






基本情况
作者只学习了python基本语法,之前没有接触过大模型的微调。本文将从anaconda的虚拟环境搭建开始。
软硬件配置:
OS:Windows11
CPU:Intel i7
GPU:NVIDIA GeForce RTX 4060 Laptop GPU 8.0 GB
目录
一 .Anaconda环境配置
1.Anaconda的下载
这里主要参考的是[大模型]Qwen2.5-1.5B微调流程(自用笔记)_用qwen2.5-1.5b微调模型-CSDN博客
2.Anaconda常用命令
遇到不太熟悉的指令可以直接在网上进行查找,方便好用,主要参考这篇文档:Anaconda conda常用命令:从入门到精通_conda list-CSDN博客
# 创建虚拟环境 ,python =后面输入你想要运行的python版本
conda create -n your_env_name python =3.11
#显示目前所拥有的所有虚拟环境
conda env list
#进入虚拟环境
conda activate your_env_name
#退出虚拟环境
conda deactivate
#删除虚拟环境
conda remove --name env_name --all
#删除虚拟环境中的指定包
conda remove --name env_name package_name
#查找包
conda list3.下载pytorch
作者第一次下载pytorch的时候,遇到了一些版本更新的问题。PyTorch官方在2024年底发布公告,宣布由于维护成本过高,将不再支持Conda包。这意味着用户不能再通过Conda安装PyTorch,而需要使用pip来安装。
首先,激活虚拟环境,安装pip
conda install pip
安装好后,可以通过conda list进行查看 会显示pip包以及它的版本就可以了。
会显示pip包以及它的版本就可以了。
然后,进入pytorch官网(不需要魔法上网):https://pytorch.org/
官网会自动检测计算机的软硬件条件,选择合适的下载版本。 复制最后一条的安装命令,并在Anaconda Prompt中进行运行。pytorch会自动进行安装。需要注意的是pytorch版本一定要跟cuda版本进行匹配,至少cuda版本要大于pytorch版本。目前使用cuda11.8的版本比较保险。因为一些模型所需要的包还不能支持cuda12.x的版本,需要重新编译非常麻烦。所以安全起见,请安装cuda11.8的版本,支持性也是最高的。
