







目录
传统的神经网络每一个输出单元与每一个输入单元都产生交互。如果有 m 个输入和 n 个输出,那么矩阵乘法需要 m × n 个参数并且相应算法的时间复杂度为 O(m × n)。一方面参数太多了,占用存储空间,影响运算速度,另一方面模型弹性太大,很容易导致overfitting,所以我们要想办法简化网络,降低模型弹性。
卷积神经网络特点
卷积运算通过三个重要的思想来帮助改进机器学习系统: 稀疏交互( sparse interactions)、 参数共享( parameter sharing)、 等变表示( equivariant representations)。
稀疏连接
人类辨识一张图片的方法就是看图片中存在的关键特征,比如鸟有鸟嘴,眼睛,锋利的爪子等等。机器可以借鉴这个思想:只需要辨识一些关键图案。所以隐藏层的神经元不需要看整个图片,每次只需一小部分作为输入,看看是否含有某种pattern。
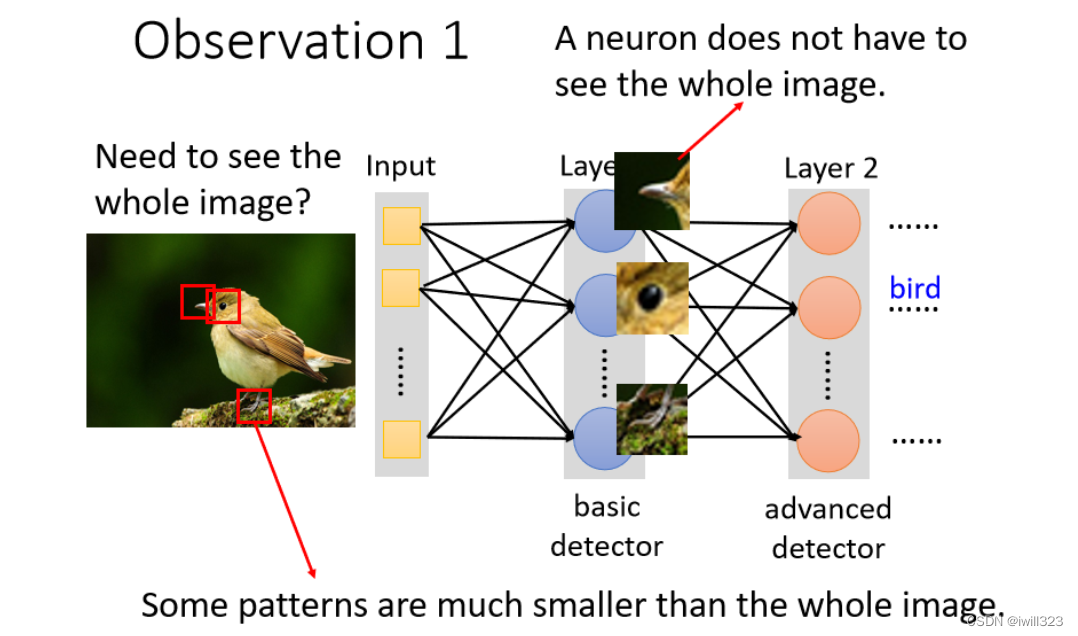
所以可以采取以下简化措施:一个神经元不用连接所有的输入向量,只连接一部分的输入,使用较少的参数来检测这部分输入是否含有目标特征。这个小部分输入就称为receptive field(感受野)。下图中的感受野是个3x3x3 的正方体,拉直后成了 27 维向量,作为神经元的输入,这样就只需要27 个weight了。 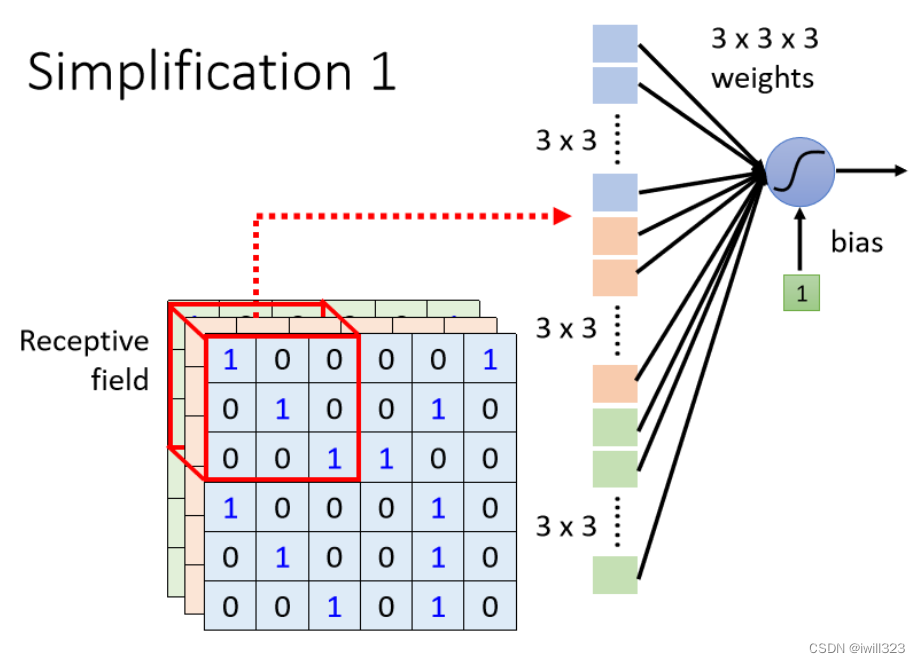
让核的大小远小于输入的大小,卷积网络具稀疏交互( sparse interactions)的特征。举个例子,当处理一张图像时,输入的图像可能包含成千上万个像素点,但是我们可以通过只占用几十到上百个像素点的核来检测一些小的有意义的特征,例如图像的边缘。在深度卷积网络中,处在网络深层的单元,感受域要比处在浅层的单元的感受域更大,这些单元可能与绝大部分输入是间接交互的。这意味着在卷积网络中尽管直接连接都是很稀疏的,但处在更深层中的单元可以间接地连接到全部或者大部分输入图像。
参数共享
相同的 pattern 会出现在不同区域,比如下图的鸟嘴,不同感受野可以共用同一个鸟嘴检测器

