








文章目录
Introduction
几个重要的点:
- 并不把输入的边缘当作一个较强的约束条件,也就是,并不会去完全拟合输入的手绘图象
- 使用联合图像(Joint Image)训练一个生成对抗网络——上下文相关的生成对抗网络(Contextual GAN)
- 将从手绘图象生成真实图像的任务看成一个根据图像的上下文,也就是输入的手绘图象,将图像进一步完成,变成一张真实图像,也就是一个图像补全(Image Completion)问题,而不是一个图像生成问题
Related Works
- Conditional GAN,在生成对抗网络(GAN,Generative Adversarial Network)中引入条件变量(Conditional Variable)
- Deep Image Completion with Perceptual and Contextual Losses,采用没有缺失的图片对生成器(G,Generator)和判别器(D,Discriminator)进行预训练,然后使用这两个网络来补全完整的图像
- 使用一个大型的数据库来训练一个跨域卷积神经网络(cross-domain CNN)
- 最近的一些sketch-to-image的工作中,都是在基于手绘图象的图像检索中对这样的mapping进行研究的,并且真实图片和手绘图象是在不同的网络中进行训练的
- 通过评估若干个triplet CNN来衡量手绘图象和真实图像的相似程度
- contrastive Loss,triplet loss 以及 ranking loss的运用
Approach
Joint Sketch-Image Representation 联合手绘图像的表示
和通常的图像补全网络的不同之处,如下图所示,上层是图像补全网络的过程,下层是论文实现的过程:
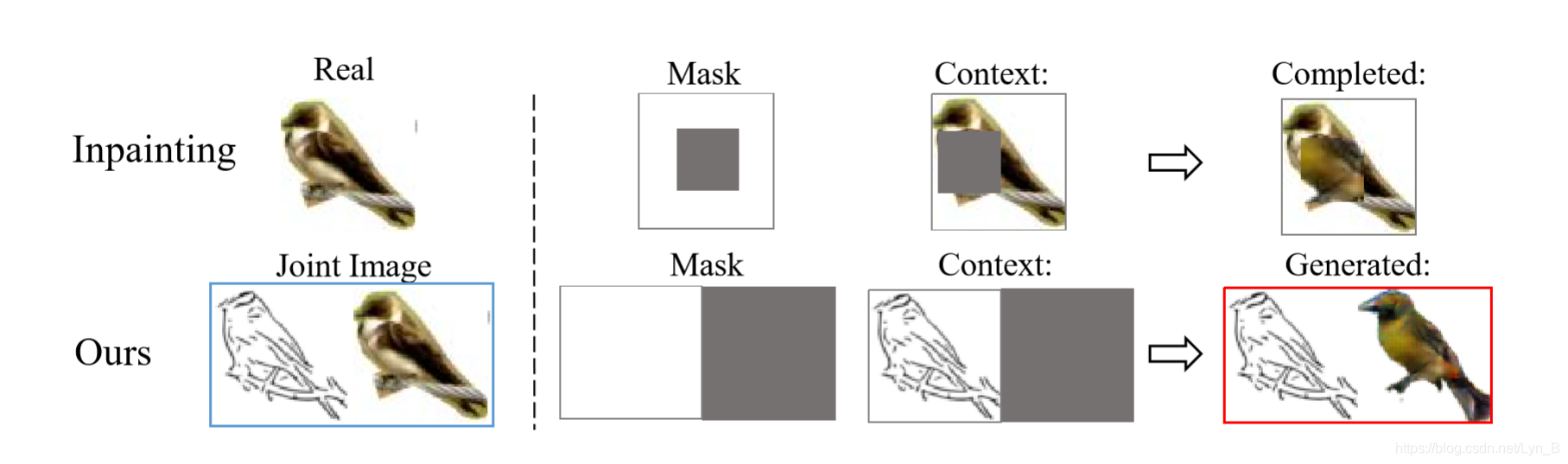 可以看到,在输入方面:可以看到上图所示论文的方法的输入图像就是前面所说的联合图像(Joint Image),由手绘图象(Sketch)A,和真实图像(Real)B组成的手绘图–真实图联合联合对AB
可以看到,在输入方面:可以看到上图所示论文的方法的输入图像就是前面所说的联合图像(Joint Image),由手绘图象(Sketch)A,和真实图像(Real)B组成的手绘图–真实图联合联合对AB
