






在本练习中,您将实现 K 均值聚类分析算法和应用它来压缩图像。
1 K-means Clustering K-Means聚类算法
在本练习中,您将实现 K 均值算法并使用它用于图像压缩。您将首先从示例 2D 数据集开始,该数据集将帮助您直观地了解 K 均值算法的工作原理。也就是说,您将使用K均值算法进行图像压缩,方法是减少图像中出现的颜色数量,仅显示这些图像中最多得颜色。
1.1 Implementing K-means
1.1.1 Finding closest centroids 找到最近的聚类中心
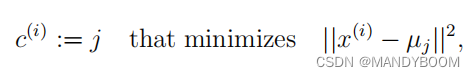
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
# 导入数据
data = loadmat('ex7data2.mat')
X = data['X']
# 找到最近得聚类中心
def find_closest_center(X, center):
'''输入样本X和初始聚类中心找到最终聚类中心'''
no_X = X.shape[0]
no_cent = center.shape[0]
idx = np.zeros(no_X)
for i in range(no_X):
min_dis = 10000000
for j in range(no_cent):
distance = np.sum((X[i, :] - center[j, :]) ** 2)
if distance < min_dis:
min_dis = distance
idx[i] = j
return idx
# 随机初始化三个聚类中心[3,3] [6,2] [8,5]
init_center = np.array([[3, 3], [6, 2], [8, 5]])
idx = find_closest_center(X, init_center)
print(idx[:3]) # [0. 2. 1.]随机初始化了一个聚类中心,发现数据集前三个样本分别离第一个、第三个、第二个聚类中心最近。
1.1.2 Computing centroid means计算聚类中心均值
也就是计算每个聚类中心所在簇得所有样本的均值。
先可视化一下数据。
# 数据可视化
data2 = pd.DataFrame(data.get('X'), columns=['x1', 'x2'])
print(data2)
import seaborn as sb
sb.set(context='notebook', style='dark')
sb.lmplot('x1', 'x2', data=data2, fit_reg=False)
plt.show()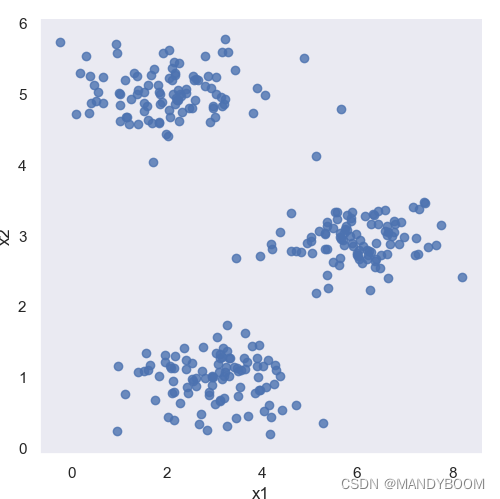
定义调整聚类中心的函数,通过输入样本X,和样本点得分类集idx,以及聚类中心点得个数K=3,返回每次迭代后得聚类中心得位置,也就是每一波聚类得点的均值。
def compute_cent(X, idx, K):
m,n = X.shape
cent = np.zeros((K,n))
for i in range(K):
ids = np.where(idx==i)
cent[i,:] = (np.sum(X[ids,:],axis=1)/len(ids[0])).ravel()
return cent
print(compute_cent(X, idx, 3))得到,三个聚类中心的位置:[[2.42830111 3.15792418]
