefix List和AS Path Filter时降低路由管理难度。
- 团体属性过滤器有两种类型:
- 基本Community Filter。匹配团体号或公认Community属性。
- 高级Community Filter。使用正则表达式匹配团体号
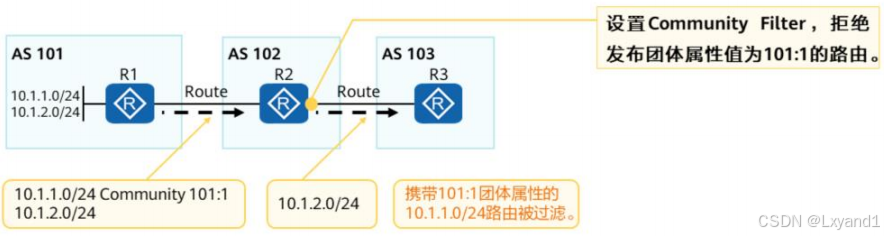
【2】设置Community的基础配置命令


3.BGP特性介绍
(1)ORF
【1】邻居按需发布路由
如果设备希望只接收自己需要的路由,但对端设备又无法针对每个与它连接的设备维护不同的出口策略。此时,可以通过配置BGP基于前缀的ORF(Outbound Route Filters,出口路由过滤器来满足两端设备的需求。
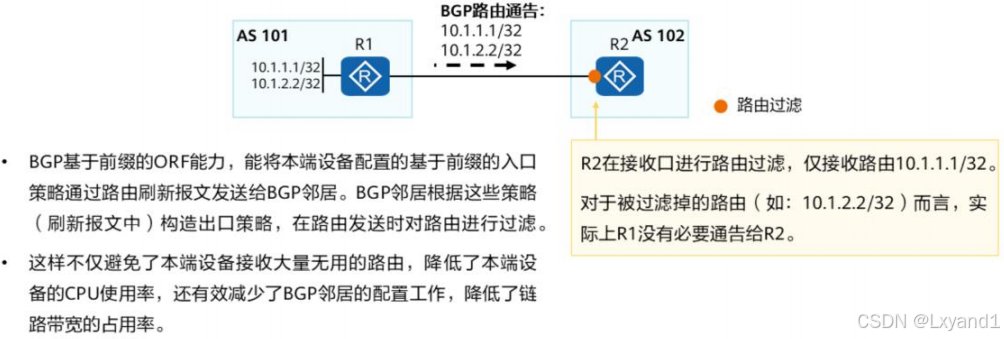
【2】ORF的基础配置命令

【3】ORF配置举例

【4】查看ORF
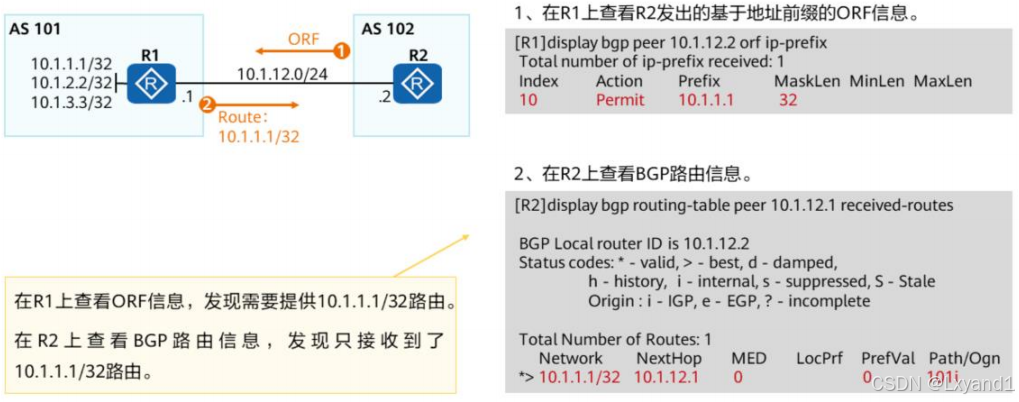
(2)BGP对等体组
【1】概述
对等体组(Peer Group)是一些具有某些相同策略的对等体的集合。当一个对等体加入对等体组中时,该对等体将获得与所在对等体组相同的配置。当对等体组的配置改变时,组内成员的配置也相应改变。
在大型BGP网络中,对等体的数量会很多,其中很多对等体具有相同的策略,在配置时会重复使用一些命令,利用对等体组可以简化配置。
【2】对等体组的基础配置命令

【3】对等体组配置举例
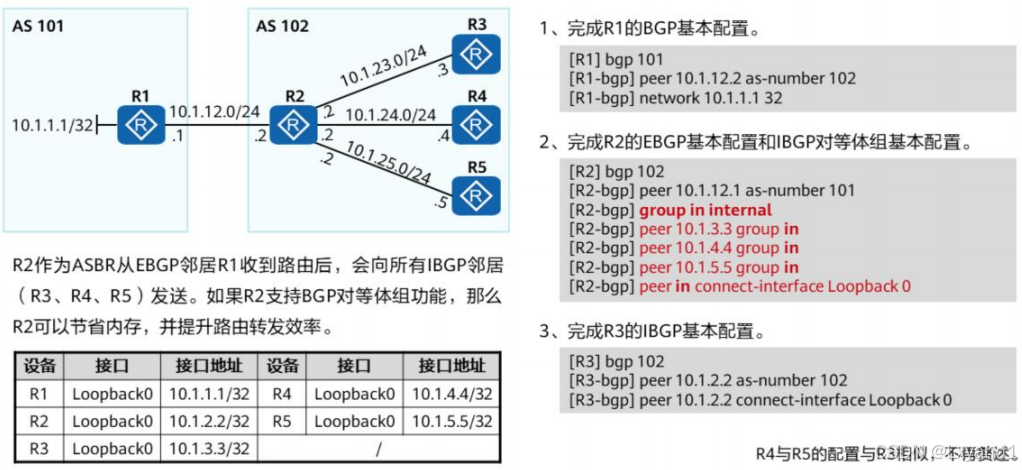
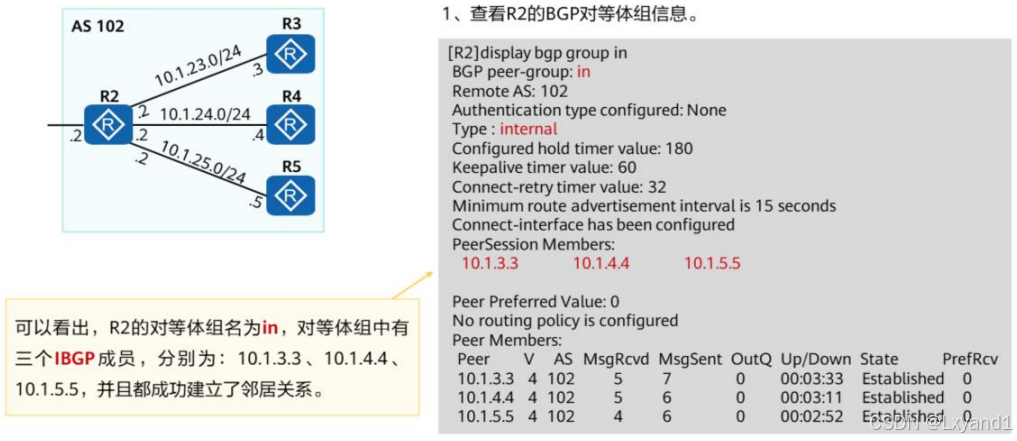
【4】查看对等体组配置
(3)BGP安全特性
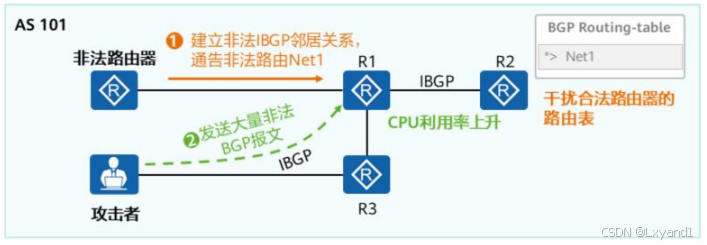
常见BGP攻击主要有两种:
- 建立非法BGP邻居关系,通告非法路由条目,干扰正常路由表。
- 发送大量非法BGP报文,路由器收到后上送CPU,导致CPU利用率升高
- BGP使用认证和GTSM(Generalized TTL Security Mechanism,通用TTL安全保护机制)两个方法保证BGP对等体间的交互安全。
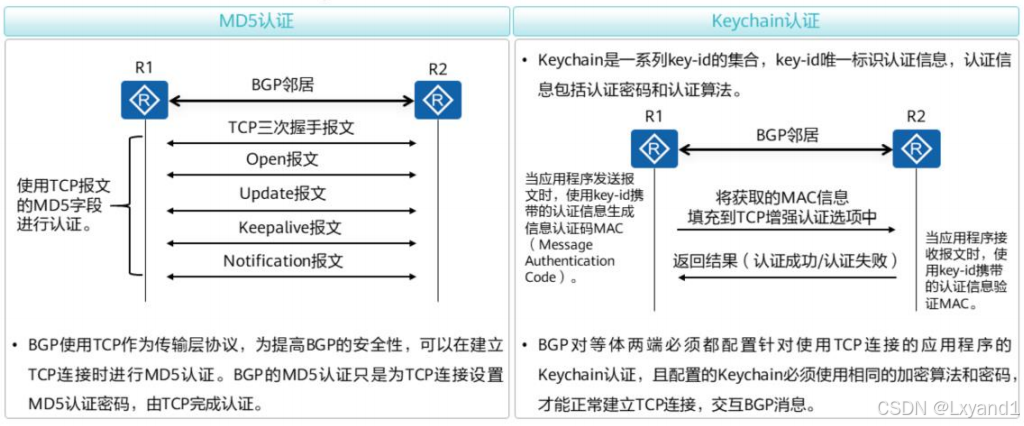
【1】BGP认证
BGP认证分为MD5认证和Keychain认证,对BGP对等体关系进行认证可以预防非法BGP邻居建立。
- 注意:BGP的MD5认证与BGP的Keychain认证互斥。
【2】BGP的GTSM
BGP的GTSM功能检测IP报文头中的TTL(Time-to-Live)值是否在一个预先设置好的特定范围内并对不符合TTL值范围的报文进行丢弃,这样就避免了网络攻击者模拟“合法”BGP报文攻击设备。

【3】BGP认证的基础配置命令

【4】GTSM功能的基础配置命令

(4)4字节AS号
- 随着网络规模的扩大,可分配的AS号已经濒临枯竭。
- 目前网络上使用的AS号范围为1至65535(2字节),需要将AS号范围扩展为1至4294967295(4字节),6支持4字节AS号的BGP设备能够与仅支持2字节AS号的BGP设备兼容。

4.BGP路由反射器组网方式
(1)备份RR组网
- 为增加网络的可靠性,防止单点故障对网络造成影响,有时需要在一个集群中配置一个以上的RR。
- 转发路径上的路由器与所有RR均建立IBGP关系,任意一个RR均有完整的BGP路由。
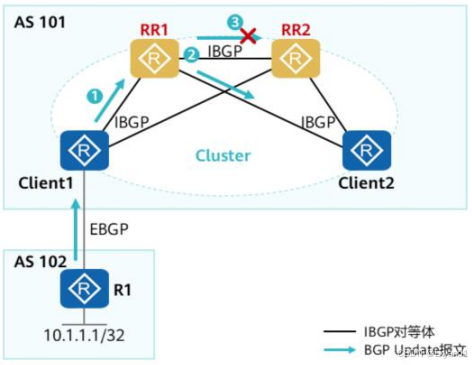
- RR1和RR2在同一个集群内,配置了相同的ClusterID。
- 单级RR组网路由反射原理(图示以RR1的反射路径为例):
- 当客户机Client1从EBGP对等体接收到一条更新路由,它将通过IBGP向RR1和RR2通告这条路由。
- RR1和RR2在接收到该更新路由后,将本地Cluster ID添加到Cluster List前面,然后向其他的客户机(Client2)反射,同时相互反射。
- RR1和RR2在接收到该反射路由后,检查Cluster List,发现自己的Cluster ID已经包含在Cluster List中。于是RR1和RR2丢弃该更新路由,从而降低BGP的内存占用。
(2)多集群RR组网1
- 一个AS中可以存在多个集群,各个集群的RR之间建立IBGP对等体。
- 当RR所处的网络层相同时,可以将不同集群的RR全互联,形成同级RR。
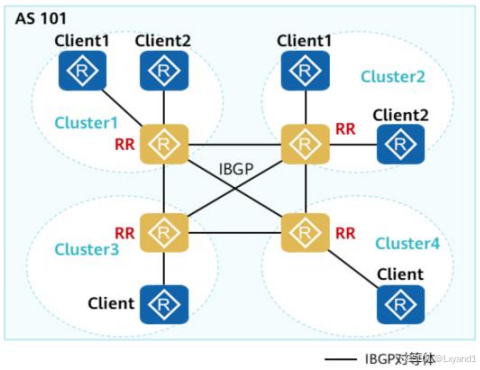
- 一个骨干网AS可能被分成多个集群。各集群的RR互为非客户机关系,并建立IBGP全互联。
- 此时虽然每个客户机只与所在集群的RR建立IBGP连接,但所有RR和客户机都能收到全部路由信息。
- 如图所示:四个RR分别处于Cluster1、Cluster2、Cluster3、Cluster4中,它们之间互相建立IBGP连接,而每个客户机只与所在集群内的RR建立IBGP连接。
(3)多集群RR组网2
- 当RR所处的网络层不同时,可以将较低网络层次的RR配成客户机,形成分级RR。
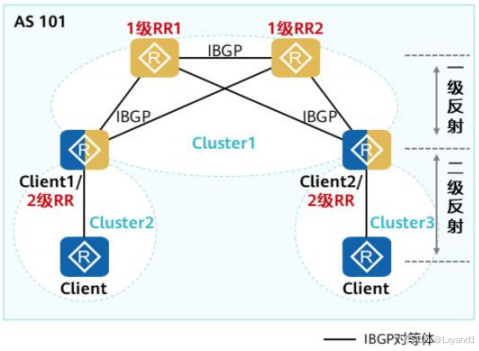
- 在实际的RR部署中,常用的是分级RR的场景。
- 如图所示,AS 101内部分为三个集群:
- 其中Cluster1内的四台设备是核心路由器,采用备份RR的形式保证可靠性。Cluster1部署了两个1级RR,其余两台路由器作为1级RR的客户机。
- Cluster2和Cluster3中分别部署了一个2级RR,而2级RR同时也是1级RR的客户机。两个2级RR之间无需建立IBGP连接关系。
(4)单集群问题
- 为了在基于RR的架构中提供所期望的冗余,正确的集群划分是非常重要的。
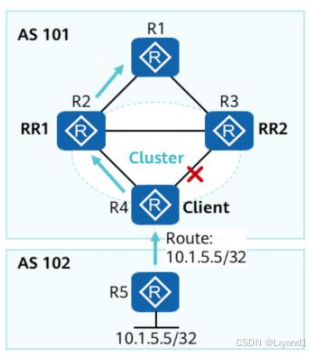
场景描述:
- 如图AS 101采用备份RR组网,RR1和RR2使用相同的ClusterID,两台RR为R1访问10.1.5.5/32提供了冗余链路。
- R4通告了10.1.5.5/32路由后,两台RR向R1通告,并相互之间通告。由于RR1和RR2有相同的ClusterID,因此RR之间的更新消息会被丢弃。
IBGP会话失效导致冗余失效:
- 假设R3和R4间的IBGP会话失效(如:错误配置),由于R3忽略R2通告的10.1.5.5/32的路由,因此R1访问10.1.5.5/32就没有了冗余链路。
(5)多集群设计
- 多集群设计不仅提供了针对链路失效的物理冗余,同时提供了针对客户机与RR之间的IBGP会话失效的逻辑冗余。
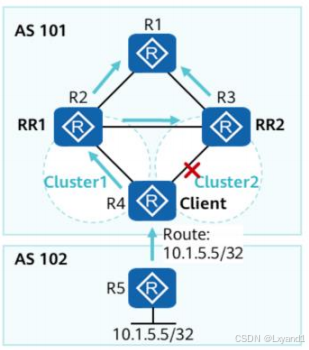
- 如图:将R2和R4划入Cluster1中,将R3和R4划入Cluster2中。
- 当R3和R4间的IBGP会话失效后,R3仍然可以继续转发流量,因为R3会学习R2通告的10.1.5.5/32路由。
5.模块总结
如果您认真学完本模块后,您将能够:
- 在配置AS Path Filter和Community Filter过程中使用正则表达式
- 使用AS Path Filter和Community Filter实现BGP路由控制
- 应用BGP的ORF功能、对等体组功能
- 实现BGP安全的基本配置
- 描述4字节AS号的概念及使用方法
- 描述BGP路由反射器的组网方式
七.BGP的详细配置
说明:这部分会分为五个板块,分别为BGP基本配置,BGP选路原则,BGP高级部分,BGP路由控制,BGP负载均衡,然后在每个板块都会有小的实验组成,共计29个实验,会陆续更新,请持续关注。同时我也会更新实验在BGP的专栏里面。可私信催更
1.BGP的基本配置
(1)实验1.1 建立基本的BGP邻居关系
关于IP 地址,如无特殊说明,都是以如下方式规划:1.每个路由器都有一个loopback0 接口,IP 地址是 10.1.x.x/32,x是路由器的号码2.路由器相连的接口IP 和路由器的号码相关,比如 AR1与 AR2 相连链路的接口 IP 分别为10.1.12.1/24和 10.1.12.2/24。
【1】实验目的
熟练掌握:
- BGP的基本配置
- 启动BGP路由进程
- IBGP邻居配置
- EBGP邻居配置
- BGP路由更新源配置
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
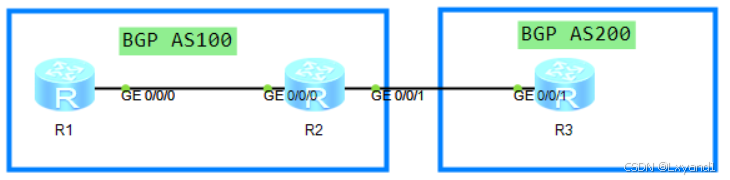
【3】实验拓扑
【4】实验步骤
如图所示,本实验在R1和R2之间配置IBGP邻居关系,在R2和R3配置EBGP邻居关系。
一般情况下,为了让IBGP 邻居关系更稳定,我们都会用环回口来建邻居。所以,基础配置是先确保底层可达(IGP建立),也就是让AR1、AR2的环回口可达,本实验 IGP 协议采用 OSPF。
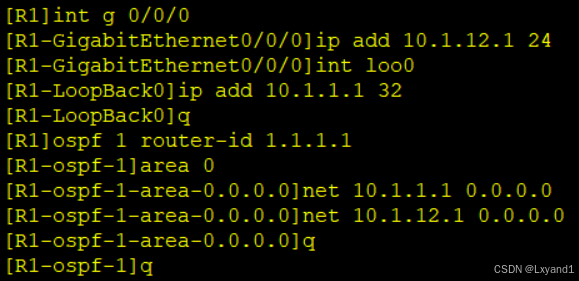
a.配置 IP 地址,配置 OSPF 协议。
在AR1上:
在AR2上:
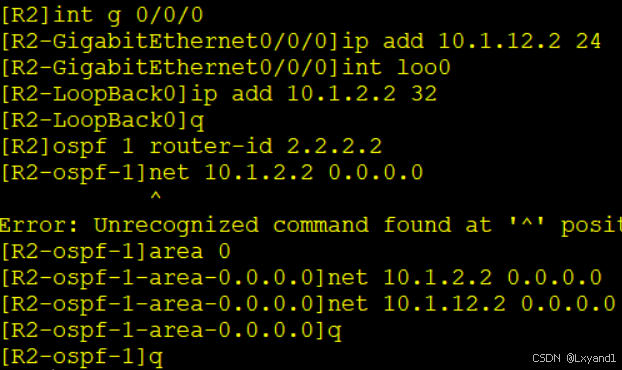
b.配置AR1与AR2之间的IBGP邻居关系
在AR1上:

