






一.chatglm简介
chatglm是清华大学知识工程和数据挖掘小组发布的一个开源的对话机器人,本次开源的版本具有60亿参数,且对中文做出了专门的优化。本文尝试在Windows上对其部署与测试,并记录部署过程与部署中所遇到的各种困扰。
二.机器配置
部署的机器配置为RTX3090+RTX2070,在项目部署时选择部署至RTX3090上;
32G内存,处理器为i5-9400F。
三.部署过程
3.1 下载模型
3.1.1 代码下载
模型配置的第一步是下载代码,下载地址如下。GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型![]() https://github.com/THUDM/ChatGLM-6B
https://github.com/THUDM/ChatGLM-6B
打包下载并解压即可。
3.1.2 模型下载
下载代码后,第二步是下载与代码匹配的模型。下载模型的目的是为了使transformers自动加载本地模型。模型可以自由选择,目前ChatGLM-6B有3个版本可以使用,没有量化的版本做推理需要13G的GPU显存,INT8量化需要8GB的显存,而INT4量化的版本需要6GB的显存。可以根据自身配置选取合适的模型,如本文基于chatglm2-6b。
本文的模型下载地址如下。
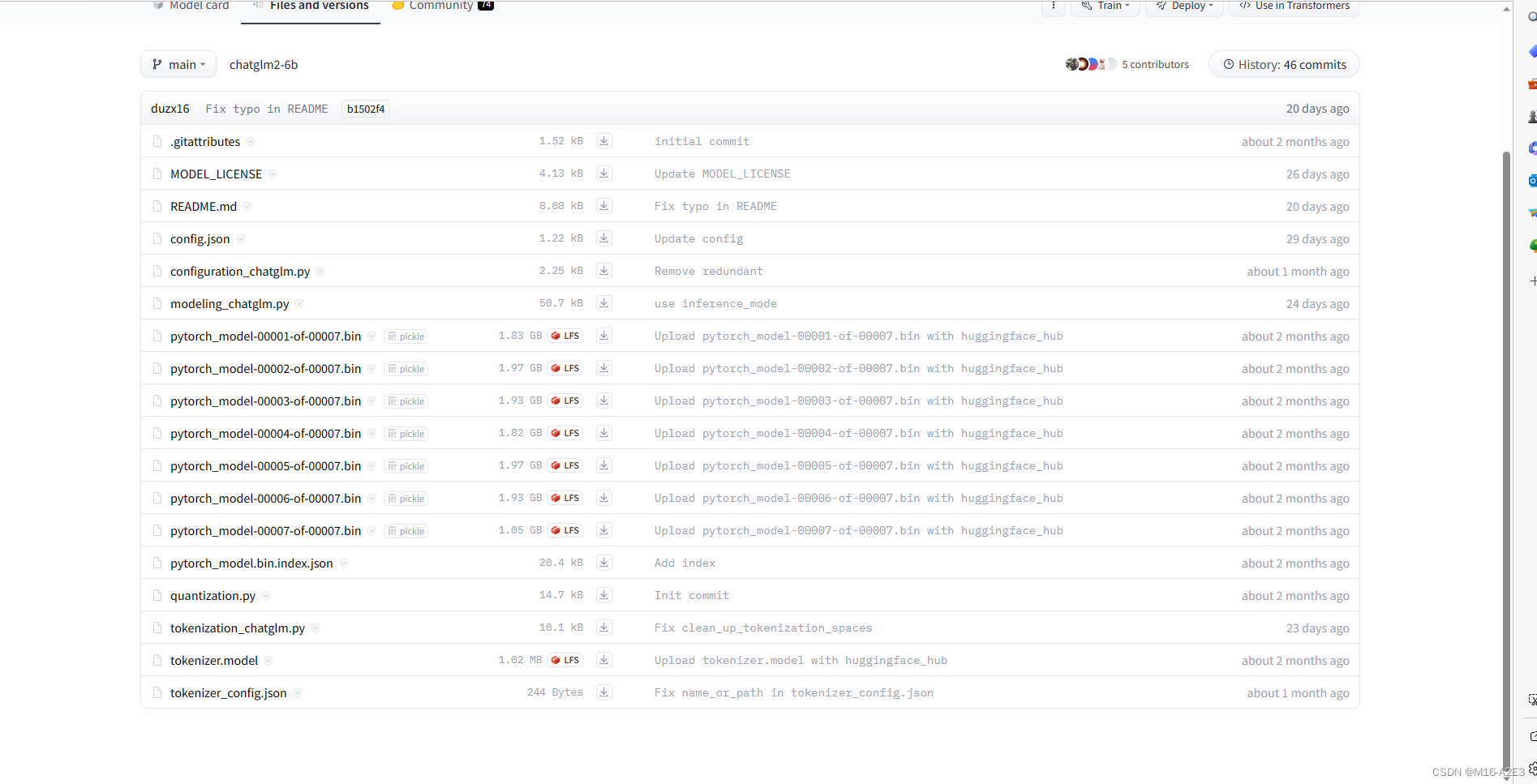
THUDM/chatglm2-6b at main (huggingface.co)![]() https://huggingface.co/THUDM/chatglm2-6b/tree/main 此链接包含如下部分,依次点击下载并放入一个文件夹内。
https://huggingface.co/THUDM/chatglm2-6b/tree/main 此链接包含如下部分,依次点击下载并放入一个文件夹内。