[5.81350331 2.63365645]
[7.11938687 3.6166844 ]]
然后将上面的调整聚类中心得步骤开始迭代个20次吧。然后可视化一下。
# 开始迭代
def run_k_means(X, init_cent, iters):
m,n = X.shape
K= init_cent.shape[0]
idx = np.zeros(m)
cent = init_cent
for i in range(iters):
idx = find_closest_center(X, cent)
cent = compute_cent(X, idx, K)
return idx,cent
idx, cent = run_k_means(X, init_center, 20)
cluster0 = X[np.where(idx==0)[0],:]
cluster1 = X[np.where(idx==1)[0],:]
cluster2 = X[np.where(idx==2)[0],:]
# 可视化
fig, ax = plt.subplots(figsize = (12,8))
ax.scatter(cluster0[:,0],cluster0[:,1],s= 50, c = 'r', label = 'cluster0')
ax.scatter(cluster1[:,0],cluster1[:,1],s= 50, c = 'g', label = 'cluster1')
ax.scatter(cluster2[:,0],cluster2[:,1],s= 50, c = 'b', label = 'cluster2')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.legend()
plt.show()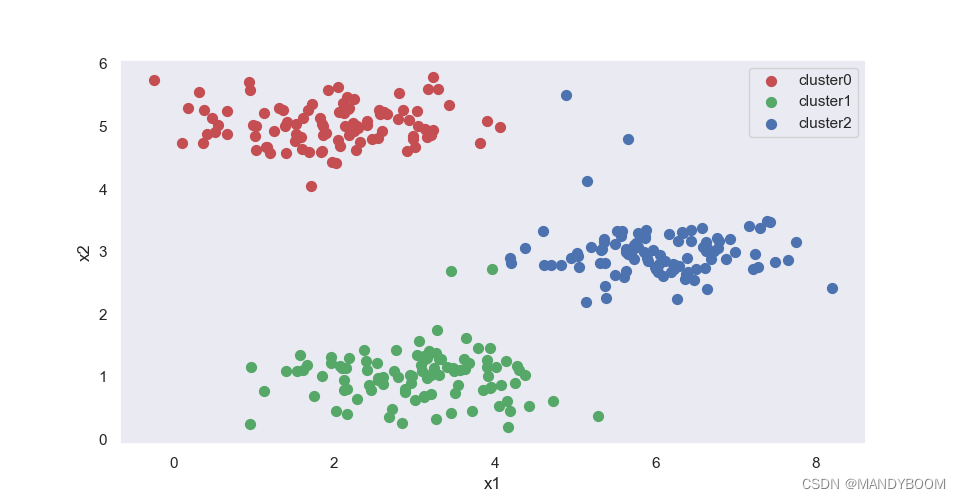
但是从图中可以看出来,有的点被分到得簇还不是很准确。可以用随机初始化创造新的初始聚类中心,观察最终结果。
定义使初始聚类中心是随机产生的方法。
def init_cent(X,K):
m,n = X.shape
cent = np.zeros((K,n))
idx = np.random.randint(0,m,K)
for i in range(K):
cent[i,:] = X[idx[i],:]
return cent
init_center2 = init_cent(X,3)
print(init_center2)得到随机初始化的聚类中心坐标为:[[1.67838038 5.26903822]
[6.69451358 2.89056083]
[2.40427775 5.0258707 ]]
用这个聚类中心坐标再次迭代上面的方法,再看分类结果。
idx,cent = run_k_means(X,init_center2,20)
cluster0 = X[np.where(idx==0)[0],:]
cluster1 = X[np.where(idx==1)[0],:]
cluster2 = X[np.where(idx==2)[0],:]
# 可视化
fig, ax = plt.subplots(figsize = (12,8))
ax.scatter(cluster0[:,0],cluster0[:,1],s= 50, c = 'r', label = 'cluster0')
