







一、什么是Convolution
打比方说我们有一个小车在一块木板上运动。还有一个超声波传感器对这辆小车来测距,但是这个传感器带有误差。我们在某一个特定时间点t测得的结果不一定准确。于是我们做一件事情:将几个连续、不同的时间段的测量值依据某一个权值序列,融合成一个单独的估计值。用这个估计值来代替t时刻的测量值。这就是convolution了。这里个人觉得这个等式成立:convolution = weighted average operation。数学一点用公式来表示就是:
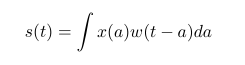
在这里x被称为input,w被称为kernel。Output被称为feature map。
二、Convolution如何和机器学习结合?
在机器学习中,我们的input是一个多维的数据array,kernel是一个多维的参数array。这些多维的array被称为tensors。然后拿kernel这个卷积核去作用我们的input,就会得到和上面相似的既视。(区别大概只有这边更多是离散的吧…)用一张比较形象的图描述如下:
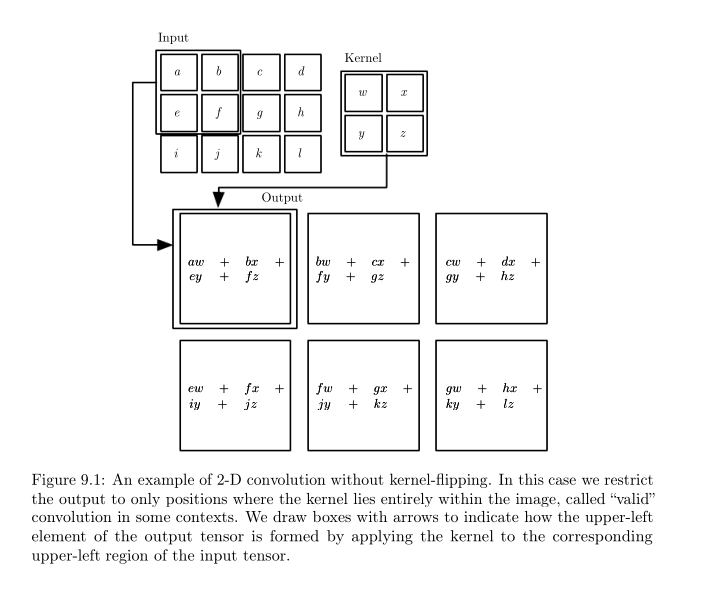
CNN典型的一层包括以下结构:
1)线性卷积
2)非线性激励(detector stage)
3)池化改进(pooling function)
三、CNN三大特色
1) sparse interactions(稀疏关联)
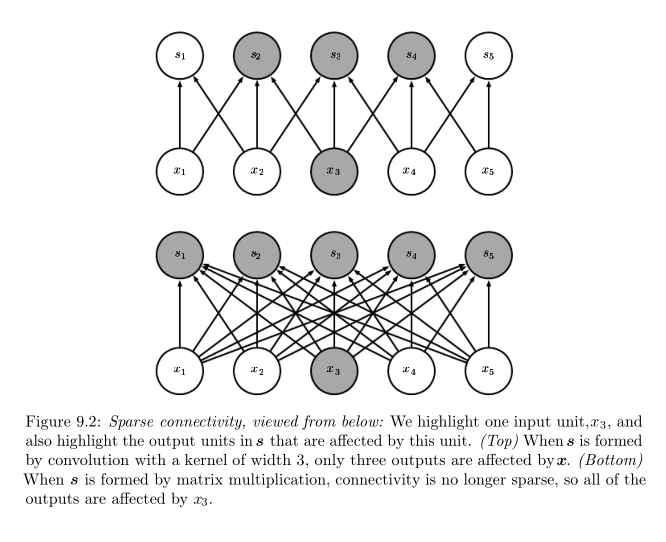
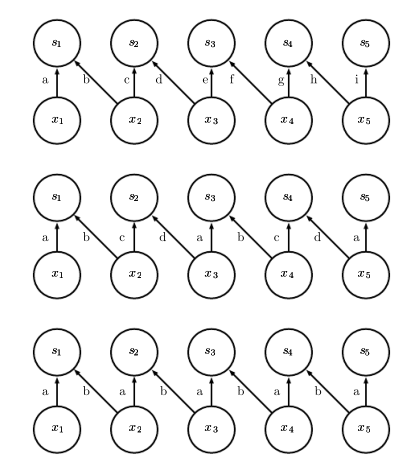