Objective Function
Contextual Loss 上下文损失
(0)
L
c
o
n
t
e
x
t
u
a
l
(
z
)
=
D
K
L
(
M
⊙
y
,
M
⊙
G
(
z
)
)
\mathcal{L_{contextual}}(z) = D_{KL}(M\odot y,M\odot G(z)) \tag{0}
Lcontextual(z)=DKL(M⊙y,M⊙G(z))(0)
其中:
- ⊙ \odot ⊙表示的是矩阵乘法(Hadamard Product,哈达玛积 c i , j = a i , j b i , j c_{i,j}=a_{i,j}b_{i,j} ci,j=ai,jbi,j,即维度相同的两个矩阵的对应位置相乘)
- M M M 是一个二值矩阵模板,而事实上,手绘图像也是一张二值图像,所以这里使用KL散度来计算这两张素描的相似程度,而这将会得到更好的拟合效果
- y y y 是神经网络可以观测到的输入手绘图像
- G ( z ) G(z) G(z) 这就是生成对抗网络中,生成器网络的输出
Perceptual Loss 感知损失
根据生成器网络的对抗损失,有:
(1)
L
p
e
r
c
e
p
t
u
a
l
(
z
)
=
log
(
1
−
D
(
G
(
z
)
)
)
\mathcal{L_{perceptual}}(z) = \log(1-D(G(z)))\tag{1}
Lperceptual(z)=log(1−D(G(z)))(1)
其中,
D
(
G
(
z
)
)
D(G(z))
D(G(z))是判别器最终的输出。
感知损失可以对图像的语义内容进行一定程度上的维持:感知损失通过比较待生成的图像和目标图像经过卷积神经网络的特征值,使得它们在语义上尽可能的相似,从而保证了生成的图像的语义内容。
也就是说,感知损失实际上就是衡量待生成的图像和目标图像在高层次的特征之间的差异,从而使得它们在高层特征上更加的相似,这也是为什么称为感知。
最终我们的目标函数就是这两个损失函数的加权和:
(2)
z
^
=
arg
min
(
L
c
o
n
t
e
x
t
u
a
l
(
z
)
+
λ