其他模型的下载地址如下。
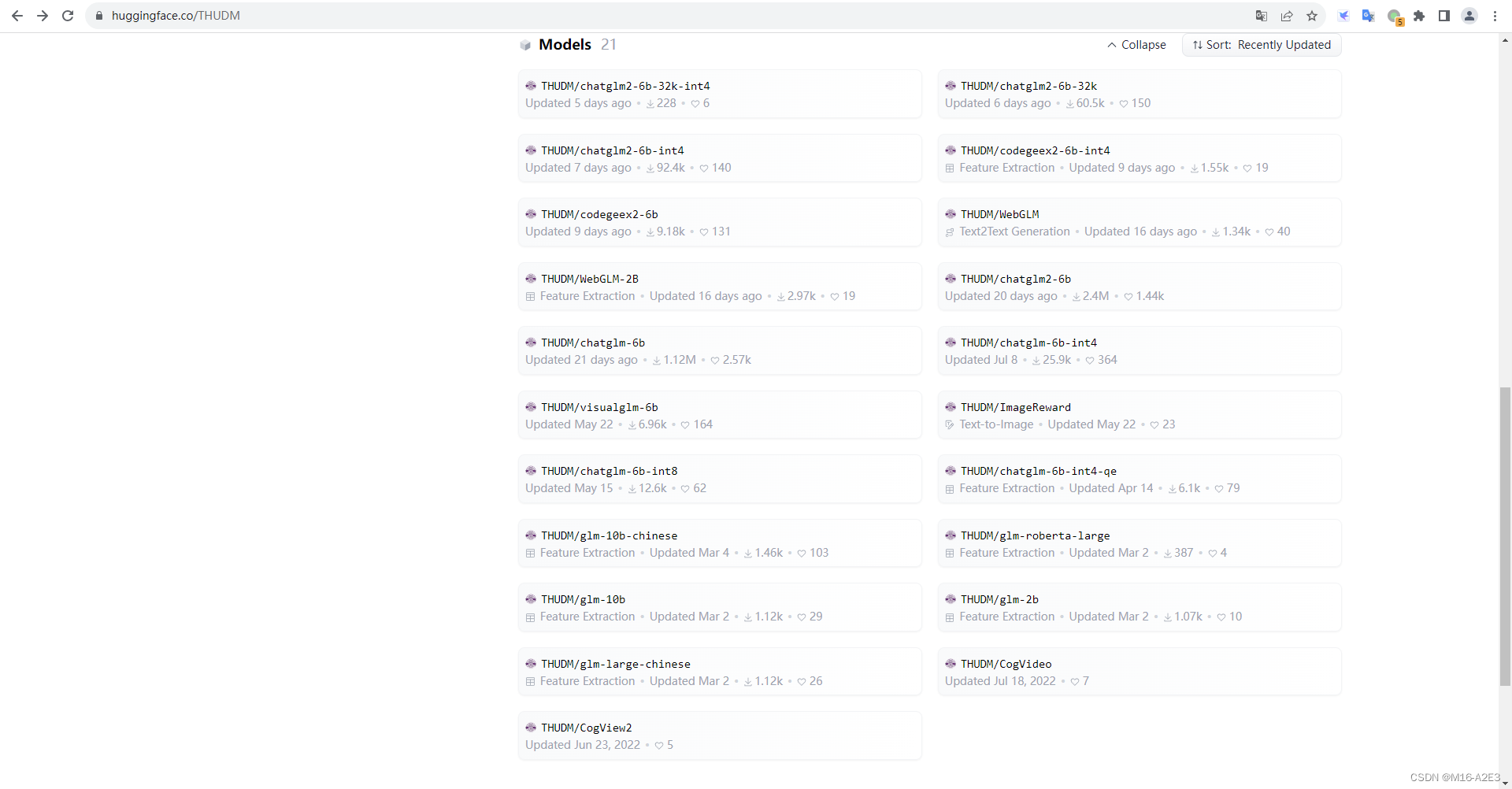
THUDM (Data Mining Research Group at Tsinghua University)Org profile for Data Mining Research Group at Tsinghua University on Hugging Face, the AI community building the future.![]() https://huggingface.co/THUDM 找到网站的models模块,可以下载其他模型。不同模型的文件不可通用。
https://huggingface.co/THUDM 找到网站的models模块,可以下载其他模型。不同模型的文件不可通用。
此后,打开3.1.1中下载的代码,新建chatglm-6b文件夹,将下载的模型整个放入此文件夹内。下载模型以后,需要修改3.1.1中的代码,以保证transformers从本地加载路径。打开文件web_demo.py,寻找如下代码。
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()将其中的form_pretrained()中的路径修改为本地路径(即下载的模型的路径);此次需要注意的是,在Windows中,若要修改为本地路径,路径中不应使用"/"号,而应使用"\\"号。若坚持使用"/"号,会报如下错误。
OSError: [WinError 123] 文件名、目录名或卷标语法不正确。: 'D:/CHATGLM/chatglm-6b'对于其他文件,诸如web_demo2、api.py等文件,均进行上述替换。
3.2 模型部署