Figure 9.2的上图表示的是稀疏关联。即对于某个输入节点,它对应的输出节点的个数是给定的;对于某个输出节点,它对应的输入节点的个数也是给定的。这区别于9.2的下图:每个输出节点都与输入节点连接。
2) parameter sharing(参数共享)
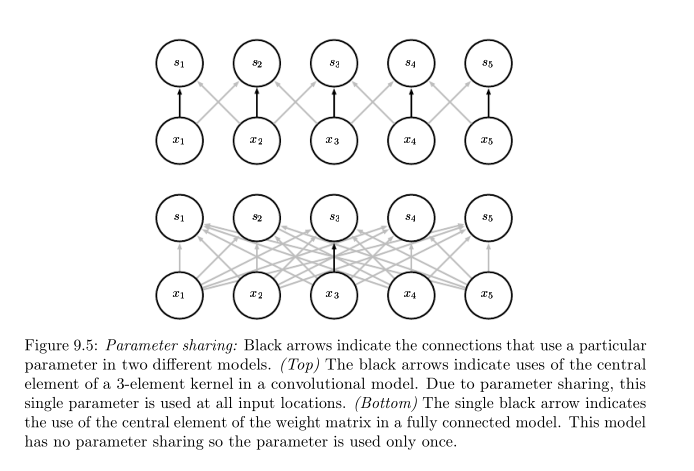
对于一般的神经网络,如Figure 9.5的下图。它的输入和输出都是全连接的,除此之外,每个连接关系对应的系数都互不相同。它们都是通过backprop的过程各自更新得到的。而对于一个CNN网络,如Figure9.5 上图,我们可以看到,同一套参数提供给了多对输入到输出的映射使用。
3) equivariant representations
简单来说这个特性就是,你先对输入做一个变换(比如平移)再做卷积的输出等于你先对输入做卷积再对它做变换的结果。
但是这块的几个Examples暂时没有看懂,待补充…
四、Pooling 池化的二三事
为什么要叫池化,从字面意思上理解,就是把一片数据扔到一个大熔池里面搅,最后搅出来一个可以体现这一片数据特征的结晶,而滤除那些数据的其它渣渣。举几个池化的手段作为例子:1)取最大值;2)取平均值;3)取L2 Norm等。池化的作用可见一斑:弱化单个数据变化对整个数据片所传达的信息的影响。换句话说就是增强一整个数据片的Invariance。这个数据片可以是同一个卷积核产生的spatial regions也可以是不同卷积核产生的区域。
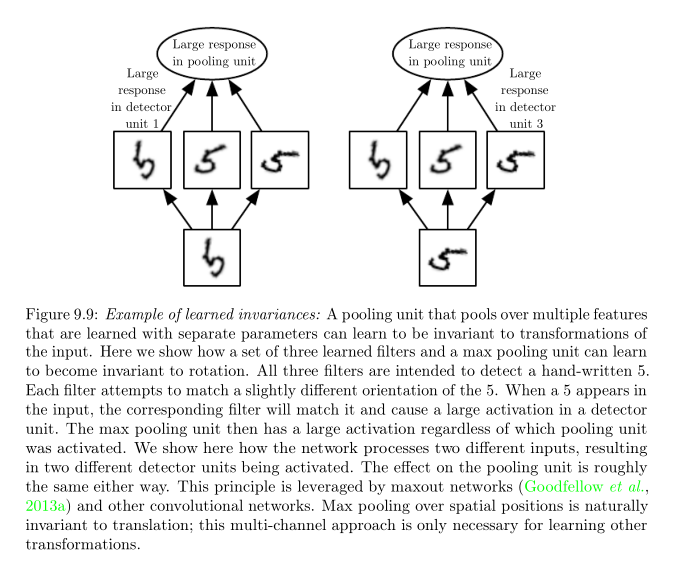
比如下面的这个例子,通过对多个卷积核取到的特征做池化,使得网络能够对抗来自旋转变换的干扰。
五、CNN变体一:zero-padding
为什么要有zero-padding?