L
p
e
r
c
e
p
t
u
a
l
(
z
)
)
\hat z = \arg\min(\mathcal{L_{contextual}}(z)+\lambda\mathcal{L_{perceptual}(z)})\tag{2}
z^=argmin(Lcontextual(z)+λLperceptual(z))(2)
其中,
λ
\lambda
λ 是一个超参数(hyperparameter),通过这个超参数使得生成的图片能够很好的依赖于输入。
Contextual GAN
包含两个阶段:
- 训练阶段(training stage):这个过程和传统的GAN的训练过程没有区别,只不过在这里的输入是联合图像(joint image)
- 补全阶段(completion stage):学习一个生成网络G
Projection through back propagation
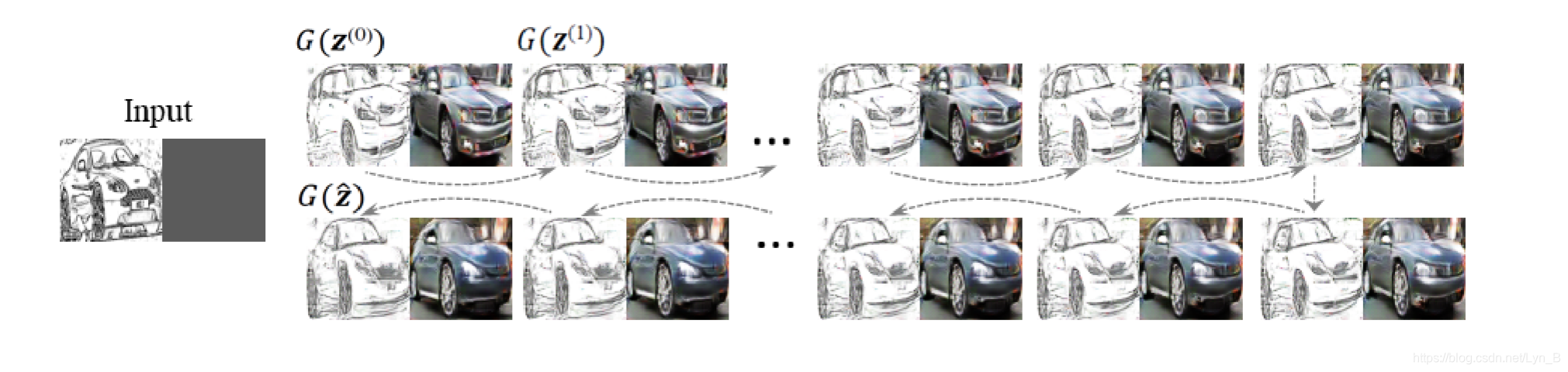
论文采用最小化(2)的指标的方法,而不是最大化
D
(
y
)
D(y)
D(y) 来计算
z
^
\hat z
z^,通过反向传播的迭代过程,将输入映射到生成器(Generator)的
z
z
z 所在的空间上。反向传播可以对
G
G
G 输入的随机噪声向量
z
z
z 进行更新。
要注意在这个阶段,只有输入的噪声向量被更新(采用梯度下降 gradient descent 的方法),而生成器网络和判别器网络的权重都保持不变,因为事实上在这个阶段的目的只是为了找到在隐空间(latent space)中离G 的流形最近的图像向量,得到完整的联合图像。
最终联合图像的遮盖部分为:
(3)
x
g
e
n
e
r
a
t
e
d
=
M
⊙
y
+
(
1
−
M
)
⊙
G
(
z
^
)
\bold x_{generated}=\bold M \odot y + (1-\bold M) \odot G(\hat z)\tag{3}
xgenerated=M⊙y+(1−M)⊙G(z^)(3)
Initialization 初始化
采用随机生成的噪声向量来初始化有一个明显的问题:生成的图像会受到初始化的影响。初始化的手绘图象部分跟输入部分有较大的感官上的差距的话,将会很难使用梯度下降的方法找到那个最近的 z z z,而这将会导致一个失败的样本,即使 λ \lambda λ 的值被设置的很小。