在AR2上:

c.配置AR2与AR3之间的EBGP邻居关系
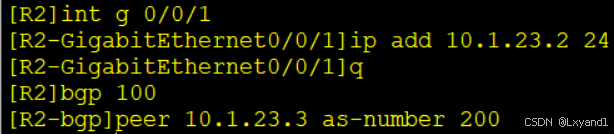
AS之间一般不会运行IGP协议,所以EBGP邻居我们一般都是有直连的地址来建立。
在AR2上:
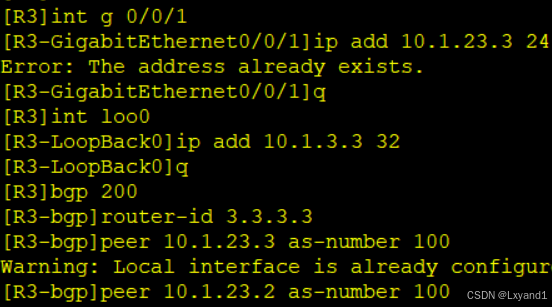
在AR3上:
d.在R2查看邻居关系状态
(2)实验 1.2 路由信息的通告
【1】实验目的
熟练掌握产生BGP路由的两种方法
Network方式
引入路由方式
解决下一跳不可达的情况
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
注意,此实验是在实验1.1的基础之上完成的
a.在R3上用network宣告的方式产生一条BGP路由

b.在R1上用引入的方式产生BGP的路由
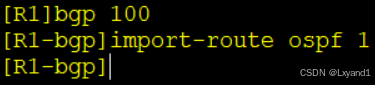
c.在R2查看bgp路由
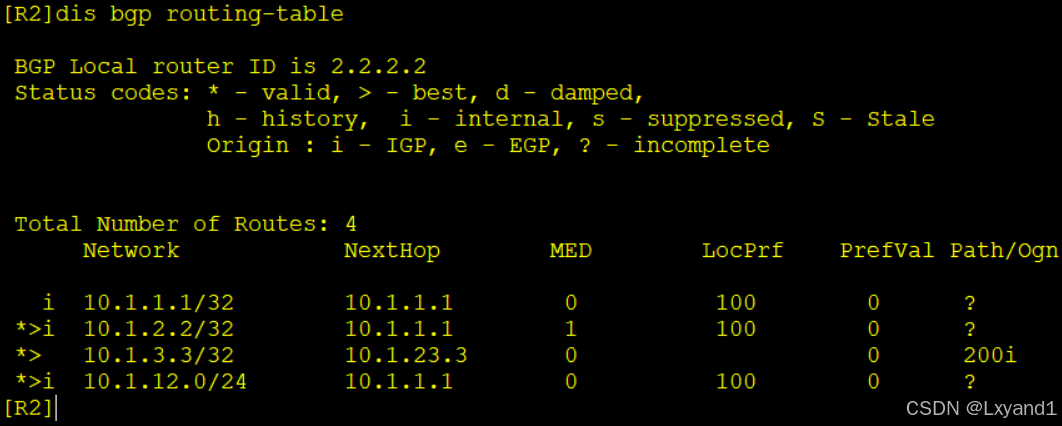
d.解决下一跳不可达情况
再去R1上查看一下BGP表:
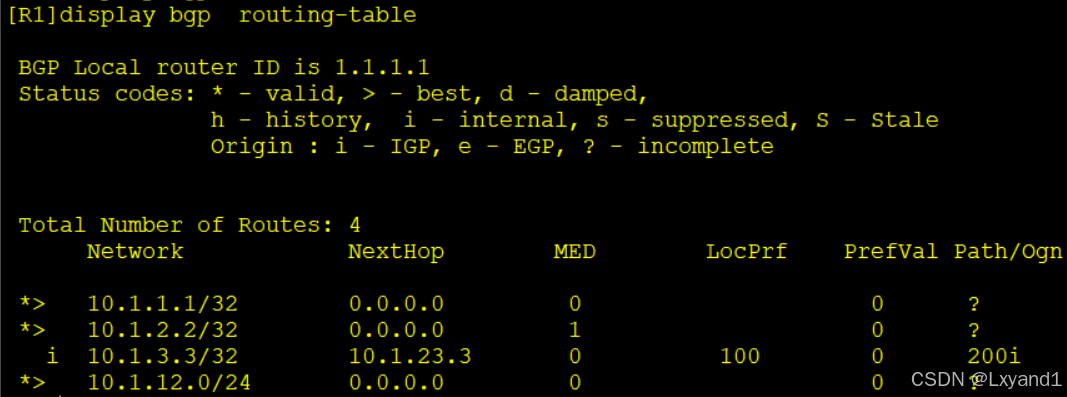
我们注意到在 10.1.3.3/32 这条路由的前面没有“*>”,说明这条路由是无效且不优的,无效不优的路由不会传给其他路由器,同时本路由也不会装载进全局IP 路由表里。无效不优的原因是因为下一跳不可达,造成这下一跳不可达的原因是因为 IBGP 邻居在传路由的时候不会改变路由的下一跳属性。所以在IBGP的邻居关系中,我们常常都会用下现的命令来让下一跳是可达的:
在AR2上:

- 配置下一跳本地,即对从EBGP邻居传入的路由,在将EBGP学习到的路由通告给IBGP邻居时,修改下一跳地址为本地connect interface。
再去AR1上查看:
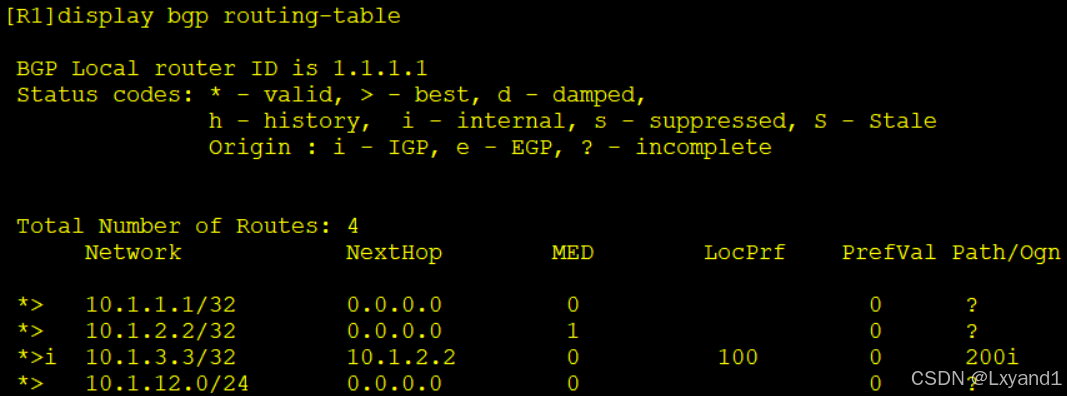
以上表示这条路由变优化了,因为下一跳变为可达了,就是R1能去R3了。
(3)实验 1.3 理解同步及解决路由黑洞
【1】实验目的
理解同步及路由黑洞的概念
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑

【4】实验步骤
- 如图所示,AR1,AR2,R3 之间运行 ospf,让 AR1 与 AR3 的环回口可达。
- 在 AR1 与 AR3 之间起 IBGP 的邻居关系。有环回口建立 IBGP 的邻居关系。
- 在 AR3 与 AR4 之间起 EBGP 邻居关系,用直连接口建立邻居。
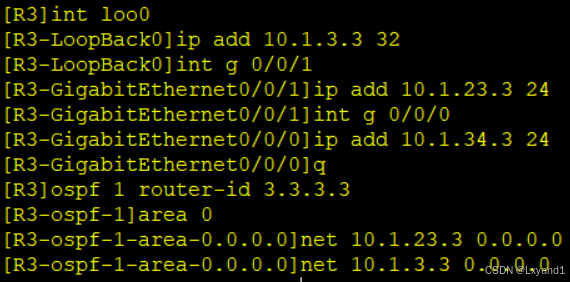
a.先配好 IP 地址:
在AR1上:
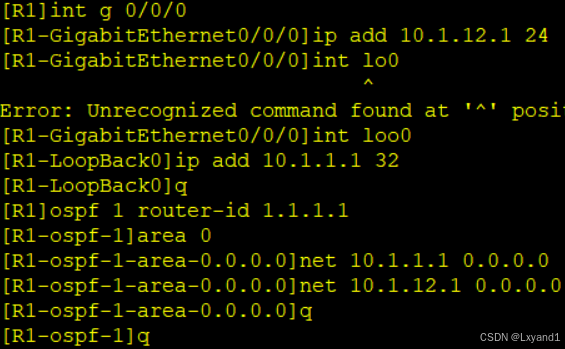
在AR2上:
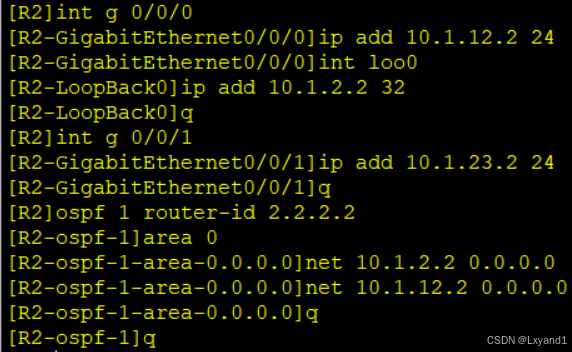
在AR3上:
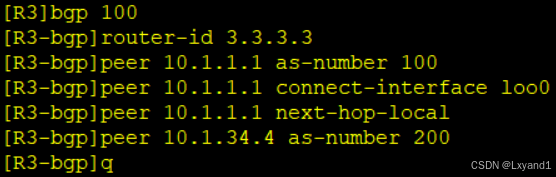
b.在AR1与AR3之间配置IBGP的邻居关系
在AR1上:
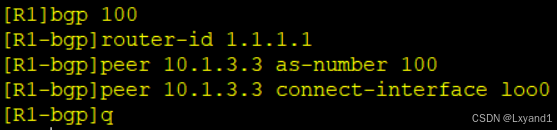
在AR3上:
c.配置AR3和AR4的EBGP邻居关系
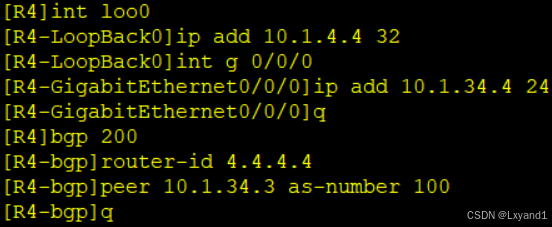
d.接下来在AR1上产生一条BGP路由
在AR1上:
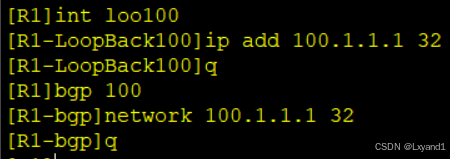
我们去AR3上分别查看BGP表和路由表:
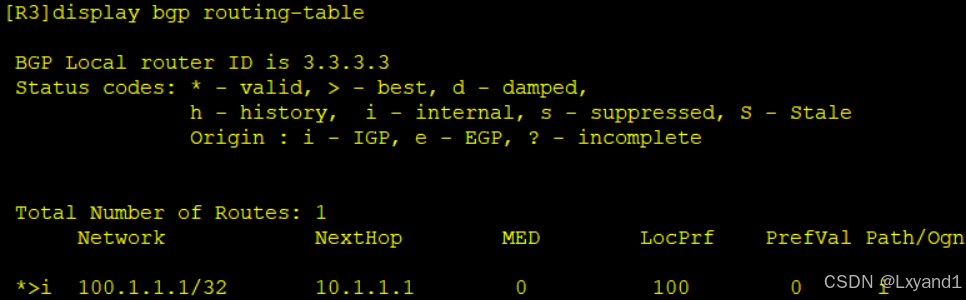
我们发现R3正常的学习到了这条路由
再去AR4上查看BGP表项:
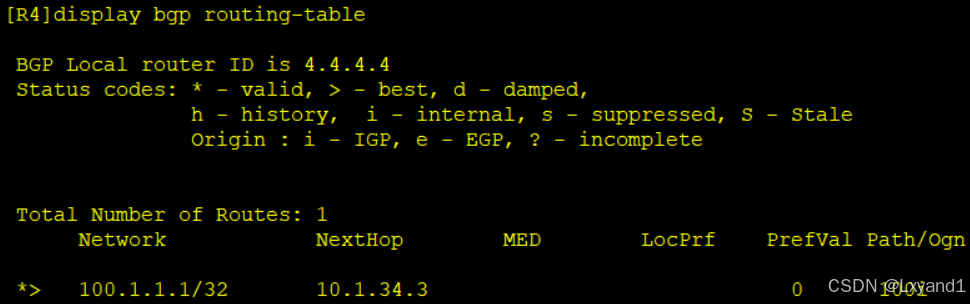
以上表示AR3也把这条AR1传给他的IBGP路由条目传给了AR4。
现在去ping通测试:
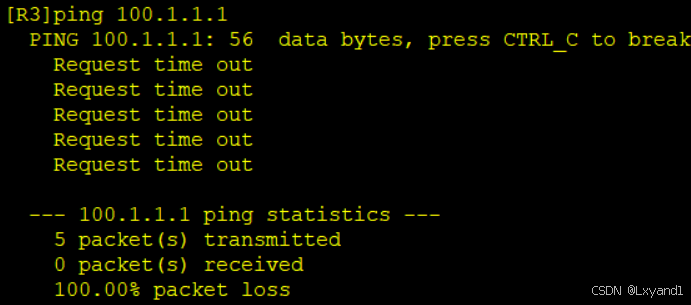
我们发现并不能通,原因也很简单,是因为在AR2上并没有100.1.1.1/32这条路由。
在AR2上查看路由表:

- 这就是路由黑洞产生了。我们通过 BGP 学习到了路由,但是中间的路由器却并一定有这条路由。在最初的时候我们用同步的方式来防止这种事情的发生,但是在华为的路由器中默认关闭同步并且无法打开,同步指的是 BGP学习到的路由在IGP也存在,意为同步。关于同步。
- 所以只要上面这种组网方式,无论如何都会产生路由黑洞,所以在这种情况下解决黑洞的方法是在 AR2 上配置 BGP 协议,让 AR2 通过 BGP 学习到此路由。但是由于IBGP 邻居的水平分割问题。(IBGP 水平分割指的是从一个IBGP邻居学到的路由不会传给别一个IBGP邻居,在本实中上是指 AR2 从 AR1 学到的 BGP路由不会传给 AR3)就要求我们运行一个全互联的 BGP邻居关系。但是这样又会带来一个 BGP的连接过多的问题,所以后面我们会学到用路由反射器和联邦的方法解决。而更好的解决方法是 MPLS。
这里,我们先运行全全互联的 BGP 邻居关系:
e.在 R2 上起一个环回口,用环回口的方式来建立邻居关系
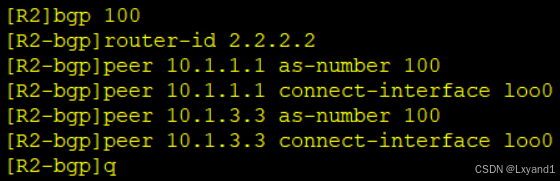
再分别去AR1和AR3上添加与AR2的邻居:
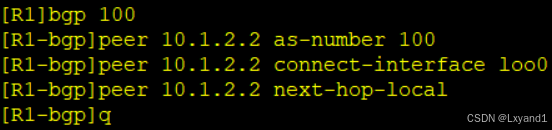
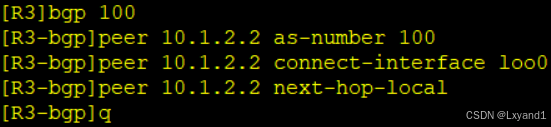
再去测试
f.在AR2上查看BGP表
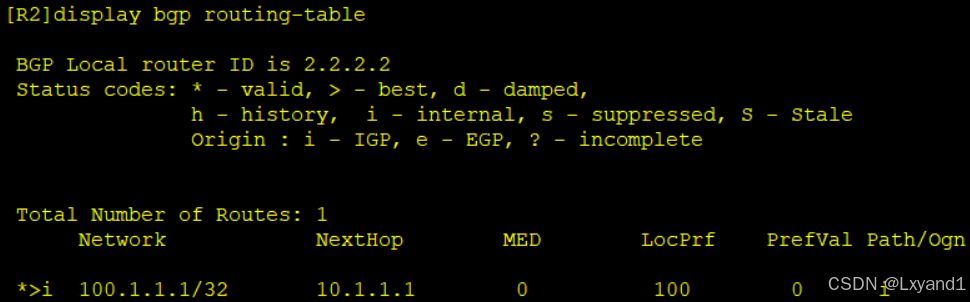
再去AR3上ping通测试:
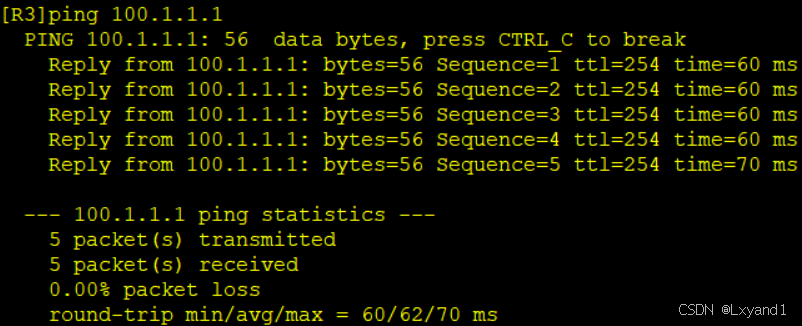
如果AR4也想要ping通的话,需要AR1上有回到AR4的路由,需要在AR4上通告这条路由出去
如下:
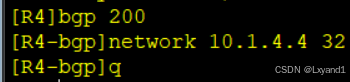
g.R4 ping R1 环回口100
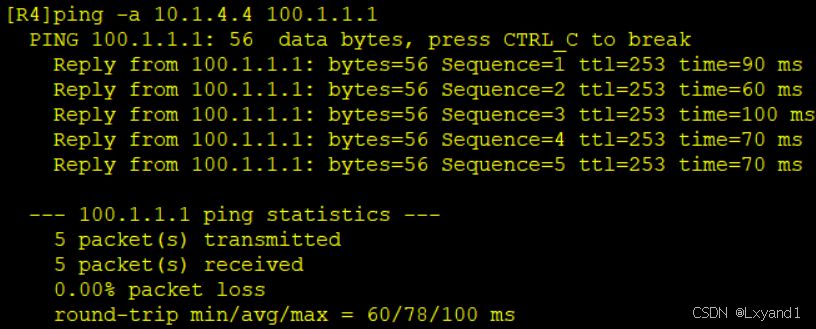
(4)实验 1.4 用 group 的方法建立邻居关系
【1】实验目的
让AR1,AR2,AR3分别建立IBGP的邻居关系
用group的方法简化配置,降低BGP的资源占用。
对等体组(Peer Group)是一些具有某些相同策略的对等体的集合。当一个对等体加入对等体组中时,该对等体将获得与所在对等体组相同的配置。当对等体组的配置改变时,组内成员的配置也相应改变。
在大型BGP网络中,对等体的数量会很多,其中很多对等体具有相同的策略,在配置时会重复使用一些命令,利用对等体组可以简化配置。
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
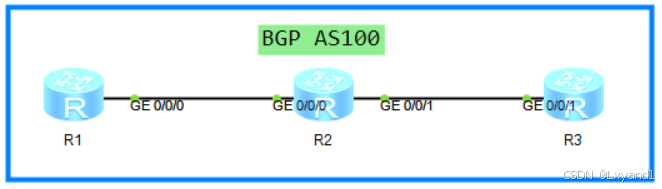
【4】实验步骤
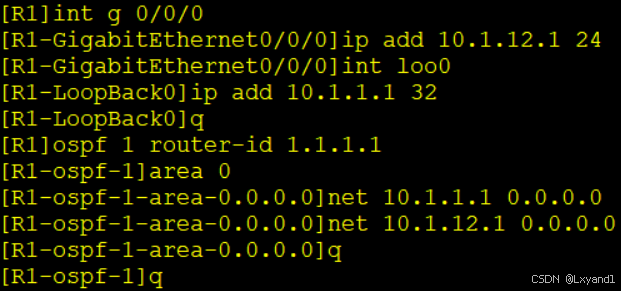
a.先配置底层IGP协议,让环回口可达
在AR1上:
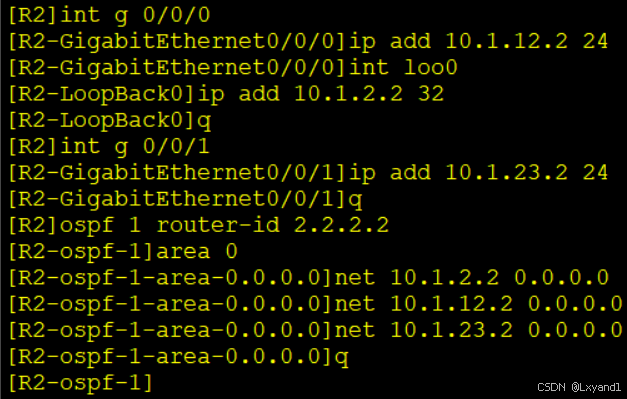
在AR2上:
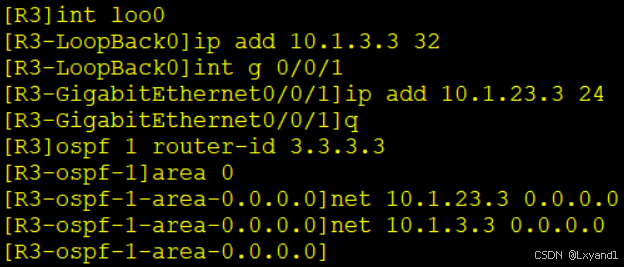
在AR3上:
b.开始配置BGP
在AR1上:
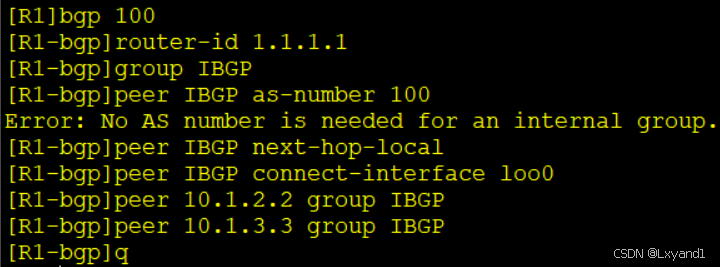
在AR2上:
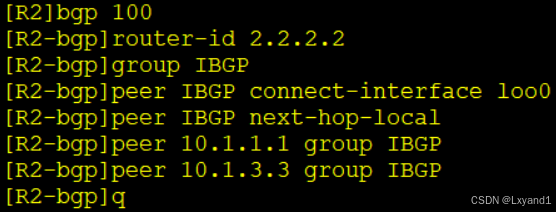
在AR3上:

- 注意:当我们用了peer-group的方式去建立邻居关系后,我们就不能针对其中的某个邻居去做一个出方向的策略,只能针对这个组去做相同的策略。
(5)实验 1.5 BGP 的自动汇总
【1】实验目的
理解BGP的自动汇总
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
a.先配置AR1与AR2之间的IGP协议,确保AR1与AR2的环回口可达。
这里不再演示。
b.配置AR1与AR2的IBGP邻居关系,AR2与AR3的EBGP邻居关系。
在AR1上:
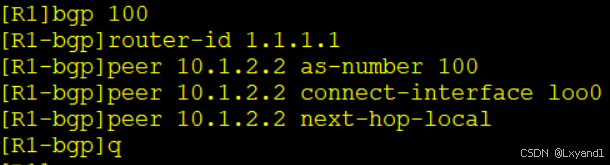
在AR2上:
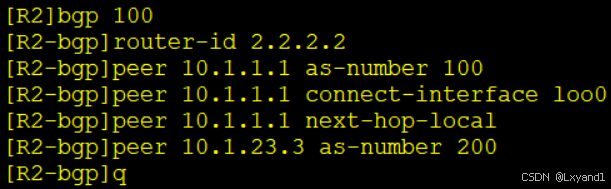
在AR3上:
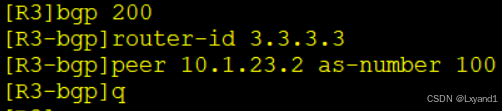
c.打开BGP的自动汇总,再用宣告的方式在AR3上产生3条BGP路由。
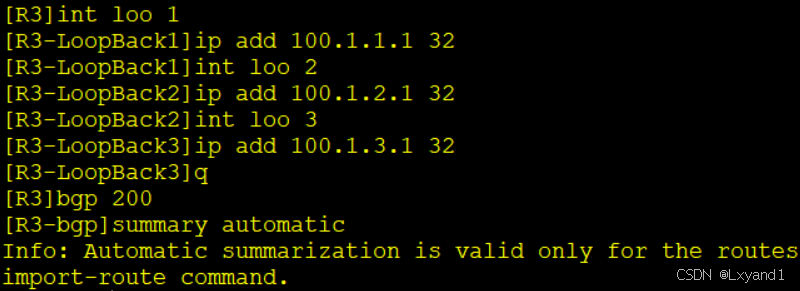
- 注意这个弹出信息,自动汇总只对通过import-route 引入的路由生效,接下来我们通过network试试看看效果

d.去AR2上查看BGP表
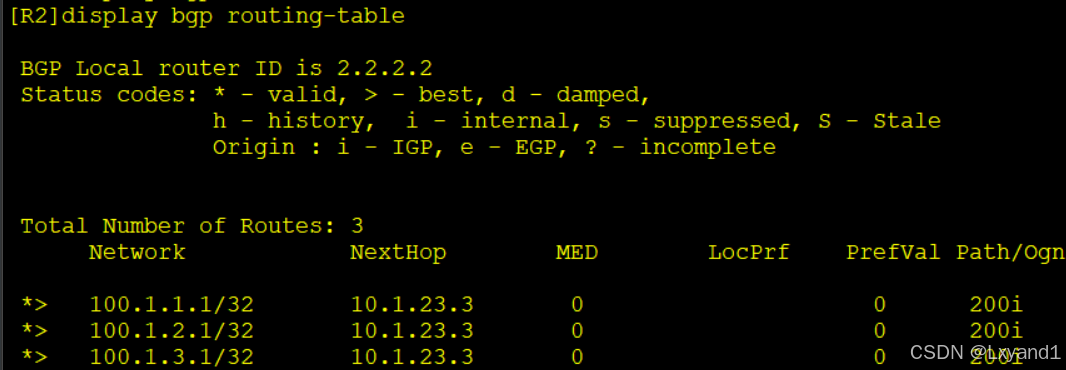
- 我们发现这三条路由并没有被汇总。也就是说BGP的汇总对我们通过network宣告进来的路由并不会汇总。而且华为设备即使打开自动汇总,也不能实现直接宣告主类。
e.去AR3上做主类的宣告
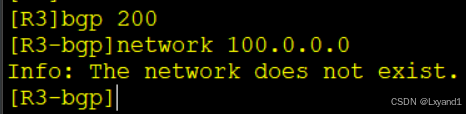
- 无法宣告主类,提示主类路由不存在,所以在华为VRP中BGP即使在自动汇总开启的情况下,都无法进行主类宣告。
f.在AR3上去做import-route方式
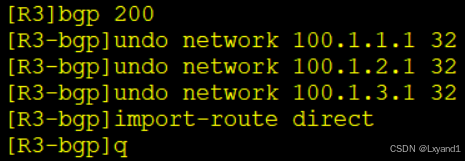
g.在AR3查看BGP表
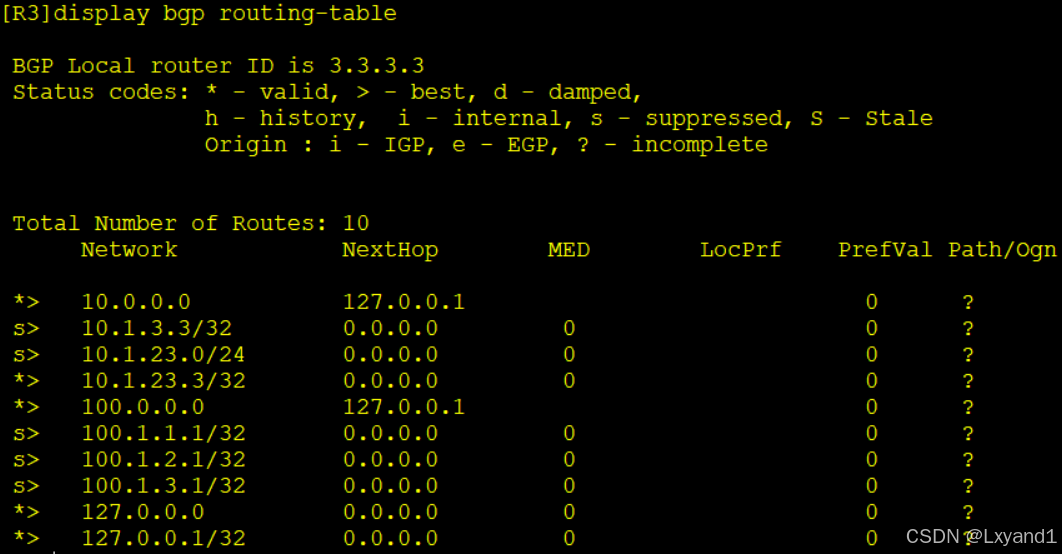
h.再去AR2上查看路由表
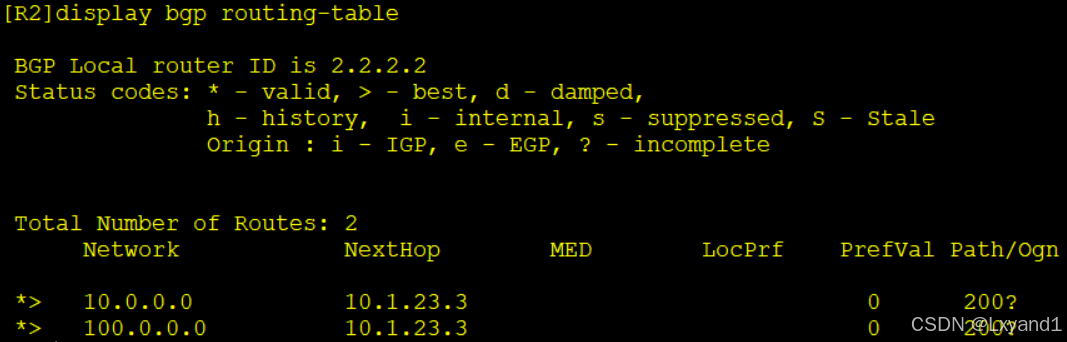
- 上面的现象告诉我们,当我们引入进BGP的路由条目是会被自动汇总的。
(6)实验 1.6 BGP 手动汇总(地址聚合)
【1】实验目的
- 掌握 BGP 的手动汇总及各种特性地址
- 聚合中参数“as-set”的含义
- 地址聚合中参数“detail-suppressed”的含义
- 地址聚合中参数“suppress-policy”的含义
- 地址聚合中参数“origin-policy”的含义
- 地址聚合中参数“attribute-policy”的含义
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
a.在实验1.5的基础上关闭所有BGP的自动汇总

b.此时在AR1、AR2、AR3都可以看到以下三条路由
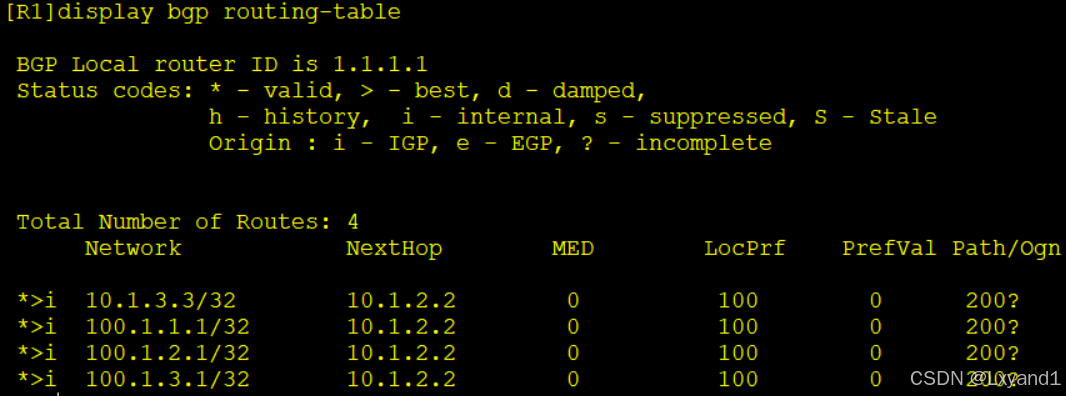
- 我们可以去任何一个路由器做BGP的地址汇总,不一定非要在起源路由器上做。
c.这里我们选择在AR2上来做汇总
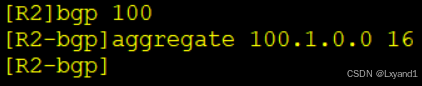
- 以上命令便是在AR2上用地址聚合的方法产生一条新的路由
去AR2查看BGP表:
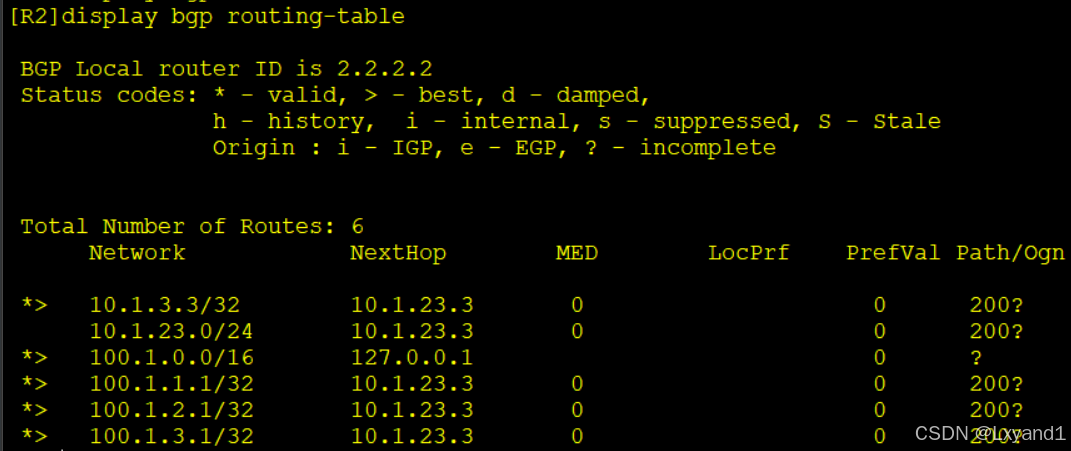
d.我们去AR1上查看BGP表
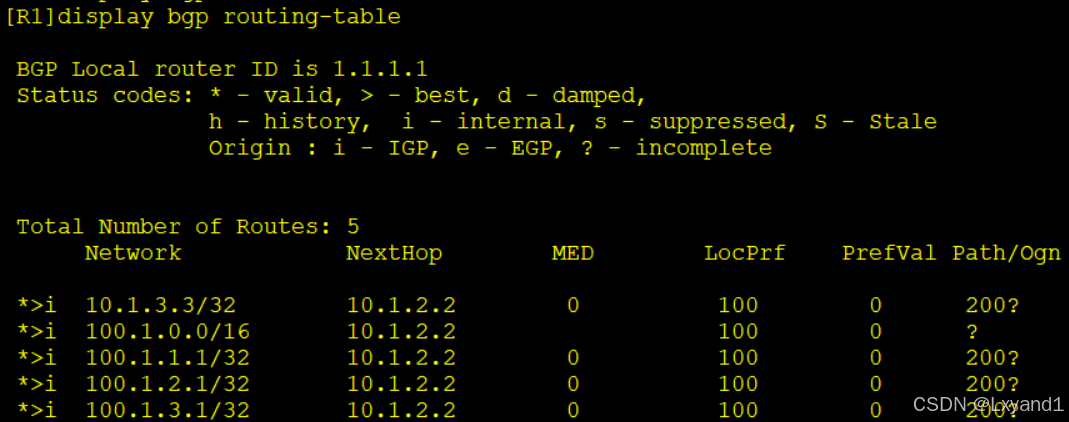
- 我们发现,AR1 不仅收到了 AR2 新产生的那条汇总路由,同时也依然学到了以前的明细路由如果我们想让在汇总后能抑制明细,就必须加上关键字:detail-suppressed,此关键字的意思是抑制所有包含在内的明细路由。
e.在AR2上配置detail-suppressed

再去AR1上看BGP表:
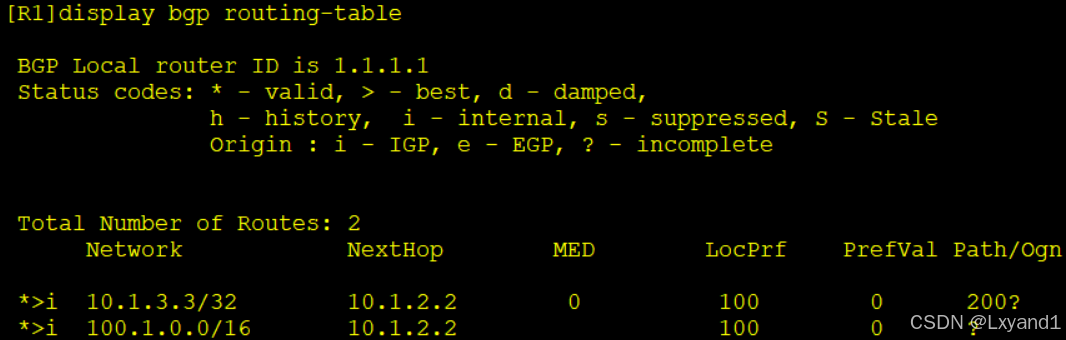
- 发现只能看到一条明细路由了。
- 接下来就有点麻烦了,请慢慢理解。有的时候,我们想让某条明细路由传出去,某些路由被抑制,这也是可以实现的。这就要用到另一个关键字:suppress-policy,此关键字的意思是选择性的抑制某些路由,比如在此实验中,我们想让 100.1.3.1/32这条路由依然被 AR1 学到,另外两条被抑制。
f.首先用 route-policy 匹配上我们想抑制的路由
在AR2上:
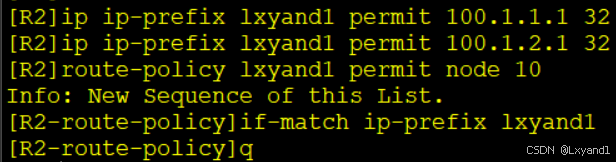
然后到BGP里用关键字suppress-policy调用这条route-policy

g.在AR1上查看BGP路由表:
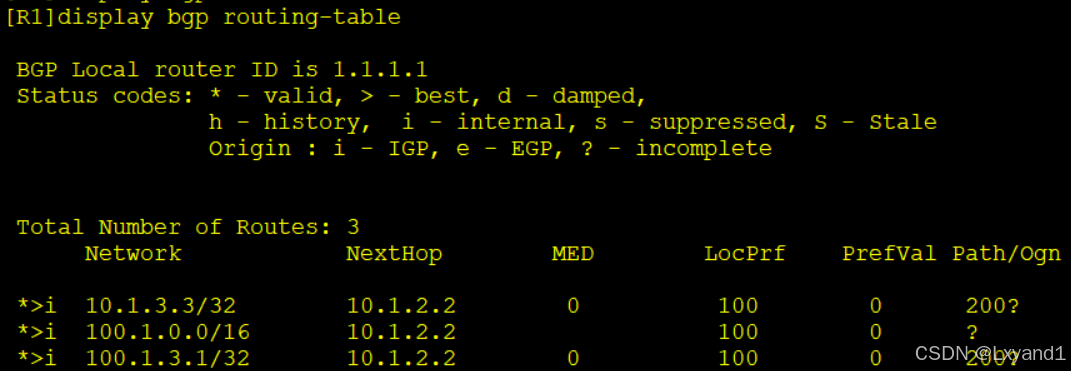
- 可以看到实现了需求,100.1.3.1没有被抑制,其他的则被抑制了。
h.在AR3上查看一下BGP路由表
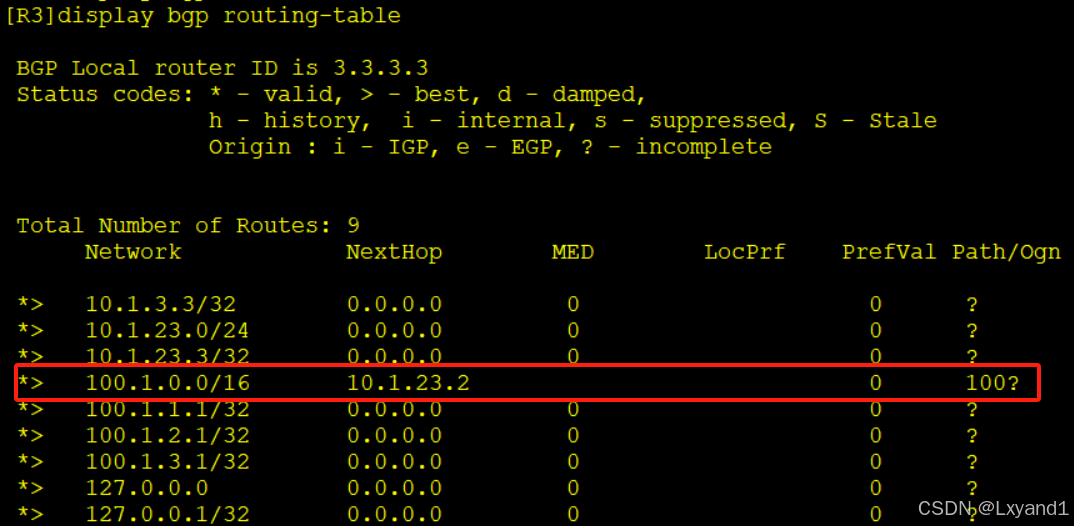
- 以上表示:我们看到一个不好的现象,AR2上汇总的路由竟然又传回了这几条明细的起源地 AR3。这是因为汇总后的路由会丢失明细的一些属性。如果我们想让汇总后的路由依然保留明细的属性就必须加上关键字:as-set。
i.在AR2上配置as-set

加上以后再去AR3上看现象:
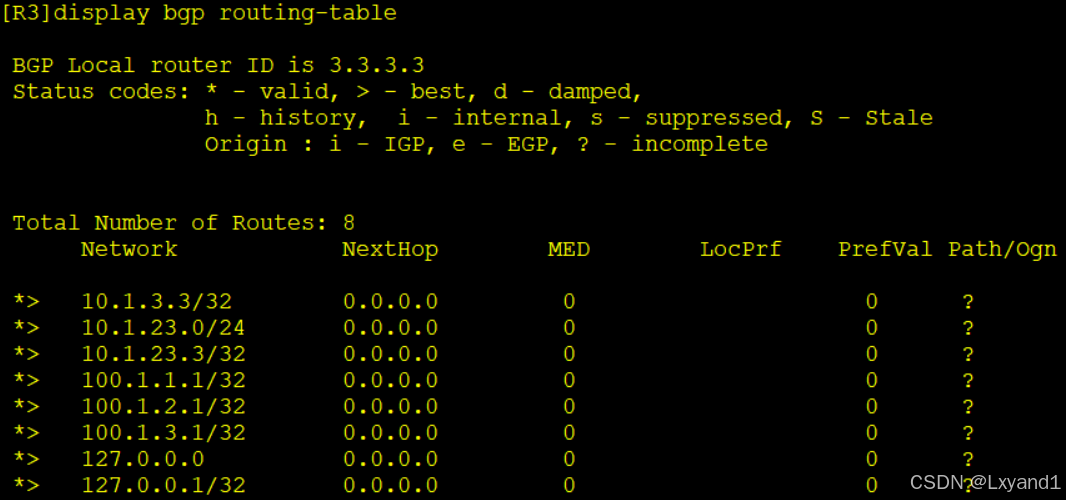
- 以上便是我们发现AR3没有收到这条汇总路由了,再去AR1上查看还在不在。
在AR1上:
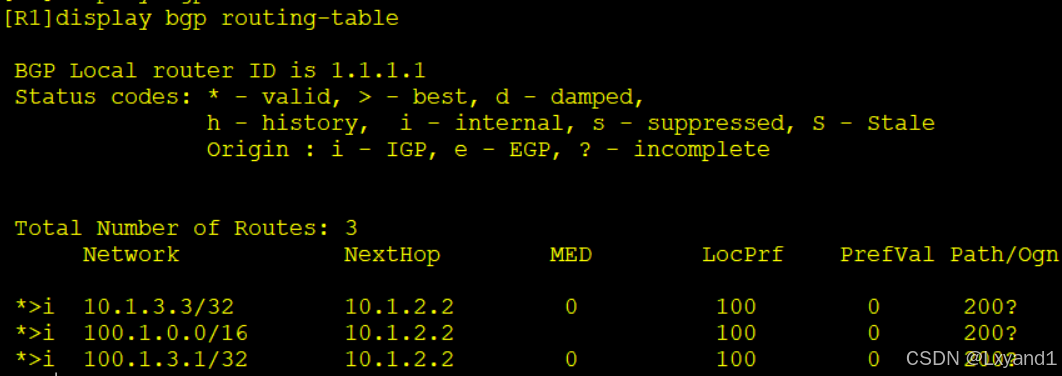
- 以上表示这条汇总依然收到,并且可以发现后面带上了200 的 AS-Path,这在开始是没有的是因为我们在 AR2 上加上 as-set这个关键字后把明细的属性值带了下来。这也是 AR3 不再收这条路由的原因--从 EBGP 邻居收到一条路由带有本 AS-Path,将不再收(EBGP 防环原则)。
- 接下来的部分更难理解,需要更多耐心。origin-policy--起源策略,指的是当route-policy 里匹配的路由(注意,此路由必须是被包含在汇总路由里的明细路由)在 BGP 表存在时,汇总路由才能生成: 如果使用 as-set参数,汇总路由只继承 route-policy 里面匹配路由的属性
- 按照上面的理论介绍,来设计本实验为:用origin-policy去匹配100.1.1.1/32这条路由,当这条路由存在的时候,就会产生汇总的路由。然后去 AR3上去掉此条路由,那么汇总就会消失。
j.先 undo 掉刚才的配置,完成origin-policy实验
在AR2上:

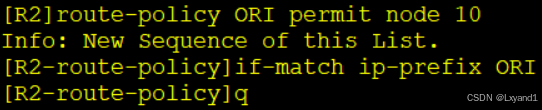
k.再写前缀列表去匹配100.1.1.1这条路由
![]()
用route-policy去调用:
再到汇总命令里面去调用这条route-policy:

l.去查看AR2的BGP表项
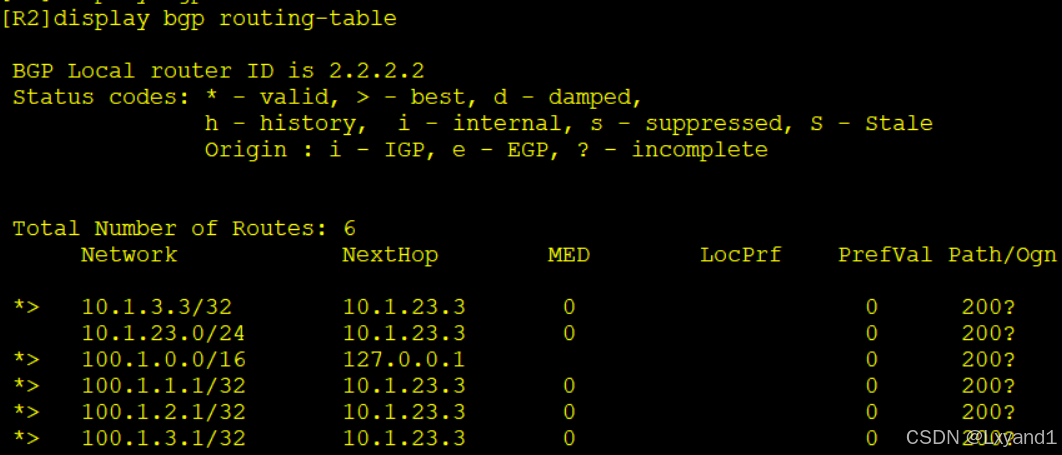
- 以上表示汇总已经成功,产生了汇总的路由。
m.去AR3上取消通告100.1.1.1/32这条路由

n.再去AR2上查看BGP路由表
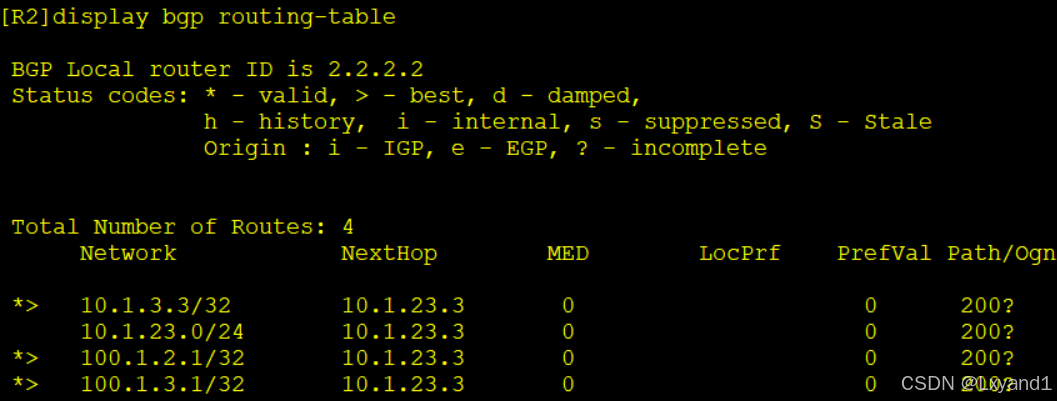
- 以上表示实验结果和预想的一样,明细和汇总都一起消失了。
(7)实验1.7 产生默认路由
【1】实验目的
理解掌握几种在BGP里产生默认路由的方法。
【2】IP地址规划
- 互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
- 每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
这个实验在实验1.1的基础之上
a.先查看BGP邻居关系
然后我们在AR1上去产生一条默认路由
b.用import-route路由的方法产生一条默认路由
在AR1上:

- 注意这里一个非常重要的点,必须配置default-route imported下发这条默认路由,不然路由表就会啥也没有。
c.查看AR2的BGP表项
这时候可以发现AR2已经学到了AR1下发的默认路由。
d.我们可以用network的方法产生一条默认路由
首先undo掉刚才的配置:
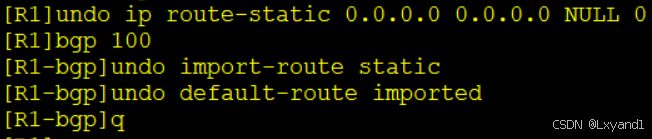
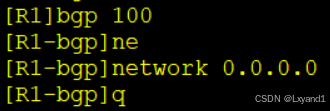
接下来依然是写一条默认静态路由,这里我们用一个下一跳的方式:

然后在BGP宣告这条路由:
f.查看AR2的BGP表项
这时候可以发现AR2已经学到了AR1下发的默认路由。
g.还有一种最简单的方式,一条命令

h.查看AR2的BGP表项
这时候可以发现AR2已经学到了AR1下发的默认路由。
2.BGP选路原则
(1)实验 2.1 优选 Prefval 值更高的路由
【1】实验目的
深入理解13条选路原则的第一条,基于Prefval值选路;掌握修改Prefval值的两个方法。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
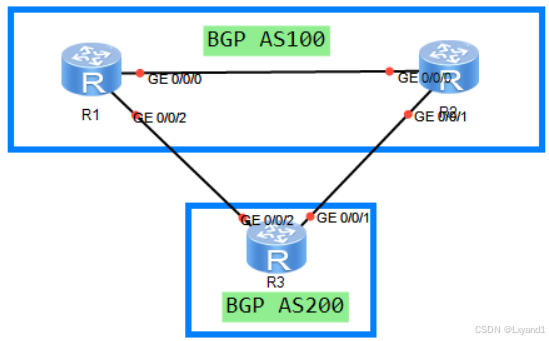
【4】实验步骤
a.先配置基本的IP地址,此处略。
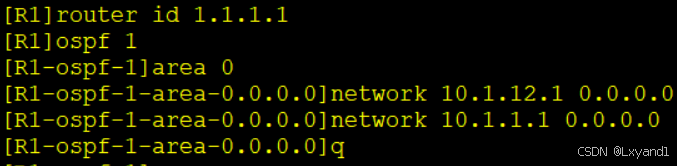
b.配置AS100内部的IGP,确保AR1,AR2的环回口可达。
在AR1上:
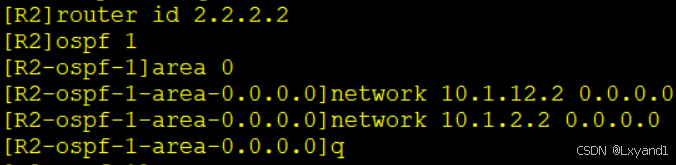
在AR2上:
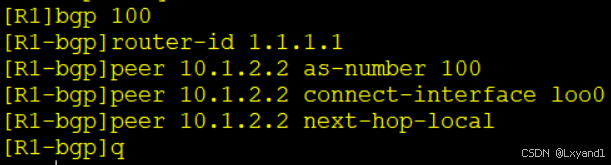
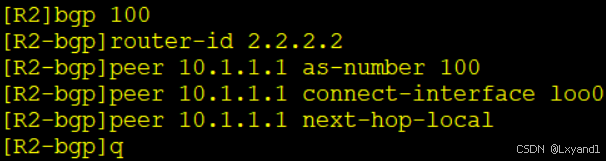
c.配置AS100内部的IBGP连接关系,用lookback0作为建立IBGP连接的IP地址,配置下一跳为本地。
在AR1上:
在AR2上:
d.配置各个AS间的EBGP连接关系,用直连接口IP地址建立EBGP连接。
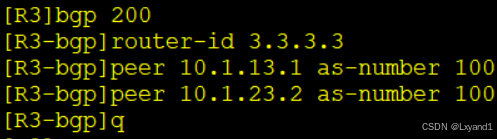
在AR1上:

在AR2上:

在AR3上:
e.在AR1上查看邻居状态
f.在AR3上用network的方法产生一条BGP路由
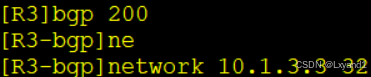
g.在AR3上去查看一下这条路由
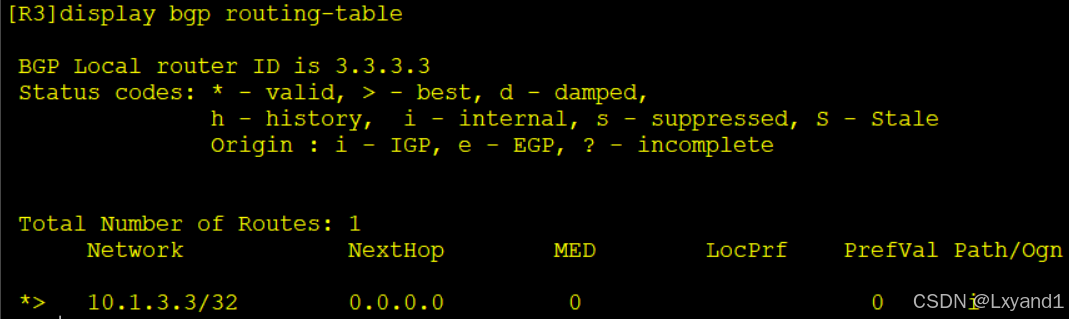
- 我们发现这条路由的Prefval值为0,因为起源于本地。
h.再去AR1上查看一下
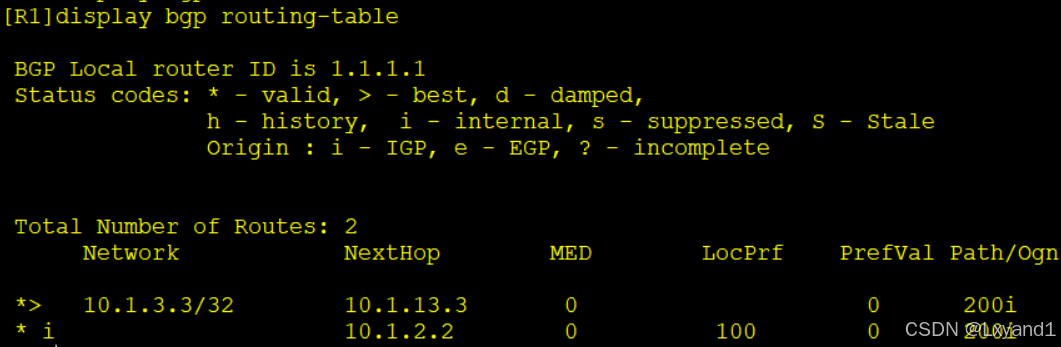
- 以上表示 AR1 这条路由从 AR3 学到了,然后也从 AR2 学到了。他们的 PrefVal 值都为0。现在因为选路原则(EBGP 优于IBGP)选择了从AR3来的路由。现在去修改成从AR2学到于的路由 PreVal值为 100,以重新选择为从 AR2 来的更优。
i.针对从某个邻居学习到的所有路由修改 PrefVal值。
在AR1上:

刷新一下BGP路由表:

再去查看AR1的BGP表:
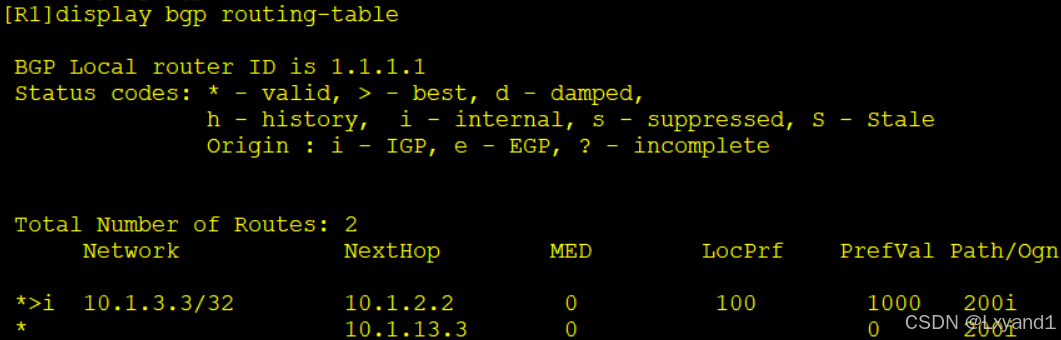
- 以上表示此路由重新选择了AR2,因为从AR2学习到的路由器前缀的 PrefVal值为1000。但此方法有不精确的地方,就是从 AR2 学过来的所有路由的 PrefVal值都会变成1000,所以我们一般会用第二种方法:
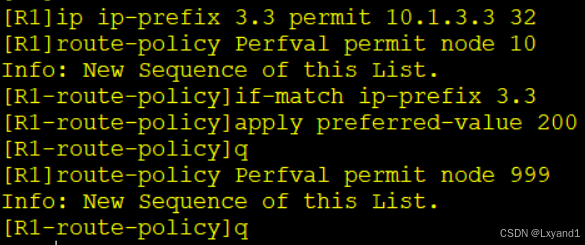
j.先在 AR1 上用 route-policy 去匹配这条路由然后优改此路由的 PrefVal值。
在AR1上:
再去调用这个route-policy

然后在AR1查看BGP路由表:
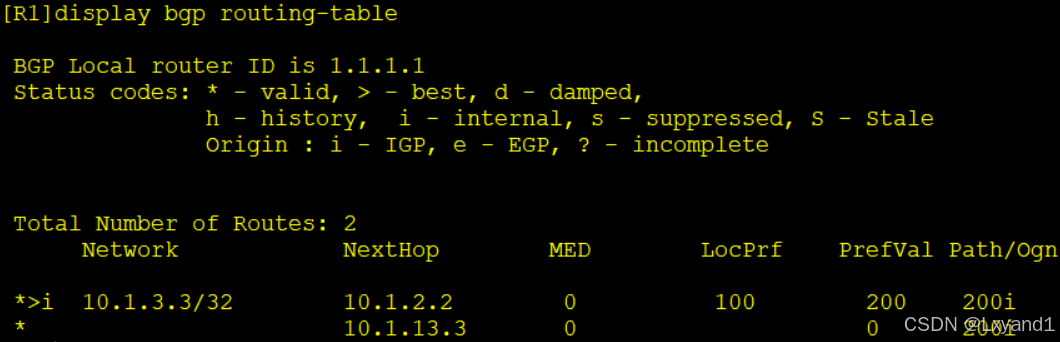
以上表明成功修改成了 200,并且我们发现,当我们二种方法都使用了的话,用route-policy 的这种方法的优先级会更高一些。
k.再去 AR3 上产生一条路由来观察这种现象。
然后在AR1上查看BGP路由表:
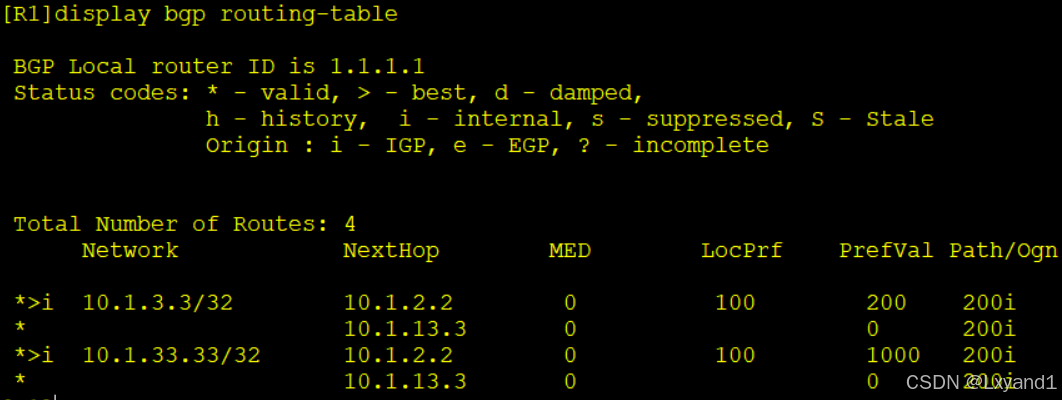
以上表示我们用route-policy精确匹配的一条被优先改成了200,其他的改成了1000。
(2)实验 2.2 优选 local preference 值更高的路由
【1】实验目的
深入理解13条选路原则的第二条,基于Local Preference值选路,掌握修改Local Preference值的两个方法。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
a.在AR1上查看BGP邻居
b.在AR3上用network的方法产生一条路由10.1.3.3/32,此步骤也不再演示
c.做完以上步骤后去AR1上查看BGP表项
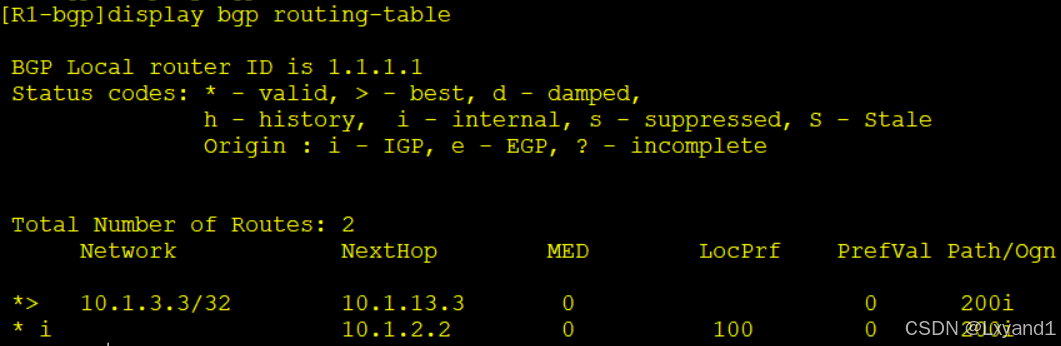
- 以上表示从 IBGP 邻居 AR2 学到的路由默认的 Local preference 值为 100,从EBGP邻居 AR3 学到的值为空(EBGP 邻居过来的条目不带 local preference 值),但是本地路由器会赋予没有携带 local preference 的 BGP 条目默认值。所以此时通过 AR3 学来的路由前缀实质在本地的 local preference 值也为100。所以此时没有通过比较 localpreference 值选出最优路径。
- 现在 AR1 的选择是从 AR3 学过来的路由前缀,我们去修改从 AR2 学过来的 localpreference 值为 200,然后去观察选路的变化。
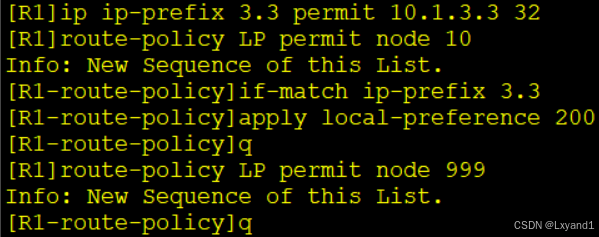
d:用 route-policy 的方法针对某个邻居的某条路由做修改
先用 route-policy把要修改的路由匹配上修改成期望值:
在AR1上:
e.再去基于R2邻居调用即可
在AR1上:

f.刷新一下R1的BGP表项,然后再看BGP路由
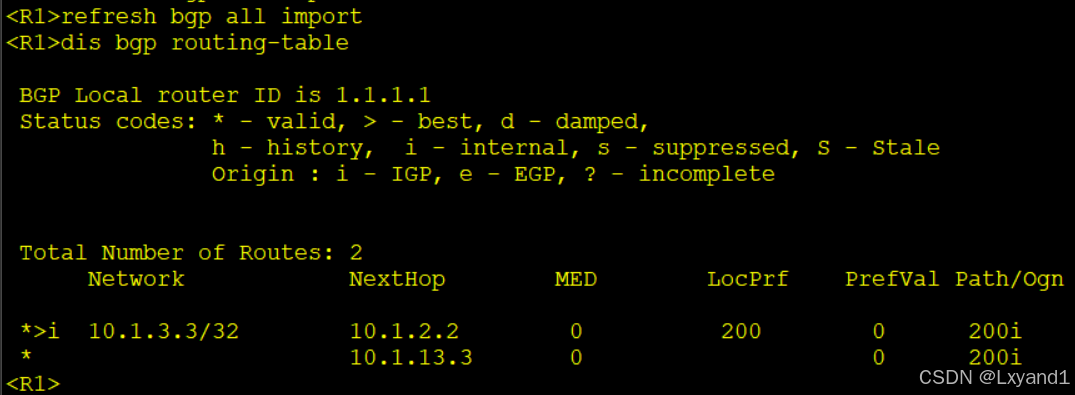
- 以上表示已经生效了。由于从 AR2学过来的这条路由local preference 值已经变成了200,被选为了最优。
- 我们再去用另一种把从 AR3学过来的local preference 值改为 300,让 BGP 再把从 AR3选为最优:用下面的方法实现
g.修改缺省的local preference 值,此命令只对从 EBGP 邻居学过来的路由和本地产生的路由生效。对于从IBGP 学过来的路由不生效。
在AR1上:

做完之后再去查看AR1的BGP表项:
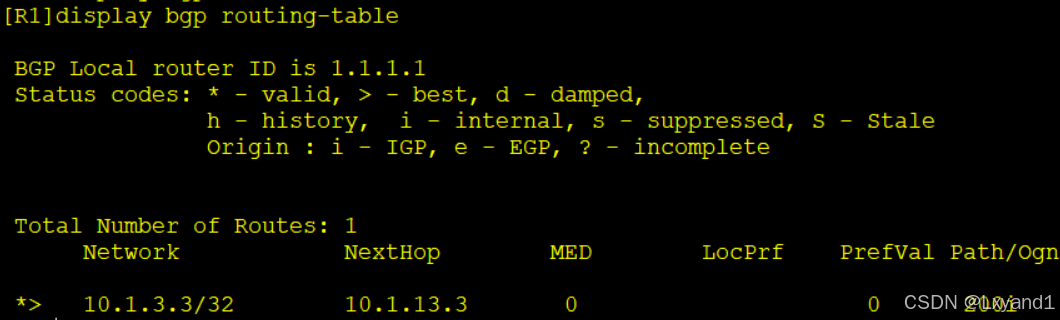
- 通过上面的表项看到了AR1只有通过AR3学习到了路由前缀,那为什么AR1没有了从AR2学过来的那条路由了呢?
h.我们去AR2上查看BGP表:
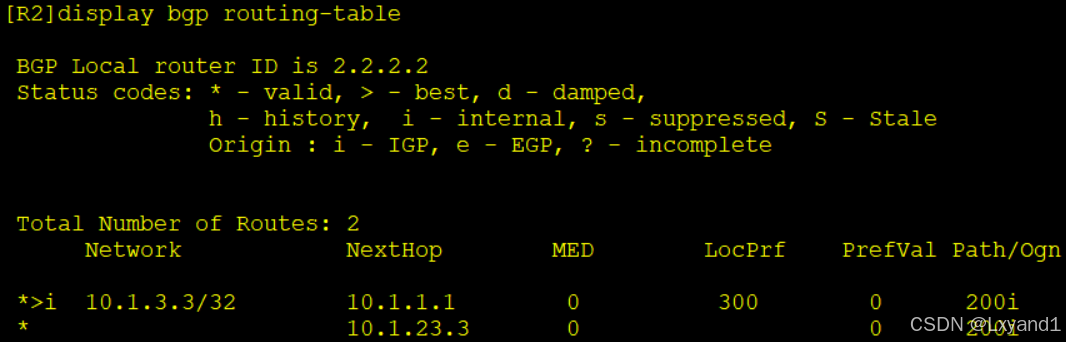
- 以上表示 AR2 选择了从 AR1 过来的最优,所以没有再把这条路由回传给 AR1了,而且我们发现从 AR1 传递过来的前缀local preference 变成了 300,也正因为如此 AR1 上才只有从 AR3 学习到的前缓。这也说明了 local preference 值在同一个 AS 之间是可以相互传递的。
(3)实验 2.3 优选从本路由器始发的路由
【1】实验目的
深入理解13条选路原则的第三条,优选从本地注入的BGP条目。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
a.在AR1上产生一条100.1.1.1/32的路由
这条路由必然会被AR2所学到,然后我们再去AR2上产生同样的一条路由。
b.在AR2上产生同样一条路由
c.在AR2上查看BGP路由表
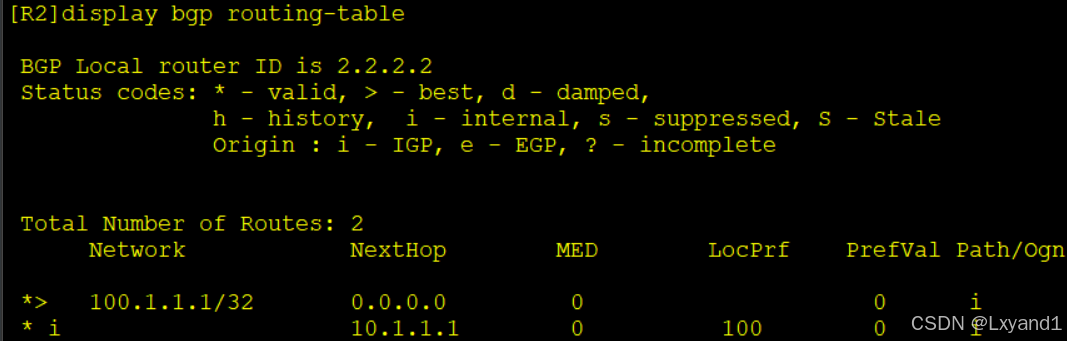
- 可以看到,从 AR2 本身宣告的条目 LocPrf为空,缺省是100。因此第一二条选路原则都不能选出最优 BGP 条目。下一跳为 0.0.0.0 的 BGP 条目为 AR2 自身宣告的条目,被选为最优。
(4)实验 2.4 优选有最短 AS_PATH 的 BGP 路由条目
【1】实验目的
深入理解13条选路原则的第四条,学会使用route-policy增加as-path影响
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
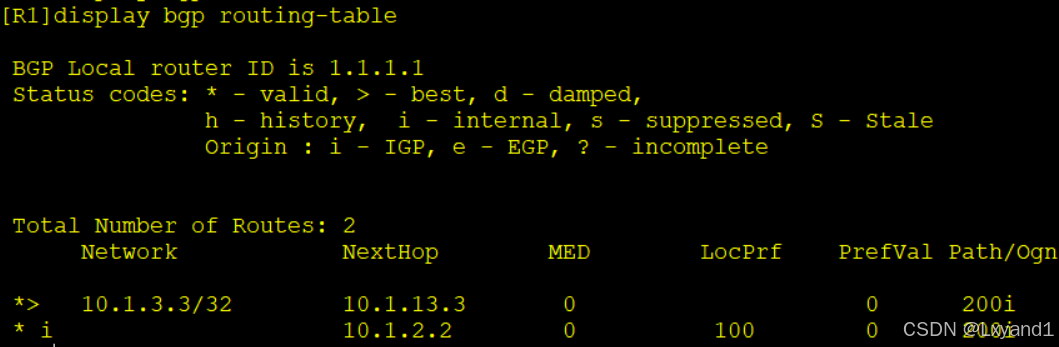
a.现在AR3上network宣告10.1.3.3的路由,然后在AR1上查看BGP表项
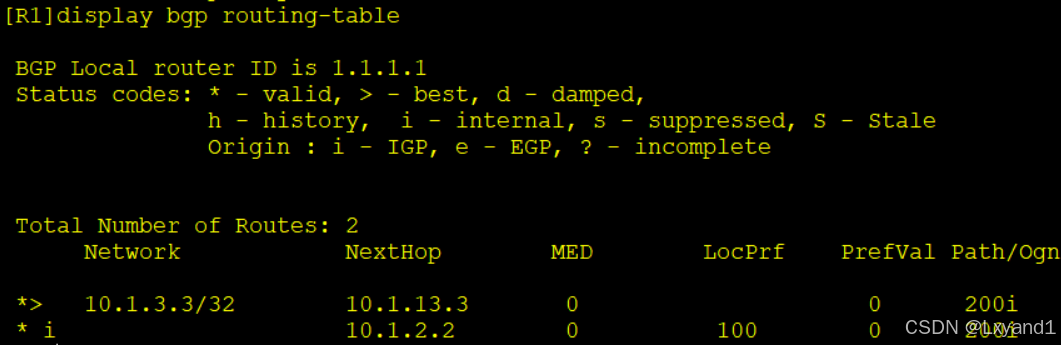
以上表示现在选择了从AR3过来的路由条目最优,我们现在去把从AR3学过来的路由前缀AS-path加长,这样就会选择从AR2过来的最优了。
b.在AR1上配置route-policy
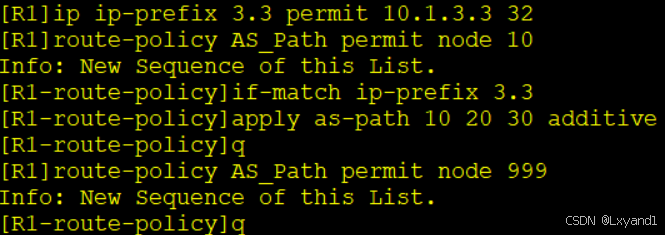
c.再去针对AR3邻居调用这个route-policy

d.在AR1上查看BGP路由表:
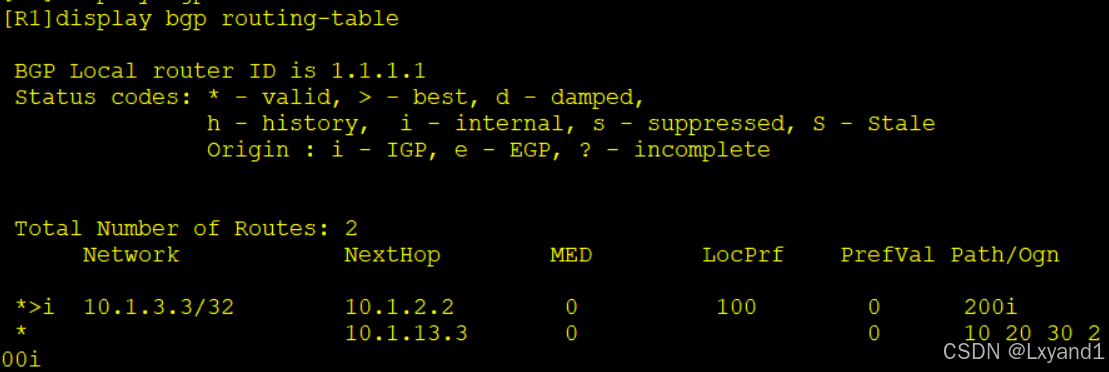 以上表示已经成功了,重新选择了从AR2过来的路由为最优。并且也看到了新加的3个AS Path。
以上表示已经成功了,重新选择了从AR2过来的路由为最优。并且也看到了新加的3个AS Path。
(5)实验 2.5 优选更低 Origin 属性的路由
【1】实验目的
深入理解13条选路原则的第五条,学会使用route-policy影响第五条选路原则。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
a.现在AR3上network宣告10.1.3.3的路由,然后在AR1上查看BGP表项
- 我们去把AR3学过来的路由的起源属性改为incomplete,这样就会重新选择AR2了。
在AR1上:
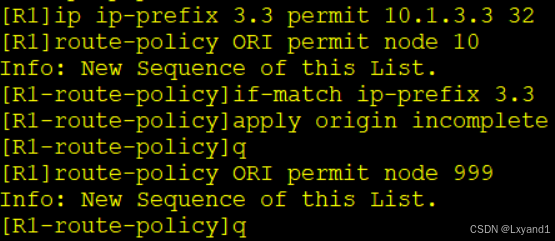
b.再对AR3调用这个route-policy

c.刷新一下路由表再去看现象
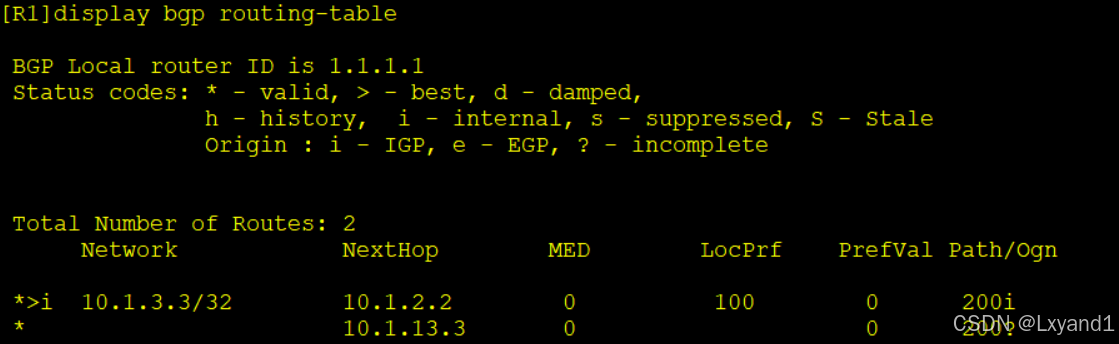
- 我们发现从AR3学过来的路由起源已经变为了 “?” ,并且也选择了AR2作为最优。
(6)实验 2.6 优选最小 MED 值的路由
【1】实验目的
深入理解13条选路原则的第六条,学会使用route-policy影响第6条选路原则。
理解什么情况下MED值的比较生效,理解compare-different-as-med。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
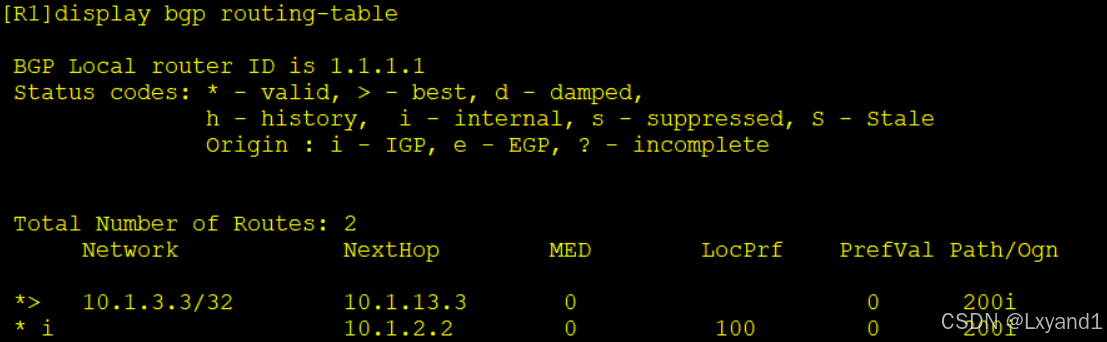
a.现在AR3上network宣告10.1.3.3的路由,然后在AR1上查看BGP表项
b.然后再从AR2查看BGP表项
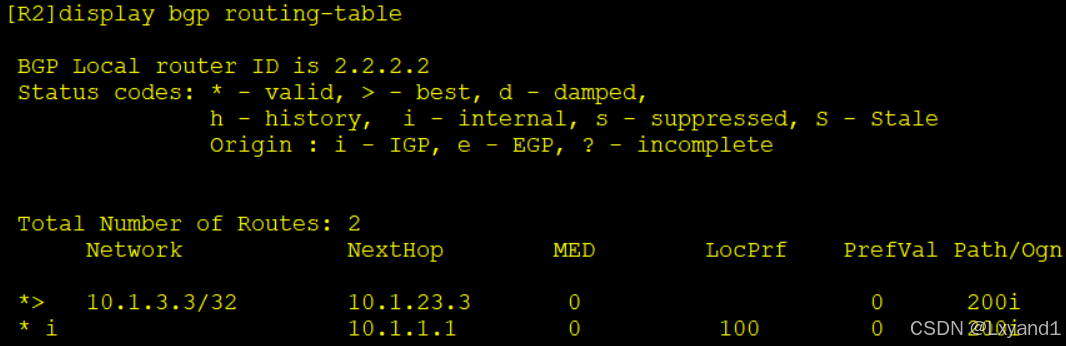
- 以上表示 AR1,AR2 分别都选择了各自的 EBGP 邻居 AR3 做为自己最优下一跳。现在我们去 AR3 上的出方向做修改,让 AS100(也就是 AR1 和 AR2)的所有流量都从 AR1进入AS200(也就是去访问 AR3)。
- 针对于 AR1,我们修改 10.1.3.3/32路由的 MED值 500。针对于 AR2,我们修改为 1000这样就会选择 AR1。
c.在AR3上配置route-policy
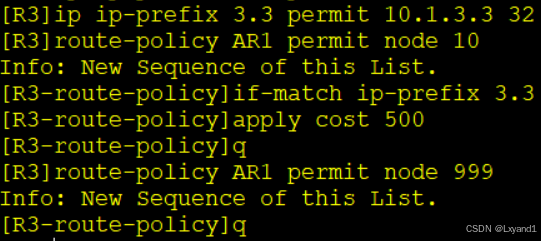
d.再写针对AR2的route-policy
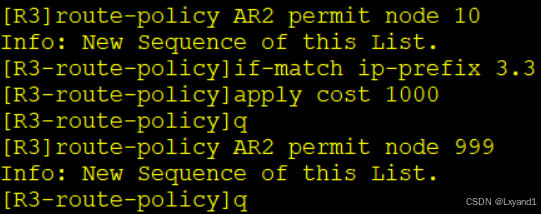
e.分别去调用他们

f.先在AR3刷新一下出向,然后去AR1,AR2查看BGP路由表
![]()
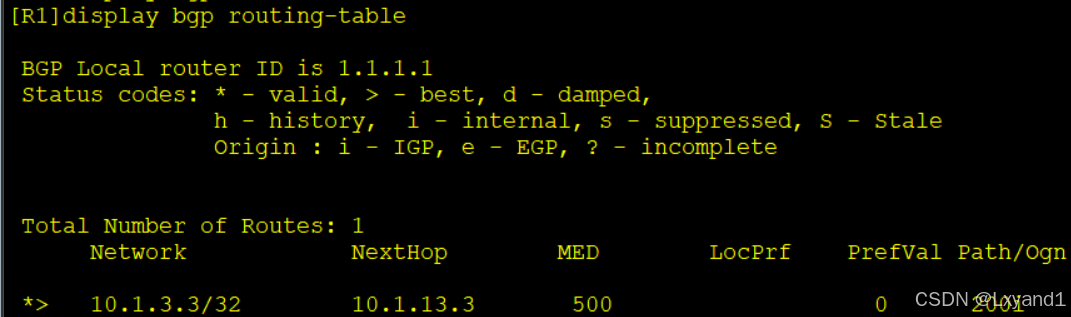
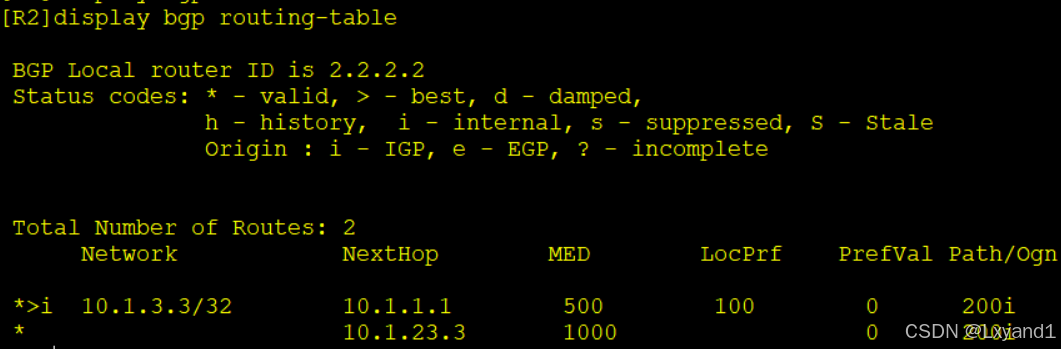
- 以上表示 AS100 里面的 AR1,AR2 的选路都是从 AR1 进到 AS200 了,达到了我们的要求。
- MED 值的比较条件:在 AS-PATH 中,默认第一个AS 号相同时才进行 MED 比较。
- 现在我们让 AR2 收到的这条路由的第一个 AS 号不一致,再来看现象
- 用我们刚才学到的知识,分别 AR1和 AR2 的入方向改变 AS-path (增加的长度要一样,AS 号码要不同)。
g.在AR1上
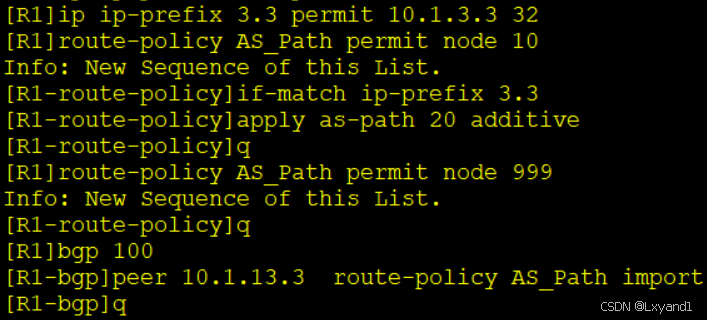
h.再去AR2上
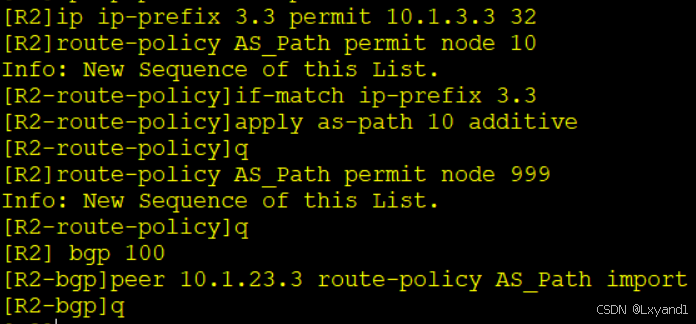
h.直接在AR2 查看BGP路由表
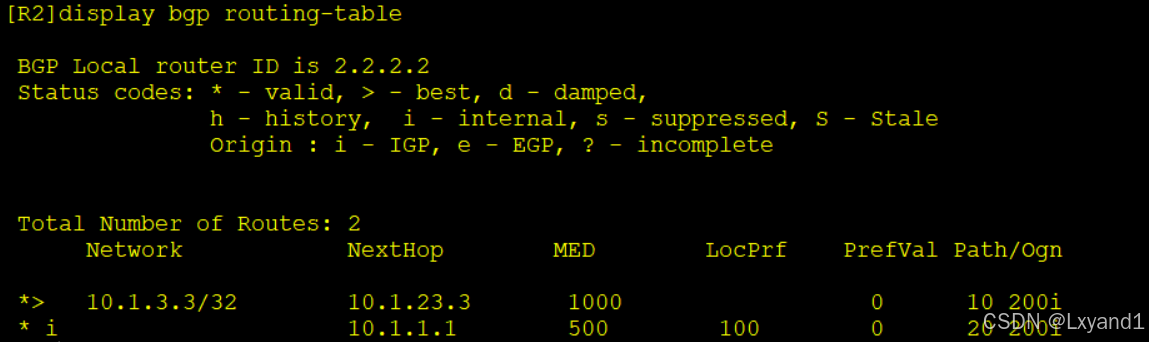
以上表示 AR2 从 AR3 学过来的 metric 值为 1000,但他依然选择了 AR3 为最优,这就是因为他们的第一个 AS path 不一致,默认情况是不比较 Metric 值的。
i.这时,如果第一个AS path 不一致时,我们也可以用以下命令要求 BGP 去做比较
在AR2上:
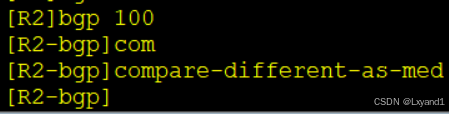
然后再AR2上看BGP路由表:
以上表示在第一个AS不一致的时候,也开始比较MED值了。达到实验要求。
(7)实验 2.7优选从 EBGP 邻居学习到的路由
【1】实验目的
深入理解13条选路原则的第七条。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
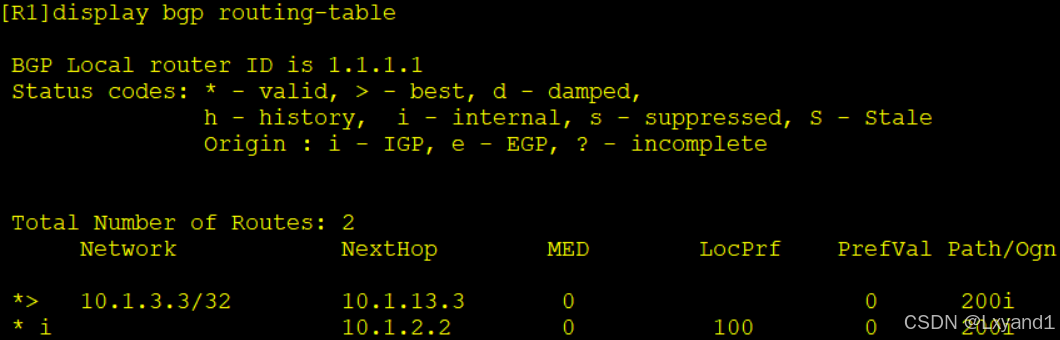
a.现在AR3上network宣告10.1.3.3的路由,然后在AR1上查看BGP表项
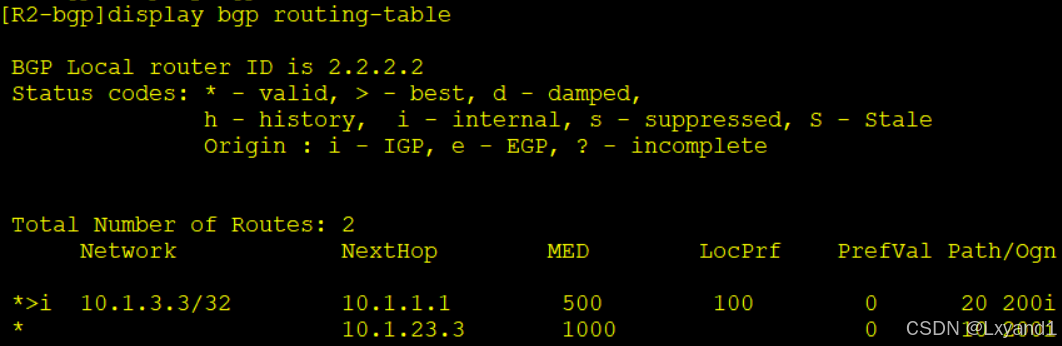
b.然后在AR2上查看路由表和详细路由