因为没有它,每过一层神经网络,计算节点就会减少;可能的结果就是还没有达到想要到的Output,计算节点数目已经将为零了。比如对一组一维的数据做CNN,这组数据总共有100个,而卷积核大小是20,移动的步长是1;在这种情况下每做一层神经网络,节点数目就会减少20-1个。(因为你无法为第82个及其以后的节点做好相应的数据匹配)这个问题在卷积核大的时候特别严重。因此需要zero-padding来为不能结成数据对来接收卷积核处理的数据找“伴”。
zero-padding的几种处理方法:
1)valid convolution:啥都不干,看着节点数目随神经网络层数的增加减少。
2)same convolution:在边沿处补零。一般卷积核有多大就补多少个零。但是它的缺点在于会自动弱化边沿节点对最后输出结果的影响。关于这个弱化的解释,个人理解如下:如果说CNN仅仅只是一系列的线性的叠加,那应该不存在弱化一部分的说法。但是CNN是引入了非线性元素的,比如detect stage和pooling。打比方说,这个网络的activation function是sigmoid。然后我们在第一个节点的左边补几个零,这个时候即便第一个节点数值比较大,容易让sigmoid出现正的结果,但是受到补加的几个零的负面影响,真正输出的结果可能是一个接近 0的数字。
3)full convolution:还是补零,但是感觉这个方法补得更极端,保证每个原本的节点都能被访问到卷积核大小的次数。这使得一个单独的卷积核很难对所有位置的节点都有一个让人满意的作用效果。(比如比卷积核对比较中间的那些节点就遵照它们原本的特性来,但是对那些边界上的节点就要尽力减少添加的零对它们产生的抑制作用)。所以这个方法貌似不怎么使用。
4) 1)和2)的中间版:最常用,最好用。但具体怎么用,暂时不知道…
六、CNN变体二:local connections
引入local connections的原因:有些特征并非全局的特征,而只是全局中部分数据的特征。因此使用的卷积核具有某种特异性,只需要对这个特定的区域使用而没有必要将整张图片都扫一遍。比如判断一张图是否是个人脸照,只需要在图片的下部扫一个检测嘴巴的卷积核,而不用对整张图都扫这个卷积核。
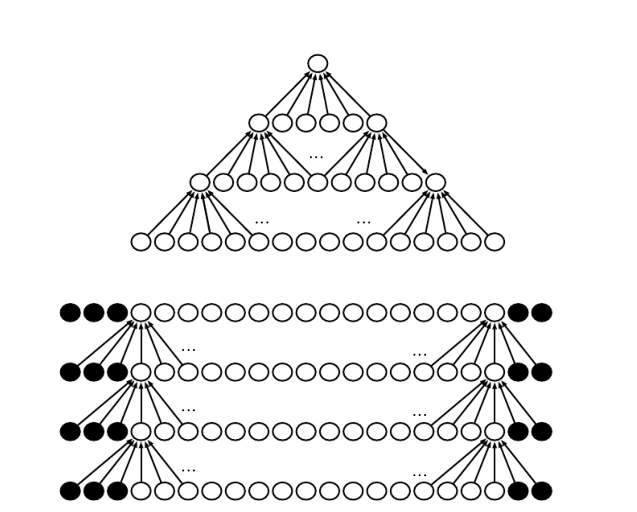
另一种变体tiled convolution则是local connected layer和convolutional layer之间的一个compromise。它们三者之间的关系可以通过下图表达:
最上是local connection,中间是tiled convolution,最下面是convolution:
七、CNN的神经网络原型
人脑有块区域叫V1,CNN就是模仿V1的工作模式来工作的:
1) V1是基于spatial map来排列的,具体来说是二维的;因此CNN也将它的特征描述为二维的;
2) V1有许多simple cells,而这些simple cells认为可以在一个小的感知域用一个线性的方程来表达它的特性;detector units就是设计出来模仿simple cells的特性的;
3) V1也有许多complex cells。这些cells对于部分特征的小变动并不敏感。 这个特性催生了池化单元。

写在最后:
把DLB里面第六章的内容咽下去嚼烂了再吐到CSDN上花了一整天的时间。DLB之于学习深度学习就像韦氏大字典之于学习英语吧。感觉嚼得我满口牙齿都松了…
另外,CNN和神经科学之间的联系个人还是觉得很有研究价值的,以后大概会专门另开一篇来学习和分享这方面的知识啦~(flag2…)















 3810
3810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