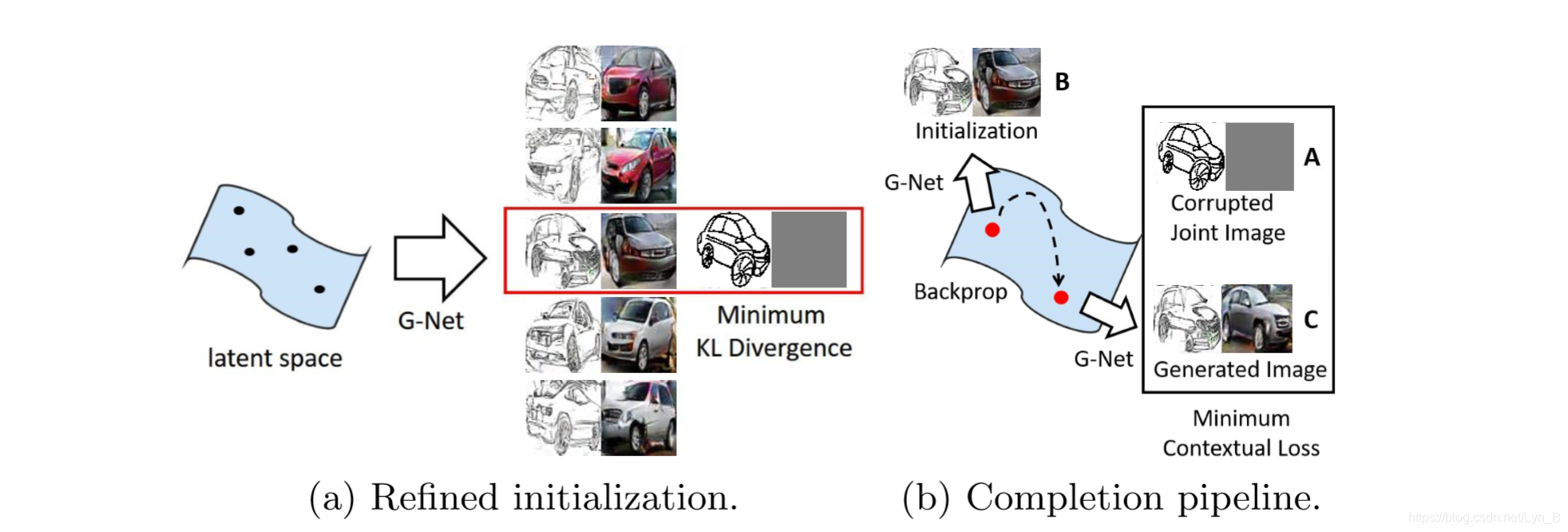
如上图,改进方法如下:
- 进行 N N N 个采样,,然后通过前向传递分别得到这 N N N 个噪声向量的手绘图象
- 计算输入手绘图象和这 N N N 个噪声向量的手绘图象的KL散度,得到的最低值作为最好的初始化结果,进行初始化
在具体的实现中, N = 10 N = 10 N=10
Network Architecture 网络架构
下图为完整的网络的结构:
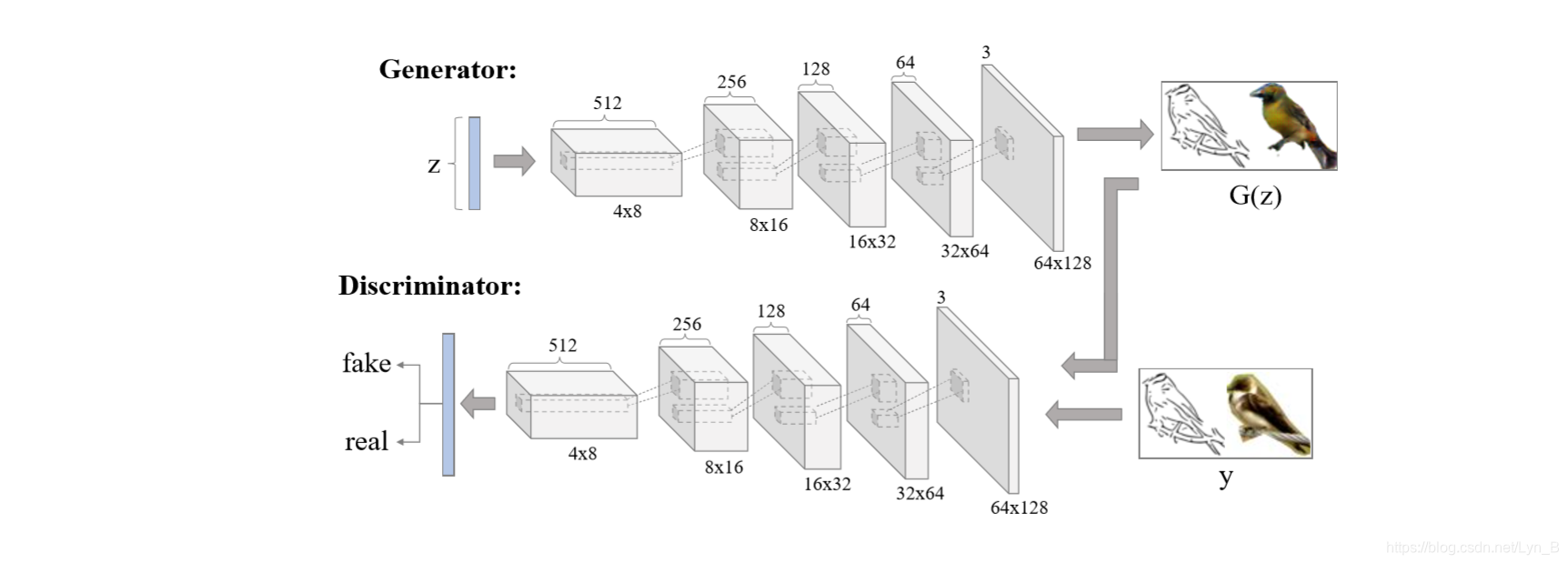
对于生成器(Generator):
- 输入:在-1到1之间随机采样的100维的噪声向量输入到生成器网络中
- 然后,一个 8192 × 2 8192\times2 8192×2 的线性层将输入变换成 4 × 8 × 512 4\times 8 \times 512 4×8×512
- 接着是5个上采样层(反卷积),卷积核的大小(size)为 5 × 5 5 \times 5 5×5,步长(stride)为 2 2 2。并且在每个上采样层后面都有一个 批标准化层(batch normalization layer),除了最后一个上采样层(为了加快训练并且保证稳定性)
- 最后取 tanh 得到最后的输出
神经网络的所有层都运用了Leaky rectified linear unit(LReLU)。这一系列的上采样和非线性处理共同完成了在隐空间(Latent Space)中的非线性加权上采样的过程,并且最终生成了 64 × 128 64\times128 64×128的较高分辨率的图像。
对于判别器(Discriminator):
- 输入: 64 × 128 × 3 64\times128\times3 64×128×3 的图像
- 四个卷积层(Convolutional Layer),每层得到的特征图像的维度减半(dimension halved),通道数量翻倍(channels doubled)。卷积核(convolutional kernel)的大小为 5 × 5 5 \times 5 5×5,步长为 2 2 2,最终得到了 4 × 8 × 512 4 \times 8 \times 512 4×8×512的输出