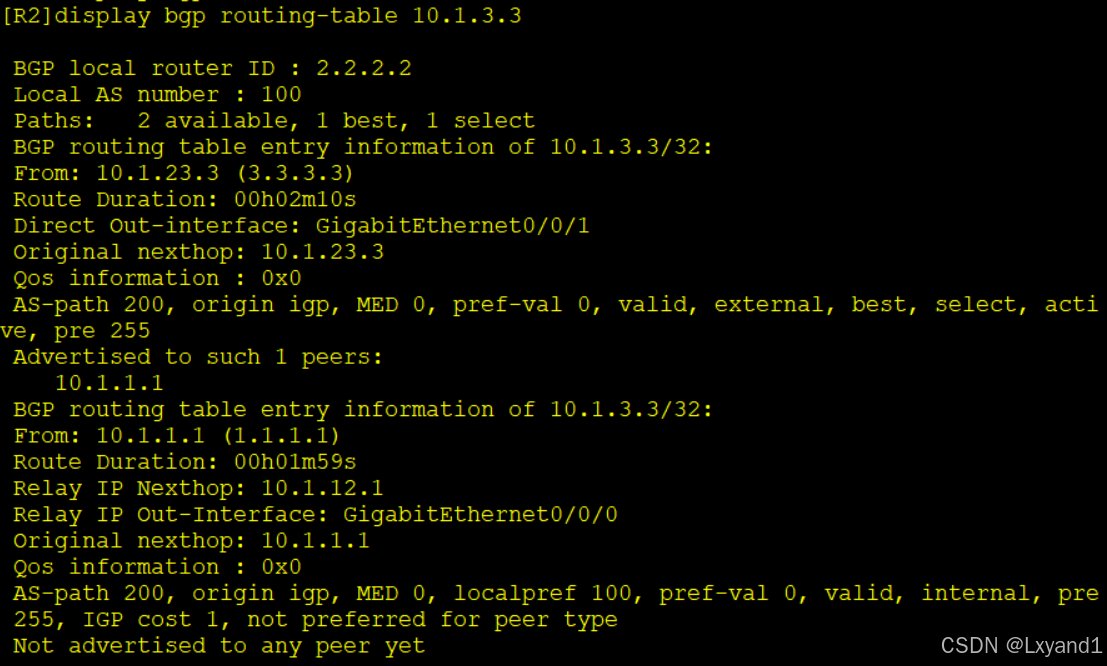
- 可以看到 AR1 和 AR2 都优选直接从 AR3 学习到的 BGP 条目,而且在 AR2 上输出详细内容发现从 AR1 学习到的路由信息不优选的原因是“not preferred forpeer type”,同理AR1 上也是一样。
- 备注:peer type类型两种,IBGP和EBGP,EBGP>IBGP。
(8)实验 2.8优选从更近的 BGP邻居学到的路由
【1】实验目的
- 深入理解13条选路原则的第八条,掌握通过调整去往BGP条目next-hop的路由的IGP度量值来影响BGP路由选路。
- 其实这个用到的情况非常少,因为需要EBGP邻居之间也运行IGP协议,正常情况下EBGP邻居是不会跑IGP的。
- 所以这个实验跳过,记住这个原理就行了。
(9)实验 2.9 BGP 的等价负载均衡
【1】实验目的
理解BGP的等价负载均衡,掌握打开和关闭IBP和EBGP的等价负载均衡。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
a.去AR2上产生一条路由
b.去AR3上查看BGP表与路由表
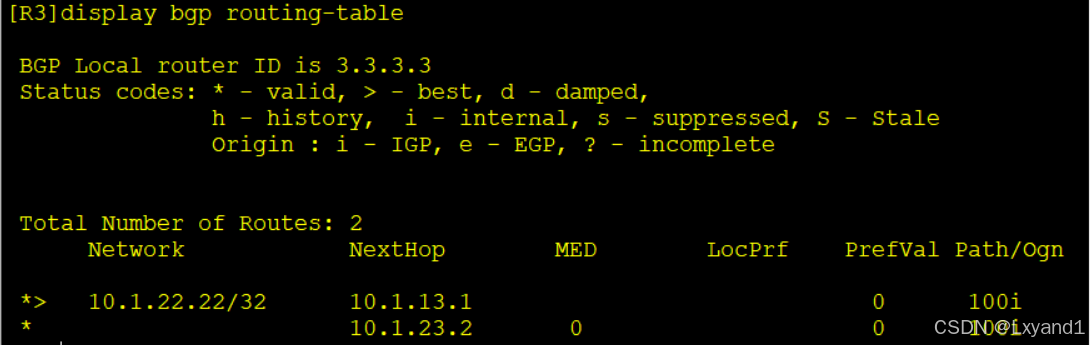
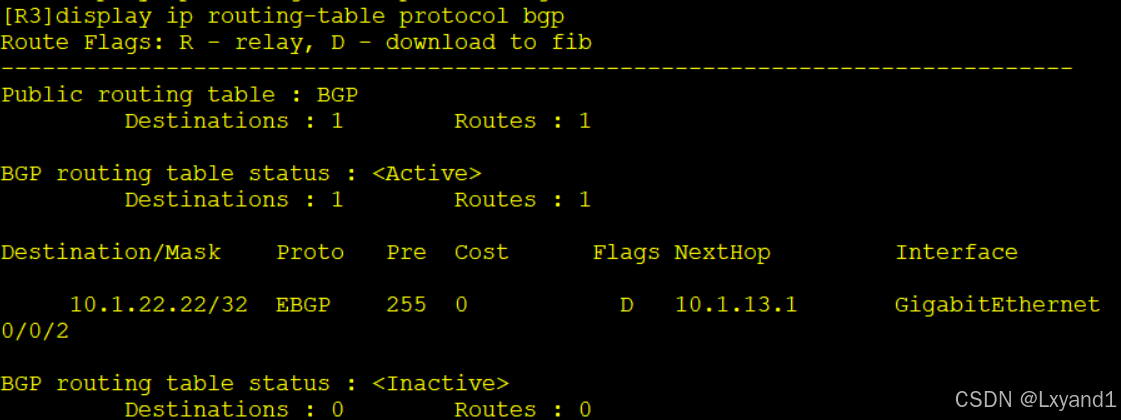
- 以上表示 AR3 选择了从 AR1 传过来的路由,原因是因为从 AR1 学习到了这一条的route-id 小。但那不是前8条选路原则选出来的,所以这里我们就可以实现负载均衡。
c.接下来直接去AR3上打开负载分担就行了
d.然后再查看AR3的路由表
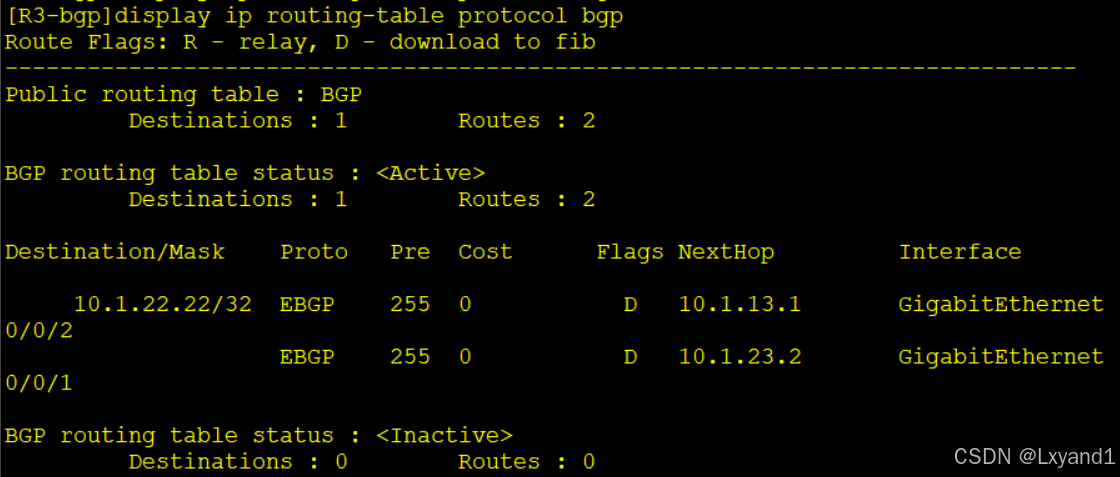
- 以上表示这条路由有了两个下一跳,实现了负载分担。
(10)实验 2.10 优选拥有最短的 cluster-list长度的路由
【1】实验目的
深入理解13条选路原则的第十条。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
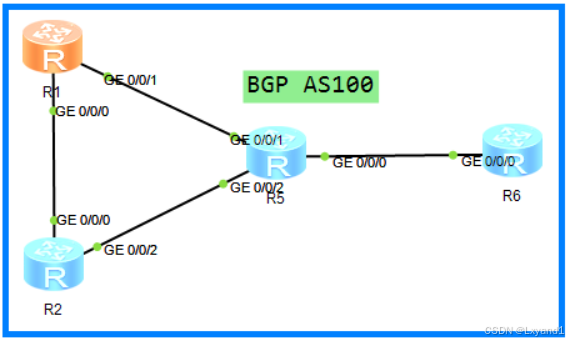
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2,AR5,AR6 的回环口可达
- 配置AR1,AR2,AR5全互联IBGP邻居,AR5与AR6配置IBGP邻居,以上配置自己配好。
a.配置AR1和AR2为RR,他们client都为AR5,然后配置AR5为RR,AR5的client为AR6。



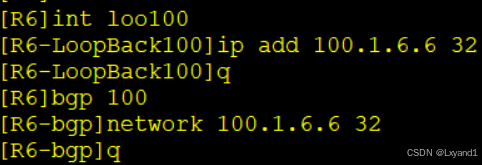
b.再去AR6上用network方式产生一条BGP路由
c.去AR1上查看BGP路由表
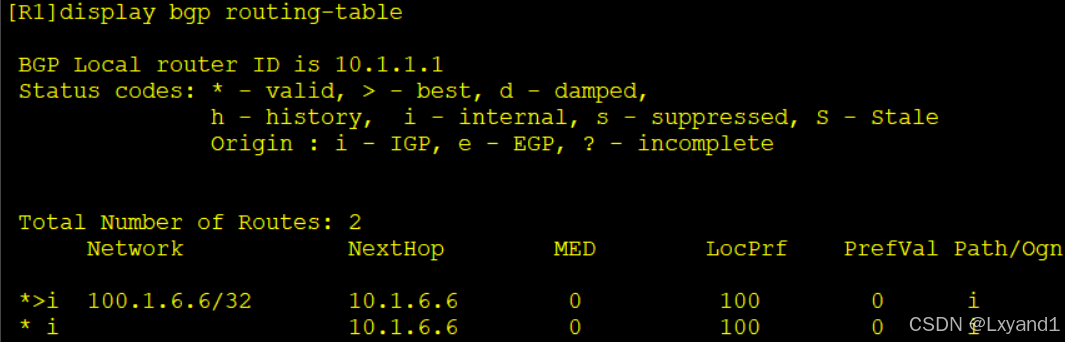
- 以上表项说明此路由的下一跳都是一样的,甚至我们都看不出来这两条分别是从哪里学来的。
d.再去看详细的
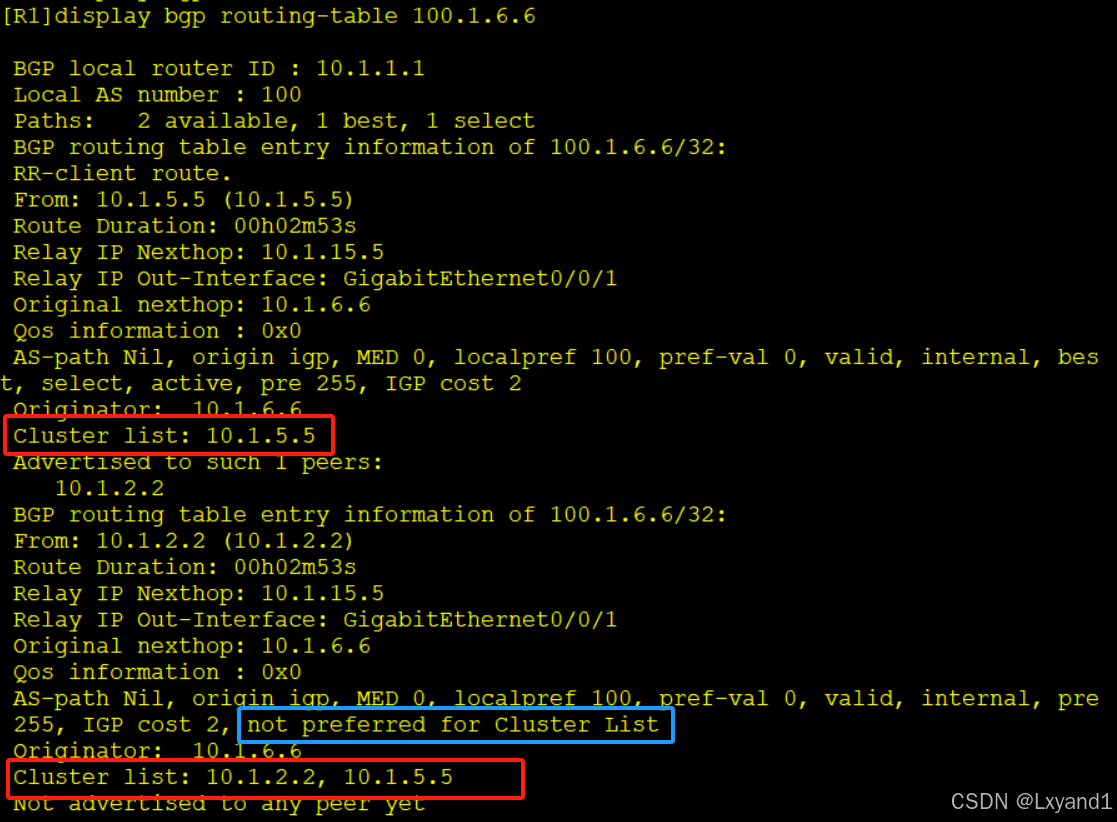
- 可以看到选了Cluster List最短的。
(11)实验 2.11优选具有更小的 Originator ID或者是 route-ID的 BGP 邻居
【1】实验目的
深入理解13条选路原则的第十一条。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 作为建立 IBGP 连接的IP 地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示。做好以后,在 AR1,AR2,AR3 上都会看到两个 BGP 邻居关系。
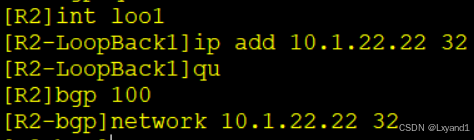
a.去AR2上产生一条路由
b.去AR3上查看BGP表与路由表
c.然后直接看10.1.22.22这条路由的详细
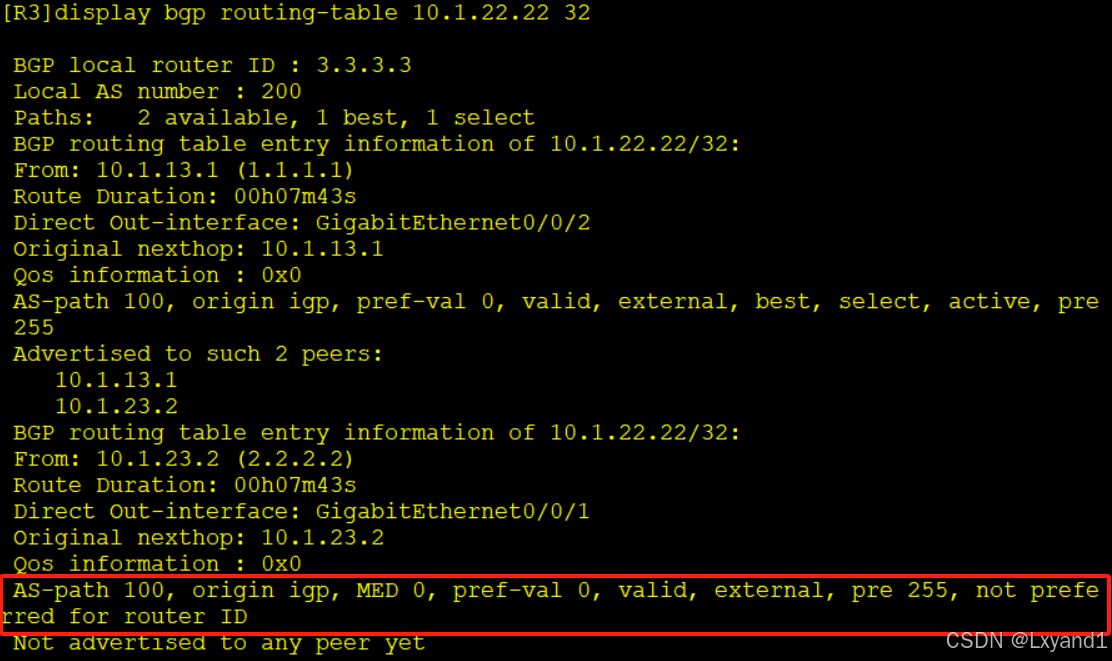
- 以上表示AR3选择了从AR1传过来的路由,原因是因为从AR1学习到的这一条路由的router-id小。
(12)实验 2.12优选具有最小BGP邻居地址的路由
【1】实验目的
深入理解13条选路原则的第十二条。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
- 基础环境搭建:IP 地址规划和前面实验一致。
- 配置 AS100 内部的 IGP,确保 AR1,AR2 的回环口可达。
- 配置 AS100 内部的IBGP 连接关系,用loopback0 和lookback1作为建立 IBGP 连接的IP 地址,以上步骤不再展示。
a.注意在AR1和AR2上分别都有lookback0和lookback1接口

b.接下来配置IBGP邻居
在AR1上:
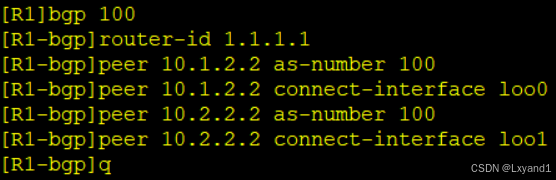
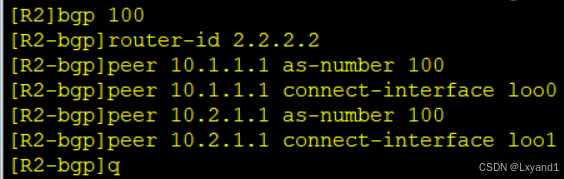
在AR2上:
c.在AR2上用network方式产生一条BGP路由100.1.2.2/32
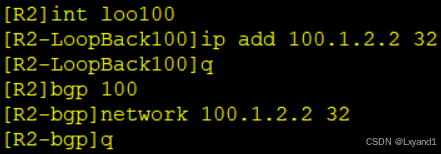
d.再去AR1上查看BGP路由表
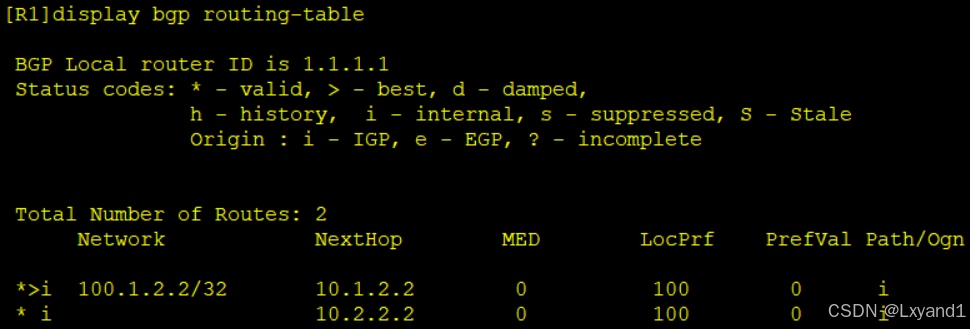
- 以上表示AR1选择了更小的IP地址建立的邻居关系的路由
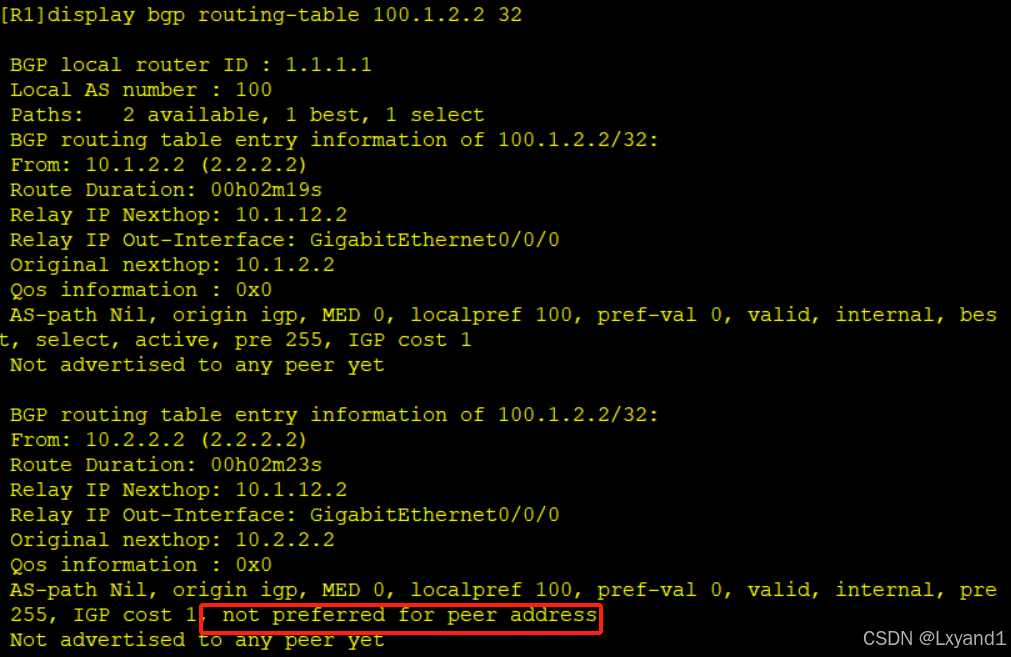
e.再去查看详细信息,也会得到此结果
3.BGP高级部分
(1)实验 3.1路由反射器
【1】实验目的
通过本实验掌握:
- RR的反射原理和反射规则
- RR的配置
- Originator_ID属性和Cluster_List属性
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑

【4】实验步骤
- 配置 AS100与 AS200 EBGP 邻居,使用 AR1 AR2 的直连接口;
- 配置AS200内部 AR2与AR3,AR3与AR4的IBGP 连接关系,用loopback0 作为建立IBGP 连接的IP地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接
- 在 AR1 上用宣告的方式产生一条 BGP 路由:10.1.1.1/24。
- 以上步骤不再演示
- 当还没有配置 RR的时候,AR3从AR2 这个IBGP 邻居收到的路由不会传给 AR4,这是由IBGP 的水平分割决定的。
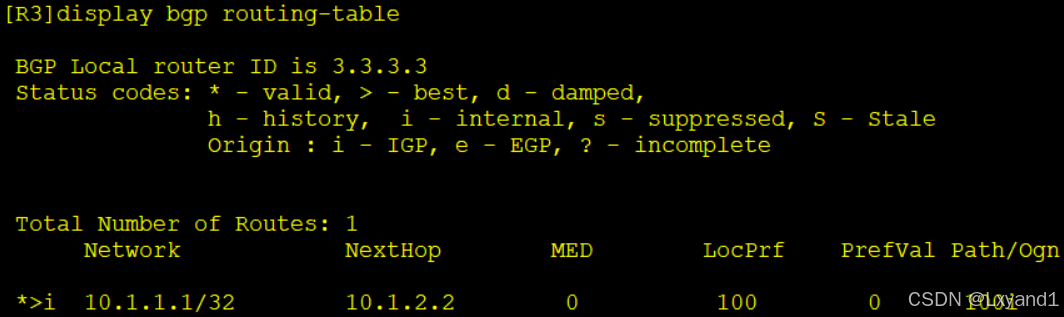
a.查看R3的BGP路由表
b.然后在R3查看R4邻居详细

部分忽略
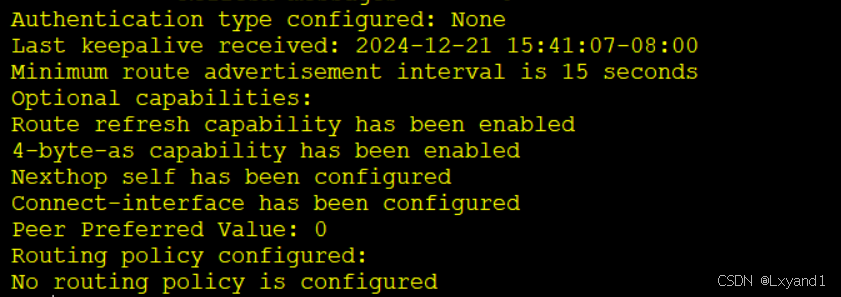
- 以上命令表示AR3并没有把任何路由传给AR4。
c.现在去AR3上配置为路由反射器,将AR4和AR2配置成自己的RR-client

d.直接在AR4上查看BGP路由表
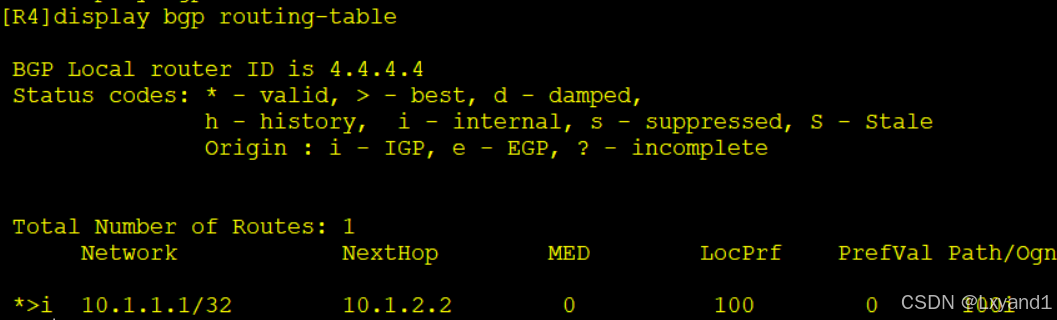
- R4收到了R3反射的路由
e.再去AR3上查看AR2传给他的路由条目
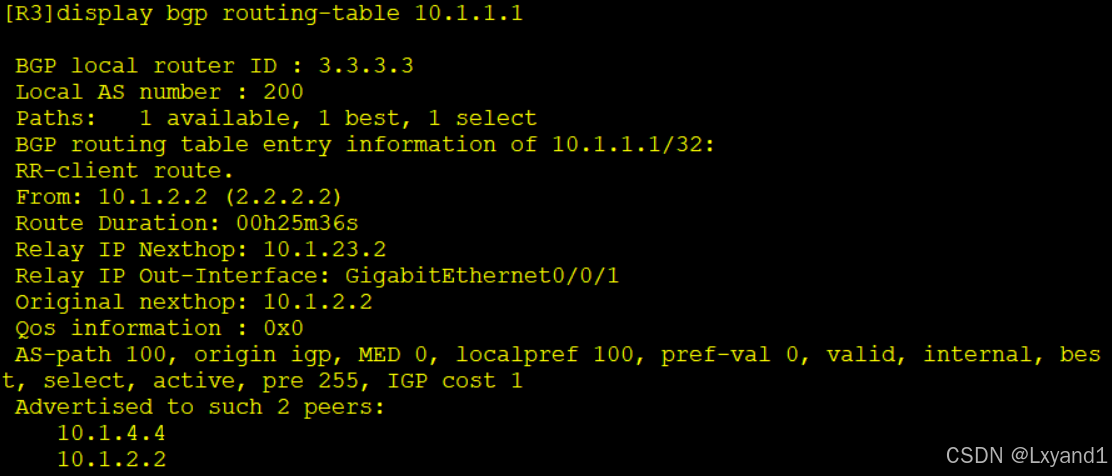
以上表示此路由是从RR的客户端收到的。
f.然后再去AR4上查看AR3反射出去的路由4
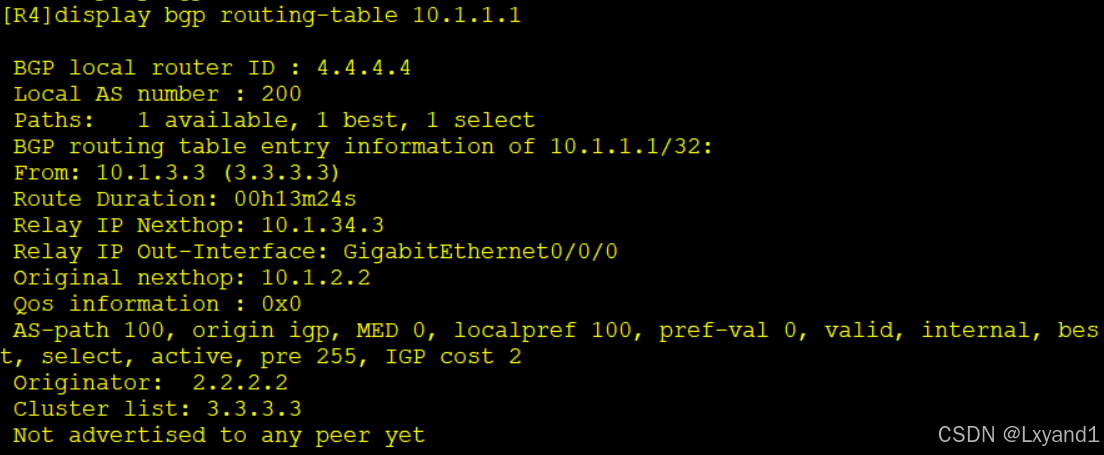
以上表示我们上文提到的两种新属性:Originator ID和Cluster list。Cluster list里的ID是可以修改的,当没有做出修改时,默认是RR的router ID。
f.去AR3上修改RR的cluster ID

g.再去AR4上查看
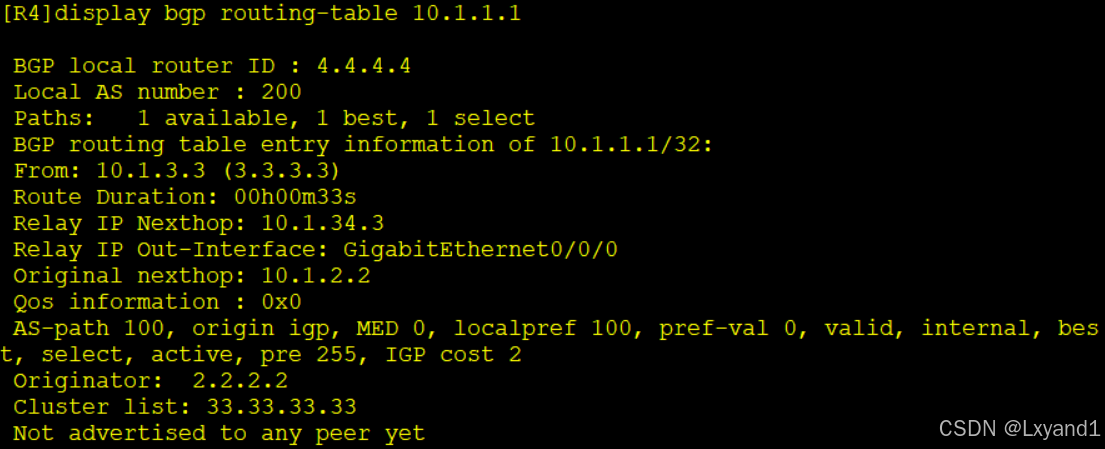
- 可以看到和刚刚不一样了
(2)实验 3.2 层次化的 RR
【1】实验目的
通过此实验可以掌握如何配置一个层次化的RR环境。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑

【4】实验步骤
- 配置 AS100与 AS200 EBGP 邻居,使用 AR1 AR2 的直连接口;
- 配置AS200内部 AR2与AR3,AR3与AR4的IBGP 连接关系,用loopback0 作为建立IBGP 连接的IP地址,配置下一跳本地(next-hop-local)
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接
- 在 AR1 上用宣告的方式产生一条 BGP 路由:10.1.1.1/24。
- 以上步骤不再演示
- 如果不配置 RR,那么这条路由只会传到 AR3上,如果配置 AR3为 RR,AR2,AR4 作为它的 client,此路由将会传递到 AR4,但是还是不会传到 AR5,如要配置 AR5 也为 AR3 的cient,就需要新增加一条 BGP 的连接。如果在一个大型的网络当中,有可能一个 RR 的负担就太重了,这时就可以用到层次化的 RR。
- 如果 AR4是AR3 的 client,但同时也是一个RR,AR5为 AR4 的 client。配置起来就比较简单了。
a.在AR3上指定AR2和AR4为client
b.再去AR4上指定AR5为client

c.然后去AR5上查看BGP路由表:
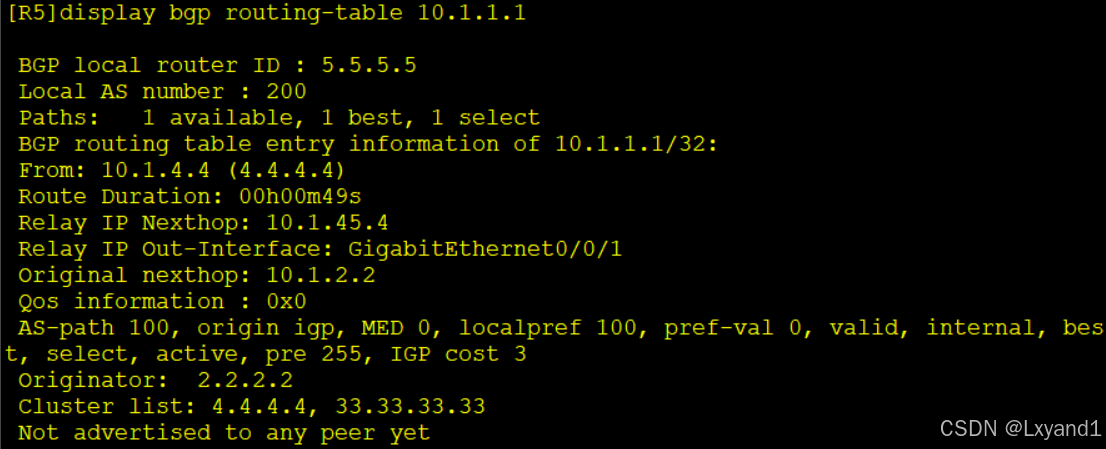
- 可以观察到AR5收到的这条路由经过了两个RR,分别是4.4.4.4,和33.33.33.33,就是AR4和AR3。
(3)实验 3.3 过滤私有 AS号
【1】实验目的
通过此实验可以掌握如何配置一个层次化的RR环境。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑

【4】实验步骤
- 配置AS200内部的IBGP关系
- 配置各个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接
- 在 AR1 上用宣告的方式产生一条 BGP 路由:10.1.1.1/24。
- 以上步骤不再演示
a.我们在AR4上查看BGP路由表
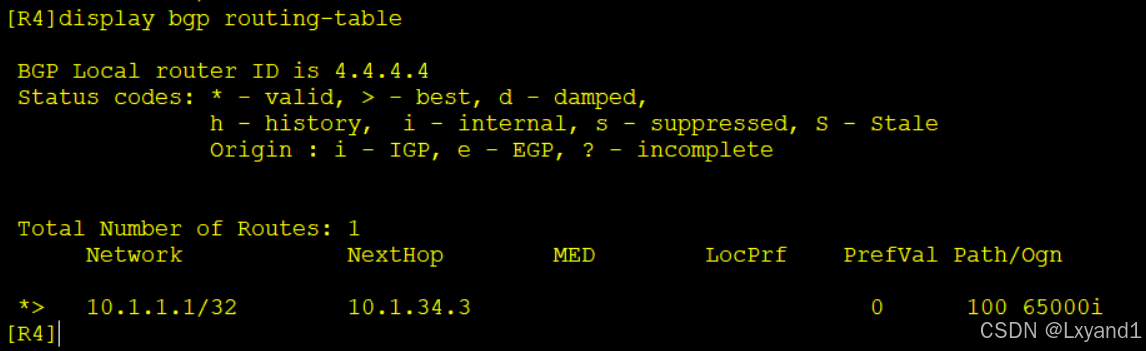
- 在AR4上可以看到此路由是起源于AS65000这个私有的AS号。
b.为了隐藏客户的私有AS号,需要在AR3上做以下配置

c.再去AR4查看BGP路由表
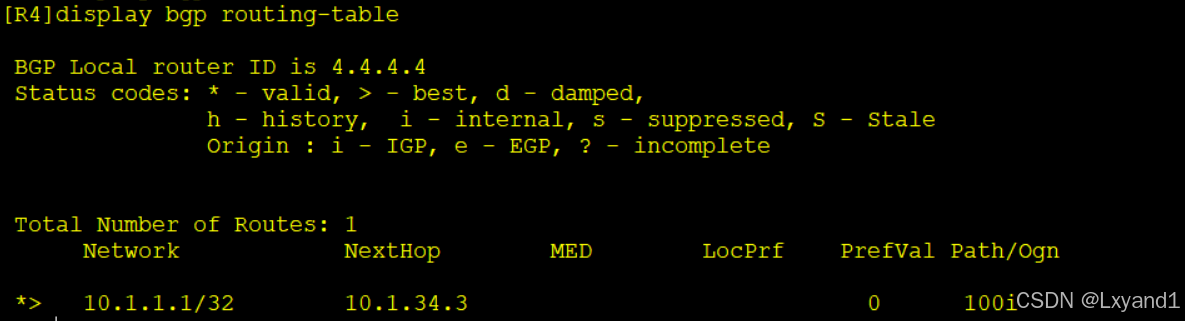
- 以上表示私有的AS号不会再被传出去。
4.BGP路由控制
(1)实验 4.1过滤 BGP 路由的方法
【1】实验目的
通过本实验可以掌握多种过滤 BGP 路由的方法,如下:
- 直接调用前缀列表过滤路由,命令:peerX.X.X.X ip-prefix XX
- 用 filter-policy 加访问控制列表过滤:
- 针对某个邻居用命令:peerX.X.X.X filter-policy+访问列表
- 或是针对所有邻居用命令:filter-policy+访问列表/前缀列表
- 用 route-policy 过滤 命令:peer X.X.X.Xroute-policy
- 每种过滤的方法都可用于二个方向。import 和 export
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
配置好各个路由器的EBGP邻居关系,各个路由器对应的AS号为R1对应AS100,R2对应AS 200,R3对应AS 300,R4对应AS400。
- 在 AR2 上产生四条路由:100.1.0.0/24 100.1.1.0/24 100.1.2.0/24 100.1.3.0/24
- 在 AR3 上产生四条路由:100.1.0.0/25 100.1.1.0/25 100.1.2.0/25 100.1.3.0/25
- 在 AR4 上产生四条路由:100.1.0.0/26 100,1.1.0/26 100.1.2.0/26 100.1.3.0/26
- 以上可以通过在设备上配置 loopback,然后通过 network 实现。
a.以上做完后再AR1上查看BGP路由表:
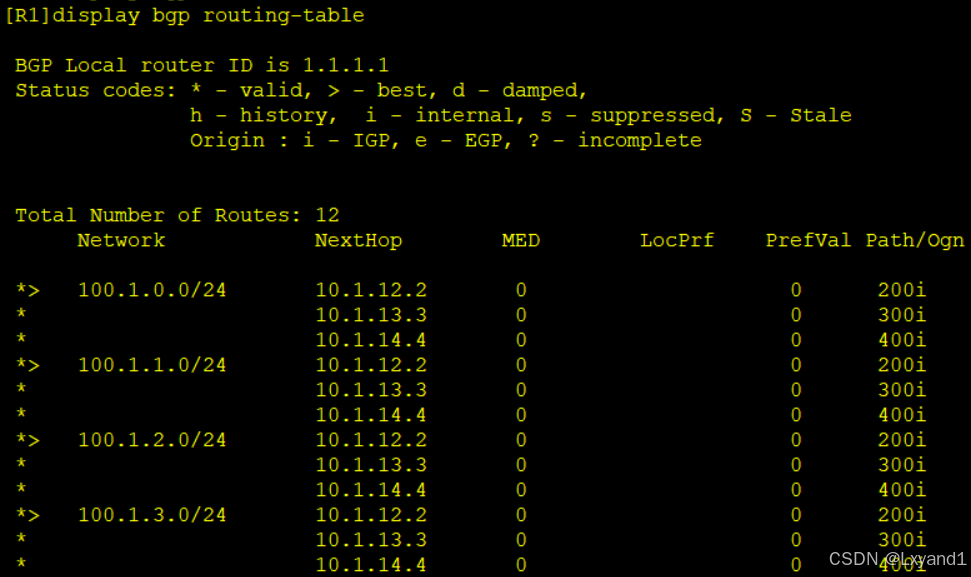
- 在R1上过滤掉100.1.0.0/24, 100.1.1.0/24,100.1.2.0/24,100.1.3.0/24这四条路由。
b.先用peer X.X.X.X ip-prefix来实现

c.调用刚才写的前缀列表

d.再查看AR1的BGP路由表
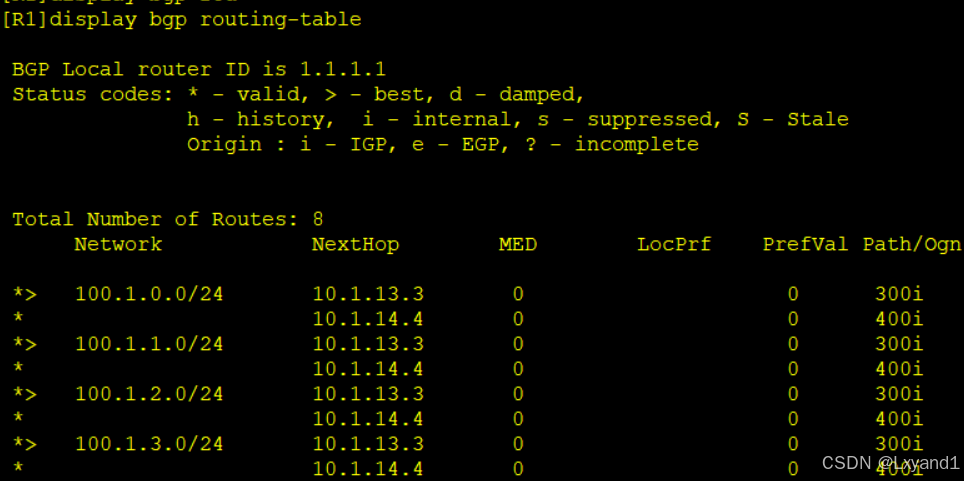
- 以上就可以看到没有AR2传过来的路由了,表示正确过滤掉了。
e.使用filter-policy+前缀列表或访问列表
在AR1上先undo掉刚才的配置:

直接调用刚才写好的前缀列表:

f.然后在看AR1的BGP表:
- 以上输出表示此方法也生效了。
- 用此方法的时候,后面不仅可以跟前缓列表,还可以跟我们所熟知的访问控制列表。想一想,用标准的访问控制列表可以完成吗?答案是不行的,因为标准的访问控制列表只能去匹配前缀,而不能匹配掩码的长度,这里的 12 条路由的前缀都是一样的,所以搞不定。
g.用peer X.X.X.X route-policy
- route-policy将会是你最佳的选择,因为route-policy更加灵活,而且route-policy可以调用前面所有的过滤策略方式
在AR1上:
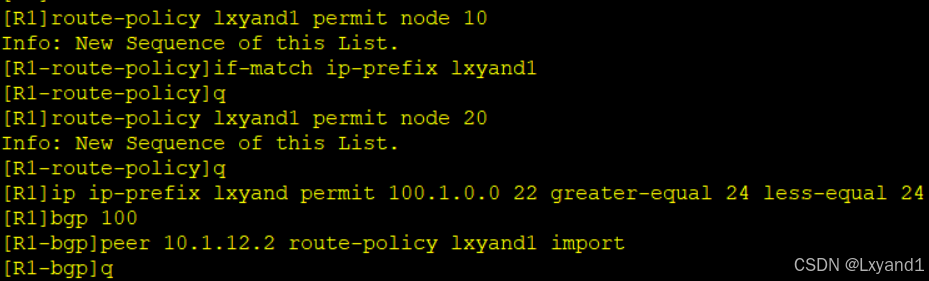
h.直接查看AR1的bgp路由表:
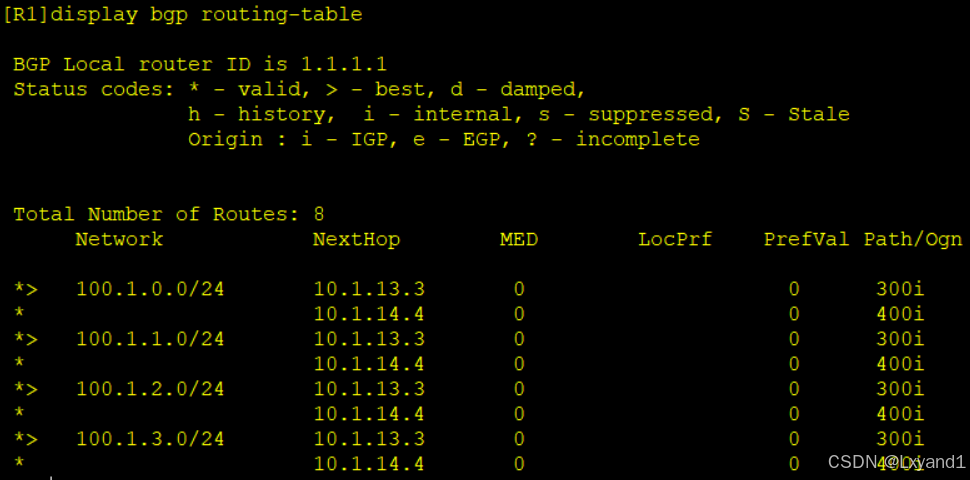
(2)实验 4.2用AS-path flter控制路由
- 这个实际工作上用的很少,主要还是理论考试会考的比较多,需要记住正则表达式的正确用法,实验的话这个4.2就略过了,以下给出正则表达式的表格。

(3)实验 4.3 使用 CommunityFilter 控制路由
【1】实验目的
通过本实验,可以掌握用Community值去匹配一条BGP路由,并且对路由进行控制。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
【4】实验步骤
配置好各个路由器的EBGP邻居关系,各个路由器对应的AS号为R1对应AS100,R2对应AS 200,R3对应AS 300。
a.在AR1上用network方式产生两条路由,并且为每条路由带上一个community值。
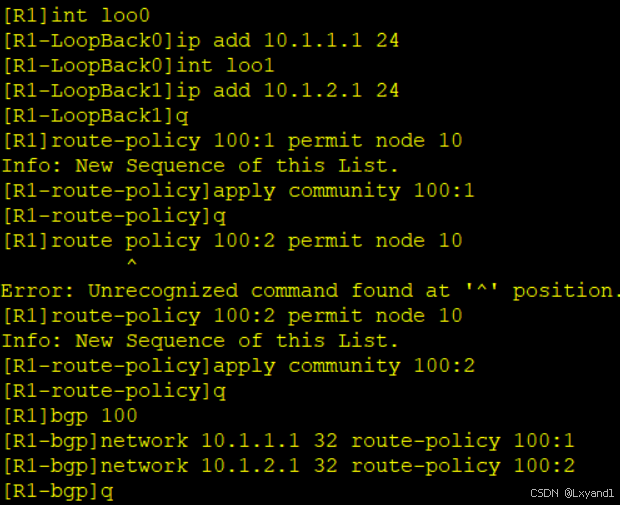
b.去查看这两天路由的community值
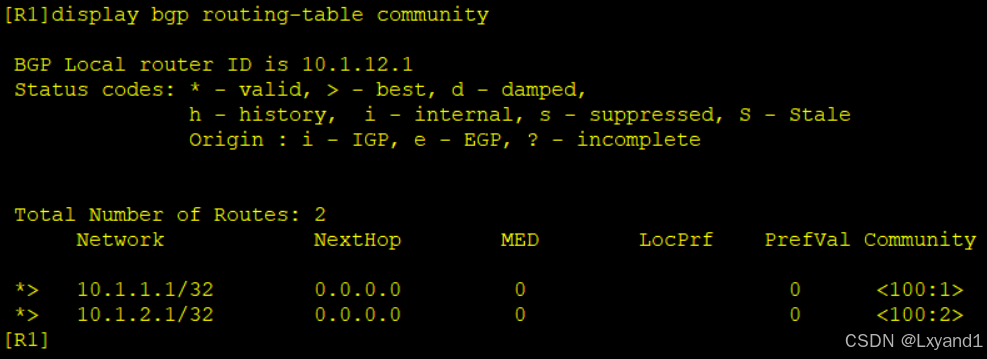
这时我们去AR2上查看的时候依然看不到属性值,是因为community值在默认情况下是不通告的。需要在AR1上配置如下命令:

c.然后去AR2上查看现象
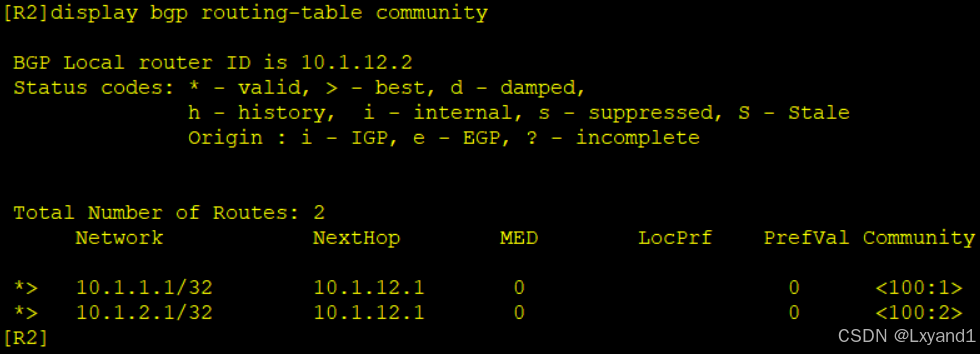
可以看到是有community值的。
community值还可以再查看路由的时候直接调用,如下:
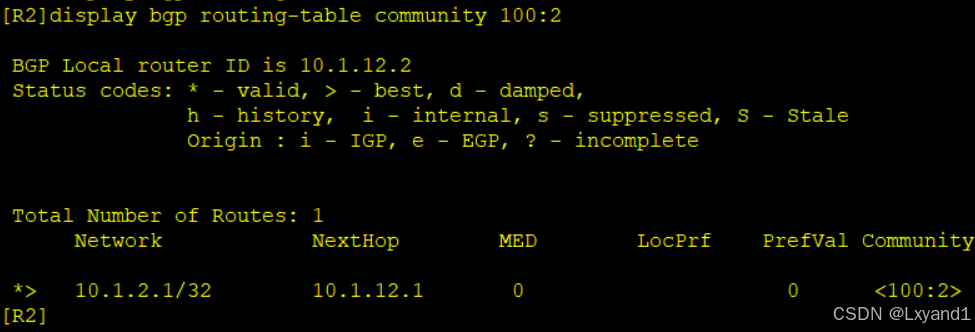
d.我们可以根据这些值来匹配路由做一些控制的策略
 、
、
- 以上是写一条community-list去匹配路由

e.再去进程下调用

f.查看AR2的BGP路由表
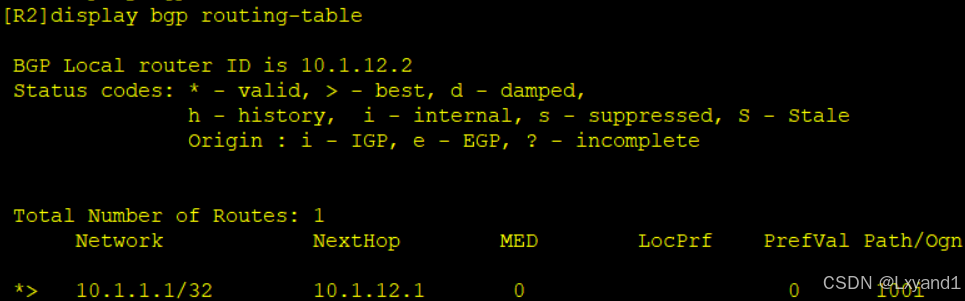
以上表示通过匹配团体属性,只接收了10.1.1.1这条路由。
在匹配上一条路由后,我们还可以给他打上新的团体属性。
g.回到刚才的route-policy里面做修改
h.直接在AR2上查看现象
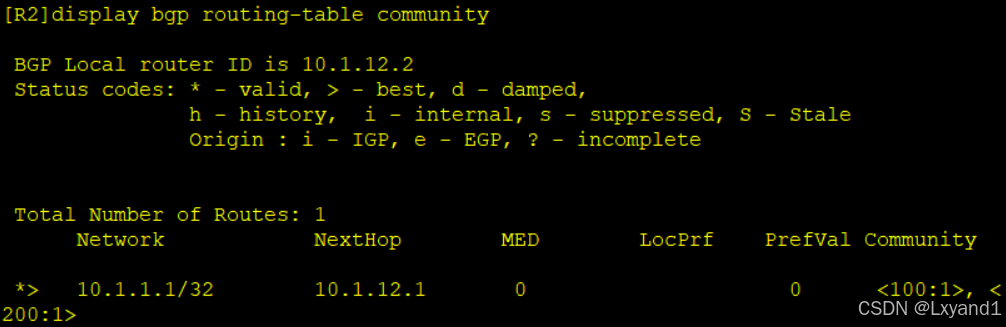
以上表示此路由有两个团体属性值了。
i.再把这些团体属性值发给AR3

j.直接在AR3上查看BGP现象
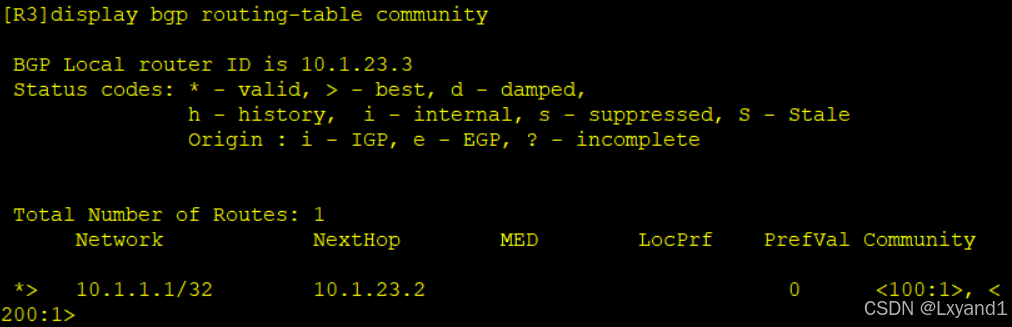
可见AR3也收到了。
5.BGP负载均衡
(1)实验 5.1 IBGP的等价负载均衡
【1】实验目的
掌握实现IBGP负载均衡的命令;掌握实现IBGP负载均衡的条件。
【2】IP地址规划
-
互联地址采用 10.1.XY.X/24位,比如 AR1与 AR2 的互联接口地址分别为 10.1.12.1/24和 10.1.12.2/24,以此类推。
-
每台设备都有一个测试用的loopback0口,地址为10.1.X.X/32,比如 AR1的loopback0口地址为 10.1.1.1/32,以此类推。
【3】实验拓扑
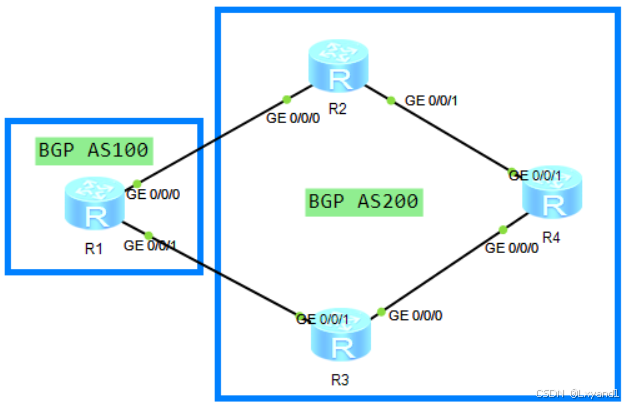
【4】实验步骤
- 配置 AS200 内部的 IGP,确保 AR2,AR3,AR4 的回环口可达。
- 配置 AS200 内部的IBGP 连接关系,AR2与AR4,AR3与AR4,用loopback0 作为建立 IBGP 连接的IP 地址,AR2,AR3 配置下一跳为自我(next-hop-self)。
- 配置两个 AS 间的 EBGP 连接关系,用直连接口IP 地址建立 EBGP 连接以上步骤不再演示,请参考实验 2.1,或实验 1.1,1.2等。
- 去 AR1 上产生一条 10.1.1.1/32 的路由。
a.以上步骤做完后,直接在AR4上查看BGP路由表
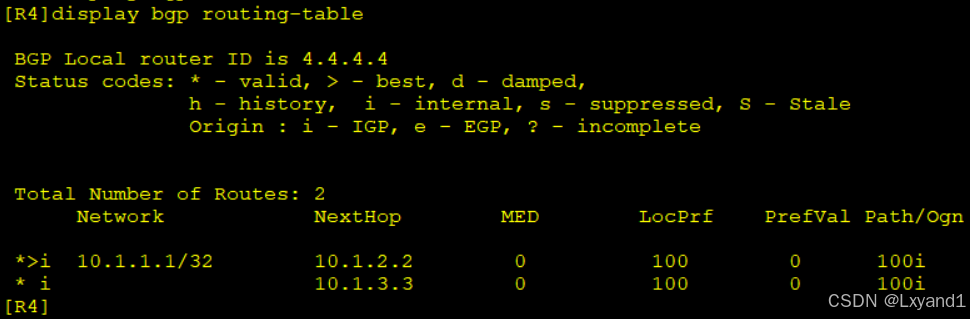
以上表示AR2被选为了最优,是通过第11条选路原则——router id最小 选出的最优。
b.去查看AR4 IP路由表,就会发现只有一条路径
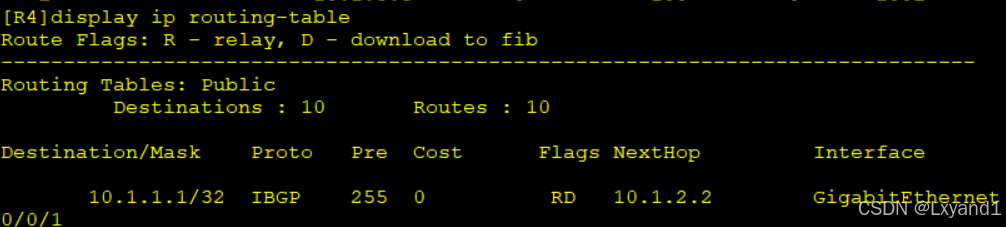
- 注意一个原则:只要在前8条选路原则都不能选出最优的情况下,BGP都可以去实现负载均衡。
- 具体理论请关注我的BGP专栏,里面有BGP全网最详解,以及BGP选路原则的实验。
c.在AR4上开启负载均衡

d.再去看AR4的IP 路由表
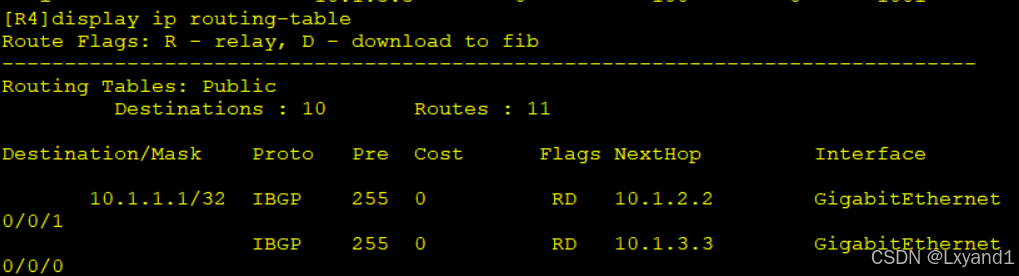
- 以上表示去往AR1的10.1.1.1有了两条路径了,实现了负载均衡。
注意:负载均衡生效是把BGP条目放进路由表的时候生效,而不是在BGP选路的时候选出两条最优路由
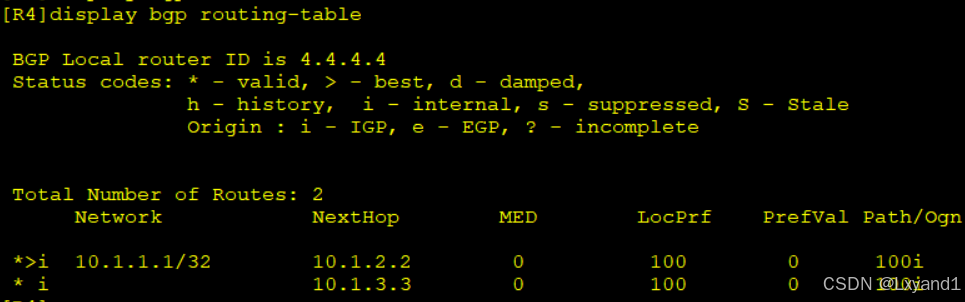
e.我们再次查看BGP表项,就会发现依然只有一条是最优的
(2)实验 5.2 EBGP的等价负载均衡
继承以上的5.1的实验配置,我们来做5.2。
【1】实验步骤
a.现在AR上宣告一条路由前缀进入bgp
b.我们去AR1上去查看BGP路由表
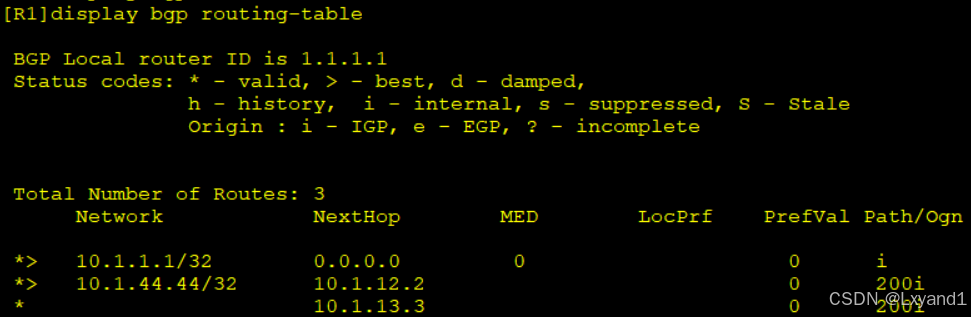
发现AR1上学习到10.1.4.4/32通过AR2 和AR3学习到,此时优选的原因是AR2的router-id更小。
c.同理在AR1上开启等价负载均衡

d.查看IP路由表
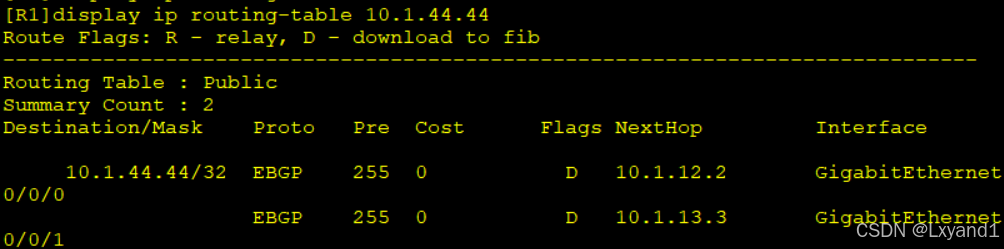
小总结:
在这最后,请允许博主发表一下感想,这是一篇四万余字的文章,需要对知识点以及实验配置做较为深度的剖析,肝了大约两个星期,颈椎病都快犯了。
至此,BGP全网最详解结束。
既然都看到这里了,请您点个赞再走吧!

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