复制最后一条的安装命令,并在Anaconda Prompt中进行运行。pytorch会自动进行安装。需要注意的是pytorch版本一定要跟cuda版本进行匹配,至少cuda版本要大于pytorch版本。目前使用cuda11.8的版本比较保险。因为一些模型所需要的包还不能支持cuda12.x的版本,需要重新编译非常麻烦。所以安全起见,请安装cuda11.8的版本,支持性也是最高的。
pytroch下载成功后,进行验证
python #进入python编辑
import torch #导入pytorch
# 检查 PyTorch 版本
print(torch.__version__)
# 查看 CUDA 版本
print(torch.version.cuda)
# 检查 CUDA 是否可用
print(torch.cuda.is_available())# 返回True表示CUDA可用
#检查CUDNN是否可用
print(torch.backends.cudnn.version()) # 返回CUDNN版本号,例如8200
from torch.backends import cudnn
print(cudnn.is_available()) # 返回True表示CUDNN可用
4.cuda和cudnn的下载
首先,检查自己的硬件规格。可以在cmd中输入命令:
nvidia-smi 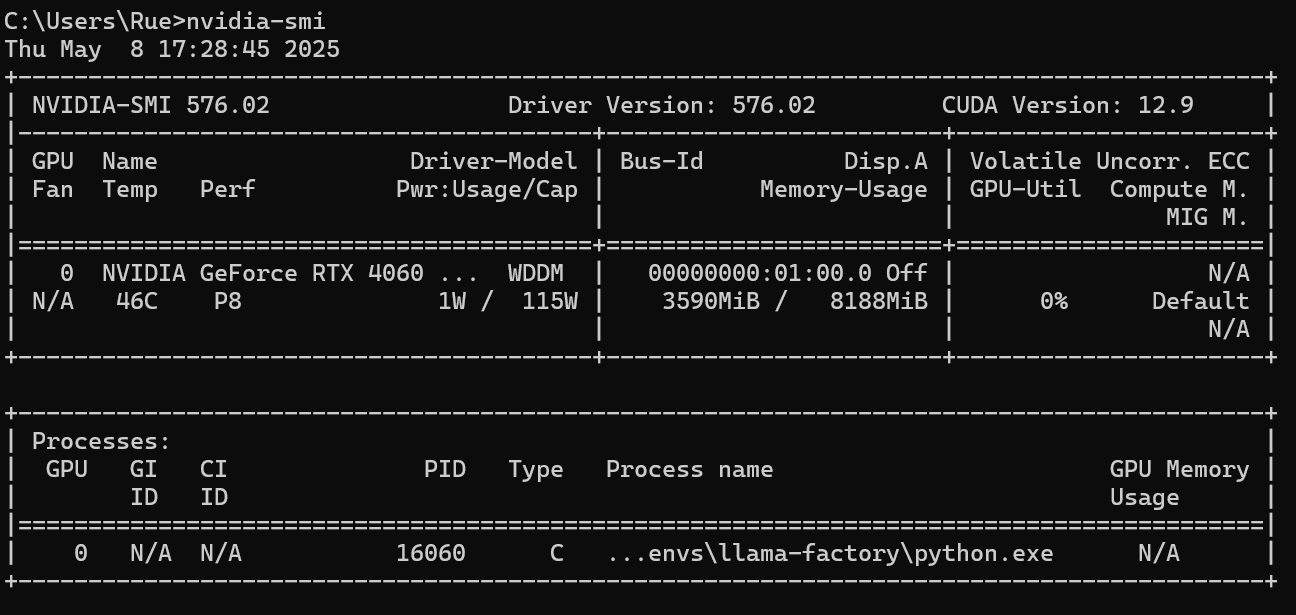 其中CUDA Version表示本机最高支持的cuda版本。
其中CUDA Version表示本机最高支持的cuda版本。
进入NVIDIA官网下载cuda和cudnn:
CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA 开发者
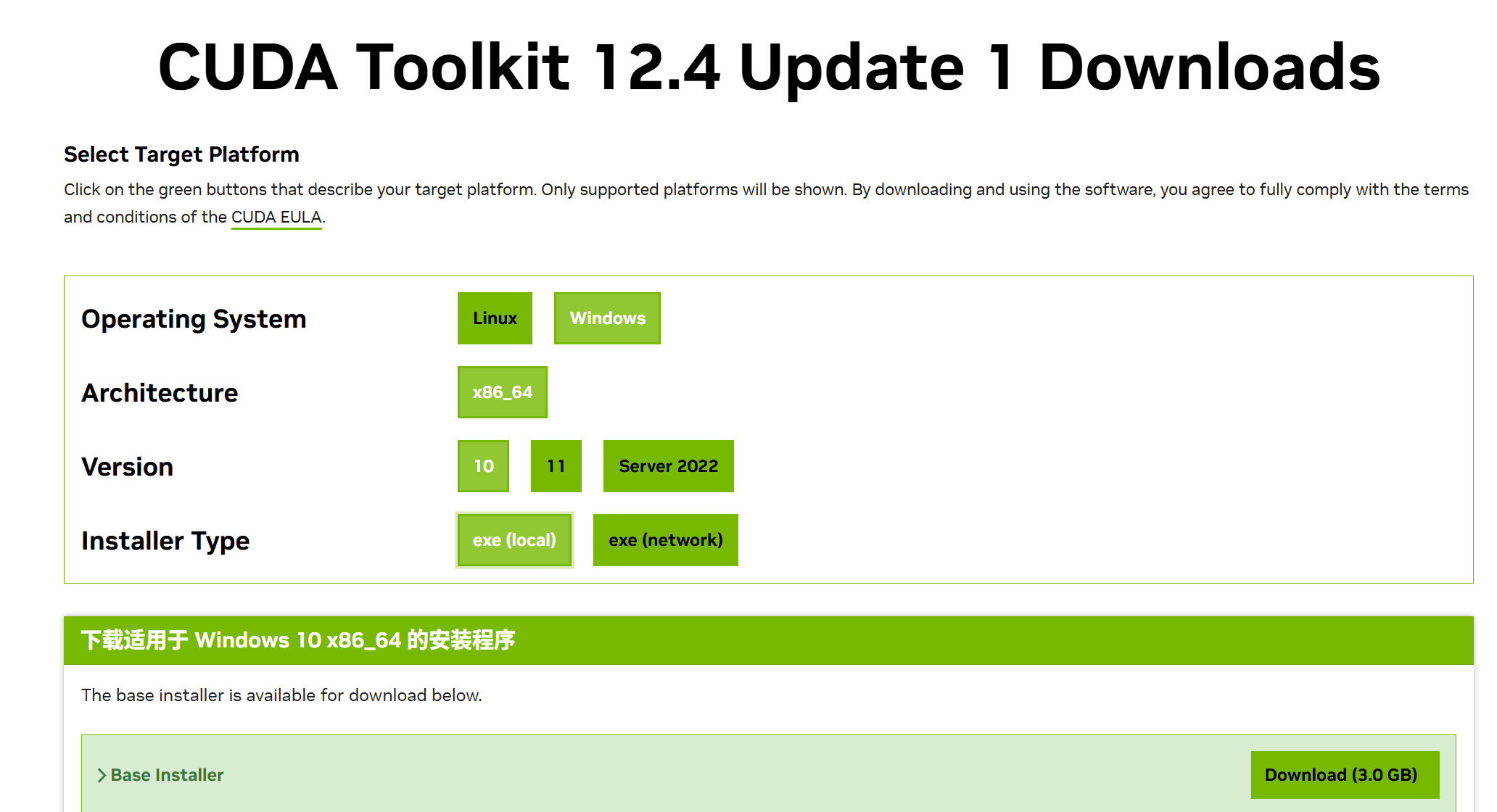
需要注意的是cuda版本和pytorch版本一定要对应。因此,需要下载cuda的旧版本,进入官网:CUDA Toolkit Archive | NVIDIA Developer,选择对应的版本(如本文档所用的cuda11.8.0版本)
cudnn的下载比较顺利,直接在官网下载最新的版本就可以了:CUDA Toolkit Archive | NVIDIA Developer
至此,基本环境的搭配已经完成。
二.下载模型与平台
1.安装LLaMa-Factory
参考的是这篇文档:[大模型]Qwen2.5-1.5B微调流程(自用笔记)_用qwen2.5-1.5b微调模型-CSDN博客
以及官方的文档:hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
