









文章目录
distinct源码
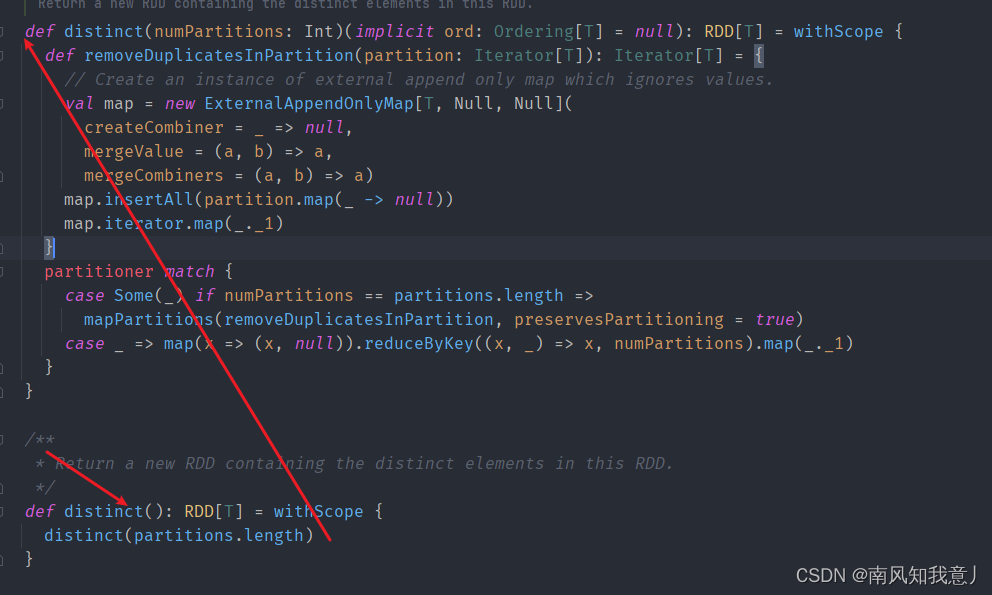
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
def removeDuplicatesInPartition(partition: Iterator[T]): Iterator[T] = {
// Create an instance of external append only map which ignores values.
val map = new ExternalAppendOnlyMap[T, Null, Null](
createCombiner = _ => null,
mergeValue = (a, b) => a,
mergeCombiners = (a, b) => a)
map.insertAll(partition.map(_ -> null))
map.iterator.map(_._1)
}
partitioner match {
case Some(_) if numPartitions == partitions.length =>
mapPartitions(removeDuplicatesInPartition, preservesPartitioning = true)
case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
}
}
主要代码:
case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
示例
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkDistinct")
val sc: SparkContext = new SparkContext(conf)
//定义一个数组
val array: Array[Int] = Array(1,1,1,2,2,3,3,4)
//把数组转为RDD算子,后面的数字2代表分区,也可以指定3,4....个分区,也可以不指定。
val line: RDD[Int] = sc.parallelize(array,2)
line.distinct().foreach(x => println(x))
println("等价写法:")
line.map((_,null)).reduceByKey((x,y)=>x).map(_._1).foreach(println)
}
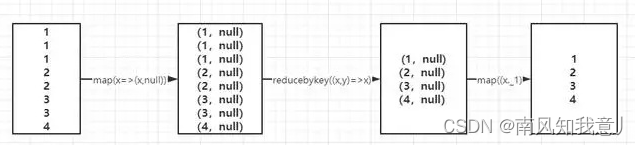
看到这应该明了,类似于wordcount的写法:map算子把元素转为一个带有null的元组;使用reducebykey对具有相同key的元素进行统计;之后再使用map算子,取得元组中的单词元素,实现去重的效果。
参考:
引申个问题,reduceBykey完成的groupBykey也能完成,但是为什么distinct源码为什么不用groupbyKey算子呢???
reducebyKey参考我的另一篇文章:
https://blog.csdn.net/Lzx116/article/details/124918622














 2387
2387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