在传统的神经网络中,计算一层的输出时,权重矩阵的每一个元素乘以输入的一个元素后就再也不会用到了。在卷积神经网络中,不同感受野的神经元共享参数,具体而言,每一个感受野上往往有多个神经元守备,输出的feature map有多个通道,相同通道上的神经元,参数(也就是filter)相同;不同通道的神经元具有不同的filter,负责检测不同的东西。从filter的角度来说,神经元共享filter意味着用这一个filter扫过一张图片。卷积运算中的参数共享保证了我们只需要学习一个参数集合,而不是对于每一位置都需要学习一个单独的参数集合。

但在某些情况下,我们并不希望对整幅图进行参数共享。例如,在处理已经通过剪裁而使其居中的人脸图像时,我们可能想要提取不同位置上的不同特征(处理人脸上部的部分网络需要去搜寻眉毛,处理人脸下部的部分网络就需要去搜寻下巴了)。
对平移等变(池化)
将图片缩小/下采样,比如只保留偶数行和偶数列,并不会改变图片中的物体。池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出,从而减少后面层的参数,提高网络的计算效率。例如, 最大池化( max pooling)函数给出相邻矩形区域内的最大值。其他常用的池化函数包括相邻矩形区域内的平均值、 L2 范数以及基于据中心像素距离的加权平均函数。
在很多任务中, 池化对于处理不同大小的输入具有重要作用。例如我们想对不同大小的图像进行分类时,分类层的输入必须是固定的大小,而这通常通过调整池化区域的偏置大小来实现,这样分类层总是能接收到相同数量的统计特征而不管最初的输入大小。

池化实际上是假定了我们的数据对于小位移是不变的。对于平移的不变性是指当我们对输入进行少量平移时,经过池化函数后的大多数输出并不会发生改变。卷积对其他的一些变换并不是天然等变的,例如对于图像的放缩或者旋转变换,需要其他的一些机制来处理这些变换。
池化会造成精确度下降,如果机器的运算能力满足要求,也可以不做池化。
卷积与池化作为一种无限强的先验
先验概率分布( prior probability distribution):模型参数的概率分布,刻画了在我们看到数据之前我们认为什么样的模型是合理的信念。先验被认为是强或者弱取决于先验中概率密度的集中程度。弱先验具有较高的熵值,例如方差很大的高斯分布,允许数据对于参数的改变具有一定的自由性。强先验具有较低的熵值,例如方差很小的高斯分布,在决定参数最终取值时起着更加积极的作用。一个无限强的先验需要对一些参数的概率置零并且完全禁止对这些参数赋值,无论数据对于这些参数的值给出了多大的支持。
全连接网络将图像数据展平成⼀维向量⽽忽略了每个图像的空间结构信息。最优的结果是利⽤先验知识,即利⽤相近像素之间的相互关联性,从图像数据中学习得到有效的模型。可以把卷积网络类比成全连接网络,但对该全连接网络的权重有一个无限强的先验。这个先验说明了该层学得的函数应该只包含局部连接关系(稀疏权重)并且对平移具有等变性。类似的,使用池化也是一个无限强的先验:每一个单元都具有对少量平移的不变性。
把卷积神经网络想成具有无限强先验的全连接网络,可以发现卷积和池化可能导致欠拟合。与任何其他先验类似,卷积和池化只有当先验的假设合理且正确时才有用。当一项任务涉及到要对输入中相隔较远的信息进行合并时,那么卷积所利用的先验可能就不正确了;如果一项任务依赖于保存精确的空间信息,那么在所有的特征上使用池化将会增大训练误。为了获得较高不变性且当平移不变性不合理时不会导致欠拟合,一些卷积网络结构被设计成在一些通道上使用池化而在另一些通道上不使用。
卷积层的优点
假设有 m 个输入和 n 个输出。设稀疏连接限制每一个输出与输入的连接数为 k,那么只需要 k × n 个参数。参数共享进一步把模型参数降低至 k 个。因为 m 和 n 通常有着大致相同的大小, 并且 k 通常要比 m 小很多个数量级,所以 k 在实际中相对于 m × n (全连接权重参数,不过全连接网络的n和卷积网络的n可能差很多)是很小的。因此,卷积在存储需求和统计效率方面极大地优于稠密矩阵的乘法运算。