为了保持格式的整洁,可以在虚拟环境中新建一个文件夹用来存放本次安装的模型,平台及其他数。将llama-factory克隆到本地,并安装依赖包。
cd LLaMA-Factory #进入文件夹
pip install -e ".[torch,metrics]"
安装完成后,进行验证,显示如图:
llamafactory-cli version

【划重点】BitsAndBytes包的cuda版本限制
一定要仔细阅读官方文档,对于Windows系统并且使用LoRa进行微调的用户,特别需要注意BitsAndBytes这个包。截至目前(2025年5月),它仅仅支持cuda11.1到12.2的版本,并且需要与之前安装的pytorch和cuda版本相匹配。再次推荐安装cuda11.8版本。
如果使用其他版本的cuda,需要通过WSL(Windows System Linux)进行编译,或者是下载一些用户编译好的wheel文件,都不太稳定和安全,不建议使用。

使用这条命令安装包
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl至此,llama-factory安装完成。
2.下载模型
推荐使用modelscope进行下载。
首先是下载modelscope:
pip install modelscope
安装完成后,在魔塔社区搜索模型,并克隆到本地文件夹内。
安装完成后,则可以进行模型的训练。
三.数据集的准备
可以在魔塔社区中下载数据集,本篇文档使用的是GSM8K中文数据集:GSM8k中文数据集 · 数据集
数据集的下载路径应为:llama-factory/data
1.数据集格式调整
根据LLaMa-Factory的官方文档,对于数据集的格式进行调整
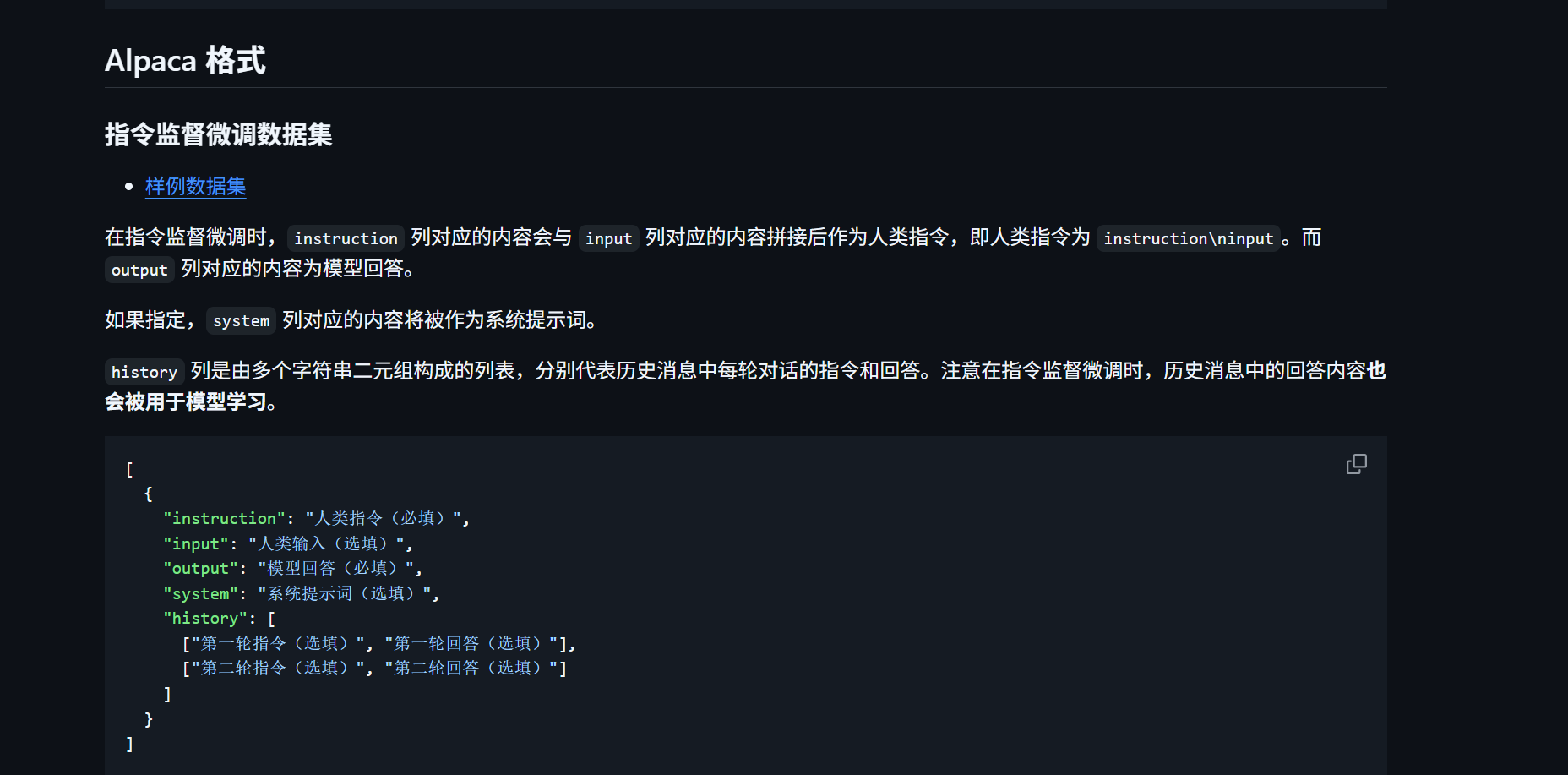
下载好了数据集,可以打开看看,发现原格式如下,并不符合官方的要求。
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer_only": "72",
"answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72",
"question_zh": "Natalia在四月份向她的48个朋友出售了夹子,然后在五月份卖出了四月份的一半。Natalia在四月和五月总共卖了多少个夹子?",
"answer_zh": "Natalia在五月份卖出了48/2 = 24个夹子。\nNatalia在四月和五月总共卖出了48+24 = 72个夹子。",
"split": "train"
},可以编写一个转换数据格式的脚本,代码如下:
import json