ax.scatter(cluster1[:,0],cluster1[:,1],s= 50, c = 'g', label = 'cluster1')
ax.scatter(cluster2[:,0],cluster2[:,1],s= 50, c = 'b', label = 'cluster2')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.legend()
plt.show()得到的分簇图如下,由于K的值为3,还算小,利用多次随机初始化,再多次迭代K-means算法,得到的结果会比较准确。
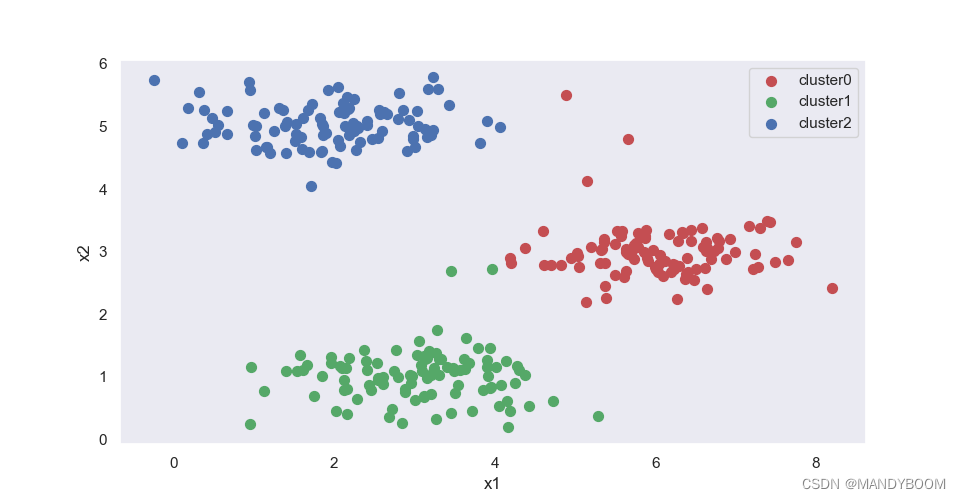
1.2 图片压缩
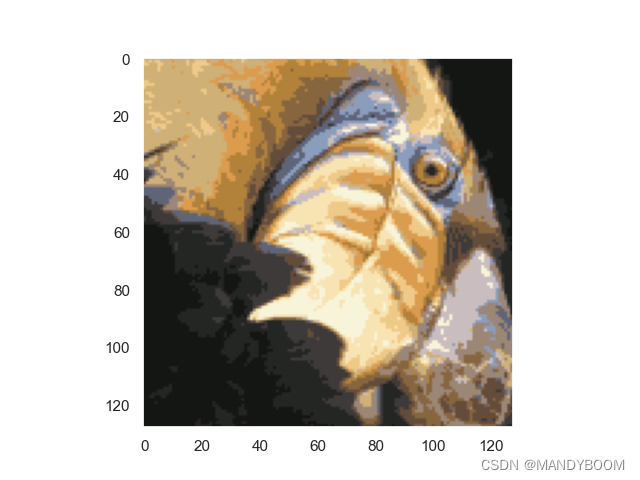
在图像的直接24位颜色表示中,每个像素被表示为三个8位无符号整数(范围从0到255),指定红色、绿色和蓝色强度值。这种编码常被称为RGB编码。我们的图像包含数千种颜色,在这部分练习中,您将把颜色的数量减少到16种颜色。通过这样的减少,可以有效地表示(压缩)照片。具体来说,您只需要存储16种选定颜色的RGB值,对于图像中的每个像素,您现在只需要在该位置存储颜色的索引(其中仅需要4位来表示16种可能性)。在本练习中,您将使用K-means算法来选择将用于表示压缩图像。具体地说,您将把原始图像中的每个像素作为一个数据示例,并使用K-mean算法来查找16种颜色,这些颜色最适合对三维RGB空间中的像素进行分组(聚类)。计算完图像上的簇质心后,将使用16种颜色替换原始图像中的像素。
# 案例: 使用K-means对图片颜色进行聚类
# RGB图像,每个像素点值范围0-255
data = loadmat('bird_small.mat')
print(data.keys())
A = data['A']
print(A.shape)
#初始化聚类中心
def kMeansInitCentroids(x, K):
randidx = np.random.permutation(x) #随机排列
centroids = randidx[:K, :]# 选前K个
return centroids
import skimage.io as io
image = io.imread('bird_small.png') # 读取图片
plt.imshow(image)
plt.axis('off') # 不显示对称轴
plt.show()
A = A/255 #标准化,让像素数据为0-1之间的数
A = A.reshape(-1,3) # 行数由Numpy自动计算,3列
print(A.shape) # (16384, 3)
k = 16 #16种颜色
centroids = kMeansInitCentroids(A, K=16)
print(centroids.shape) #(16, 3)
idx, centros = run_k_means(A, centroids, iters = 20)
print(idx.shape, centros.shape)
im = np.zeros(A.shape)
for i in range(k):
im[idx == i] = centros[i]
im = im.reshape(128, 128, 3)
plt.imshow(im)
plt.show()
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