全连接层弹性大,能适用于很多任务,但是却做不好,多而不精。卷积层基于稀疏连接(很多权重设成 0)和参数共享(某一些神经元的权重要一模一样),专门为图像设计,网络弹性变小,有更大的model bias,但是不容易overfitting,在图片辨识中的效果很好。
卷积核常用的设定
- kernel size: 指感受野的宽和高大小。感受野的 depth 不需设定,它会覆盖图像所有的channel。
- stride: 指每次感受野移动多少像素点。 一般 stride < kernel size,因为要让相邻感受野有重叠 (overlap),防止有pattern在边缘交界处检测不到
- out channels:同一个感受野可以由多个神经元守备
- padding: 为了充分识别到边缘的 pattern,在边缘外补值(比如 0)。
基本卷积函数的变体
strided convolution:在输出的每个方向上每间隔 s 个像素进行采样
填充 (pad):有效( valid)卷积(不使用零填充)、相同( same)卷积(进行足够的零填充来保持输出和输入具有相同的大小)、全( full)卷积(足够多的零填充使得每个像素在每个方向上恰好被访问了 k 次,最终输出图像的宽度为 m + k - 1)
局部连接:多层感知机对应的邻接矩阵是相同的,但每一个连接都有它自己的权重,用一个 6 维的张量 W 来表示。 W 的索引分别是:输出的通道 i,输出的行 j 和列 k,输入的通道 l,输入的行偏置 m 和列偏置 n。有时也被称为非共享卷积( unshared convolution)。当我们知道每一个特征都是一小块空间的函数并且相同的特征不会出现在所有的空间上时,局部连接层是很有用的。例如,如果想要辨别一张图片是否是人脸图像时,只需要去寻找嘴是否在图像下半部分即可。
平铺卷积( tiled convolution):学习一组核使得当我们在空间移动时它们可以循环利用。这意味着在近邻的位置上拥有不同的过滤器,就像局部连接层一样,但是对于这些参数的存储需求仅仅
是核的集合的大小,而不是整个输出的特征映射的大小。
局部连接层、 平铺卷积和标准卷积的比较:
当使用相同大小的核时,这三种方法在单元之间具有相同的连接。局部连接每条边用唯一的字母标记,来显示每条边都有自身的权重参数。
平铺卷积有 t 个不同的核。这里我们说明 t = 2 的情况。与局部连接层类似,输出中的相邻单元具有不同的参数。与局部连接层不同的是,在我们遍历所有可用的 t 个核之后,我们循环回到了第一个核。如果两个输出单元间隔 t 个步长的倍数,则它们共享参数。
正如用于标记每条边的字母重复出现所指示的,卷积层在整个输入上重复使用相同的两个权重。

一般来说,在卷积层从输入到输出的变换中我们不仅仅只用线性运算。我们一般也会在进行非线性运算前,对每个输出加入一些偏置项。这样就产生了如何在偏置项中共享参数的问题。对于卷积层来说,通常的做法是在输出的每一个通道上都设置一个偏置,这个偏置在每个卷积映射的所有位置上共享。对于局部连接层,很自然地对每个单元都给定它特有的偏置,然而,如果输入是已知的固定大小,也可以在输出映射的每个位置学习一个单独的偏置。分离这些偏置可能会稍稍降低模型的统计效率,但同时也允许模型来校正图像中不同位置的统计差异。例如,当使用隐含的零填充时,图像边缘的探测单元接收到较少的输入,因此需要较大的偏置。
结构化输出
卷积神经网络可以用于输出高维的结构化对象,而不仅仅是预测分类任务的类标签或回归任务的实数值。通常这个对象只是一个张量,由标准卷积层产生。例如,模型可以产生张量 S,其中 Sijk 是网络的输入像素 (j, k) 属于类 i 的概率。这允许模型标记图像中的每个像素,并绘制沿着单个对象轮廓的精确掩模。
一旦对每个像素都进行了预测,我们就可以使用各种方法来进一步处理这些预测,以便获得图像在区域上的分割。语义分割可能是一个例子
数据类型
卷积网络的一个优点是它们还可以处理具有可变的空间尺度的输入。这些类型的输入不能用传统的基于矩阵乘法的神经网络来表示。例如,考虑一组图像的集合,其中每个图像具有不同的高度和宽度。卷积就可以很直接地应用;核依据输入的大小简单地被使用不同次,并且卷积运算的输出也相应地放缩。有时,网络的输出允许和输入一样具有可变的大小,例如如果我们想要为输入的每个像素分配一个类标签。在这种情况下,不需要进一步的设计工作。在其他情况下,网络必须产生一些固定大小的输出,例如,如果我们想要为整个图像指定单个类标签。在这种情况下,我们必须进行一些额外的设计步骤,例如插入一个池化层, 池化区域的大小要与输入的大小成比例,以便保持固定数量的池化输出。















 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