with open("GSM8K_zh.json", "r", encoding="utf-8") as f:
data = json.load(f)
with open("gsm8k_zh_alpaca.jsonl", "w", encoding="utf-8") as out_file:
for item in data:
new_item = {
"instruction": "请回答下列数学题",
"input": item["question_zh"],
"output": item["answer_zh"]
}
out_file.write(json.dumps(new_item, ensure_ascii=False) + ,"\n")
运行结束后,该脚本会自动生成一个jsonl文件,这就是我们调整好的数据格式。
2.数据集的注册
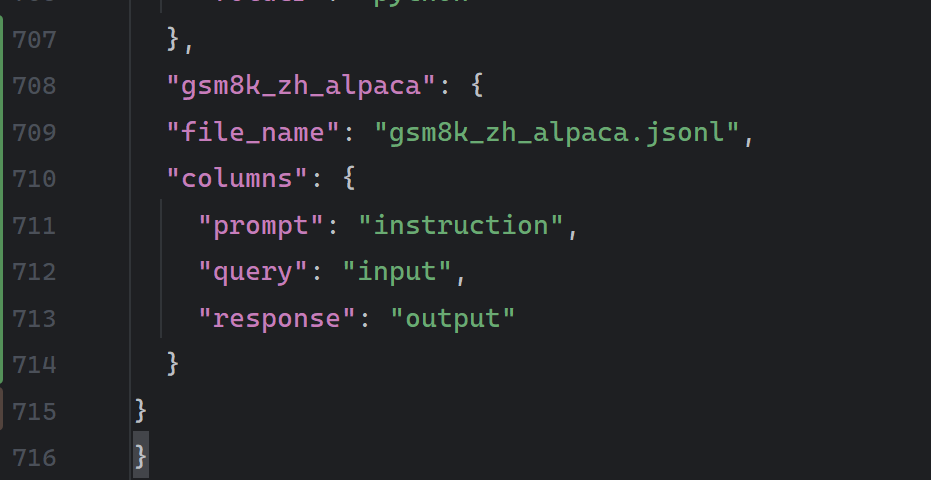
数据集编写好后,需要在dataset_info.json(同样是在data文件夹下)对数据集进行注册。
官方的要求: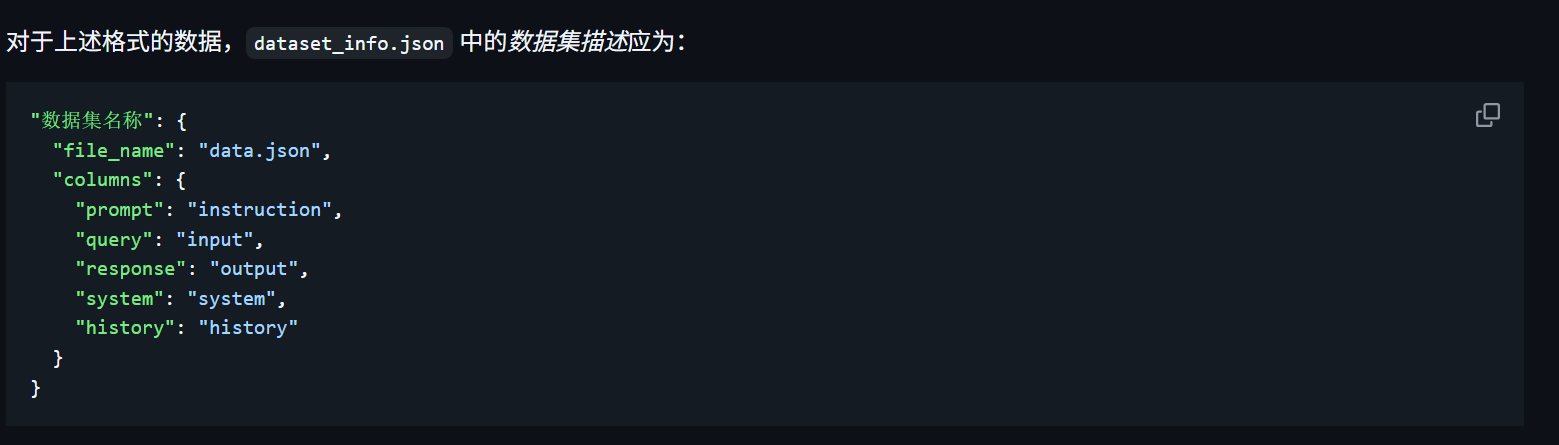
手动注册,注意要在上一个数据格式后加上","
至此,数据集的准备工作结束
四. 模型的训练
1.yaml训练文件的编写
首先,在config文件夹中新建一个以.yaml结尾的文件。如果找不到config文件,可以在llama-factory的可视化页面自动生成一个训练配置文件,此时再回到llama-factory文件下就可以找到config文件。将训练相关的参数放进去。参考的是这篇文档:LLM基础学习03:Qwen2.5-1.5B-Instruct指令微调全流程实践——LLaMA Factory框架与GSM8K评估_qwen2.5 1.5b微调-CSDN博客
注意将存放模型的地址改成自己的路径,并且注释掉这一行。

Tips:config文件夹存放训练参数文件
saves文件夹存放训练结果,分别对应可视化页面的这两个选项。

2.可视化训练
使用这条命令打开llama-factory
llamafactory-cli webui可视化参考:2.实际操作_哔哩哔哩_bilibili
需要注意的是以下几个部分,如果无法选择数据集,那么就是数据集格式或注册信息有误,请仔细检查。


优雅地退出WebUI页面:Ctrl+C
3.合并模型
3.1.背景介绍
合并模型权重,通常指将多个预训练模型或同一模型在不同阶段/不同任务上训练得到的参数(weights)进行融合,得到一个新的、具有综合能力的模型。
