






网络名称:TCM
作者:Wenwen Yu*,1, Yuliang Liu∗,1, Wei Hua1, Deqiang Jiang2, Bo Ren2, Xiang Bai†,1
单位:华中科技大学,腾讯优图实验室
Abstract
场景文本包含有丰富的文本(语义)和视觉信息,与CLIP模型有天然的联系。
本文贡献:
- 提出的框架可以用于改进现有的场景文本检测器
- 促进了现有方法的few-shot训练能力
- 将CLIP模型迁移到现有的场景文本检测方法中,进一步实现较好的区域适应能力(domain adaptation ability)
Introduction

不同的文本检测范式对比
将CLIP模型用于场景文本检测器的关键在于寻找一种合适的方法来利用每幅图所包含的视觉和语义先验信息
- 提出了一个新的可插拔文本检测框架TCM,可以提高现有检测方法的性能
- 该方法是few-shot的
- 在不同数据集上的泛化能力强
- 在无代理任务预训练的情况下,TCM仍可以利用CLIP模型的先验知识,使其结果优于其他场景文本预训练方法
Relate Works
单峰场景文本检测(Unimodal Scene Text Detection)
单峰场景文本检测直接用边界框标注,可分为基于分割的方法和基于回归的方法。
跨模态辅助场景文本检测(Cross-modal Assisted Scene Text Detection)
跨模态辅助场景文本检测旨在充分利用包括视觉、语义和文本知识在内的跨模态信息来提高性能。
Methodology
Contrastive Language-Image Pretraining(CLIP)
CLIP通过对比损失来学习两种模式的联合嵌入空间。给定图像-文本对,CLIP将最大化图像与匹配文本的余弦相似度,同时最小化与其他不匹配文本的余弦相似度。因此,CLIP就拥有zero-shot图像识别的能力。
要从模型中挖掘相关信息需要解决两个问题:
- 有效地从CLIP模型中获取先验知识的方法
- 原始模型只能衡量一个整体图像与单个单词或句子之间的相似度
Turning a CLIP into a Text Detector
本文设计了一种跨模态交互机制,通过视觉提示学习从CLIP图像编码器中恢复局部特征,捕捉细颗粒度信息以响应粗文本区域,用于后续文本实例与语言的匹配。
为了更好地利用与训练知识,本文引入了一个Language prompt Generator来生成每幅图像的条件线索,一个visual prompt Generator学习图像prompt,为文本检测任务调整被冻住的clip文本编码器。
此外,本文还设计了一种实例语言匹配方法来对齐图像嵌入和文本嵌入,鼓励图像编码器显式地从跨模态视觉-语言先验中细化文本区域。