创建一个新的conda环境,通过pycharm打开此模型后并激活对应conda环境后,先下载对应的cuda、pytorch,并保证torch.cuda.is_available()==True;此后在conda终端通过pip安装对应依赖。
pip install -r requirements.txt此时需要再次检测torch.cuda.is_available()==True是否成立,若不成立则说明pip安装时下载了CPU版本的torch,需要卸载掉并重新安装。
3.3 模型测试
在上述步骤执行以后,即可进行对应的测试。
3.3.1 web_demo.py
可以通过运行web_demo.py以进行测试。具体可在conda命令行运行如下命令。
python web_demo.py将此URL打开,主界面如下图所示。

进行一些较为简单的测试,测试期间GPU使用如下图。


经过多次测试后发现,第一次输入的时候输出较慢,需要等待3-7s左右,后续输入的输出均较快。
3.3.2 web_demo2.py
测试亦可以通过web_demo2文件以进行。在conda命令行运行如下命令。此时conda命令行要求提供邮箱,输入即可。
streamlit run web_demo2.py 输入邮箱以后,就会产生对应的URL,打开后界面如下。

3.3.1中的命令运行以后,会立刻将模型读入GPU内;而3.3.2中的命令,只有在给出了第一次输入以后才会将模型读入,相应的第一次输入以后输出也会较慢。

四.总结
相对上一篇文章部署的alpaca-lora,本次部署的模型完全支持中文,且可以联系上下文。在本台机器上的运行速度比alpaca-lora更快。














 2298
2298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