模型推理(Inference)指的是在训练完成后,将新输入(如图像、文本、音频等)通过已训练好的模型进行前向计算,得到输出(如分类结果、生成文本、预测数值)的过程。
# 给宝宝的大模型微调课
简单来说,大模型就是一把万能瑞士军刀,它的功能齐全但并不专精,因此需要微调(Fine-tuning)给这把刀装上专门的附件。
微调往往只改变了原模型的一部分“参数”。直接部署时,你既要加载原模型,又要加载这些“新增参数”,就像同时背着一把“万能大刀”和一堆“专用附件”,很笨重。因此需要对合并的方式进行调整。
合并模型权重就是把“主刀”(原模型权重)和“附件”(微调得到的增量权重)按一定规则黏在一起,变成一把真正集成了专用功能的“大刀”。技术上常用 LoRA(低秩适配)或者简单的“加权相加”来把两个权重矩阵合成一个。
模型推理则用这把“专用大刀”去实际处理用户输入,完成预测或生成。
3.2实际操作
首先找到LoRA adapter对应的文件夹。本地 LoRA adapter 就是你在微调时指定的 --output_dir(或 llama-factory 默认的 saves 目录)下那个存放增量权重和配置文件的文件夹。名字可能叫 lora、adapter_model 或者直接是你在训练时通过参数 --adapter_name_or_path 指定的名字。
进入这个文件夹,确认里面有两个核心文件:
adapter_config.json(LoRA 的配置)
pytorch_model.bin(或类似名的增量权重文件,如adapter_model.safetensors)
输入以下命令,llama-factory 会在该目录下自动读到你的 LoRA 权重和配置,完成与基模型的合并:
REM 指定使用哪块 GPU
set CUDA_VISIBLE_DEVICES=0
llamafactory-cli export ^
--model_name_or_path "your_original_model" ^# 原始模型
--adapter_name_or_path "your_adapter_name_or_path" ^# LoRA调整权重
--finetuning_type lora ^
--export_dir "your_export_dir" ^# 合并后的模型路径
--export_size 2 ^
--template qwen ^
--export_legacy_format False
也可以使用一行写完,更加便于计算机识别(注意template一定是qwen
set CUDA_VISIBLE_DEVICES=0 && ^
llamafactory-cli export --model_name_or_path "your_model_name_or_path" --adapter_name_or_path "your_adapter_name_or_path" --finetuning_type lora --export_dir "your_export_dir" --export_size 2 --template qwen --export_legacy_format False
4.模型的推理
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1) 路径请使用原始字符串 (r"...") 或正斜杠 "/",避免转义问题
model_path = rr"your_model_path" # 合并后的模型
tokenizer_path = r"your_tokenizer_path"# 原始模型
# 2) 选择设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# 3) 加载模型(会自动分配到 GPU/CPU)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto"
)
# 4) 加载分词器
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
# 5) 构造对话
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke about cats."}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 6) 编码并移动到设备
inputs = tokenizer(text, return_tensors="pt").to(device)
# 7) 生成
outputs = model.generate(
inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
)
# 8) 去掉 prompt,只保留新生成部分
generated = outputs[0][inputs.input_ids.shape[-1]:]
# 9) 解码并打印
response = tokenizer.decode(generated, skip_special_tokens=True)
print(response)
结束语
以上是Qwen2.5-1.5B模型在LLaMa-Factory上进行可视化微调的流程,其他调参内容请见下一篇文档。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