- 最后是一个全连接层(Full Connected Layer),将卷积层输出的结果变换为一个维度为 1 1 1 的向量
- Softmax Layer 计算损失(Loss)
Network Generality 网络的生成
提高网络的生成质量并且防止对某些风格的手绘图象过拟合:
- 使用多种风格的手绘图象(multiple style)
- 使用 XDoG 边缘检测算子(论文发现,XDoG出来的效果和实际的手绘图象更加接近,并且细节更加丰富),Photoshop 的影印效果(Photocopy effect)以及FDoG 滤波器来生成不同风格的手绘图象
Datasets and Implementation 数据集和实现
用到的三个数据集:
- 人脸 L a r g e − s c a l e C e l e b F a c e s A t t r i b u t e s ( C e l e b A ) d a t a s e t Large-scale CelebFaces Attributes (CelebA) dataset Large−scaleCelebFacesAttributes(CelebA)dataset
- 鸟 C a l t e c h U C S D B i r d s − 200 − 2011 CaltechUCSD Birds-200-2011 CaltechUCSDBirds−200−2011
- 汽车 S t a n f o r d ’ s C a r s D a t a s e t Stanford’s Cars Dataset Stanford’sCarsDataset
Data Process
Implementation
使用 C o n t e x t u a l G A N Contextual GAN ContextualGAN 分别针对这三类图像对网络进行预训练。参数设置如下:
| parameters | value |
|---|---|
| A d a m O p t i m i z e r Adam Optimizer AdamOptimizer(判别器和生成器)learning rate | 0.0002 |
