







程序背景
将大规模数据数据存储到SQL数据库,如面临上万、十万、百万条数据存储,如果按照一般思路一条条存,必然会耗费大量时间,使得效率低下,本文利用java实现对数据的批量存储。
数据输入
本文示例数据结构如下,其中每一行代表一个车型的竞争关系,其中第一个数字为这款车型(如:车型82),后面所跟数子表示与该车型有竞争关系的其他车型,竞争关系按照从前到后递减(如车型82的竞争车型为:871、18、65、496等十款)。

任务是将这些车型的竞争关系存入SQL数据库,数据库中数据表结构如下:
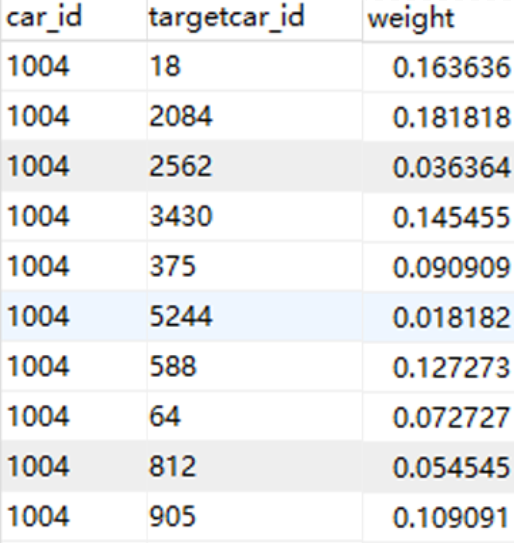
其中,car_id为前文文本数据中第一列所示,targetcar_id为后面有竞争关系的车型,weight是将排序标准化的结果,表示竞争强弱。本例中需要存储的数据条数已经上万,所需采用批量存储的方式,具体实现如下。
程序代码
package JDBC;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.sql.*;
public class DataSavceBatch {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement prepstmt = null;
final String DB_DRIVER = "com.mysql.jdbc.Driver";
final String DB_URL = "jdbc:mysql://114.213.252.89:3306/liangruicheng";
final String DB_USER = "root";
final String DB_PASSWORD = "112233";
File result = new File("data"+File.separator+"carCompetitor.txt");
String resultLine;
String[] resultSplitLine;
String car_id;
String targetcar_id = null;
double targetcar_weight = 0;
int batchSize = 0; //批处理的数量计数
try {
BufferedReader bfr = new BufferedReader( new InputStreamReader( new FileInputStream(result),"UTF-8")); //读取本地文件
//加载驱动类
Class.forName(DB_DRIVER);
//建立连接
conn = DriverManager.getConnection(DB_URL,DB_USER,DB_PASSWORD);
//关闭事务提交,这一行必须加上
conn.setAutoCommit(false);
while((resultLine = bfr.readLine()) != null) {
int count = 0;
resultSplitLine = resultLine.split("\\s+");
for(int i = 1;i<resultSplitLine.length;i++) {
count += i;
}
car_id = resultSplitLine[0];
for(int i = 1; i<resultSplitLine.length;i++) {
batchSize ++;
targetcar_id = resultSplitLine[i];
//根据排序,将权重标准化处理
targetcar_weight = (double)(resultSplitLine.length - i)/count;
//接下来批量存储数据
if(batchSize%5000 != 0) { //计数是否到达5000,不到5000先放入PreparedStatement中
prepstmt.setString(1,car_id);
prepstmt.setString(2,targetcar_id);
prepstmt.setDouble(3,targetcar_weight);
prepstmt.addBatch();
}else { //到达5000后,执行操作将数批量存入数据库
//进行事务提交
prepstmt.executeBatch();
conn.commit();
//初始化batchSize计数
batchSize = 0;
}
}
//此处较为重要,最后需要再执行一次,将不满5000条的结果提交上去,否则将漏存数据
prepstmt.executeBatch();
conn.commit();
}
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
} catch (SQLException e2) {
e2.printStackTrace();
} catch (IOException e3) {
e3.printStackTrace();
}finally {
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
上面的代码中,通过PreparedStatement实现对数据的批量存储,能过大大减少数据存储的时间,提高效率。















 1081
1081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