Image Encoder
输入图像 I ′ ∈ R H × W × 3 I'\in \mathbb{R}^{H\times W \times 3} I′∈RH×W×3经过image Encoder后输出 I ∈ R H ^ × W ^ × C I\in \mathbb{R}^{\hat{H}\times \hat{W}\times C} I∈RH^×W^×C,其中 H ^ = H s , W ^ = W s , C = 1024 \hat{H}=\frac{H}{s},\hat{W}=\frac{W}{s},C=1024 H^=sH,W^=sW,C=1024,s为下采样倍率,设置为32。
该过程可表示为:
I
=
I
m
a
g
e
E
n
c
o
d
e
r
(
I
′
)
I = ImageEncoder(I')
I=ImageEncoder(I′)
Text Encoder
Text Encoder将K种Prompt作为输入,由于文本检测中对象仅有文本一类,因此设置为1。将prompt嵌入到一个连续向量空间 T = { t 1 , ⋯ , t k ) } ∈ R K × C T=\{t_1,\cdots,t_k)\}\in\mathbb{R}^{K\times C} T={t1,⋯,tk)}∈RK×C中,并作为Text Encoder的输出, t i ∈ R C t_i\in\mathbb{R}^C ti∈RC.
与原始的clip模型中的prompt不同,本文将离散语言提示符预定义为“Text”,则对于输入
t
i
n
′
t_{in}'
tin′,该过程可表示为:
t
i
n
′
=
W
o
r
d
E
m
b
e
d
d
i
n
g
(
T
e
x
t
)
∈
R
D
t_{in}'=WordEmbedding(Text)\in\mathbb{R}^D
tin′=WordEmbedding(Text)∈RD
其中D为字符嵌入维度,值为512。
受CoOP的启发,本文添加了可学习的prompt
{
c
1
,
⋯
,
c
n
}
\{c_1,\cdots,c_n\}
{c1,⋯,cn}学习文本嵌入的鲁棒可移植性,便于clip模型的zero-shot迁移,n表示可学习prompt的数量,这里设置为4,
c
i
∈
R
D
c_i\in\mathcal{R}^D
ci∈RD,所以,令输入为
t
i
n
t_{in}
tin则过程可表示为:
t
i
n
=
[
c
1
,
⋯
,
c
n
,
t
i
n
′
]
∈
R
(
n
+
1
)
×
D
t_{in}=[c_1,\cdots,c_n,t_{in}']\in\mathbb{R}^{(n+1)\times D}
tin=[c1,⋯,cn,tin′]∈R(n+1)×D
Text Encoder将
t
i
n
t_{in}
tin作为输入,生成text embedding
T
=
{
t
1
}
∈
R
C
T=\{t_1\}\in\mathbb{R}^C
T={t1}∈RC,并被简化为
t
o
u
t
∈
R
C
t_{out}\in\mathcal{R}^C
tout∈RC:
t
o
u
t
=
T
e
x
t
E
n
c
o
d
e
r
(
t
i
n
)
∈
R
C
t_{out}=TextEncoder(t_{in})\in\mathbb{R}^C
tout=TextEncoder(tin)∈RC
Language Prompt Generator
为了解决在测试文本实例与训练图像分布不均的开放式场景中可能面临的few-shot和有限泛化能力的影响,本文提出使用Language Prompt Generator来生成条件特征向量,即Conditional cue(cc),对每一张图片,cc将和
t
i
n
t_{in}
tin共同组成
t
^
i
n
\hat{t}_{in}
t^in,即:
t
^
i
n
=
c
c
+
t
i
n
∈
R
(
n
+
1
)
×
D
\hat{t}_{in}=cc+t_{in}\in\mathbb{R}^{(n+1)\times D}
t^in=cc+tin∈R(n+1)×D
t
^
i
n
\hat{t}_{in}
t^in表示新的text Encoder的Prompt输入。
cc的生成如下:
c
c
=
L
N
(
σ
(
L
N
(
I
‾
)
W
1
+
b
1
)
)
W
2
+
b
2
∈
R
D
cc=LN(\sigma(LN(\overline{I})W_1+b_1))W_2+b_2 \in \mathbb{R}^D
cc=LN(σ(LN(I)W1+b1))W2+b2∈RD
其中
I
‾
∈
R
C
,
W
1
∈
R
C
×
C
,
W
2
∈
R
C
×
D
,
b
1
∈
R
C
,
b
2
∈
R
D
\overline{I}\in \mathbb{R}^{\mathbb{C}}, W_1\in \mathbb{R}^{C\times C},W_2\in \mathbb{R}^{C\times D},b_1\in \mathbb{R}^C,b_2\in \mathbb{R}^D
I∈RC,W1∈RC×C,W2∈RC×D,b1∈RC,b2∈RD,
I
‾
\overline{I}
I是由
I
I
I经过与clip中相同的全局池化层得到的。
Instance-Language Matching
P = s i g m o i d ( I ^ t o u t T / τ ) ∈ R H ~ × W ~ × 1 P=sigmoid(\hat{I}t_{out}^T/\tau)\in \mathbb{R}^{\widetilde{H}\times \widetilde{W} \times1} P=sigmoid(I^toutT/τ)∈RH ×W ×1
P为二值文本分割图, t o u t t_{out} tout为文本嵌入
最小化P和标签之间的二进制交叉熵损失:
L
a
u
x
=
∑
i
H
~
∑
j
W
~
y
i
j
log
P
i
j
+
(
1
−
y
i
j
)
log
(
1
−
P
i
j
)
\mathcal{L}_{aux}=\sum_i^{\widetilde{H}}\sum_j^{\widetilde{W}}y_{ij}\log{P_{ij}} +(1-y_{ij})\log(1-P_{ij})
Laux=i∑H
j∑W
yijlogPij+(1−yij)log(1−Pij)
总损失函数:
L
t
o
t
a
l
=
L
d
e
t
+
λ
L
a
u
x
\mathcal{L}_{total}=\mathcal{L}_{det}+\lambda\mathcal{L}_{aux}
Ltotal=Ldet+λLaux
实验结果
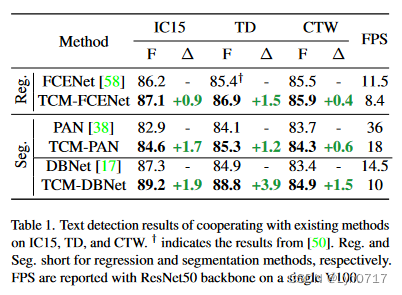
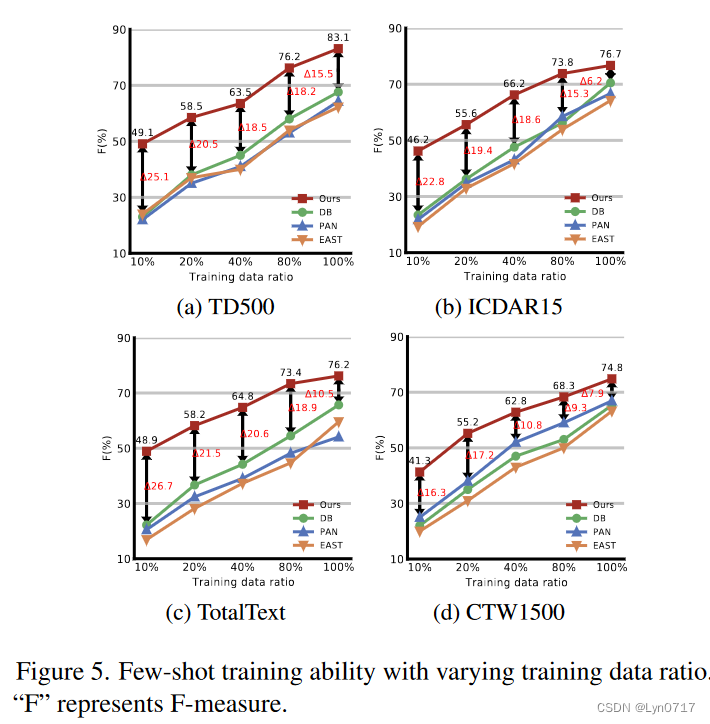
可以看出本文提出的方法few-shot能力还是很强的,同时,我认为将CLIP模型用于与文本有关的其他任务也是非常可行的。















 2753
2753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