| A d a m O p t i m i z e r Adam Optimizer AdamOptimizer(判别器和生成器)beta | 0.5 |
| batch | 64 |
| epoch | 200 |
训练时长在
6
6
6 到
48
48
48 小时之间,取决于训练集的大小。在对
X
D
o
G
XDoG
XDoG 风格进行了充分的训练之后,再对这个网络使用较低的学习率(
1
e
−
5
1e^{-5}
1e−5)进行其他风格的手绘图象的训练,来得到其他风格的模型。
对于缺失部分的补全阶段:
| parameters | value |
|---|---|
| λ \lambda λ | 0.01 |
| momentum | 0.9 |
几个要注意的地方:
- 在测试阶段,会设置一个较小的 λ \lambda λ (对于生成遮盖部分的图像是很重要的)来使得生成的图像更加贴近手绘图象
- 在反向传播时,生成器和判别器的参数不会发生变化,只是对输入的 z z z 进行更新
- 对三个数据集都是用同一个网络架构
实验结果来看,通过反向传播进行的更新大概需要 500 500 500 个 i t e r a t i o n s \bold {iterations} iterations (在100个iterations之后会开始变得稳定)。
Results
人脸数据集:
 鸟类数据集:
鸟类数据集:

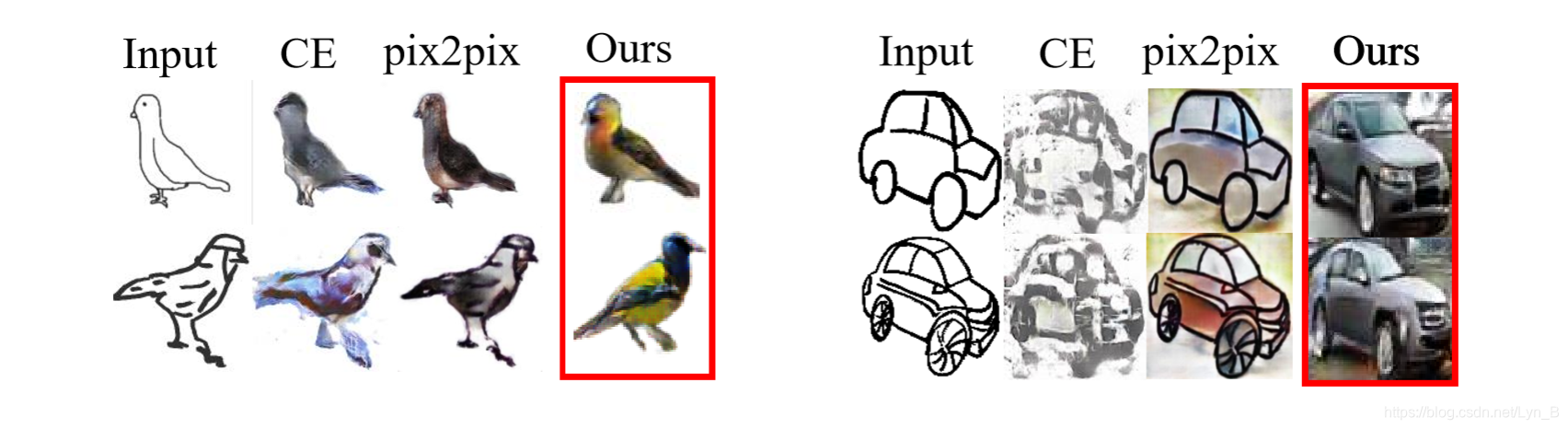
汽车数据集:
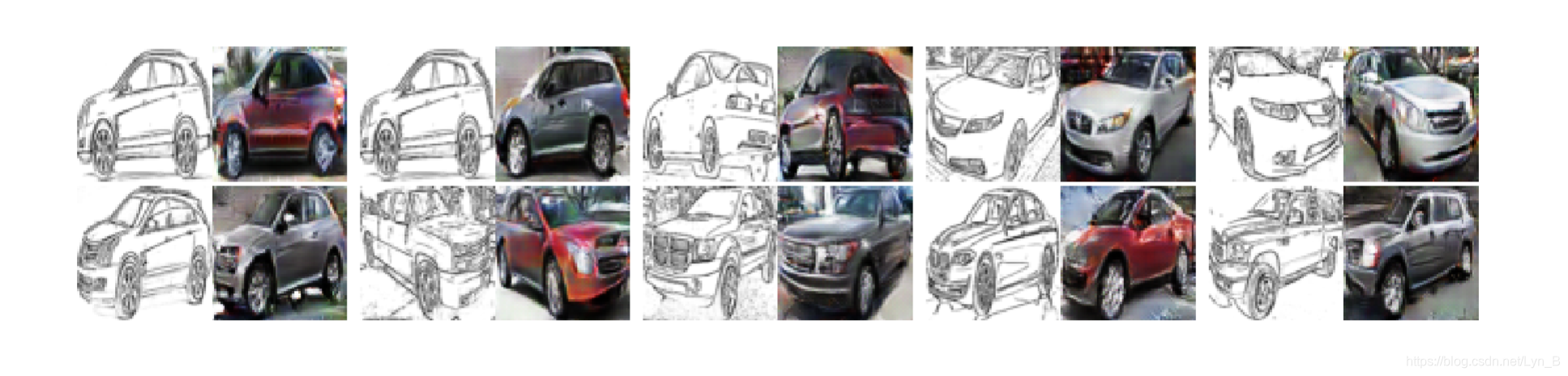 和
p
i
x
2
p
i
x
pix2pix
pix2pix,
C
E
CE
CE 在较差的输入图像上得到的效果之间的比较:
和
p
i
x
2
p
i
x
pix2pix
pix2pix,
C
E
CE
CE 在较差的输入图像上得到的效果之间的比较:
 在
S
S
I
M
\bold{SSIM}
SSIM 和
V
e
r
i
f
i
c
a
t
i
o
n
A
c
c
u
r
a
c
y
\bold{Verification\space Accuracy}
Verification Accuracy 这两个指标上的比较:
在
S
S
I
M
\bold{SSIM}
SSIM 和
V
e
r
i
f
i
c
a
t
i
o
n
A
c
c
u
r
a
c
y
\bold{Verification\space Accuracy}
Verification Accuracy 这两个指标上的比较:

- S S I M \bold{SSIM} SSIM:Structural Similarity Metric,结构相似性,描述生成图像和真实图像的相似程度
- V e r i f i c a t i o n A c c u r a c y \bold{Verification\space Accuracy} Verification Accuracy:通过一个预训练的 L i g h t C N N \bold{Light\space CNN} Light CNN对保持的特征进行提取,使用 L 2 \bold{L2} L2 范数进行比较得到的生成图像和真实图像之间在独有特征上的相似程度
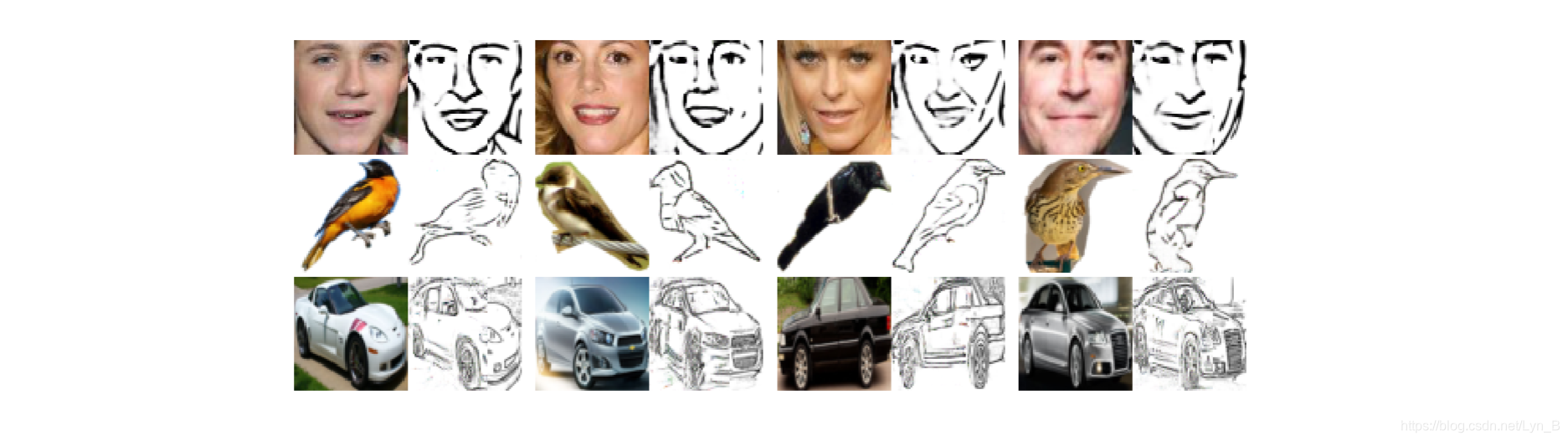
Bi-Direction Generation 双向生成
正如前文提到的,因为使用的是联合图像(joint image)这个模型既可以用于 sketch-to-image,也可以用于 image-to-sketch。在训练和测试中交换 sketch 和 image 的角色,得到了从照片到手绘图像的生成:
Limitation 局限性
对于人脸数据,当输入的手绘图象呈现出比较稀疏的视觉效果时,无法保证一些独特的特征可以被保留,例如下图
 可以看到 (a) 中缺失了眼镜,而 (b) 中缺少了胡须,虽然生成的图片从视觉上看很好的对应了输入的手绘图象。相信如果在生成过程中加入一些额外的特征约束的话可以引导出一个更好的生成结果。
可以看到 (a) 中缺失了眼镜,而 (b) 中缺少了胡须,虽然生成的图片从视觉上看很好的对应了输入的手绘图象。相信如果在生成过程中加入一些额外的特征约束的话可以引导出一个更好的生成结果。















 4074
4074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









